你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用 Azure AI 文档智能的检索扩充生成
此内容适用于:![]() v4.0(预览版)
v4.0(预览版)
介绍
检索扩充生成 (RAG) 是一种设计模式,它将 ChatGPT 等预训练的大型语言模型 (LLM) 与外部数据检索系统结合起来,生成一个包含原始训练数据之外的新数据的增强响应。 通过向应用程序添加信息检索系统,可以与文档聊天、生成引人注解的内容,并访问数据 Azure OpenAI 模型的强大功能。 在制定响应时,你还会对 LLM 使用的数据拥有更大的控制权。
文档智能布局模型是基于机器学习的高级文档分析 API。 该布局模型为高级内容提取和文档结构分析功能提供了全面的解决方案。 使用布局模型,可以轻松提取文本和结构元素,根据语义内容而不是任意分割将大段文本划分为更小、有意义的区块。 提取的信息可以方便地输出到 Markdown 格式,使你能够基于提供的构建基块定义语义分块策略。
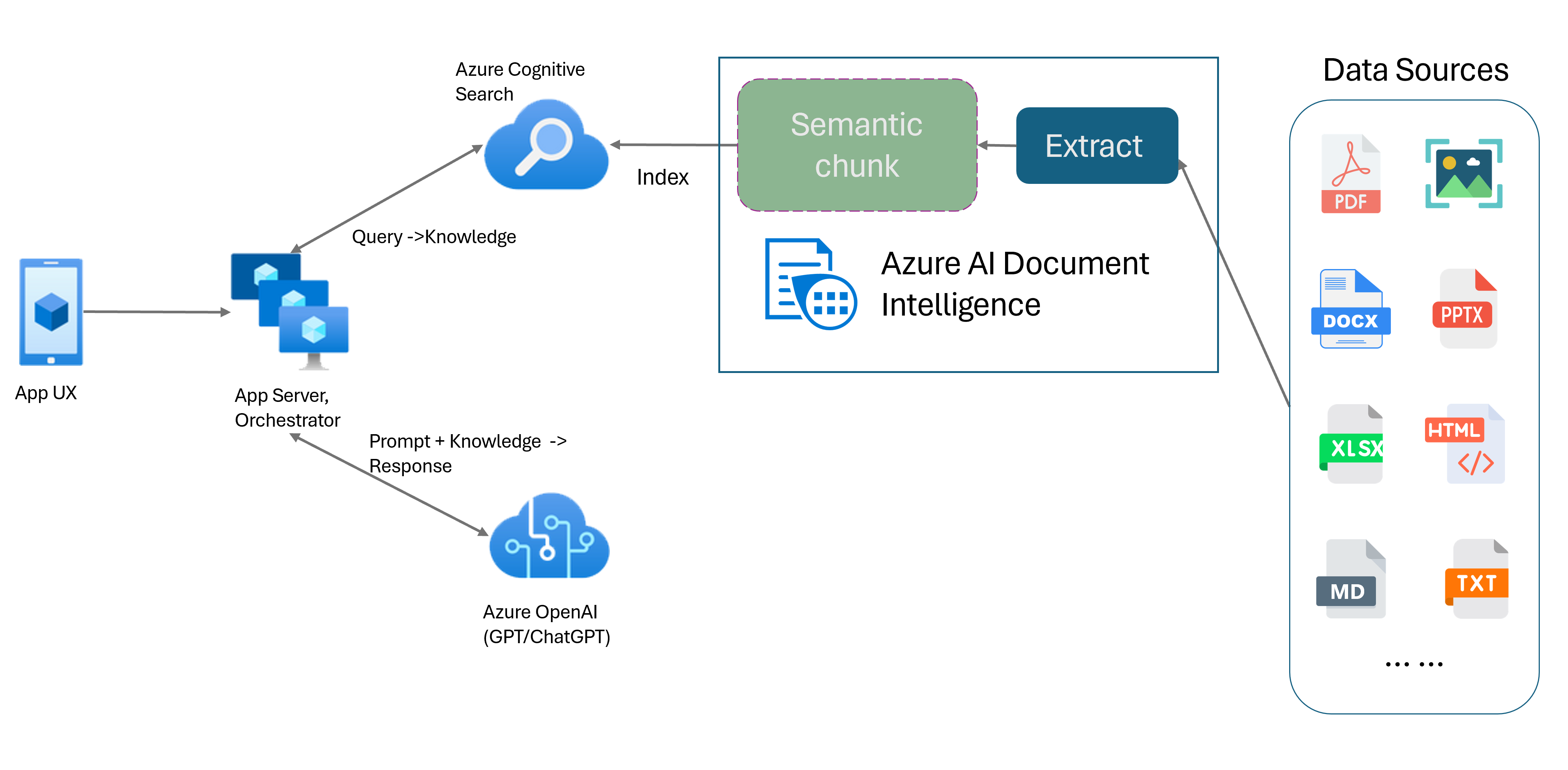
语义分块
对于自然语言处理 (NLP) 应用程序来说,长句具有挑战性。 特别是当它们由多个子句、复杂名词或谓词短语、关系从句和插入语组成时。 就像人类观察者一样,自然语言处理系统也需要成功地跟踪所有呈现的依赖关系。 语义分块的目标是找到句子表述中语义连贯的片段。 然后,这些片段可以独立处理,并重新组合为语义表征,而不会丢失信息、解释或语义相关性。 文本的固有含义会用作分块过程的指导。
文本数据分块策略在优化 RAG 响应和性能方面发挥关键作用。 固定大小分块法和语义分块法是两种截然不同的分块方法:
固定大小分块。 目前在 RAG 中使用的大多数分块策略都基于称固定大小的文本段,即区块。 固定大小的分块对于没有强语义结构(如日志和数据)的文本而言快速、简单且有效。 不过,对于需要理解语义和精确上下文的文本,不建议使用这种方法。 窗口的固定大小可能导致单词、句子或段落被截断,阻碍理解并打乱信息和理解的流程。
语义分块。 此方法根据语义理解将文本划分为区块。 划分边界侧重于句子主题,并使用大量复杂的计算算法资源。 但是,它具有保持每个块内的语义一致性的独特优势。 它适用于文本摘要、情绪分析和文档分类任务。
使用文档智能布局模型的语义分块
Markdown 是结构化和格式化的标记语言,也是用于在 RAG(检索增强生成)中启用语义分块的常用输入。 可以使用布局模型中的 Markdown 内容基于段落边界拆分文档,为表格创建特定的区块,并微调分块策略以提高生成的响应的质量。
使用布局模型的好处
简化的处理。 可以使用单个 API 调用分析不同的文档类型,例如数字版和扫描的 PDF、图像、Office 文件 (docx、xlsx、pptx) 和 HTML。
可伸缩性和 AI 质量。 布局模型在光学字符识别 (OCR)、表提取和文档结构分析高度可缩放。 它支持 309 种打印和 12 种手写语言,进一步确保由 AI 功能驱动的高质量结果。
大型语言模型 (LLM) 兼容性。 布局模型 Markdown 格式的输出为 LLM 友好型,有助于将其无缝集成到工作流中。 可以将文档中的任何表格转换为 Markdown 格式,避免对文档进行繁琐的解析以提高 LLM 理解。
使用文档智能工作室进行处理并通过布局模型输出到 MarkDown 的文本图像

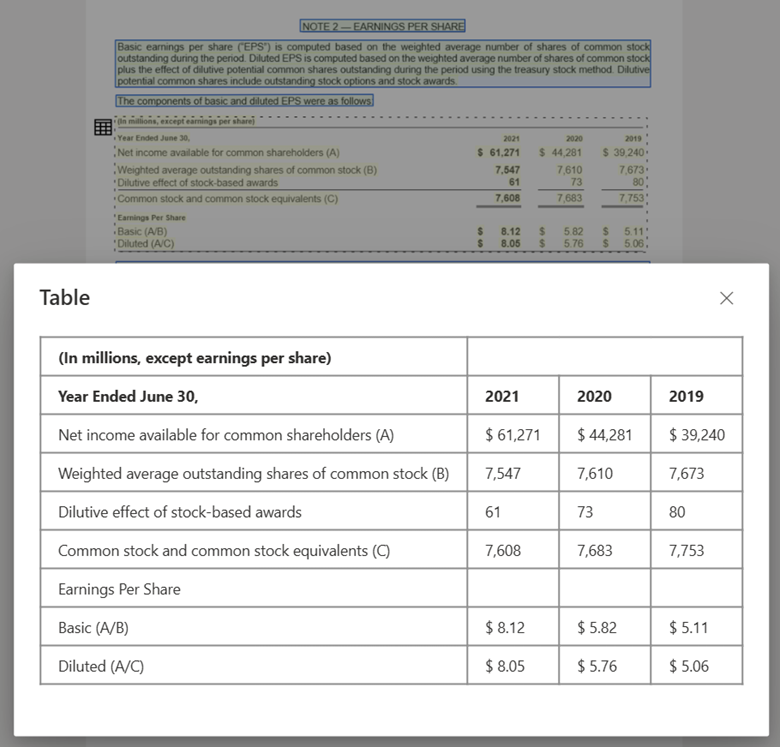
使用布局模型通过文档智能工作室处理的表图像
开始使用
文档智能布局模型 2024-02-29-preview 和 2023-10-31-preview 支持以下开发选项:
准备好开始了吗?
文档智能工作室
可以按照“文档智能工作室快速入门”开始操作。 接下来,可以使用提供的示例代码将文档智能功能与自己的应用程序集成。
从布局模型开始。 需要选择以下分析选项,以在工作室中使用 RAG:
**Required**- 运行分析范围 → 当前文档。
- 页面范围 → 所有页面。
- 输出格式样式 → Markdown。
**Optional**- 还可以选择相关的可选检测参数。
选择“保存”。
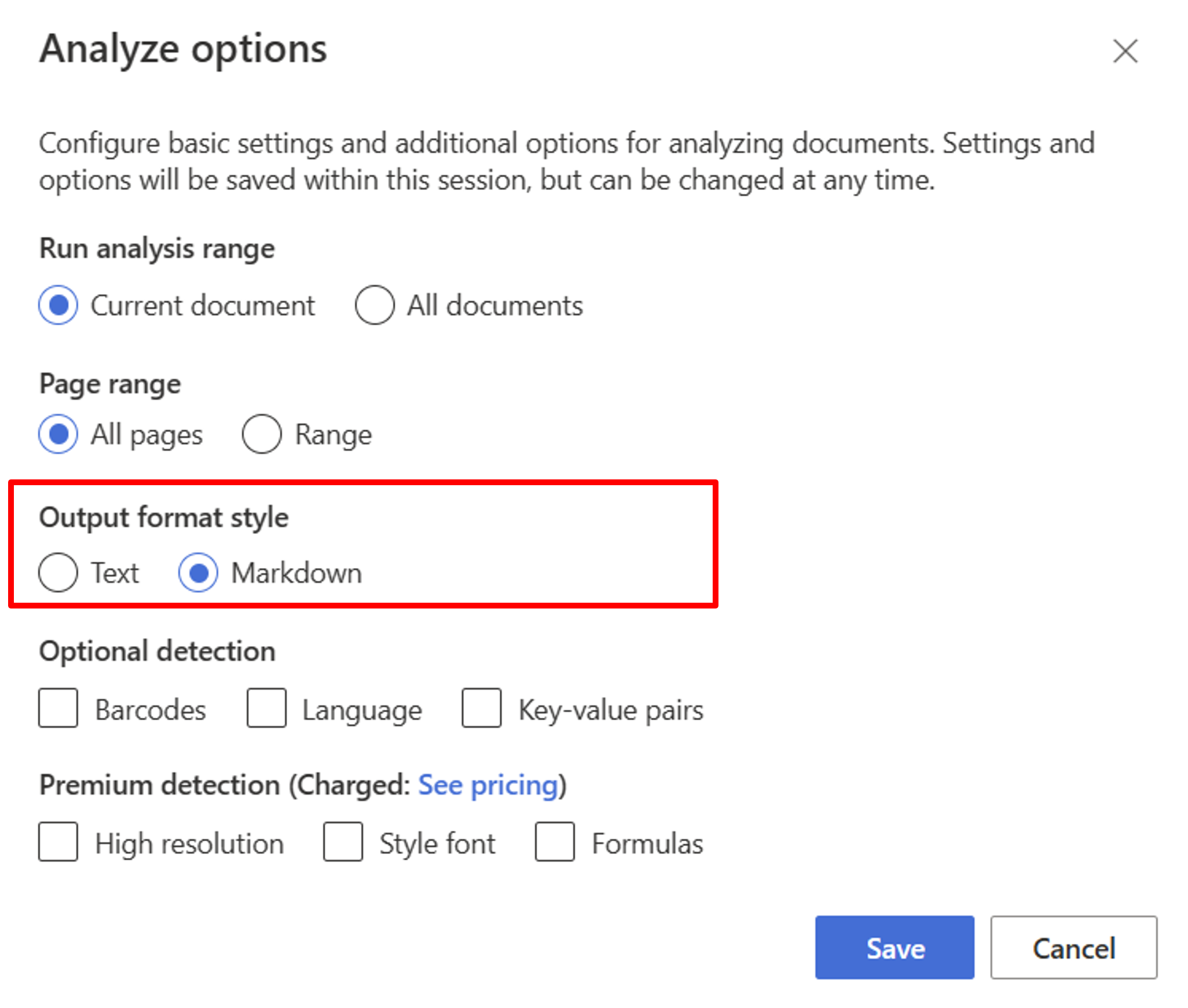
选择“运行分析”按钮以查看输出。

SDK 或 REST API
可以遵循首选编程语言 SDK 或 REST API 的文档智能快速入门。 使用布局模型从文档中提取内容和结构。
还可以查看 GitHub 存储库,了解代码示例和有关使用 markdown 输出格式分析文档的提示。
使用语义分块生成文档聊天
数据上的 Azure OpenAI 使你能够在文档中运行支持的聊天。 Azure OpenAI 对数据应用文档智能布局模型,通过基于表和段落对长文本进行分块来提取和分析文档数据。 还可以使用位于 GitHub 存储库中的 Azure OpenAI 示例脚本自定义分块策略。
Azure AI 文档智能现已与 LangChain 集成,成为其文档加载器之一。 可以使用它轻松地将数据输出并加载到 Markdown 格式。 有关详细信息,请参阅显示了 RAG 模式的简单演示的示例代码,其中 Azure AI 文档智能是文档加载程序,Azure 搜索是 LangChain 中的检索器。
与数据解决方案加速器的聊天代码示例演示端到端基线 RAG 模式示例。 它使用 Azure AI 搜索作为检索器,并使用 Azure AI 文档智能进行文档加载和语义分块。
用例
如果要在文档中查找特定部分,可以使用语义分块根据节标题将文档划分为较小的区块,从而帮助你快速轻松地找到要查找的部分:
# Using SDK targeting 2024-02-29-preview or 2023-10-31-preview, make sure your resource is in one of these regions: East US, West US2, West Europe
# pip install azure-ai-documentintelligence==1.0.0b1
# pip install langchain langchain-community azure-ai-documentintelligence
from azure.ai.documentintelligence import DocumentIntelligenceClient
endpoint = "https://<my-custom-subdomain>.cognitiveservices.azure.com/"
key = "<api_key>"
from langchain_community.document_loaders import AzureAIDocumentIntelligenceLoader
from langchain.text_splitter import MarkdownHeaderTextSplitter
# Initiate Azure AI Document Intelligence to load the document. You can either specify file_path or url_path to load the document.
loader = AzureAIDocumentIntelligenceLoader(file_path="<path to your file>", api_key = key, api_endpoint = endpoint, api_model="prebuilt-layout")
docs = loader.load()
# Split the document into chunks base on markdown headers.
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
text_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
docs_string = docs[0].page_content
splits = text_splitter.split_text(docs_string)
splits
后续步骤
详细了解 Azure AI 文档智能。
完成文档智能快速入门,并使用你选择的开发语言开始创建文档处理应用。
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈