你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
本指南介绍如何使用上下文关联检测 API。 此功能会自动检测并更正针对提供的源文档的文本,确保生成的内容与事实引用或预期引用保持一致。 下面,我们将探讨几个常见场景,以帮助你了解如何以及何时应用这些功能来实现最佳结果。
先决条件
- 一个 Azure 帐户。 如果没有帐户,可以免费创建一个帐户。
- Azure AI 资源。
设置
按照以下步骤使用内容安全试用页面:
- 转到 Azure AI Foundry 并导航到你的项目/中心。 然后选择左侧导航栏上的 Guardrails + 控件 选项卡,然后选择“ 试用 ”选项卡。
- 在“试用”页面上,您可以尝试包括文本和图像内容在内的多种保护措施和控件功能,并使用可调整的阈值来筛选不当或有害内容。
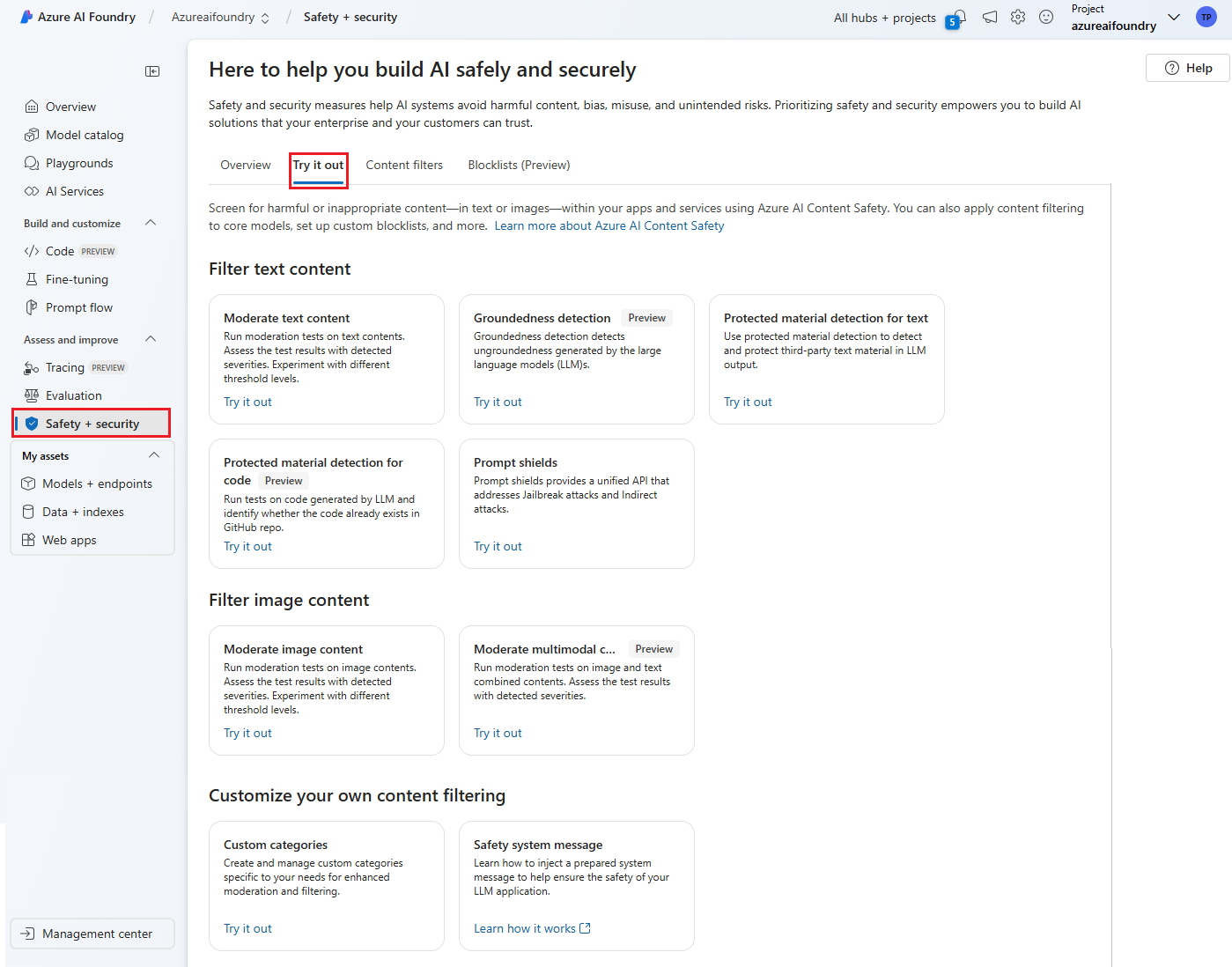
使用有据性检测
借助有据性检测面板,可以检测大型语言模型 (LLM) 的文本响应是否以用户提供的源材料为依据。
- 选择“有据性检测”面板。
- 选择页面上的示例内容集,或输入自己的用于测试的内容。
- (可选)启用推理功能,并从下拉列表中选择你的 Azure OpenAI 资源。
- 选择“运行测试”。 该服务返回有据性检测结果。
有关详细信息,请参阅有据性检测概念指南。
先决条件
- Azure 订阅 - 免费创建订阅
- 拥有 Azure 订阅后,请在 Azure 门户中创建 Content Safety 资源 ,以获取密钥和终结点。 输入资源的唯一名称,选择订阅,并选择资源组、支持的区域和支持的定价层。 然后选择“创建”。
- 部署资源需要几分钟时间。 完成后,请转到新的资源。 在左窗格的“资源管理”下,选择“API 密钥和终结点”。 将其中一个订阅密钥值和终结点复制到临时位置供以后使用。
- (可选)若要使用 推理 功能,请在 Azure AI Foundry 模型资源中创建已部署 GPT 模型的 Azure OpenAI。
- 安装 cURL 或 Python。
身份验证
为了增强安全性,需要使用托管标识 (MI) 来管理对资源的访问权限。有关更多详细信息,请参阅安全性。
在不推理的情况下检查有据性
在不使用推理功能的简单情况下,有据性检测 API 将提交内容的无据性分类为 或 truefalse。
本部分介绍使用 cURL 进行请求的示例。 将以下命令粘贴到文本编辑器,并进行以下更改。
将
<endpoint>替换为与资源关联的终结点 URL。将
<your_subscription_key>替换为资源的密钥之一。(可选)将正文中的
"query"或"text"字段替换为要分析的文本。curl --location --request POST '<endpoint>/contentsafety/text:detectGroundedness?api-version=2024-09-15-preview' \ --header 'Ocp-Apim-Subscription-Key: <your_subscription_key>' \ --header 'Content-Type: application/json' \ --data-raw '{ "domain": "Generic", "task": "QnA", "qna": { "query": "How much does she currently get paid per hour at the bank?" }, "text": "12/hour", "groundingSources": [ "I'm 21 years old and I need to make a decision about the next two years of my life. Within a week. I currently work for a bank that requires strict sales goals to meet. IF they aren't met three times (three months) you're canned. They pay me 10/hour and it's not unheard of to get a raise in 6ish months. The issue is, **I'm not a salesperson**. That's not my personality. I'm amazing at customer service, I have the most positive customer service \"reports\" done about me in the short time I've worked here. A coworker asked \"do you ask for people to fill these out? you have a ton\". That being said, I have a job opportunity at Chase Bank as a part time teller. What makes this decision so hard is that at my current job, I get 40 hours and Chase could only offer me 20 hours/week. Drive time to my current job is also 21 miles **one way** while Chase is literally 1.8 miles from my house, allowing me to go home for lunch. I do have an apartment and an awesome roommate that I know wont be late on his portion of rent, so paying bills with 20hours a week isn't the issue. It's the spending money and being broke all the time.\n\nI previously worked at Wal-Mart and took home just about 400 dollars every other week. So I know i can survive on this income. I just don't know whether I should go for Chase as I could definitely see myself having a career there. I'm a math major likely going to become an actuary, so Chase could provide excellent opportunities for me **eventually**." ], "reasoning": false }'
打开命令提示符窗口并运行 cURL 命令。
若要测试摘要任务而不是问题解答 (QnA) 任务,请使用以下示例 JSON 正文:
{
"domain": "Medical",
"task": "Summarization",
"text": "Ms Johnson has been in the hospital after experiencing a stroke.",
"groundingSources": [
"Our patient, Ms. Johnson, presented with persistent fatigue, unexplained weight loss, and frequent night sweats. After a series of tests, she was diagnosed with Hodgkin’s lymphoma, a type of cancer that affects the lymphatic system. The diagnosis was confirmed through a lymph node biopsy revealing the presence of Reed-Sternberg cells, a characteristic of this disease. She was further staged using PET-CT scans. Her treatment plan includes chemotherapy and possibly radiation therapy, depending on her response to treatment. The medical team remains optimistic about her prognosis given the high cure rate of Hodgkin’s lymphoma."
],
"reasoning": false
}
URL 中必须包含以下字段:
| 名称 | 必需 | 说明 | 类型 |
|---|---|---|---|
| API 版本 | 必需 | 这是要使用的 API 版本。 当前版本为:api-version=2024-09-15-preview。 示例: <endpoint>/contentsafety/text:detectGroundedness?api-version=2024-09-15-preview |
字符串 |
请求正文中的参数在此表中定义:
| 名称 | 说明 | 类型 |
|---|---|---|
| domain | (可选)MEDICAL 或 GENERIC。 默认值:GENERIC。 |
枚举 |
| 任务 | (可选)任务类型:QnA、Summarization。 默认值:Summarization。 |
枚举 |
| 问题与解答 | (可选)当任务类型为 QnA 时保存 QnA 数据。 |
字符串 |
- query |
(可选)这表示 QnA 任务中的问题。 字符限制:7,500。 | 字符串 |
| 文本 | (必需)要检查的 LLM 输出文本。 字符限制:7,500。 | 字符串 |
| groundingSources | (必需)使用一组有据源来验证 AI 生成的文本。 有关限制,请参阅输入要求。 | 字符串数组 |
| reasoning | (可选)指定是否使用推理功能。 默认值为 false。 如果为 true,则需要自带 Azure OpenAI GPT-4o(0513、0806 版本)来提供解释。 请注意:使用推理会增加处理时间。 |
布尔 |
解释 API 响应
提交请求后,将收到反映执行的有据性分析的 JSON 响应。 下面是典型输出的外观:
{
"ungroundedDetected": true,
"ungroundedPercentage": 1,
"ungroundedDetails": [
{
"text": "12/hour."
}
]
}
输出中的 JSON 对象定义如下:
| 名称 | 说明 | 类型 |
|---|---|---|
| ungroundedDetected | 指示文本是否表现出无据性。 | 布尔 |
| ungroundedPercentage | 指定被识别为无据的文本的比例,表示为 0 到 1 之间的数字,其中 0 表示没有无据内容,1 表示完全为无据内容。 这不是置信度。 | 浮点 |
| ungroundedDetails | 通过具体示例和百分比提供对无据内容的见解。 | 数组 |
-text |
无据的特定文本。 | 字符串 |
在推理的情况下检查有据性
有据性检测 API 提供了在 API 响应中包含推理的选项。 启用推理后,响应包括一个 "reasoning" 字段,详细说明了特定实例以及对任何检测到的无据性的解释。
连接自己的 GPT 部署
提示
我们仅支持 Azure OpenAI GPT-4o(版本 0513,0806)资源,不支持其他模型。 你可以灵活地在任何区域中部署 Azure OpenAI GPT-4o(版本 0513,0806)资源。 但是,为了尽量减少潜在的延迟并避免任何地理边界数据隐私和风险问题,我们建议将它们置于 Azure AI 内容安全资源所在的同一区域。 有关数据隐私的全面详细信息,请参阅 Azure OpenAI 的数据、隐私和安全指南 和 Azure AI 内容安全的 数据、隐私和安全指南。
若要使用 Azure OpenAI GPT-4o(版本 0513,0806)资源启用推理功能,请使用托管标识允许内容安全资源访问 Azure OpenAI 资源:
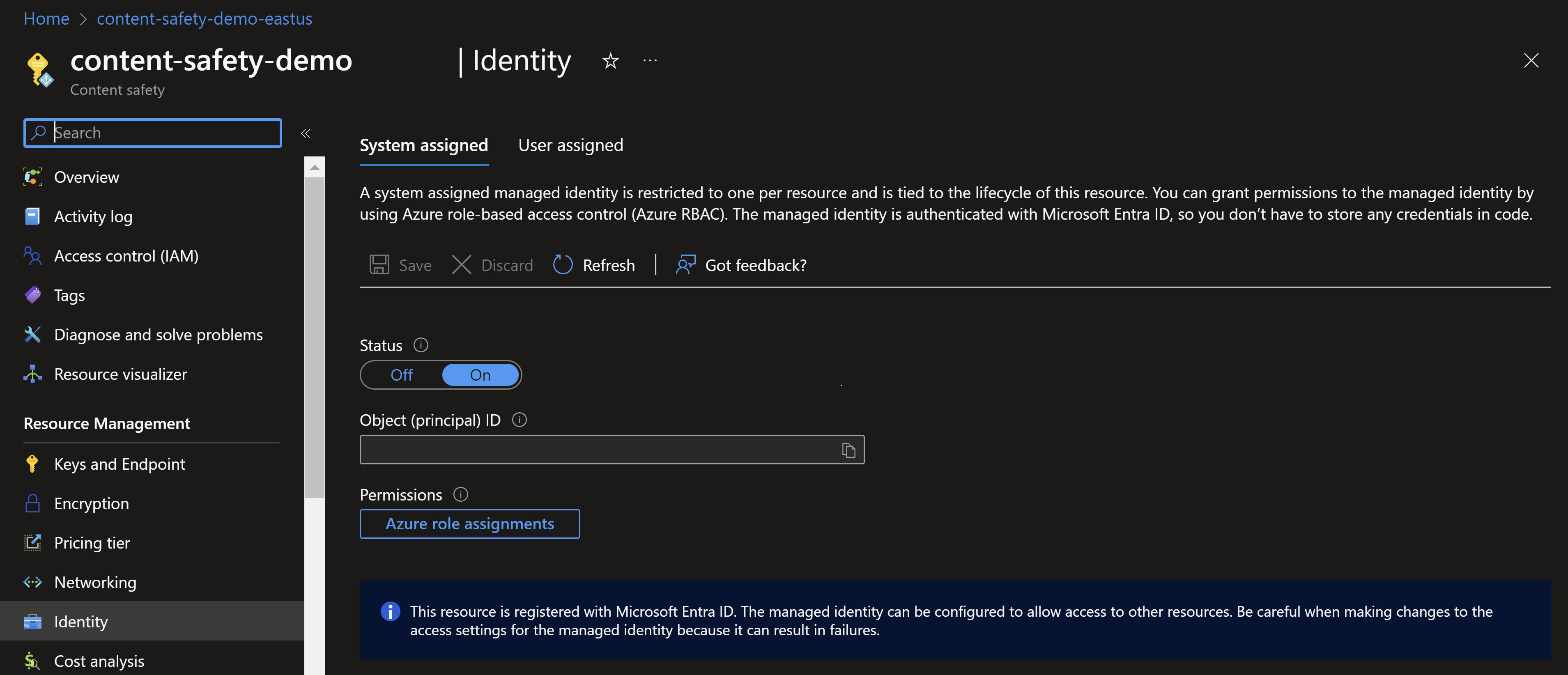
为 Azure AI 内容安全启用托管标识。
在 Azure 门户中导航到 Azure AI 内容安全实例。 在“设置”类别下找到“标识”部分。 启用系统分配的托管标识。 此操作向 Azure AI 内容安全实例授予可在 Azure 中识别和使用的标识,可用于访问其他资源。
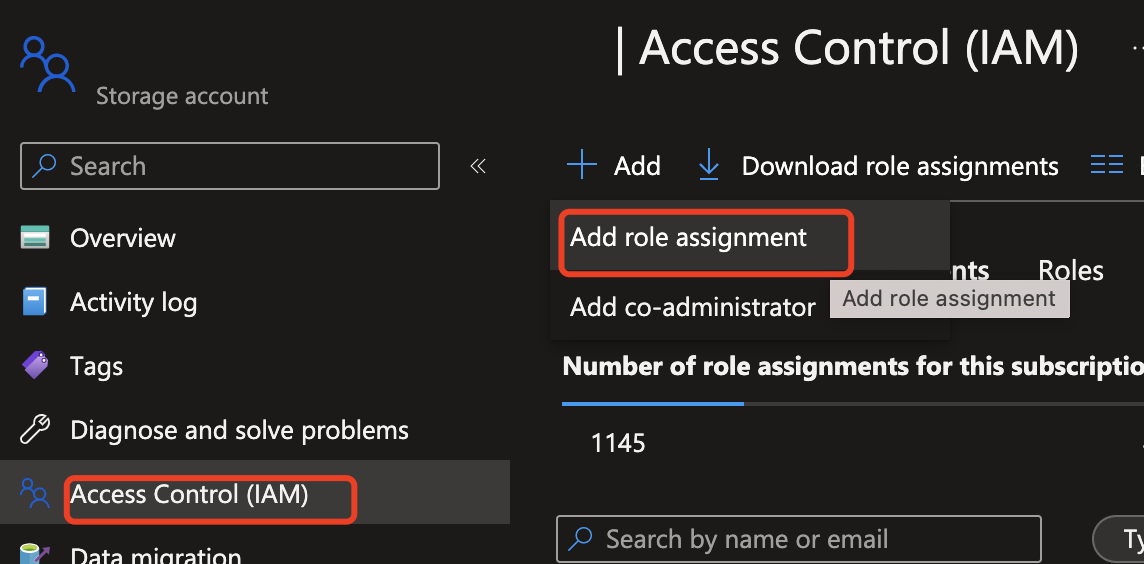
为托管标识分配角色。
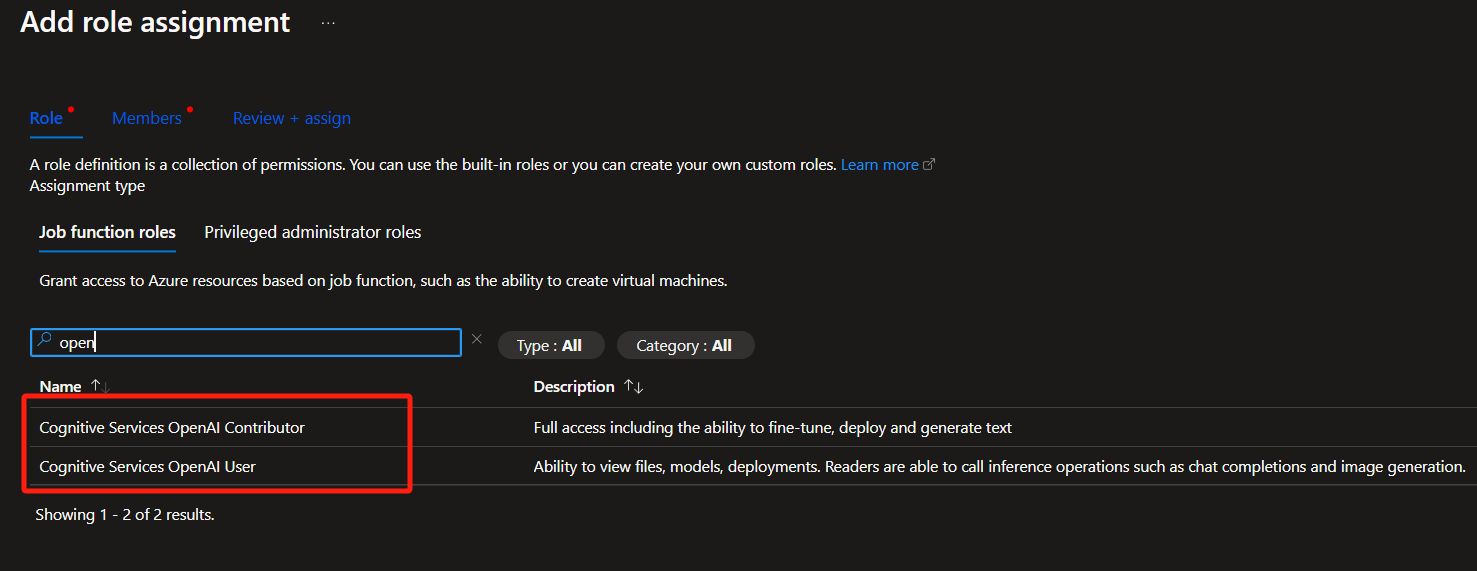
导航到 Azure OpenAI 实例,选择“添加角色分配”开始将 Azure OpenAI 角色分配到 Azure AI 内容安全标识的过程。
选择“用户”或“参与者”角色。


发出 API 请求
在对有据性检测 API 的请求中,将 "reasoning" 正文参数设置为 true,并提供其他所需的参数:
{
"domain": "Medical",
"task": "Summarization",
"text": "The patient name is Kevin.",
"groundingSources": [
"The patient name is Jane."
],
"reasoning": true,
"llmResource": {
"resourceType": "AzureOpenAI",
"azureOpenAIEndpoint": "<your_OpenAI_endpoint>",
"azureOpenAIDeploymentName": "<your_deployment_name>"
}
}
本部分介绍使用 cURL 进行请求的示例。 将以下命令粘贴到文本编辑器,并进行以下更改。
请将
<endpoint>替换为与你的 Azure AI 内容安全资源关联的终结点 URL。将
<your_subscription_key>替换为资源的密钥之一。请将
<your_OpenAI_endpoint>替换为与你的 Azure OpenAI 资源关联的终结点 URL。请将
<your_deployment_name>替换为你的 Azure OpenAI 部署名称。(可选)将正文中的
"query"或"text"字段替换为要分析的文本。curl --location --request POST '<endpoint>/contentsafety/text:detectGroundedness?api-version=2024-09-15-preview' \ --header 'Ocp-Apim-Subscription-Key: <your_subscription_key>' \ --header 'Content-Type: application/json' \ --data-raw '{ "domain": "Generic", "task": "QnA", "qna": { "query": "How much does she currently get paid per hour at the bank?" }, "text": "12/hour", "groundingSources": [ "I'm 21 years old and I need to make a decision about the next two years of my life. Within a week. I currently work for a bank that requires strict sales goals to meet. If they aren't met three times (three months) you're canned. They pay me 10/hour and it's not unheard of to get a raise in 6ish months. The issue is, **I'm not a salesperson**. That's not my personality. I'm amazing at customer service, I have the most positive customer service \"reports\" done about me in the short time I've worked here. A coworker asked \"do you ask for people to fill these out? you have a ton\". That being said, I have a job opportunity at Chase Bank as a part time teller. What makes this decision so hard is that at my current job, I get 40 hours and Chase could only offer me 20 hours/week. Drive time to my current job is also 21 miles **one way** while Chase is literally 1.8 miles from my house, allowing me to go home for lunch. I do have an apartment and an awesome roommate that I know wont be late on his portion of rent, so paying bills with 20hours a week isn't the issue. It's the spending money and being broke all the time.\n\nI previously worked at Wal-Mart and took home just about 400 dollars every other week. So I know i can survive on this income. I just don't know whether I should go for Chase as I could definitely see myself having a career there. I'm a math major likely going to become an actuary, so Chase could provide excellent opportunities for me **eventually**." ], "reasoning": true, "llmResource": { "resourceType": "AzureOpenAI", "azureOpenAIEndpoint": "<your_OpenAI_endpoint>", "azureOpenAIDeploymentName": "<your_deployment_name>" }'打开命令提示符窗口并运行 cURL 命令。
请求正文中的参数在此表中定义:
| 名称 | 说明 | 类型 |
|---|---|---|
| domain | (可选)MEDICAL 或 GENERIC。 默认值:GENERIC。 |
枚举 |
| 任务 | (可选)任务类型:QnA、Summarization。 默认值:Summarization。 |
枚举 |
| 问题与解答 | (可选)当任务类型为 QnA 时保存 QnA 数据。 |
字符串 |
- query |
(可选)这表示 QnA 任务中的问题。 字符限制:7,500。 | 字符串 |
| 文本 | (必需)要检查的 LLM 输出文本。 字符限制:7,500。 | 字符串 |
| groundingSources | (必需)使用一组有据源来验证 AI 生成的文本。 有关限制,请参阅输入要求。 | 字符串数组 |
| reasoning | (可选)设置为 true,该服务使用 Azure OpenAI 资源提供说明。 请注意:使用推理会增加处理时间,并产生额外的费用。 |
布尔 |
| llmResource | (必需)如果要使用自己的 Azure OpenAI GPT-4o(版本 0513,0806)资源启用推理,请添加此字段并包括所用资源的子字段。 | 字符串 |
- resourceType |
指定要使用的资源的类型。 目前只允许 AzureOpenAI。 我们仅支持 Azure OpenAI GPT-4o(版本 0513,0806)资源,不支持其他模型。 |
枚举 |
- azureOpenAIEndpoint |
Azure OpenAI 服务的终结点 URL。 | 字符串 |
- azureOpenAIDeploymentName |
要使用的特定模型部署的名称。 | 字符串 |
解释 API 响应
提交请求后,将收到反映执行的有据性分析的 JSON 响应。 下面是典型输出的外观:
{
"ungroundedDetected": true,
"ungroundedPercentage": 1,
"ungroundedDetails": [
{
"text": "12/hour.",
"offset": {
"utf8": 0,
"utf16": 0,
"codePoint": 0
},
"length": {
"utf8": 8,
"utf16": 8,
"codePoint": 8
},
"reason": "None. The premise mentions a pay of \"10/hour\" but does not mention \"12/hour.\" It's neutral. "
}
]
}
输出中的 JSON 对象定义如下:
| 名称 | 说明 | 类型 |
|---|---|---|
| ungroundedDetected | 指示文本是否表现出无据性。 | 布尔 |
| ungroundedPercentage | 指定被识别为无据的文本的比例,表示为 0 到 1 之间的数字,其中 0 表示没有无据内容,1 表示完全为无据内容。 这不是置信度。 | 浮点 |
| ungroundedDetails | 通过具体示例和百分比提供对无据内容的见解。 | 数组 |
-text |
无据的特定文本。 | 字符串 |
-offset |
描述无据文本在各种编码中的位置的对象。 | 字符串 |
- offset > utf8 |
无据文本在 UTF-8 编码中的偏移位置。 | 整数 |
- offset > utf16 |
无据文本在 UTF-16 编码中的偏移位置。 | 整数 |
- offset > codePoint |
无据文本相对于 Unicode 码位的偏移位置。 | 整数 |
-length |
描述无据文本在各种编码中的长度的对象。 (utf8、utf16、codePoint),类似于偏移量。 | 物体 |
- length > utf8 |
无据文本在 UTF-8 编码中的长度。 | 整数 |
- length > utf16 |
无据文本在 UTF-16 编码中的长度。 | 整数 |
- length > codePoint |
无据文本相对于 Unicode 码位的长度。 | 整数 |
-reason |
提供检测到的无据性的说明。 | 字符串 |
使用纠正功能检查上下文关联性
上下文关联性检测 API 包含一个纠正功能,可以根据提供的基础源自动纠正文本中检测到的任何上下文不关联性。 启用纠正功能时,响应会包含一个 "correction Text" 字段,该字段显示与基础源一致的已纠正文本。
连接自己的 GPT 部署
提示
目前,更正功能仅支持 Azure OpenAI GPT-4o(版本 0513,0806) 资源。 为了尽量减少延迟并遵守数据隐私准则,建议在 Azure AI 内容安全资源所在的同一区域中部署 Azure OpenAI GPT-4o(版本 0513,0806)。 有关数据隐私的更多详细信息,请参阅 Azure OpenAI 的数据、隐私和安全性指南 和 Azure AI 内容安全的数据、隐私和安全性。
若要使用 Azure OpenAI GPT-4o(版本 0513,0806)资源启用更正功能,请使用托管标识允许内容安全资源访问 Azure OpenAI 资源。 按照前面部分中所述的步骤设置托管标识。
发出 API 请求
在对上下文关联性检测 API 的请求中,请将 "correction" 正文参数设置为 true,并提供其他必要参数:
{
"domain": "Medical",
"task": "Summarization",
"text": "The patient name is Kevin.",
"groundingSources": [
"The patient name is Jane."
],
"correction": true,
"llmResource": {
"resourceType": "AzureOpenAI",
"azureOpenAIEndpoint": "<your_OpenAI_endpoint>",
"azureOpenAIDeploymentName": "<your_deployment_name>"
}
}
本部分演示一个使用 cURL 的示例请求。 请根据需要替换占位符:
- 请将
<endpoint>替换为你的资源的终结点 URL。 - 将
<your_subscription_key>替换为订阅密钥。 - (可选)将“text”字段替换为你要分析的文本。
curl --location --request POST '<endpoint>/contentsafety/text:detectGroundedness?api-version=2024-09-15-preview' \
--header 'Ocp-Apim-Subscription-Key: <your_subscription_key>' \
--header 'Content-Type: application/json' \
--data-raw '{
"domain": "Generic",
"task": "Summarization",
"text": "The patient name is Kevin.",
"groundingSources": [
"The patient name is Jane."
],
"correction": true,
"llmResource": {
"resourceType": "AzureOpenAI",
"azureOpenAIEndpoint": "<your_OpenAI_endpoint>",
"azureOpenAIDeploymentName": "<your_deployment_name>"
}
}'
请求正文中的参数在此表中定义:
| 名称 | 说明 | 类型 |
|---|---|---|
| domain | (可选)MEDICAL 或 GENERIC。 默认值:GENERIC。 |
枚举 |
| 任务 | (可选)任务类型:QnA、Summarization。 默认值:Summarization。 |
枚举 |
| 问题与解答 | (可选)当任务类型为 QnA 时保存 QnA 数据。 |
字符串 |
- query |
(可选)这表示 QnA 任务中的问题。 字符限制:7,500。 | 字符串 |
| 文本 | (必需)要检查的 LLM 输出文本。 字符限制:7,500。 | 字符串 |
| groundingSources | (必需)使用一组有据源来验证 AI 生成的文本。 有关限制,请参阅输入要求。 | 字符串数组 |
| 纠正 | (可选)设置为 true,服务将使用 Azure OpenAI 资源提供纠正的文本,确保与基础源保持一致。 请注意:使用纠正功能会增加处理时间并产生额外的费用。 |
布尔 |
| llmResource | (必需)如果要使用自己的 Azure OpenAI GPT-4o(版本 0513,0806)资源启用推理,请添加此字段并包括所用资源的子字段。 | 字符串 |
- resourceType |
指定要使用的资源的类型。 目前只允许 AzureOpenAI。 我们仅支持 Azure OpenAI GPT-4o(版本 0513,0806)资源,不支持其他模型。 |
枚举 |
- azureOpenAIEndpoint |
Azure OpenAI 服务的终结点 URL。 | 字符串 |
- azureOpenAIDeploymentName |
要使用的特定模型部署的名称。 | 字符串 |
解释 API 响应
响应中有一个 "correction Text" 字段,其中包含纠正的文本,确保与提供的基础源保持一致。
纠正功能检测到 Kevin 上下文不关联,因为它与基础源 Jane 冲突。 API 返回纠正的文本:"The patient name is Jane."
{
"ungroundedDetected": true,
"ungroundedPercentage": 1,
"ungroundedDetails": [
{
"text": "The patient name is Kevin"
}
],
"correction Text": "The patient name is Jane"
}
输出中的 JSON 对象定义如下:
| 名称 | 说明 | 类型 |
|---|---|---|
| ungroundedDetected | 指示是否检测到上下文不关联的内容。 | 布尔 |
| ungroundedPercentage | 上下文不关联的内容在文本中所占的比例。 这不是置信度。 | 浮点 |
| ungroundedDetails | 上下文不关联的内容的详细信息,包括特定的文本段。 | 数组 |
-text |
无据的特定文本。 | 字符串 |
-offset |
描述无据文本在各种编码中的位置的对象。 | 字符串 |
- offset > utf8 |
无据文本在 UTF-8 编码中的偏移位置。 | 整数 |
- offset > utf16 |
无据文本在 UTF-16 编码中的偏移位置。 | 整数 |
-length |
描述无据文本在各种编码中的长度的对象。 (utf8、utf16、codePoint),类似于偏移量。 | 物体 |
- length > utf8 |
无据文本在 UTF-8 编码中的长度。 | 整数 |
- length > utf16 |
无据文本在 UTF-16 编码中的长度。 | 整数 |
- length > codePoint |
无据文本相对于 Unicode 码位的长度。 | 整数 |
-correction Text |
纠正的文本,确保与基础源保持一致。 | 字符串 |
清理资源
如果想要清理并移除 Azure AI 服务订阅,可以删除资源或资源组。 删除资源组同时也会删除与之相关联的任何其他资源。
相关内容
- 有据性检测概念
- 将有据性检测与其他 LLM 安全功能(如 Prompt Shields)结合使用。