你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
为微调任务 生成架构 后,向项目添加训练话语。 陈述应类似于用户在与项目交互时使用的内容。 添加语句时,必须指定该言语所属的意图。 添加语句后,标记语句中要提取为实体的字词。
数据标记是对话语言理解(CLU)训练的开发生命周期中的关键步骤。 训练模型时,下一步会使用此数据,以便模型可以从标记的数据中学习。 如果已标记话语,则可以将数据直接 导入项目(如果数据遵循 接受的数据格式)。 若要了解有关导入标记数据的详细信息,请参阅 创建 CLU 微调任务。 标记的数据告知模型如何解释文本,并用于训练和评估。
提示
使用 “快速部署 ”选项实现自定义 CLU 意向路由,该路由由你自己的大型语言模型部署提供支持,无需添加或标记任何训练数据。
先决条件
- 已成功创建的项目。
有关详细信息,请参阅 CLU 开发生命周期。
数据标记指南
生成架构并创建项目后,需要标记数据。 标记数据非常重要,以便模型知道哪些句子和字词与项目中的意向和实体相关联。 花时间标记话语来引入和优化用于训练模型的数据。
添加语句并标记它们时,请记住:
机器学习模型基于你提供的标记示例进行通用化。 提供的示例越多,模型所需的数据点越多,就可以进行更好的通用化。
标记数据的精度、一致性和完整性是确定模型性能的关键因素:
- 准确标记: 始终将每个意向和实体标记为其正确的类型。 仅包括要分类和提取的内容。 避免标签中不必要的数据。
- 标签一致: 同一实体应在所有陈述中具有相同的标签。
- 完全标记:为每个意向提供不同的语句。 标记所有语句中实体的所有实例。
清楚地标记语句
确保实体引用的概念定义清晰且可分离。 检查是否可以轻松可靠地确定差异。 如果你无法做到,这种缺乏区别可能表明学习组件存在困难。
确保数据的某些方面可以在实体之间存在相似性时提供差异信号。
例如,如果你生成了一个模型来预订航班,用户可能会使用此类语句:“我想要预订从波士顿飞往西雅图的航班。”此类语句的“出发地城市”和“目的地城市”应该类似。 区分“出发地城市”的一个信号可能是,它的前面经常出现“从”一词。
确保在训练数据和测试数据中标记每个实体的所有实例。 一种方法是使用搜索函数查找数据中某个字词或短语的所有实例,以检查是否正确标记。
对于 多语言项目,使用其他语言添加话语会增加模型在这些语言中的性能。 避免跨要支持的所有语言复制数据。 例如,为了提高日历机器人与用户的互动表现,开发人员可能会添加一些以英语为主的示例,还包括少量西班牙语或法语。 他们可能会添加以下言语:
- “明天下午12点与马特和凯文举行会晤。(英语)
- “Reply as tentative to the weekly update meeting.”(英语)
- “Cancelar mi próxima reunión.”(西班牙语)
标记语句
使用以下步骤标记语句:
转到 Azure AI Foundry 中的项目页。
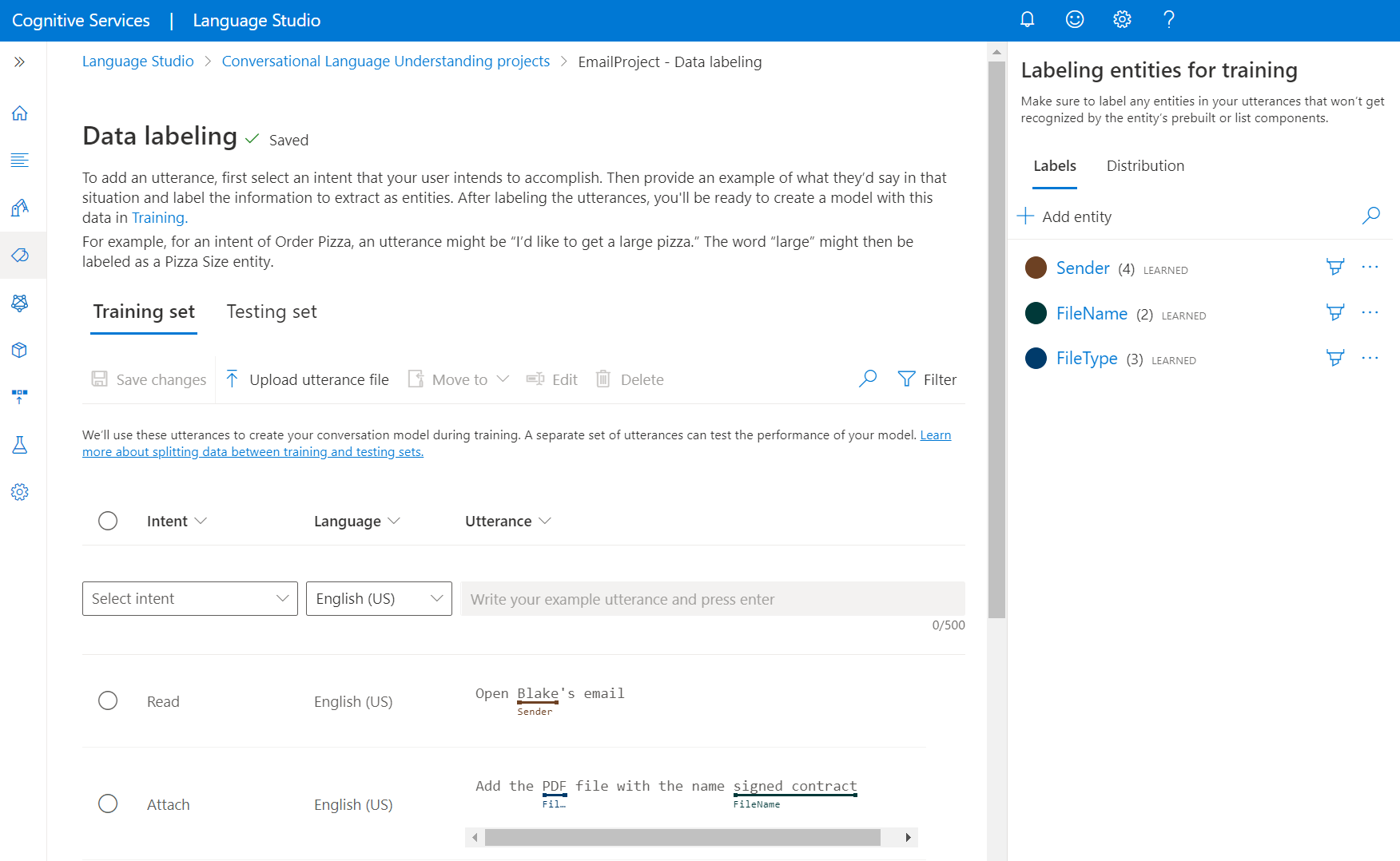
在左窗格中,选择“ 管理数据”。 在此页上,可以添加话语并标记它们。 还可以直接从顶部菜单中选择“ 上传话语文件 ”来直接上传话语。 请确保遵循 接受的格式。
通过使用顶部选项卡,可以将视图更改为 “训练集 ”或 “测试集”。 详细了解训练集和测试集以及它们如何用于模型训练和评估。
提示
如果计划使用“从训练数据中自动拆分测试集”拆分,请将所有语句添加到训练集中。
在“选择意向”下拉菜单中,选择其中一个意向、语句的语言(对于多语言项目),以及语句本身。 在话语的文本框中按 Enter 键并添加话语。
有两个选项来标记语句中的实体:
选项 说明 使用画笔标记 选择右侧窗格中实体旁边的画笔图标,然后在要标记的话语中突出显示文本。 使用内联菜单标记 突出显示要标记为实体的字词,随即会显示一个菜单。 选择要标记这些字词的实体。 在右侧的窗格中,在标签选项卡上,可以找到项目中的所有实体类型及每种实体类型的标记实例数量。
在 “分发 ”选项卡上,可以查看训练集和测试集之间的分布。 可以使用以下选项查看:
- 每个标记实体的实例总数: 可以查看特定实体的所有标记实例的计数。
- 每个标记实体的唯一陈述: 如果每个陈述包含此实体的至少一个标记实例,则会对其进行计数。
- 每个意向的语句数: 您可以查看每个意向的语句数量。



注意
数据标记页上不显示列表、正则表达式和预生成组件。 此处的所有标签仅适用于学习相关的组件。
删除标签:
- 从语句中,选择要从中移除标记的实体。
- 滚动显示的菜单,然后选择“删除标签”。
删除实体:
- 在右侧窗格中选择要编辑的实体旁边的垃圾箱图标。
- 选择“删除”以确认。
使用 Azure OpenAI 建议语句
在 CLU 中,使用 Azure OpenAI 的生成语言模型来建议要添加到项目中的话语。 建议在使用 CLU 时使用 Azure AI Foundry 资源,这样就不需要连接多个资源。
若要使用 Azure AI Foundry 资源,需要向 Azure AI Foundry 资源提供提升的访问权限。 为此,请访问 Azure 门户。 在 Azure AI 资源中,以“认知服务用户”的身份提供对自身的访问。 此步骤可确保资源的各个部分能够正确交流。
使用单独的语言和 Azure OpenAI 资源进行连接
首先需要在 Azure OpenAI 中获取访问权限并创建资源。 接下来,在 Azure AI Foundry 页面左窗格的 管理中心 内,在同一 Azure AI Foundry 项目中创建与 Azure OpenAI 资源的连接。 然后,需要在连接的 Azure OpenAI 资源中为 Azure OpenAI 模型创建部署。 若要创建新资源,请按照 “在 Azure AI Foundry Models 资源中创建和部署 Azure OpenAI”中的步骤作。
在开始之前,建议的话语功能仅在语言资源位于以下区域时才可用:
- 美国东部
- 美国中南部
- 西欧
在 “数据标签 ”页上:
选择 “建议话语”。 此时会在右侧打开一个窗格,并提示你选择 Azure OpenAI 资源和部署。
选择 Azure OpenAI 资源后,选择 “连接 ”,使语言资源能够直接访问 Azure OpenAI 资源。 它为语言资源分配针对 Azure OpenAI 资源的“认知服务用户”角色。 现在,当前语言资源有权访问 Azure OpenAI。 如果连接失败,请 按照以下步骤 将正确的角色手动添加到 Azure OpenAI 资源。
连接资源后,选择部署。 建议用于 Azure OpenAI 部署的模型是
gpt-35-turbo-instruct。选择您希望获取建议的意图。 请确保所选的意图至少有五个已保存的语句,以便启用语句建议。 Azure OpenAI 提供的建议基于您为该意向添加的最新语句。
选择“生成语句”。
建议的语句会出现在虚线边框中,并标注为AI 生成的。 必须接受或拒绝这些建议。 接受建议会将其添加到你的项目中,就像是你自己添加的一样。 拒绝建议会将其完全删除。 只有被接受的语句才是您项目的一部分,并会用于训练或测试。
若要接受或拒绝,请选择每个话语旁边的绿色复选标记或红色取消按钮。 还可以在工具栏上使用 “接受全部 ”和 “全部拒绝 ”。


使用此功能将产生针对 Azure OpenAI 资料的费用,计费标准将基于与生成的建议语句类似的令牌数量。 有关 Azure OpenAI 定价的信息,请参阅 Azure OpenAI 服务定价。
将所需配置添加到 Azure OpenAI 资源
使用以下选项为语言资源启用标识管理。
语言资源必须具有标识管理。 若要使用 Azure 门户启用它,请执行以下作:
- 转到你的语言资源。
- 在左窗格中的 “资源管理 ”部分下,选择“ 标识”。
- 在“系统分配”选项卡上,将“状态”设置为“启用”。
启用托管标识后,使用语言资源的托管标识将 认知服务用户 角色分配给 Azure OpenAI 资源。
登录到 Azure 门户 并转到 Azure OpenAI 资源。
选择访问控制 (IAM)选项卡。
选择添加>添加角色分配。
选择 “作业函数角色 ”,然后选择“ 下一步”。
从角色列表中选择 认知服务用户 ,然后选择“ 下一步”。
选择 “分配访问权限:托管标识 ”,然后选择 “选择成员”。
在 托管标识 下,选择 语言。
搜索资源并选择它。 然后选择“ 下一步 ”并完成该过程。
查看详细信息,然后选择“ 查看 + 分配”。


几分钟后,刷新 Azure AI Foundry,并可以成功连接到 Azure OpenAI。