你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
概述
Azure 内容理解分析功能可帮助你将非结构化数据转换为结构化、计算机可读的信息。 通过在保留其结构关系的同时精确识别和提取元素,可以为各种应用程序构建强大的处理工作流。
具有类型 contents 的 document 对象支持不同输入文件的输出,包括文档、图像、文本和结构化文件。 你可以使用这些输出从文件中提取有意义的内容、保留文档结构以及解锁数据的全部潜力。
文档内容类型包括输入文件的输出,例如:
- 文档:PDF、Word 文档、PowerPoint 演示文稿和 Excel 电子表格
- 图:照片、扫描的文档和图表
- 文本文件:纯文本、HTML、Markdown 和 RTF
- 结构化内容:XML、JSON、CSV 和 TSV 文件
- 电子邮件:EML 和 MSG 邮件格式
有关支持的文件类型、文件大小限制和其他约束的详细信息,请参阅服务配额和限制。
JSON 响应结构
内容理解 API 以结构化 JSON 格式返回分析结果。 下面是整个容器结构:
{
"id": "10a01d32-e21e-46e3-bb5c-361375f184de",
"status": "Succeeded",
"result": {
"analyzerId": "my-analyzer",
"apiVersion": "2025-11-01",
"createdAt": "2025-06-18T22:50:34Z",
"warnings": [],
"contents": [
{
"markdown": "# Example Document\n\n...",
"fields": { /* extracted field values */ },
"kind": "document",
"startPageNumber": 1,
"endPageNumber": 2,
"unit": "inch",
"pages": [ /* page-level elements */ ],
"paragraphs": [ /* paragraph elements */ ],
"sections": [ /* section elements */ ],
"tables": [ /* table elements */ ],
"figures": [ /* figure elements */ ],
"hyperlinks": [ /* hyperlink elements */ ],
"annotations": [ /* annotation elements */ ]
}
]
}
}
文档元素
可以通过文档分析提取以下文档元素:
并非所有内容和布局元素都适用或当前受所有文档文件类型支持。
Markdown 内容元素
内容理解会生成格式丰富的 Markdown,用于保留原始文档的结构。 因此,大型语言模型可以更好地理解 AI 驱动的分析和生成任务的文档上下文和分层关系。 除了字词、选择标记、条形码、公式和图像作为内容外,Markdown 还包括用于视觉呈现和计算机处理的节、表和页面元数据。 详细了解内容理解如何表示 Markdown 中的内容和布局元素。
单词
字词是由一系列字符构成的内容元素。 Unicode 标准附件 #29 定义字词边界。 对于拉丁语言,即使没有中间空格,单词也可以与标点符号分离。 在某些语言(如中文)中,补充词字典用于在语义边界上启用字词拆分。 有关详细信息,请参阅边界分析。
JSON 示例:
{
"words": [
{
"content": "Example",
"span": {
"length": 7
},
"confidence": 0.992,
"source": "D(1,1.265,1.0836,2.4972,1.0816,2.4964,1.4117,1.2645,1.4117)"
}
]
}

选择标记
选择标记是一种内容元素,它表示一个指示选择状态的视觉字形。 选择标记可能会在文档中显示为复选框、复选标记或按钮。 你可以选择或清除选择标记,并使用不同的视觉表示形式来指示状态。 选择标记使用 Unicode 字符☒(已选中)和☐(已清除)在文档分析结果中编码为单词。
内容理解将检测表格单元格内的复选标记作为选定状态中的选择标记。 它不会将空表格单元格检测为处于清除状态的选择标记。
JSON 示例:
{
"words": [
{
"content": "☒",
"span": {
"length": 1
},
"confidence": 0.983,
"source": "D(1,1.258,2.7952,1.3705,2.7949,1.371,2.9098,1.2575,2.9089)"
}
]
}

条形码
条形码是描述线性(例如 UPC 或 EAN)和二维(例如 QR 或 MaxiCode)条形码的内容元素。 内容理解使用检测到的类型和提取的值来表示条形码。 目前支持以下条形码格式:
| 条形码类型 | DESCRIPTION |
|---|---|
QRCode |
QR 码,如 ISO/IEC 18004:2015 中定义 |
PDF417 |
ISO 15438 中定义的 PDF417 |
UPCA |
GS1 12 位通用产品代码 |
UPCE |
GS1 6 位通用产品代码 |
Code39 |
ISO/IEC 16388:2007 中定义的 CODE 39 条码 |
Code128 |
ISO/IEC 15417:2007 中定义的代码 128 条形码 |
EAN8 |
GS1 8 位国际项目编号(欧洲项目编号) |
EAN13 |
GS1 13 位国际项目编号(欧洲项目编号) |
DataBar |
GS1 DataBar 条形码 |
Code93 |
代码 93 条形码,如 ANSI/AIM BC5-1995 中定义 |
Codabar |
Codabar 条形码,如 ANSI/AIM BC3-1995 中所定义 |
DataBarExpanded |
GS1 DataBar 扩展条形码 |
ITF |
ANSI/AIM BC2-1995 中定义的“交错式 2/5 条形码 (ITF)” |
MicroQRCode |
ISO/IEC 23941:2022 中定义的微 QR 码 |
Aztec |
Aztec 代码,如 ISO/IEC 24778:2008 中所述 |
DataMatrix |
ISO/IEC 16022:2006 中定义的数据矩阵代码 |
MaxiCode |
MaxiCode,在 ISO/IEC 16023:2000 中定义 |
JSON 示例:
{
"barcodes": [
{
"kind": "Code39",
"value": "Hello World",
"source": "D(1,2.5738,4.8186,3.8617,4.8153,3.8621,4.9894,2.5743,4.9928)",
"span": {"offset": 192, "length": 10 },
"confidence": 0.977
}
]
}
公式
公式是表示文档中数学表达式的内容元素。 它可能是嵌入其他文本的内联公式,或者是占用整行的显示公式。 多行公式表示为多个显示公式元素,这些元素归类到段落中以保留数学关系。
公式可以是类型 inline ,也可以 display 取决于公式在文档中的位置。
JSON 示例:
{
"formulas": [
{
"kind": "inline",
"value": "x = \\frac { - b \\pm \\sqrt { b ^ { 2 } - 4 a c } } { 2 a }",
"confidence": 0.708,
"source": "D(1,3.4282,7.0195,4.0452,7.0307,4.0425,7.1803,3.4255,7.1691)",
"span": {
"offset": 394,
"length": 51
}
}
]
}
图表
图是表示文档中嵌入的图像、图形或图表的内容元素。 内容理解会生成检测到的数字摘要,将选择图像转换为 chart.js 表示形式,并从图像和任何关联的标题和脚注中提取任何嵌入文本。 图表在图形内容中使用 chart.js 语法表示,示意图在图形内容中使用 mermaid 语法的字符串表示。 这是一项可选功能,可以通过在分析器配置中将 enableFigureAnalysis 和 enableFigureDescription 设置为 true 进行启用。
目前支持以下图形类型:
| 图类型 | 表示 |
|---|---|
Bar chart |
Chart.js |
Line chart |
Chart.js |
Pie chart |
Chart.js |
Radar chart |
Chart.js |
Scatter chart |
Chart.js |
Bubble chart |
Chart.js |
Quadrant chart |
Chart.js |
Mixed chart (e.g. combined bar and line chart) |
Mermaid.js |
Flow chart |
Mermaid.js |
Sequence diagrams |
Mermaid.js |
Gantt chart |
Mermaid.js |
JSON 示例:
{
"figures": [
{
// enableFigureDescription = True
"description": "This figure illustrates the sales revenue over the year 2023.",
// enableFigureAnalysis = True
"kind": "chart",
"content": {
"type": "line",
"data": {
"labels": ["January", "February", "March", "April", "May", "June", "July"],
"datasets": [
{
"label": "A",
"data": [93, -29, -17, -8, 73, 98, 40]
},
{
"label": "B",
"data": [20, 85, -79, 93, 27, -81, -22]
}
]
},
"options": {
"title": { "text": "Title" }
}
}
},
{
"kind": "mermaid",
"content": "xychart-beta\n title \"Sales Revenue\"\n x-axis [jan, feb, mar, apr]..."
},
]
}
Hyperlinks
超链接是一个内容元素,表示连接到另一个资源(如文档中的网页)的嵌入链接。 Content Understanding 使用其嵌入链接来表示超链接。
JSON 示例:
{
"hyperlinks": [
{
"content": "Microsoft",
"url": "https://www.microsoft.com",
"span": {...},
"source": "..."
}
]
}
Annotations
批注 是文档中的其他元数据,用于提供额外的信息、澄清或反馈,而无需更改主要内容本身。 批注的类型多样,可能涉及特定的内容跨度,或者甚至指向特定的边界框。 下面是我们支持的批注类型列表。
注释
请注意,批注目前仅在数字 PDF 输入中受支持。
| 批注类型 |
|---|
highlight |
underline |
strikethrough |
rectangle |
circle |
drawing |
comments |
other |
JSON 示例:
{
"annotations": [
{
"id": "underline-1",
"kind": "underline",
"spans": [...],
"source": "D(pageNumber,l,t,w,h)",
"comments": [
{
"message": "Hi",
"author": "johndoe",
"createdAt": "2023-10-01T12:00:00Z",
"tags": ["approved"]
}
]
"author": "paulhsu",
"createdAt": "2023-10-01T12:00:00Z",
"lastModifiedAt": "2023-10-02T12:00:00Z",
"tags": [ ... ],
}
]
}
布局元素
文档布局元素是视觉和结构组件,如页面、表格、段落、行、表、节和整体结构,有助于解释内容。 提取这些元素使工具能够有效地分析文档,以便执行信息检索、语义理解和数据结构等任务。
页
页面是一组内容,通常对应于纸张的一面。 呈现的页面通过指定单位的宽度和高度来表征。 通常,图像使用像素,而 PDF 使用英寸。 该 angle 属性以度为单位描述可能旋转的页面的整体文本角度。
对于 Excel 等电子表格,每个工作表映射到一个页面。 对于演示文稿(例如 PowerPoint),每张幻灯片映射到一个页面。 对于不呈现本机页面概念的文件格式(如 HTML 或 Word 文档),整个主内容被视为单页。
JSON 示例:
{
"pages": [
{
"pageNumber": 1,
"angle": 0.0739153,
"width": 8.5,
"height": 11,
"spans": [
{
"offset": 0,
"length": 620
}
],
"words": [ /* array of word objects */ ],
"barcodes": [ /* details of barcodes */ ],
"lines": [ /* array of line objects */ ],
"formulas": [ /* array of formula objects */ ]
}
]
}
段落
段落是构成逻辑单元的有序行序列。 通常,线条共享共同的对齐方式和线条之间的间距。 段落通常通过缩进、增加的间距或项目符号/编号来分隔。 某些段落在文档中可能具有特殊功能的角色。 目前支持的角色包括页眉、页脚、页码、标题、章节标题、脚注和公式块。
JSON 示例:
{
"paragraphs": [
{
"role": "title",
"content": "Example Document",
"source": "D(1,1.264,1.0836,4.1584,1.0795,4.1589,1.4083,1.2644,1.4124)",
"span": {
"offset": 0,
"length": 18
}
}
]
}
线条
行是连续内容元素的有序序列,通常由视觉空间分隔。 同一水平平面(行)中的内容元素,但多个视觉空间分隔的内容元素通常拆分为多行。 此功能有时会将语义上连续的内容拆分为单独的行。 它还允许文本内容拆分为多个列或单元格的表示形式。 垂直书写中的线条会在垂直方向上被检测到。
JSON 示例:
{
"lines": [
{
"content": "Example Document",
"source": "D(1,1.264,1.0836,4.1583,1.0795,4.1589,1.4083,1.2645,1.4117)",
"span": {
"offset": 0,
"length": 16
}
}
]
}
表格
表格将内容整理成网格布局中的一组单元格。 行和列可以直观地按网格线、颜色条带或更大的间距分隔。 表格单元格的位置由其行索引和列索引指定。 一个单元格可以跨越多行和多列。
根据单元格的位置和样式,单元格被归类为常规内容、行标题、列标题、存根头或说明:
- 行标题单元格通常是一行中的第一个单元格,用于描述该行中的其他单元格。
- 列标题单元格通常是一列中的第一个单元格,用于描述该列中的其他单元格。
- 一行或一列可以包含多个标题单元格来描述分层内容。
- 副标题单元格通常是位于第一行第一列位置的单元格。 该单元格为空,或描述同一行/列中标题单元格中的值。
- 描述单元格通常位于表格的最上部或最下部区域,并描述整个表格内容。 它有时会出现在表格的中间,以将表分解为节。 通常,描述单元格跨越单行中的多个单元格。
表标题指定用于解释表的内容。 表格还可以有一组脚注。 与描述单元格不同,标题通常位于网格布局之外。 表格脚注批注表格内的内容,通常使用脚注符号进行标记。 它们通常位于表网格下方。
表格可能跨越文档的连续页面。 在这种情况下,后续页面中的表延续通常保留相同的列计数、宽度和样式。 它们通常会重复列标题。 通常,除了页眉、页脚和页码之外,初始表格和其延续部分之间通常没有中间内容。
表格可能跨越文档的连续页面。 在这种情况下,后续页面中的表延续通常保留相同的列计数、宽度和样式。 它们通常会重复列标题。 除了页眉、页脚和页码之外,初始表格和其延续部分之间通常没有中间内容。
注释
表格的跨度将涵盖核心内容及其关联的标题和脚注。
JSON 示例:
{
"tables": [
{
"rowCount": 6,
"columnCount": 2,
"cells": [
{
"kind": "columnHeader",
"rowIndex": 0,
"columnIndex": 0,
"rowSpan": 1,
"columnSpan": 1,
"content": "Category",
"source": "D(2,1.1674,5.0483,4.1733,5.0546,4.1733,5.2358,1.1674,5.2358)",
"span": {
"offset": 798,
"length": 8
},
"elements": [
"/paragraphs/7"
]
}
],
"source": "D(2,1.1566,5.0425,7.1855,5.0428,7.1862,6.1853,1.1574,6.1858)",
"span": {
"offset": 781,
"length": 280
},
"caption": {
"content": "Table 1: This is a table",
"source": "D(2,1.1566,5.0425,7.1855,5.0428,7.1862,6.1853,1.1574,6.1858)",
"span": {
"offset": 335,
"length": 30
}
}
}
]
}
章节
节是构成文档中分层结构的相关内容元素的逻辑分组。 它通常以章节标题作为第一段。 节可能包含用于创建保留语义关系的嵌套文档结构的子节。
JSON 示例:
{
"sections": [
{
"span": {
"offset": 113,
"length": 77
},
"elements": [
"/paragraphs/3",
"/paragraphs/4"
]
}
]
}
元素属性
文档由分类为结构、文本和表单相关元素的各种组件组成。 这些元素定义文档的组织和呈现。 你可以系统地识别和提取元素,以便进一步分析或应用。
跨度
该 span 属性通过字符偏移量和长度指定文档中元素的逻辑位置,并将其长度指定到顶级 markdown 字符串属性中。 默认情况下,字符偏移量和长度在 Unicode 码位中返回,这是 Python 3 使用的。 若要适应使用不同字符单元的不同开发环境,你可以指定 stringEncoding 查询参数以 UTF16 代码单元(Java、JavaScript 或 .NET)或 UTF8 字节(Go、Rust、Ruby 或 PHP)返回跨度偏移量和长度。
来源
该 source 属性使用编码字符串描述文件中元素的可视位置。 对于文档,源字符串的格式为以下中的一种:
-
边界多边形:
D({pageNumber},{x1},{y1},{x2},{y2},{x3},{y3},{x4},{y4}) -
轴对齐边界框:
D({pageNumber},{left},{top},{width},{height})
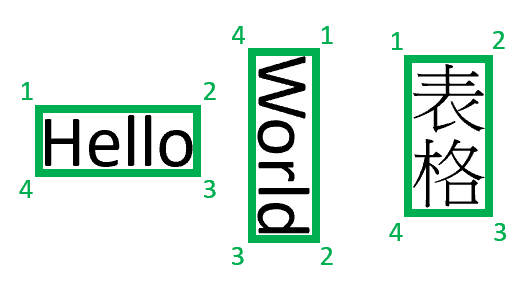
页码的索引从 1 开始。 边界多边形描述了一个顺序排列的点集,从元素自然方向的左侧开始顺时针排列。 对于四边形,这些点表示左上角、右上角、右下角和左下角。 每个点表示由属性“unit”指定的长度单位的 x 和 y 轴坐标。 一般情况下,图像的度量单位为像素。 PDF 使用英寸。
注释
目前,内容理解仅返回四点四边形作为边界多边形。 将来的版本可能会返回不同数量的点来描述更复杂的形状,例如曲线线或非矩形图像。 目前,仅针对呈现文件中的元素(PDF/图像)返回源。
相关内容
- 尝试使用 内容理解工作室处理文档内容。
- 查看 内容理解工作室快速入门指南。
- 了解如何使用 分析器模板分析文档内容。
- 使用可视化文档搜索查看代码示例。
- 查看代码示例分析器模板。
完整 JSON 示例
以下示例演示了分析文档的完整 JSON 响应结构。 当处理包含多个元素类型的 PDF 文档时,此 JSON 表示内容理解的完整输出:

{
"id": "10a01d32-e21e-46e3-bb5c-361375f184de",
"status": "Succeeded",
"result": {
"analyzerId": "auto-labeling-model-1750287025291-104",
"apiVersion": "2025-11-01",
"createdAt": "2025-06-18T22:50:34Z",
"warnings": [],
"contents": [
{
"markdown": "# Example Document\n\n\n## 1. Selection Marks (Checkboxes)\n\nEmployee Preferences Form\n☐\nRemote\n☒\nHybrid\n☐\nOn-site\n\n\n## 2. Barcodes\n\nGo check out Azure Content Understanding at the below link\n\n\n## 3. Formulas\n\nBayesian Inference (Posterior Probability):\n\n$$P \\left( \\theta \\mid D \\right) = \\frac { P \\left( D \\mid \\theta \\right) \\cdot P \\left( \\theta \\right) } { P \\left( D \\right) }$$\n\nWhere:\n\n$$P \\left( \\theta \\mid D \\right)$$\nis the posterior\n\n$P \\left( D \\mid \\theta \\right)$ is the likelihood\n$P \\left( \\theta \\right)$ is the prior\n\n$$P \\left( D \\right) i s \\quad t h e \\quad e v i d e n c e$$\n\n<!-- PageBreak -->\n\n\n## 4. Images\n\nSample Product Image\n\n\n<figure>\n\nContent\nUnderstanding\n\n</figure>\n\n\nImage Description: \"A ceramic coffee mug with company logo.\"\n\n\n## 5. Tables\n\n\n<table>\n<tr>\n<th>Category</th>\n<th>Amount ($)</th>\n</tr>\n<tr>\n<td>Rent</td>\n<td>1,200</td>\n</tr>\n<tr>\n<td>Utilities</td>\n<td>150</td>\n</tr>\n<tr>\n<td>Groceries</td>\n<td>300</td>\n</tr>\n<tr>\n<td>Transportation</td>\n<td>100</td>\n</tr>\n<tr>\n<td>Total</td>\n<td>1,750</td>\n</tr>\n</table>\n\n\n## 6. Paragraphs\n\nOur company is committed to fostering a productive and inclusive work environment. All\nemployees are expected to comply with the outlined policies and demonstrate mutual\nrespect in day-to-day operations. Regular reviews will ensure that these policies remain\nrelevant and effective.\n",
"fields": {
"EmployeePreferences": {
"type": "string",
"valueString": "Hybrid",
"spans": [
{
"offset": 94,
"length": 6
}
],
"confidence": 0.987,
"source": "D(1,1.4104,2.7836,1.8760,2.7823,1.8760,2.9377,1.4110,2.9396)"
},
"ImageDescription": {
"type": "string",
"valueString": "\"A ceramic coffee mug with company logo.\"",
"spans": [
{
"offset": 722,
"length": 41
}
],
"confidence": 0.958,
"source": "D(2,2.5222,4.2511,5.3236,4.2497,5.3237,4.4422,2.5223,4.4436)"
}
},
"kind": "document",
"startPageNumber": 1,
"endPageNumber": 2,
"unit": "inch",
"pages": [
{
"pageNumber": 1,
"angle": 0.0739153,
"width": 8.5,
"height": 11,
"spans": [
{
"offset": 0,
"length": 620
}
],
"words": [
{
"content": "Example",
"span": {
"length": 7
},
"confidence": 0.992,
"source": "D(1,1.265,1.0836,2.4972,1.0816,2.4964,1.4117,1.2645,1.4117)"
},
{
"content": "Document",
"span": {
"length": 8
},
"confidence": 0.996,
"source": "D(1,2.6252,1.084,4.1615,1.0886,4.1615,1.3993,2.6241,1.4117)"
},
{
"content": "☒",
"span": {
"length": 1
},
"confidence": 0.983,
"source": "D(1,1.258,2.7952,1.3705,2.7949,1.371,2.9098,1.2575,2.9089)"
},
{
"content": "Hybrid",
"span": {
"length": 6
},
"confidence": 0.996,
"source": "D(1,1.4104,2.7836,1.876,2.7823,1.876,2.9377,1.411,2.9396)"
}
],
"lines": [
{
"content": "Example Document",
"source": "D(1,1.264,1.0836,4.1583,1.0795,4.1589,1.4083,1.2645,1.4117)",
"span": {
"offset": 0,
"length": 16
}
}
],
"formulas": [
{
"confidence": 0.583
},
{
"confidence": 0.708
}
]
},
{
"pageNumber": 2,
"angle": 0.1008425,
"width": 8.5,
"height": 11,
"spans": [
{
"offset": 620,
"length": 744
}
],
"words": [
{
"content": "Images",
"source": "D(2,1.4516,1.0434,2.0254,1.0463,2.0254,1.229,1.4506,1.224)"
},
{
"content": "ceramic",
"source": "D(2,2.5230,4.2539,2.6591,4.2543,2.6584,4.4392,2.5223,4.4407)"
}
],
"lines": [
{
"content": "4. Images",
"source": "D(2,1.24,1.0409,2.0238,1.0463,2.0226,1.2284,1.2387,1.223)"
}
]
}
],
"paragraphs": [
{
"role": "title",
"content": "Example Document",
"source": "D(1,1.264,1.0836,4.1584,1.0795,4.1589,1.4083,1.2644,1.4124)",
"span": {
"offset": 0,
"length": 18
}
},
{
"role": "sectionHeading",
"content": "1. Selection Marks (Checkboxes)",
"source": "D(1,1.2461,1.8719,3.8532,1.8731,3.8531,2.065,1.246,2.0638)",
"span": {
"offset": 21,
"length": 34
}
},
{
"content": "Employee Preferences Form ☐ Remote ☒ Hybrid ☐ On-site",
"source": "D(1,1.246,2.0993,3.1019,2.1007,3.101,3.2724,1.2451,3.2709)",
"span": {
"offset": 57,
"length": 53
}
}
],
"sections": [
{
"span": {
"offset": 0,
"length": 1364
},
"elements": [
"/paragraphs/0",
"/sections/1",
"/sections/2",
"/sections/3",
"/sections/4",
"/sections/5",
"/sections/6"
]
},
{
"span": {
"offset": 21,
"length": 89
},
"elements": [
"/paragraphs/1",
"/paragraphs/2"
]
}
],
"tables": [
{
"rowCount": 6,
"columnCount": 2,
"cells": [
{
"kind": "columnHeader",
"rowIndex": 0,
"columnIndex": 0,
"rowSpan": 1,
"columnSpan": 1,
"content": "Category",
"source": "D(2,1.1674,5.0483,4.1733,5.0546,4.1733,5.2358,1.1674,5.2358)",
"span": {
"offset": 798,
"length": 8
}
},
{
"kind": "columnHeader",
"rowIndex": 0,
"columnIndex": 1,
"rowSpan": 1,
"columnSpan": 1,
"content": "Amount ($)",
"source": "D(2,4.1733,5.0546,7.1668,5.0546,7.1668,5.2358,4.1733,5.2358)",
"span": {
"offset": 816,
"length": 10
}
}
],
"source": "D(2,1.1566,5.0425,7.1855,5.0428,7.1862,6.1853,1.1574,6.1858)",
"span": {
"offset": 781,
"length": 280
}
}
],
"figures": [
{
"source": "D(2,1.3465,1.8481,3.4788,1.8484,3.4779,3.8286,1.3456,3.8282)",
"span": {
"offset": 658,
"length": 42
},
"elements": [
"/paragraphs/14"
],
"id": "2.1"
}
]
}
]
}
}
本完整示例演示内容理解如何从文档中提取和构造所有不同元素类型。 它提供原始内容以及支持高级文档处理工作流的详细位置和结构信息。