你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
The Azure OpenAI Batch API is designed to handle large-scale and high-volume processing tasks efficiently. Process asynchronous groups of requests with separate quota, with 24-hour target turnaround, at 50% less cost than global standard. With batch processing, rather than send one request at a time you send a large number of requests in a single file. Global batch requests have a separate enqueued token quota avoiding any disruption of your online workloads.
Key use cases include:
Large-Scale Data Processing: Quickly analyze extensive datasets in parallel.
Content Generation: Create large volumes of text, such as product descriptions or articles.
Document Review and Summarization: Automate the review and summarization of lengthy documents.
Customer Support Automation: Handle numerous queries simultaneously for faster responses.
Data Extraction and Analysis: Extract and analyze information from vast amounts of unstructured data.
Natural Language Processing (NLP) Tasks: Perform tasks like sentiment analysis or translation on large datasets.
Marketing and Personalization: Generate personalized content and recommendations at scale.
Tip
If your batch jobs are so large that you are hitting the enqueued token limit even after maxing out the quota for your deployment, certain regions now support a new feature that allows you to queue multiple batch jobs with exponential backoff.
Once your enqueued token quota is available, the next batch job can be created and kicked off automatically. To learn more, see automating retries of large batch jobs with exponential backoff.
Important
We aim to process batch requests within 24 hours; we don't expire the jobs that take longer. You can cancel the job anytime. When you cancel the job, any remaining work is canceled and any already completed work is returned. You'll be charged for any completed work.
Data stored at rest remains in the designated Azure geography, while data may be processed for inferencing in any Azure OpenAI location. Learn more about data residency.
Batch support
Global batch model availability
| Region | o3, 2025-04-16 | o4-mini, 2025-04-16 | gpt-4.1, 2025-04-14 | gpt-4.1-nano, 2025-04-14 | gpt-4.1-mini, 2025-04-14 | o3-mini, 2025-01-31 | gpt-4o, 2024-05-13 | gpt-4o, 2024-08-06 | gpt-4o, 2024-11-20 | gpt-4o-mini, 2024-07-18 |
|---|---|---|---|---|---|---|---|---|---|---|
| australiaeast | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| brazilsouth | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| canadaeast | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| eastus | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| eastus2 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| francecentral | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| germanywestcentral | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| japaneast | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| koreacentral | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| northcentralus | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| norwayeast | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| polandcentral | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| southafricanorth | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| southcentralus | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| southindia | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| swedencentral | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| switzerlandnorth | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| uksouth | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| westeurope | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| westus | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| westus3 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
Registration is required for access to o3-mini. For more information see, our reasoning models guide.
The following models support global batch:
| Model | Version | Input format |
|---|---|---|
o3-mini |
2025-01-31 | text |
gpt-4o |
2024-08-06 | text + image |
gpt-4o-mini |
2024-07-18 | text + image |
gpt-4o |
2024-05-13 | text + image |
API support
| API Version | |
|---|---|
| Latest GA API release: | 2024-10-21 |
| Latest Supported Preview API release: | 2025-04-01-preview |
Note
While Global Batch supports older API versions, some models require newer preview API versions. For example, o3-mini isn't supported with 2024-10-21 since it was released after this date. To access the newer models with global batch use the latest preview API version.
Feature support
The following aren't currently supported:
- Integration with the Assistants API.
- Integration with Azure OpenAI On Your Data feature.
Batch deployment
Note
In the Azure AI Foundry portal the batch deployment types will appear as Global-Batch and Data Zone Batch. To learn more about Azure OpenAI deployment types, see our deployment types guide.

Tip
We recommend enabling dynamic quota for all global batch model deployments to help avoid job failures due to insufficient enqueued token quota. Using dynamic quota allows your deployment to opportunistically take advantage of more quota when extra capacity is available. When dynamic quota is set to off, your deployment will only be able to process requests up to the enqueued token limit that was defined when you created the deployment.
Prerequisites
- An Azure subscription - Create one for free.
- An Azure OpenAI resource with a model of the deployment type
Global-Batchdeployed. You can refer to the resource creation and model deployment guide for help with this process.
Preparing your batch file
Like fine-tuning, global batch uses files in JSON lines (.jsonl) format. Below are some example files with different types of supported content:
Input format
{"custom_id": "task-0", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was Microsoft founded?"}]}}
{"custom_id": "task-1", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was the first XBOX released?"}]}}
{"custom_id": "task-2", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "What is Altair Basic?"}]}}
The custom_id is required to allow you to identify which individual batch request corresponds to a given response. Responses won't be returned in identical order to the order defined in the .jsonl batch file.
model attribute should be set to match the name of the Global Batch deployment you wish to target for inference responses.
Important
The model attribute must be set to match the name of the Global Batch deployment you wish to target for inference responses. The same Global Batch model deployment name must be present on each line of the batch file. If you want to target a different deployment you must do so in a separate batch file/job.
For the best performance we recommend submitting large files for batch processing, rather than a large number of small files with only a few lines in each file.
Create input file
For this article, we'll create a file named test.jsonl and will copy the contents from standard input code block above to the file. You'll need to modify and add your global batch deployment name to each line of the file.
Upload batch file
Once your input file is prepared, you first need to upload the file to then be able to initiate a batch job. File upload can be done both programmatically or via the Azure AI Foundry portal. This example demonstrates uploading a file directly to your Azure OpenAI resource. Alternatively, you can configure Azure Blob Storage for Azure OpenAI Batch.
Sign in to Azure AI Foundry portal.
Select the Azure OpenAI resource where you have a global batch model deployment available.
Select Batch jobs > +Create batch jobs.
From the dropdown under Batch data > Upload files > select Upload file and provide the path for the
test.jsonlfile created in the previous step > Next.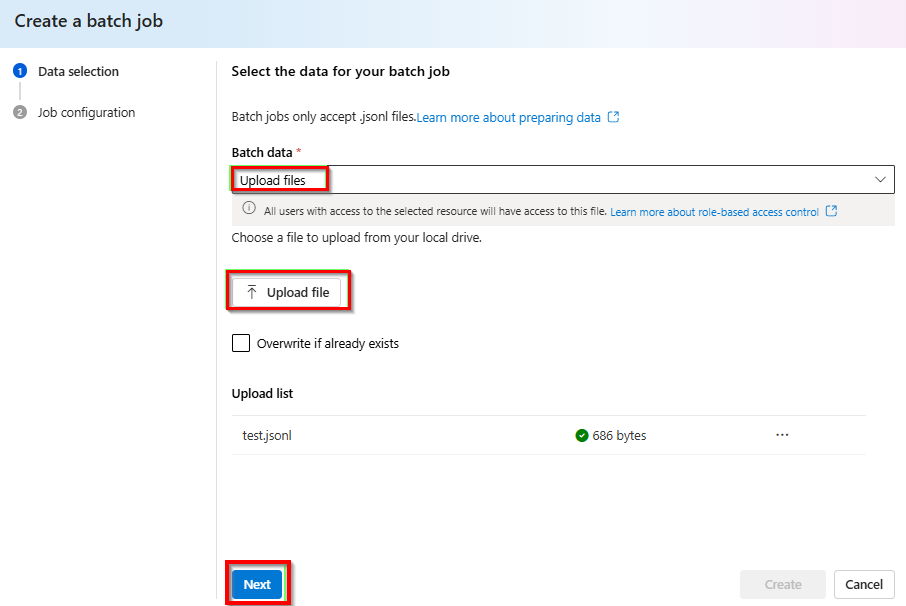


Create batch job
Select Create to start your batch job.

Track batch job progress
Once your job is created, you can monitor the job's progress by selecting the Job ID for the most recently created job. By default you will be taken to the status page for your most recently created batch job.

You can track job status for your job in the right-hand pane:

Retrieve batch job output file
Once your job has completed or reached a terminal state, it will generate an error file and an output file which can be downloaded for review by selecting the respective button with the downward arrow icon.

Cancel batch
Cancels an in-progress batch. The batch will be in status cancelling for up to 10 minutes, before changing to cancelled, where it will have partial results (if any) available in the output file.

Prerequisites
- An Azure subscription - Create one for free.
- Python 3.8 or later version
- The following Python library:
openai - Jupyter Notebooks
- An Azure OpenAI resource with a model of the deployment type
Global-Batchdeployed. You can refer to the resource creation and model deployment guide for help with this process.
The steps in this article are intended to be run sequentially in Jupyter Notebooks. For this reason we'll only instantiate the Azure OpenAI client once at the beginning of the examples. If you want to run a step out-of-order you'll often need to set up an Azure OpenAI client as part of that call.
Even if you already have the OpenAI Python library installed you might need to upgrade your installation to the latest version:
!pip install openai --upgrade
Preparing your batch file
Like fine-tuning, global batch uses files in JSON lines (.jsonl) format. Below are some example files with different types of supported content:
Input format
{"custom_id": "task-0", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was Microsoft founded?"}]}}
{"custom_id": "task-1", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was the first XBOX released?"}]}}
{"custom_id": "task-2", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "What is Altair Basic?"}]}}
The custom_id is required to allow you to identify which individual batch request corresponds to a given response. Responses won't be returned in identical order to the order defined in the .jsonl batch file.
model attribute should be set to match the name of the Global Batch deployment you wish to target for inference responses.
Important
The model attribute must be set to match the name of the Global Batch deployment you wish to target for inference responses. The same Global Batch model deployment name must be present on each line of the batch file. If you want to target a different deployment you must do so in a separate batch file/job.
For the best performance we recommend submitting large files for batch processing, rather than a large number of small files with only a few lines in each file.
Create input file
For this article we'll create a file named test.jsonl and will copy the contents from standard input code block above to the file. You'll need to modify and add your global batch deployment name to each line of the file. Save this file in the same directory that you're executing your Jupyter Notebook.
Upload batch file
Once your input file is prepared, you first need to upload the file to then be able to initiate a batch job. File upload can be done both programmatically or via the Azure AI Foundry portal. This example demonstrates uploading a file directly to your Azure OpenAI resource. Alternatively, you can configure Azure Blob Storage for Azure OpenAI Batch.
import os
from openai import AzureOpenAI
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
token_provider = get_bearer_token_provider(
DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default"
)
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
azure_ad_token_provider=token_provider,
api_version="2025-04-01-preview"
)
# Upload a file with a purpose of "batch"
file = client.files.create(
file=open("test.jsonl", "rb"),
purpose="batch",
extra_body={"expires_after":{"seconds": 1209600, "anchor": "created_at"}} # Optional you can set to a number between 1209600-2592000. This is equivalent to 14-30 days
)
print(file.model_dump_json(indent=2))
print(f"File expiration: {datetime.fromtimestamp(file.expires_at) if file.expires_at is not None else 'Not set'}")
file_id = file.id
By uncommenting and adding extra_body={"expires_after":{"seconds": 1209600, "anchor": "created_at"}} you're setting our upload file to expire in 14 days. There's a max limit of 500 batch files per resource when no expiration is set. By setting a value for expiration the number of batch files per resource is increased to 10,000 files per resource.
Output:
{
"id": "file-655111ec9cfc44489d9af078f08116ef",
"bytes": 176064,
"created_at": 1743391067,
"filename": "test.jsonl",
"object": "file",
"purpose": "batch",
"status": "processed",
"expires_at": 1744600667,
"status_details": null
}
File expiration: 2025-04-13 23:17:47
Create batch job
Once your file has uploaded successfully you can submit the file for batch processing.
# Submit a batch job with the file
batch_response = client.batches.create(
input_file_id=file_id,
endpoint="/chat/completions",
completion_window="24h",
extra_body={"output_expires_after":{"seconds": 1209600, "anchor": "created_at"}} # Optional you can set to a number between 1209600-2592000. This is equivalent to 14-30 days
)
# Save batch ID for later use
batch_id = batch_response.id
print(batch_response.model_dump_json(indent=2))
The default 500 max file limit per resource also applies to output files. Here you can uncomment this line to add extra_body={"output_expires_after":{"seconds": 1209600, "anchor": "created_at"}} so that your output files expire in 14 days. By setting a value for expiration the number of batch files per resource is increased to 10,000 files per resource.
Note
Currently the completion window must be set to 24h. If you set any other value than 24h your job will fail. Jobs taking longer than 24 hours will continue to execute until canceled.
Output:
{
"id": "batch_6caaf24d-54a5-46be-b1b7-518884fcbdde",
"completion_window": "24h",
"created_at": 1722476583,
"endpoint": null,
"input_file_id": "file-655111ec9cfc44489d9af078f08116ef",
"object": "batch",
"status": "validating",
"cancelled_at": null,
"cancelling_at": null,
"completed_at": null,
"error_file_id": null,
"errors": null,
"expired_at": null,
"expires_at": 1722562983,
"failed_at": null,
"finalizing_at": null,
"in_progress_at": null,
"metadata": null,
"output_file_id": null,
"request_counts": {
"completed": 0,
"failed": 0,
"total": 0
}
}
If your batch jobs are so large that you're hitting the enqueued token limit even after maxing out the quota for your deployment, certain regions now support a new fail fast feature that allows you to queue multiple batch jobs with exponential backoff so once one large batch job completes the next can be kicked off automatically. To learn more about what regions support this feature and how to adapt your code to take advantage of it, see queuing batch jobs.
Track batch job progress
Once you have created batch job successfully you can monitor its progress either in the Studio or programmatically. When checking batch job progress we recommend waiting at least 60 seconds in between each status call.
import time
import datetime
status = "validating"
while status not in ("completed", "failed", "canceled"):
time.sleep(60)
batch_response = client.batches.retrieve(batch_id)
status = batch_response.status
print(f"{datetime.datetime.now()} Batch Id: {batch_id}, Status: {status}")
if batch_response.status == "failed":
for error in batch_response.errors.data:
print(f"Error code {error.code} Message {error.message}")
Output:
2024-07-31 21:48:32.556488 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: validating
2024-07-31 21:49:39.221560 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: in_progress
2024-07-31 21:50:53.383138 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: in_progress
2024-07-31 21:52:07.274570 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: in_progress
2024-07-31 21:53:21.149501 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: finalizing
2024-07-31 21:54:34.572508 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: finalizing
2024-07-31 21:55:35.304713 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: finalizing
2024-07-31 21:56:36.531816 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: finalizing
2024-07-31 21:57:37.414105 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: completed
The following status values are possible:
| Status | Description |
|---|---|
validating |
The input file is being validated before the batch processing can begin. |
failed |
The input file has failed the validation process. |
in_progress |
The input file was successfully validated and the batch is currently running. |
finalizing |
The batch has completed and the results are being prepared. |
completed |
The batch has been completed and the results are ready. |
expired |
The batch wasn't able to be completed within the 24-hour time window. |
cancelling |
The batch is being cancelled (This may take up to 10 minutes to go into effect.) |
cancelled |
the batch was cancelled. |
To examine the job status details you can run:
print(batch_response.model_dump_json(indent=2))
Output:
{
"id": "batch_6caaf24d-54a5-46be-b1b7-518884fcbdde",
"completion_window": "24h",
"created_at": 1722476583,
"endpoint": null,
"input_file_id": "file-9f3a81d899b4442f98b640e4bc3535dd",
"object": "batch",
"status": "completed",
"cancelled_at": null,
"cancelling_at": null,
"completed_at": 1722477429,
"error_file_id": "file-c795ae52-3ba7-417d-86ec-07eebca57d0b",
"errors": null,
"expired_at": null,
"expires_at": 1722562983,
"failed_at": null,
"finalizing_at": 1722477177,
"in_progress_at": null,
"metadata": null,
"output_file_id": "file-3304e310-3b39-4e34-9f1c-e1c1504b2b2a",
"request_counts": {
"completed": 3,
"failed": 0,
"total": 3
}
}
Observe that there's both error_file_id and a separate output_file_id. Use the error_file_id to assist in debugging any issues that occur with your batch job.
Retrieve batch job output file
import json
output_file_id = batch_response.output_file_id
if not output_file_id:
output_file_id = batch_response.error_file_id
if output_file_id:
file_response = client.files.content(output_file_id)
raw_responses = file_response.text.strip().split('\n')
for raw_response in raw_responses:
json_response = json.loads(raw_response)
formatted_json = json.dumps(json_response, indent=2)
print(formatted_json)
Output:
For brevity, we're only including a single chat completion response of output. If you follow the steps in this article you should have three responses similar to the one below:
{
"custom_id": "task-0",
"response": {
"body": {
"choices": [
{
"content_filter_results": {
"hate": {
"filtered": false,
"severity": "safe"
},
"self_harm": {
"filtered": false,
"severity": "safe"
},
"sexual": {
"filtered": false,
"severity": "safe"
},
"violence": {
"filtered": false,
"severity": "safe"
}
},
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"message": {
"content": "Microsoft was founded on April 4, 1975, by Bill Gates and Paul Allen in Albuquerque, New Mexico.",
"role": "assistant"
}
}
],
"created": 1722477079,
"id": "chatcmpl-9rFGJ9dh08Tw9WRKqaEHwrkqRa4DJ",
"model": "gpt-4o-2024-05-13",
"object": "chat.completion",
"prompt_filter_results": [
{
"prompt_index": 0,
"content_filter_results": {
"hate": {
"filtered": false,
"severity": "safe"
},
"jailbreak": {
"filtered": false,
"detected": false
},
"self_harm": {
"filtered": false,
"severity": "safe"
},
"sexual": {
"filtered": false,
"severity": "safe"
},
"violence": {
"filtered": false,
"severity": "safe"
}
}
}
],
"system_fingerprint": "fp_a9bfe9d51d",
"usage": {
"completion_tokens": 24,
"prompt_tokens": 27,
"total_tokens": 51
}
},
"request_id": "660b7424-b648-4b67-addc-862ba067d442",
"status_code": 200
},
"error": null
}
Additional batch commands
Cancel batch
Cancels an in-progress batch. The batch will be in status cancelling for up to 10 minutes, before changing to cancelled, where it will have partial results (if any) available in the output file.
client.batches.cancel("batch_abc123") # set to your batch_id for the job you want to cancel
List batch
List batch jobs for a particular Azure OpenAI resource.
client.batches.list()
List methods in the Python library are paginated.
To list all jobs:
all_jobs = []
# Automatically fetches more pages as needed.
for job in client.batches.list(
limit=20,
):
# Do something with job here
all_jobs.append(job)
print(all_jobs)
List batch (Preview)
Use the REST API to list all batch jobs with additional sorting/filtering options.
In the examples below we're providing the generate_time_filter function to make constructing the filter easier. If you don't wish to use this function the format of the filter string would look like created_at gt 1728860560 and status eq 'Completed'.
import requests
import json
from datetime import datetime, timedelta
from azure.identity import DefaultAzureCredential
token_credential = DefaultAzureCredential()
token = token_credential.get_token('https://cognitiveservices.azure.com/.default')
endpoint = "https://{YOUR_RESOURCE_NAME}.openai.azure.com/"
api_version = "2025-03-01-preview"
url = f"{endpoint}openai/batches"
order = "created_at asc"
time_filter = lambda: generate_time_filter("past 8 hours")
# Additional filter examples:
#time_filter = lambda: generate_time_filter("past 1 day")
#time_filter = lambda: generate_time_filter("past 3 days", status="Completed")
def generate_time_filter(time_range, status=None):
now = datetime.now()
if 'day' in time_range:
days = int(time_range.split()[1])
start_time = now - timedelta(days=days)
elif 'hour' in time_range:
hours = int(time_range.split()[1])
start_time = now - timedelta(hours=hours)
else:
raise ValueError("Invalid time range format. Use 'past X day(s)' or 'past X hour(s)'")
start_timestamp = int(start_time.timestamp())
filter_string = f"created_at gt {start_timestamp}"
if status:
filter_string += f" and status eq '{status}'"
return filter_string
filter = time_filter()
headers = {'Authorization': 'Bearer ' + token.token}
params = {
"api-version": api_version,
"$filter": filter,
"$orderby": order
}
response = requests.get(url, headers=headers, params=params)
json_data = response.json()
if response.status_code == 200:
print(json.dumps(json_data, indent=2))
else:
print(f"Request failed with status code: {response.status_code}")
print(response.text)
Output:
{
"data": [
{
"cancelled_at": null,
"cancelling_at": null,
"completed_at": 1729011896,
"completion_window": "24h",
"created_at": 1729011128,
"error_file_id": "file-472c0626-4561-4327-9e4e-f41afbfb30e6",
"expired_at": null,
"expires_at": 1729097528,
"failed_at": null,
"finalizing_at": 1729011805,
"id": "batch_4ddc7b60-19a9-419b-8b93-b9a3274b33b5",
"in_progress_at": 1729011493,
"input_file_id": "file-f89384af0082485da43cb26b49dc25ce",
"errors": null,
"metadata": null,
"object": "batch",
"output_file_id": "file-62bebde8-e767-4cd3-a0a1-28b214dc8974",
"request_counts": {
"total": 3,
"completed": 2,
"failed": 1
},
"status": "completed",
"endpoint": "/chat/completions"
},
{
"cancelled_at": null,
"cancelling_at": null,
"completed_at": 1729016366,
"completion_window": "24h",
"created_at": 1729015829,
"error_file_id": "file-85ae1971-9957-4511-9eb4-4cc9f708b904",
"expired_at": null,
"expires_at": 1729102229,
"failed_at": null,
"finalizing_at": 1729016272,
"id": "batch_6287485f-50fc-4efa-bcc5-b86690037f43",
"in_progress_at": 1729016126,
"input_file_id": "file-686746fcb6bc47f495250191ffa8a28e",
"errors": null,
"metadata": null,
"object": "batch",
"output_file_id": "file-04399828-ae0b-4825-9b49-8976778918cb",
"request_counts": {
"total": 3,
"completed": 2,
"failed": 1
},
"status": "completed",
"endpoint": "/chat/completions"
}
],
"first_id": "batch_4ddc7b60-19a9-419b-8b93-b9a3274b33b5",
"has_more": false,
"last_id": "batch_6287485f-50fc-4efa-bcc5-b86690037f43"
}
Queueing batch jobs
If your batch jobs are so large that you're hitting the enqueued token limit even after maxing out the quota for your deployment, certain regions now support a new fail fast feature that allows you to queue multiple batch jobs with exponential backoff. Once one large batch job completes and your enqueued token quota is once again available, the next batch job can be created and kicked off automatically.
Old behavior:
- Large Batch job/s already running and using all available tokens for your deployment.
- New batch job submitted.
- New batch job goes into validation phase which can last up to a few minutes.
- Token count for new job is checked against currently available quota.
- New batch job fails with error reporting token limit exceeded.
New behavior:
- Large Batch job/s already running and using all available tokens for your deployment
- New batch job submitted
- Approximate token count of new job immediately compared against currently available batch quota job fails fast allowing you to more easily handle retries programmatically.
Region support
The following regions support the new fail fast behavior:
- australiaeast
- eastus
- germanywestcentral
- italynorth
- northcentralus
- polandcentral
- swedencentral
- switzerlandnorth
- eastus2
- westus
The code below demonstrates the basic mechanics of handling the fail fast behavior to allow automating retries and batch job queuing with exponential backoff.
Depending on the size of your batch jobs you may need to greatly increase the max_retries or alter this example further.
import time
from openai import BadRequestError
max_retries = 10
retries = 0
initial_delay = 5
delay = initial_delay
while True:
try:
batch_response = client.batches.create(
input_file_id=file_id,
endpoint="/chat/completions",
completion_window="24h",
)
# Save batch ID for later use
batch_id = batch_response.id
print(f"✅ Batch created successfully after {retries} retries")
print(batch_response.model_dump_json(indent=2))
break
except BadRequestError as e:
error_message = str(e)
# Check if it's a token limit error
if 'token_limit_exceeded' in error_message:
retries += 1
if retries >= max_retries:
print(f"❌ Maximum retries ({max_retries}) reached. Giving up.")
raise
print(f"⏳ Token limit exceeded. Waiting {delay} seconds before retry {retries}/{max_retries}...")
time.sleep(delay)
# Exponential backoff - increase delay for next attempt
delay *= 2
else:
# If it's a different error, raise it immediately
print(f"❌ Encountered non-token limit error: {error_message}")
raise
Output:
⏳ Token limit exceeded. Waiting 5 seconds before retry 1/10...
⏳ Token limit exceeded. Waiting 10 seconds before retry 2/10...
⏳ Token limit exceeded. Waiting 20 seconds before retry 3/10...
⏳ Token limit exceeded. Waiting 40 seconds before retry 4/10...
⏳ Token limit exceeded. Waiting 80 seconds before retry 5/10...
⏳ Token limit exceeded. Waiting 160 seconds before retry 6/10...
⏳ Token limit exceeded. Waiting 320 seconds before retry 7/10...
✅ Batch created successfully after 7 retries
{
"id": "batch_1e1e7b9f-d4b4-41fa-bd2e-8d2ec50fb8cc",
"completion_window": "24h",
"created_at": 1744402048,
"endpoint": "/chat/completions",
"input_file_id": "file-e2ba4ccaa4a348e0976c6fe3c018ea92",
"object": "batch",
"status": "validating",
"cancelled_at": null,
"cancelling_at": null,
"completed_at": null,
"error_file_id": "",
"errors": null,
"expired_at": null,
"expires_at": 1744488444,
"failed_at": null,
"finalizing_at": null,
"in_progress_at": null,
"metadata": null,
"output_file_id": "",
"request_counts": {
"completed": 0,
"failed": 0,
"total": 0
}
}
Prerequisites
- An Azure subscription - Create one for free.
- An Azure OpenAI resource with a model of the deployment type
Global-Batchdeployed. You can refer to the resource creation and model deployment guide for help with this process.
Preparing your batch file
Like fine-tuning, global batch uses files in JSON lines (.jsonl) format. Below are some example files with different types of supported content:
Input format
{"custom_id": "task-0", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was Microsoft founded?"}]}}
{"custom_id": "task-1", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was the first XBOX released?"}]}}
{"custom_id": "task-2", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "What is Altair Basic?"}]}}
The custom_id is required to allow you to identify which individual batch request corresponds to a given response. Responses won't be returned in identical order to the order defined in the .jsonl batch file.
model attribute should be set to match the name of the Global Batch deployment you wish to target for inference responses.
Important
The model attribute must be set to match the name of the Global Batch deployment you wish to target for inference responses. The same Global Batch model deployment name must be present on each line of the batch file. If you want to target a different deployment you must do so in a separate batch file/job.
For the best performance we recommend submitting large files for batch processing, rather than a large number of small files with only a few lines in each file.
Create input file
For this article we'll create a file named test.jsonl and will copy the contents from standard input code block above to the file. You'll need to modify and add your global batch deployment name to each line of the file.
Upload batch file
Once your input file is prepared, you first need to upload the file to then be able to initiate a batch job. File upload can be done both programmatically or via the Azure AI Foundry portal. This example demonstrates uploading a file directly to your Azure OpenAI resource. Alternatively, you can configure Azure Blob Storage for Azure OpenAI Batch.
Important
Use API keys with caution. Don't include the API key directly in your code, and never post it publicly. If you use an API key, store it securely in Azure Key Vault. For more information about using API keys securely in your apps, see API keys with Azure Key Vault.
For more information about AI services security, see Authenticate requests to Azure AI services.
curl -X POST https://YOUR_RESOURCE_NAME.openai.azure.com/openai/files?api-version=2025-03-01-preview \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=batch" \
-F "file=@C:\\batch\\test.jsonl;type=application/json" \
-F "expires_after.seconds=1209600" \
-F "expires_after.anchor=created_at"
The above code assumes a particular file path for your test.jsonl file. Adjust this file path as necessary for your local system.
By adding the optional "expires_after.seconds=1209600" and "expires_after.anchor=created_at" parameters you're setting your upload file to expire in 14 days. There's a max limit of 500 batch files per resource when no expiration is set. By setting a value for expiration the number of batch files per resource is increased to 10,000 files per resource. You can set to a number between 1209600-2592000. This is equivalent to 14-30 days.
Output:
{
"status": "processed",
"bytes": 817,
"purpose": "batch",
"filename": "test.jsonl",
"expires_at": 1744607747,
"id": "file-7733bc35e32841e297a62a9ee50b3461",
"created_at": 1743398147,
"object": "file"
}
Track file upload status
Depending on the size of your upload file it might take some time before it's fully uploaded and processed. To check on your file upload status run:
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/files/{file-id}?api-version=2025-03-01-preview \
-H "api-key: $AZURE_OPENAI_API_KEY"
Output:
{
"status": "processed",
"bytes": 686,
"purpose": "batch",
"filename": "test.jsonl",
"expires_at": 1744607747,
"id": "file-7733bc35e32841e297a62a9ee50b3461",
"created_at": 1721408291,
"object": "file"
}
Create batch job
Once your file has uploaded successfully you can submit the file for batch processing.
curl -X POST https://YOUR_RESOURCE_NAME.openai.azure.com/openai/batches?api-version=2025-03-01-preview \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"input_file_id": "file-abc123",
"endpoint": "/chat/completions",
"completion_window": "24h",
"output_expires_after": {
"seconds": 1209600
},
"anchor": "created_at"
}'
The default 500 max file limit per resource also applies to output files. Here you can optionally add "output_expires_after":{"seconds": 1209600}, and "anchor": "created_at" so that your output files expire in 14 days. By setting a value for expiration the number of batch files per resource is increased to 10,000 files per resource.
Note
Currently the completion window must be set to 24h. If you set any other value than 24h your job will fail. Jobs taking longer than 24 hours will continue to execute until canceled.
Output:
{
"cancelled_at": null,
"cancelling_at": null,
"completed_at": null,
"completion_window": "24h",
"created_at": "2024-07-19T17:13:57.2491382+00:00",
"error_file_id": null,
"expired_at": null,
"expires_at": "2024-07-20T17:13:57.1918498+00:00",
"failed_at": null,
"finalizing_at": null,
"id": "batch_fe3f047a-de39-4068-9008-346795bfc1db",
"in_progress_at": null,
"input_file_id": "file-21006e70789246658b86a1fc205899a4",
"errors": null,
"metadata": null,
"object": "batch",
"output_file_id": null,
"request_counts": {
"total": null,
"completed": null,
"failed": null
},
"status": "Validating"
}
Track batch job progress
Once you have created batch job successfully you can monitor its progress either in the Studio or programmatically. When checking batch job progress we recommend waiting at least 60 seconds in between each status call.
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/batches/{batch_id}?api-version=2025-03-01-preview \
-H "api-key: $AZURE_OPENAI_API_KEY"
Output:
{
"cancelled_at": null,
"cancelling_at": null,
"completed_at": null,
"completion_window": "24h",
"created_at": "2024-07-19T17:33:29.1619286+00:00",
"error_file_id": null,
"expired_at": null,
"expires_at": "2024-07-20T17:33:29.1578141+00:00",
"failed_at": null,
"finalizing_at": null,
"id": "batch_e0a7ee28-82c4-46a2-a3a0-c13b3c4e390b",
"in_progress_at": null,
"input_file_id": "file-c55ec4e859d54738a313d767718a2ac5",
"errors": null,
"metadata": null,
"object": "batch",
"output_file_id": null,
"request_counts": {
"total": null,
"completed": null,
"failed": null
},
"status": "Validating"
}
The following status values are possible:
| Status | Description |
|---|---|
validating |
The input file is being validated before the batch processing can begin. |
failed |
The input file has failed the validation process. |
in_progress |
The input file was successfully validated and the batch is currently running. |
finalizing |
The batch has completed and the results are being prepared. |
completed |
The batch has been completed and the results are ready. |
expired |
The batch wasn't able to be completed within the 24-hour time window. |
cancelling |
The batch is being cancelled (This can take up to 10 minutes to go into effect.) |
cancelled |
the batch was cancelled. |
Retrieve batch job output file
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/files/{output_file_id}/content?api-version=2025-03-01-preview \
-H "api-key: $AZURE_OPENAI_API_KEY" > batch_output.jsonl
Additional batch commands
Cancel batch
Cancels an in-progress batch. The batch will be in status cancelling for up to 10 minutes, before changing to cancelled, where it will have partial results (if any) available in the output file.
curl -X POST https://YOUR_RESOURCE_NAME.openai.azure.com/openai/batches/{batch_id}/cancel?api-version=2025-03-01-preview \
-H "api-key: $AZURE_OPENAI_API_KEY"
List batch
List existing batch jobs for a given Azure OpenAI resource.
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/batches?api-version=2025-03-01-preview \
-H "api-key: $AZURE_OPENAI_API_KEY"
The list API call is paginated. The response contains a boolean has_more to indicate when there are more results to iterate through.
List batch (Preview)
Use the REST API to list all batch jobs with additional sorting/filtering options.
curl "YOUR_RESOURCE_NAME.openai.azure.com/batches?api-version=2025-03-01-preview&$filter=created_at%20gt%201728773533%20and%20created_at%20lt%201729032733%20and%20status%20eq%20'Completed'&$orderby=created_at%20asc" \
-H "api-key: $AZURE_OPENAI_API_KEY"
To avoid the error URL rejected: Malformed input to a URL function spaces are replaced with %20.
Batch limits
| Limit Name | Limit Value |
|---|---|
| Max files per resource | 500 |
| Max input file size | 200 MB |
| Max requests per file | 100,000 |
Batch quota
The table shows the batch quota limit. Quota values for global batch are represented in terms of enqueued tokens. When you submit a file for batch processing the number of tokens present in the file are counted. Until the batch job reaches a terminal state, those tokens will count against your total enqueued token limit.
Global batch
| Model | Enterprise agreement | Default | Monthly credit card based subscriptions | MSDN subscriptions | Azure for Students, Free Trials |
|---|---|---|---|---|---|
gpt-4.1 |
5 B | 200 M | 50 M | 90 K | N/A |
gpt-4.1 mini |
15B | 1B | 50M | 90k | N/A |
gpt-4.1-nano |
15 B | 1 B | 50 M | 90 K | N/A |
gpt-4o |
5 B | 200 M | 50 M | 90 K | N/A |
gpt-4o-mini |
15 B | 1 B | 50 M | 90 K | N/A |
gpt-4-turbo |
300 M | 80 M | 40 M | 90 K | N/A |
gpt-4 |
150 M | 30 M | 5 M | 100 K | N/A |
gpt-35-turbo |
10 B | 1 B | 100 M | 2 M | 50 K |
o3-mini |
15 B | 1 B | 50 M | 90 K | N/A |
o4-mini |
15 B | 1 B | 50 M | 90 K | N/A |
B = billion | M = million | K = thousand
Data zone batch
| Model | Enterprise agreement | Default | Monthly credit card based subscriptions | MSDN subscriptions | Azure for Students, Free Trials |
|---|---|---|---|---|---|
gpt-4.1 |
500 M | 30 M | 30 M | 90 K | N/A |
gpt-4.1-mini |
1.5 B | 100 M | 50 M | 90 K | N/A |
gpt-4o |
500 M | 30 M | 30 M | 90 K | N/A |
gpt-4o-mini |
1.5 B | 100 M | 50 M | 90 K | N/A |
o3-mini |
1.5 B | 100 M | 50 M | 90 K | N/A |
Batch object
| Property | Type | Definition |
|---|---|---|
id |
string | |
object |
string | batch |
endpoint |
string | The API endpoint used by the batch |
errors |
object | |
input_file_id |
string | The ID of the input file for the batch |
completion_window |
string | The time frame within which the batch should be processed |
status |
string | The current status of the batch. Possible values: validating, failed, in_progress, finalizing, completed, expired, cancelling, cancelled. |
output_file_id |
string | The ID of the file containing the outputs of successfully executed requests. |
error_file_id |
string | The ID of the file containing the outputs of requests with errors. |
created_at |
integer | A timestamp when this batch was created (in unix epochs). |
in_progress_at |
integer | A timestamp when this batch started progressing (in unix epochs). |
expires_at |
integer | A timestamp when this batch will expire (in unix epochs). |
finalizing_at |
integer | A timestamp when this batch started finalizing (in unix epochs). |
completed_at |
integer | A timestamp when this batch started finalizing (in unix epochs). |
failed_at |
integer | A timestamp when this batch failed (in unix epochs) |
expired_at |
integer | A timestamp when this batch expired (in unix epochs). |
cancelling_at |
integer | A timestamp when this batch started cancelling (in unix epochs). |
cancelled_at |
integer | A timestamp when this batch was cancelled (in unix epochs). |
request_counts |
object | Object structure:total integer The total number of requests in the batch. completed integer The number of requests in the batch that have been completed successfully. failed integer The number of requests in the batch that have failed. |
metadata |
map | A set of key-value pairs that can be attached to the batch. This property can be useful for storing additional information about the batch in a structured format. |
Frequently asked questions (FAQ)
Can images be used with the batch API?
This capability is limited to certain multi-modal models. Currently only GPT-4o support images as part of batch requests. Images can be provided as input either via image url or a base64 encoded representation of the image. Images for batch are currently not supported with GPT-4 Turbo.
Can I use the batch API with fine-tuned models?
This is currently not supported.
Can I use the batch API for embeddings models?
This is currently not supported.
Does content filtering work with Global Batch deployment?
Yes. Similar to other deployment types, you can create content filters and associate them with the Global Batch deployment type.
Can I request additional quota?
Yes, from the quota page in the Azure AI Foundry portal. Default quota allocation can be found in the quota and limits article.
What happens if the API doesn't complete my request within the 24 hour time frame?
We aim to process these requests within 24 hours; we don't expire the jobs that take longer. You can cancel the job anytime. When you cancel the job, any remaining work is canceled and any already completed work is returned. You'll be charged for any completed work.
How many requests can I queue using batch?
There's no fixed limit on the number of requests you can batch, however, it will depend on your enqueued token quota. Your enqueued token quota includes the maximum number of input tokens you can enqueue at one time.
Once your batch request is completed, your batch rate limit is reset, as your input tokens are cleared. The limit depends on the number of global requests in the queue. If the Batch API queue processes your batches quickly, your batch rate limit is reset more quickly.
Troubleshooting
A job is successful when status is Completed. Successful jobs will still generate an error_file_id, but it will be associated with an empty file with zero bytes.
When a job failure occurs, you'll find details about the failure in the errors property:
"value": [
{
"id": "batch_80f5ad38-e05b-49bf-b2d6-a799db8466da",
"completion_window": "24h",
"created_at": 1725419394,
"endpoint": "/chat/completions",
"input_file_id": "file-c2d9a7881c8a466285e6f76f6321a681",
"object": "batch",
"status": "failed",
"cancelled_at": null,
"cancelling_at": null,
"completed_at": 1725419955,
"error_file_id": "file-3b0f9beb-11ce-4796-bc31-d54e675f28fb",
"errors": {
"object": “list”,
"data": [
{
"code": "empty_file",
"message": "The input file is empty. Please ensure that the batch contains at least one request."
}
]
},
"expired_at": null,
"expires_at": 1725505794,
"failed_at": null,
"finalizing_at": 1725419710,
"in_progress_at": 1725419572,
"metadata": null,
"output_file_id": "file-ef12af98-dbbc-4d27-8309-2df57feed572",
"request_counts": {
"total": 10,
"completed": null,
"failed": null
},
}
Error codes
| Error code | Definition |
|---|---|
invalid_json_line |
A line (or multiple) in your input file wasn't able to be parsed as valid json. Please ensure no typos, proper opening and closing brackets, and quotes as per JSON standard, and resubmit the request. |
too_many_tasks |
The number of requests in the input file exceeds the maximum allowed value of 100,000. Please ensure your total requests are under 100,000 and resubmit the job. |
url_mismatch |
Either a row in your input file has a URL that doesn’t match the rest of the rows, or the URL specified in the input file doesn’t match the expected endpoint URL. Please ensure all request URLs are the same, and that they match the endpoint URL associated with your Azure OpenAI deployment. |
model_not_found |
The Azure OpenAI model deployment name that was specified in the model property of the input file wasn't found.Please ensure this name points to a valid Azure OpenAI model deployment. |
duplicate_custom_id |
The custom ID for this request is a duplicate of the custom ID in another request. |
empty_batch |
Please check your input file to ensure that the custom ID parameter is unique for each request in the batch. |
model_mismatch |
The Azure OpenAI model deployment name that was specified in the model property of this request in the input file doesn't match the rest of the file.Please ensure that all requests in the batch point to the same Azure OpenAI in Azure AI Foundry Models model deployment in the model property of the request. |
invalid_request |
The schema of the input line is invalid or the deployment SKU is invalid. Please ensure the properties of the request in your input file match the expected input properties, and that the Azure OpenAI deployment SKU is globalbatch for batch API requests. |
input_modified |
Blob input has been modified after the batch job has been submitted. |
input_no_permissions |
It's not possible to access the input blob. Please check permissions and network access between the Azure OpenAI account and Azure Storage account. |
Known issues
Resources deployed with Azure CLI won't work out-of-box with Azure OpenAI global batch. This is due to an issue where resources deployed using this method have endpoint subdomains that don't follow the
https://your-resource-name.openai.azure.compattern. A workaround for this issue is to deploy a new Azure OpenAI resource using one of the other common deployment methods which will properly handle the subdomain setup as part of the deployment process.UTF-8-BOM encoded
jsonlfiles aren't supported. JSON lines files should be encoded using UTF-8. Use of Byte-Order-Mark (BOM) encoded files isn't officially supported by the JSON RFC spec, and Azure OpenAI will currently treat BOM encoded files as invalid. A UTF-8-BOM encoded file will currently return the generic error message: "Validation failed: A valid model deployment name couldn't be extracted from the input file. Please ensure that each row in the input file has a valid deployment name specified in the 'model' field, and that the deployment name is consistent across all rows."
See also
- Learn more about Azure OpenAI deployment types
- Learn more about Azure OpenAI quotas and limits