你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
参考文档 | 包 (NuGet) | GitHub 上的其他示例
本快速入门介绍处理自定义关键字的基础知识。 关键字是使产品能够被语音激活的单词或短语。 你将在 Speech Studio 中创建关键字模型。 然后导出一个模型文件,在应用程序中与语音 SDK 一起使用。
先决条件
- Azure 订阅。 可以免费创建一个帐户。
- 在 Azure 门户中创建用于语音的 AI Foundry 资源。
- 获取语音资源密钥和区域。 部署语音资源后,选择“转到资源”以查看和管理密钥。
在 Speech Studio 中创建关键字
在使用自定义关键字之前,需使用 Speech Studio 上的自定义关键字页来创建关键字。 在你提供关键字后,它将生成一个 .table 文件,该文件可用于语音 SDK。
重要
自定义关键字模型以及生成的 .table 文件只能在 Speech Studio 中创建。
不能通过 SDK 或 REST 调用创建自定义关键字。
转到 Speech Studio 并登录。 如果没有语音订阅,请转到创建语音服务。
在自定义关键字页面上,选择“创建新项目”。
为自定义关键字项目输入“名称”、“说明”和“语言” 。 只能为每个项目选择一种语言,目前仅支持英语(美国)和中文(普通话、简体)。
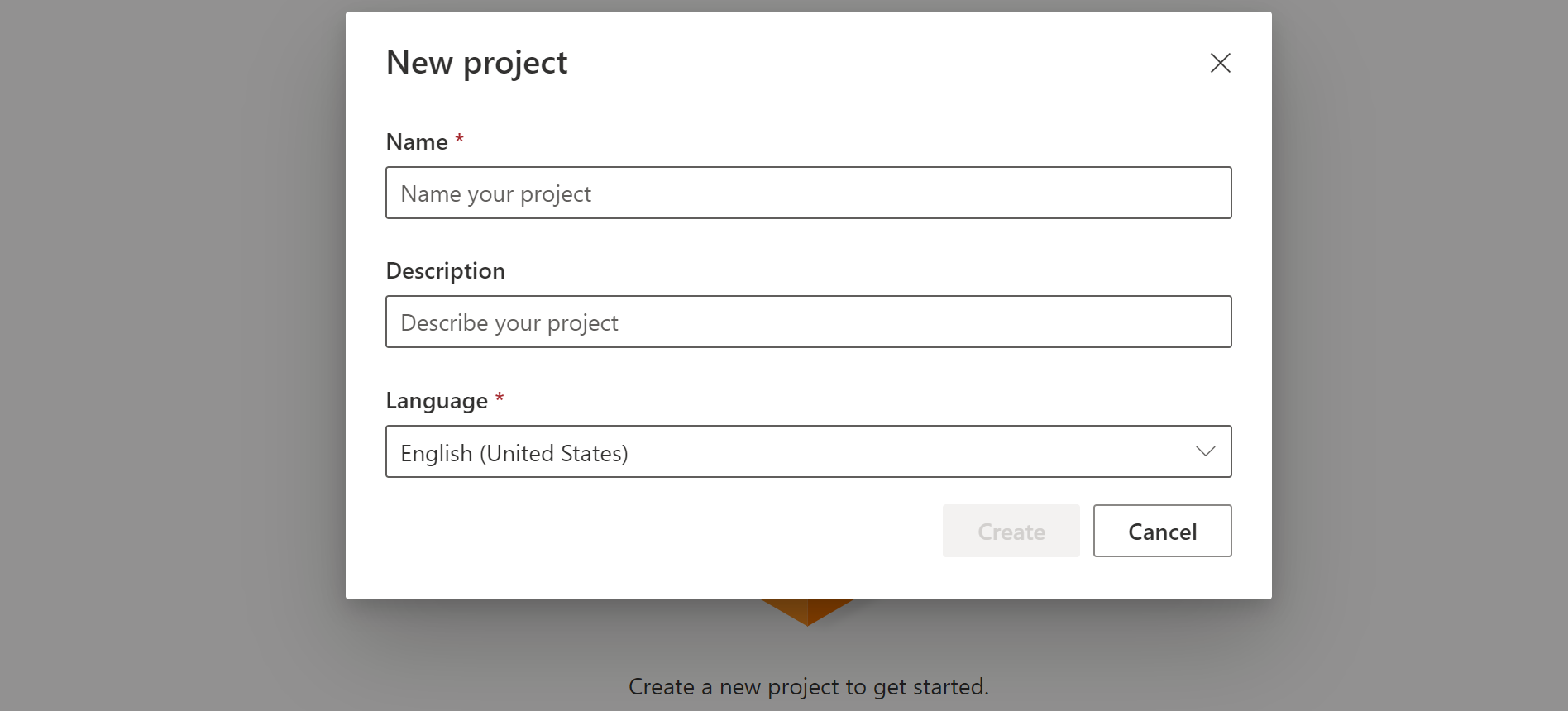
从列表中选择项目的名称。
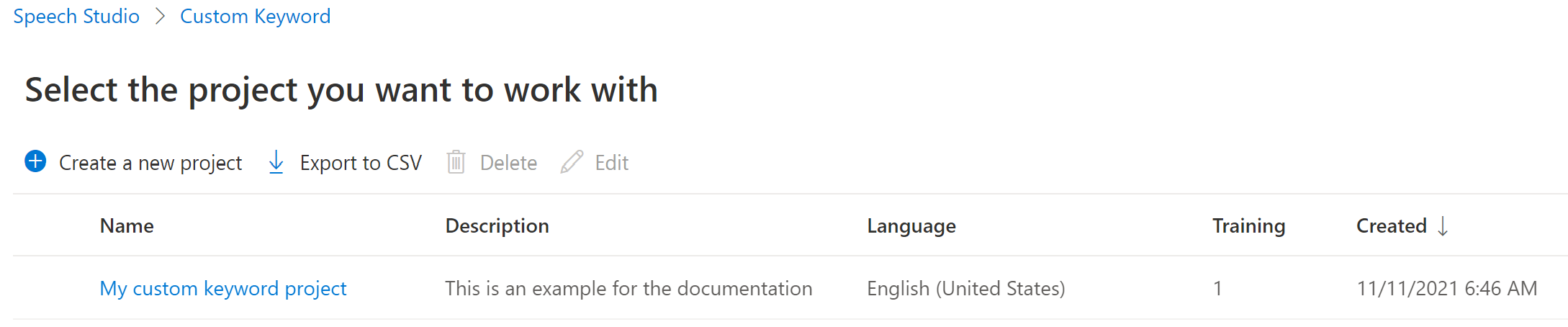
若要为虚拟助理创建自定义关键字,请选择“创建新模型”。
输入模型的名称、说明和所选的关键字,然后选择“下一步” 。 有关如何选择有效关键字,请参阅指南。
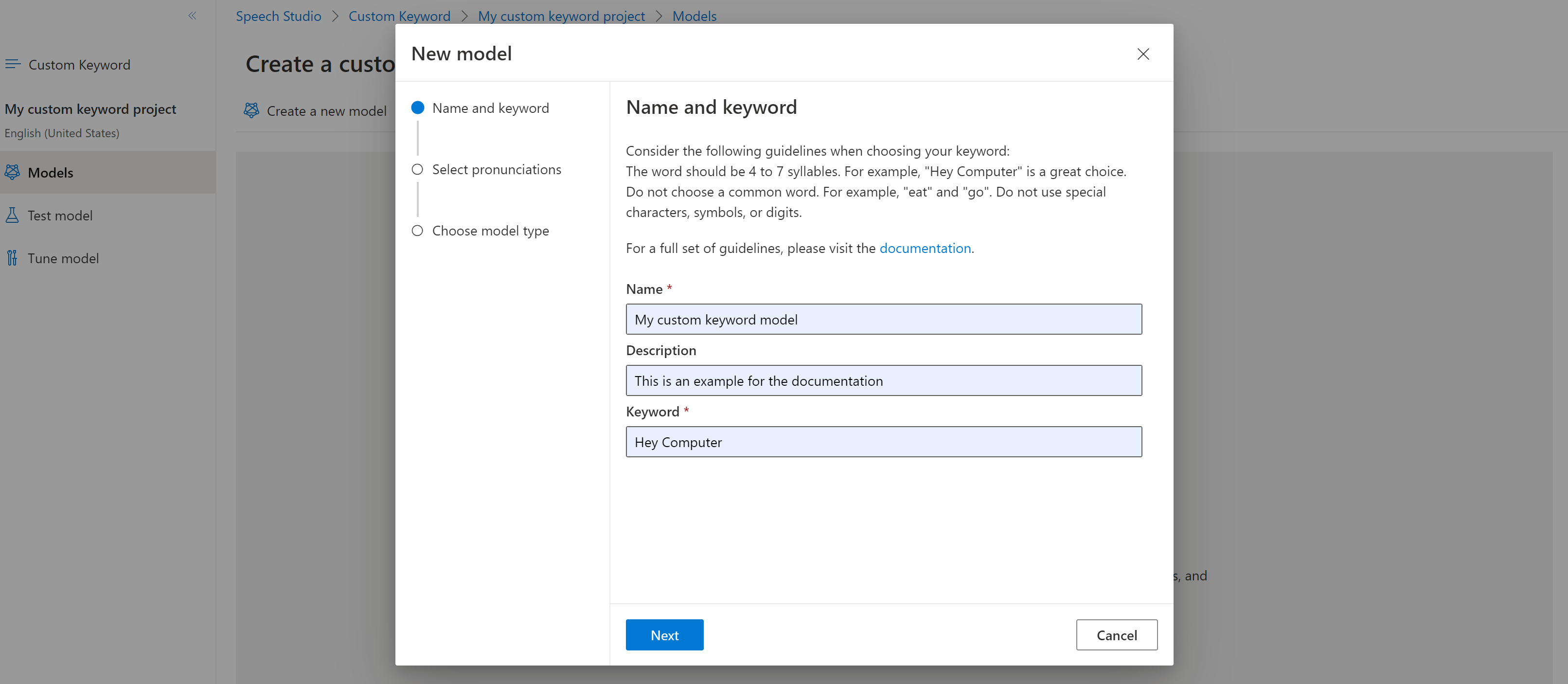
门户为关键字创建候选发音。 通过选择播放按钮收听每个候选发音,并删除任何不正确发音旁边的复选标记。选择与你希望用户说出关键字的方式相对应的所有发音,然后选择“下一步”以开始生成关键字模型。

选择模型类型,然后选择“创建”。 可以在关键字识别区域支持文档中查看支持高级模型类型的区域列表。
由于需求量很大,训练基础模型可能需要几个小时。 训练高级模型可能需要一天时间才能完成。 训练完成后,状态将从“正在处理”更改为“成功”。
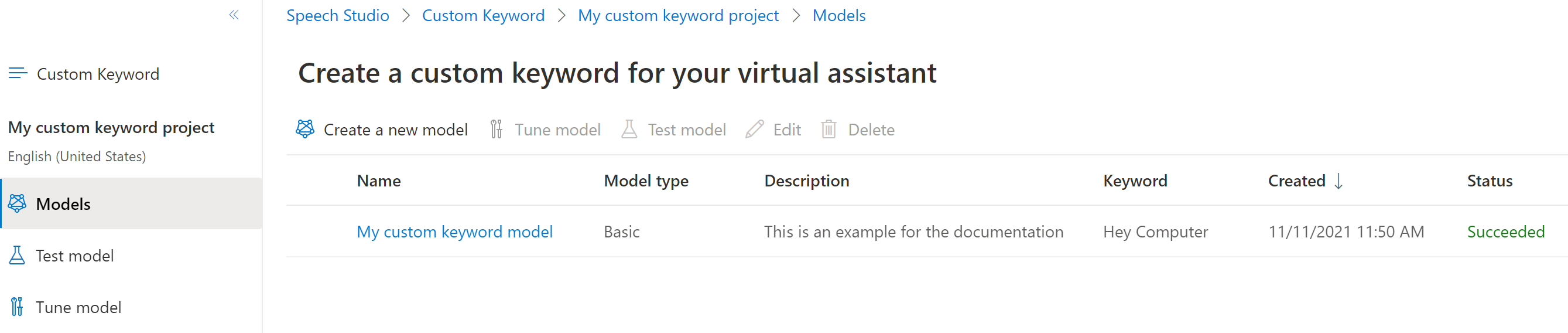
从左侧的可折叠菜单中,选择“优化”以获得优化和下载模型的选项。 下载的文件是
.zip存档。 提取存档,将看到一个扩展名为.table的文件。 你将.table文件与 SDK 一起使用,因此请务必记下其路径。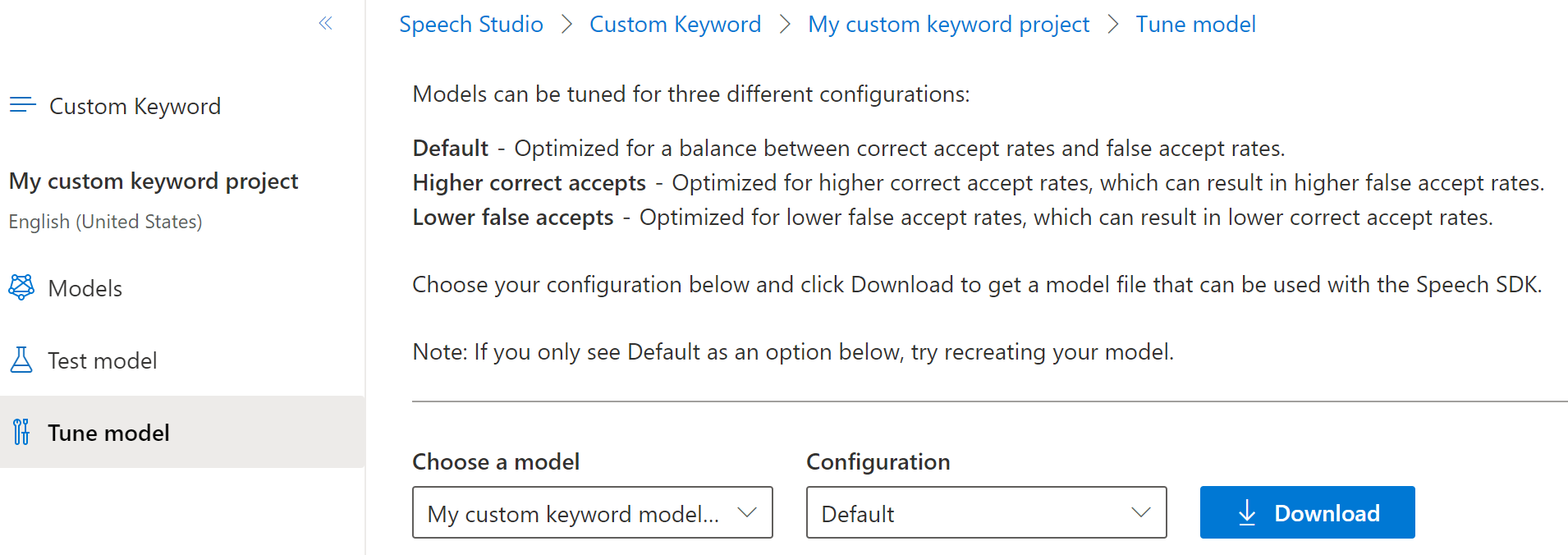
结合使用关键字模型和语音 SDK
首先,使用 FromFile() 静态函数加载关键字模型文件,该函数将返回一个 KeywordRecognitionModel。 使用从 Speech Studio 下载的 .table 文件的路径。 此外,使用默认麦克风创建一个 AudioConfig,然后使用音频配置实例化一个新的 KeywordRecognizer。
using Microsoft.CognitiveServices.Speech;
using Microsoft.CognitiveServices.Speech.Audio;
var keywordModel = KeywordRecognitionModel.FromFile("your/path/to/Activate_device.table");
using var audioConfig = AudioConfig.FromDefaultMicrophoneInput();
using var keywordRecognizer = new KeywordRecognizer(audioConfig);
重要
如果希望通过 AudioConfig.fromStreamInput() 方法直接使用音频样本测试关键字模型,请确保使用的样本在第一个关键字之前至少有 1.5 秒的静音。 这是为了在检测第一个关键字之前留出足够的时间让关键字识别引擎完成初始化并进入侦听状态。
接下来,通过传递模型对象调用 RecognizeOnceAsync() 来运行关键字识别。 此方法会启动一个关键字识别会话,此会话将一直持续到关键字被识别为止。 因此,你通常在多线程应用程序中使用此设计模式,或者在可能无限期等待唤醒词的用例中使用此设计模式。
KeywordRecognitionResult result = await keywordRecognizer.RecognizeOnceAsync(keywordModel);
注意
此处显示的示例使用本地关键字识别,因为它不需要将 SpeechConfig 对象用于身份验证上下文,也不会与后端联系。
连续识别
语音 SDK 中的其他类通过关键字识别支持连续识别(用于语音和意向识别)。 SDK 使你可以使用通常用于连续识别的那些代码,并能够为关键字模型引用 .table 文件。
对于语音转文本,请按照识别语音指南中所示的设计模式来设置连续识别。 然后,将对 recognizer.StartContinuousRecognitionAsync() 的调用替换为对 recognizer.StartKeywordRecognitionAsync(KeywordRecognitionModel) 的调用,并传递 KeywordRecognitionModel 对象。 若要停止通过关键字识别进行连续识别,请使用 recognizer.StopKeywordRecognitionAsync() 而不是 recognizer.StopContinuousRecognitionAsync()。
意向识别对 StartKeywordRecognitionAsync 和 StopKeywordRecognitionAsync 函数使用相同的模式。
参考文档 | 包 (NuGet) | GitHub 上的其他示例
适用于 C++ 的语音 SDK 支持关键字识别,但我们尚未提供有关此内容的指南。 请选择其他编程语言开始了解相关概念,或参阅本文开头链接的 C++ 引用和示例。
- Azure 订阅。 可以免费创建一个帐户。
- 在 Azure 门户中创建用于语音的 AI Foundry 资源。
- 获取语音资源密钥和区域。 部署语音资源后,选择“转到资源”以查看和管理密钥。
在 Speech Studio 中创建关键字
在使用自定义关键字之前,需使用 Speech Studio 上的自定义关键字页来创建关键字。 在你提供关键字后,它将生成一个 .table 文件,该文件可用于语音 SDK。
重要
自定义关键字模型以及生成的 .table 文件只能在 Speech Studio 中创建。
不能通过 SDK 或 REST 调用创建自定义关键字。
转到 Speech Studio 并登录。 如果没有语音订阅,请转到创建语音服务。
在自定义关键字页面上,选择“创建新项目”。
为自定义关键字项目输入“名称”、“说明”和“语言” 。 只能为每个项目选择一种语言,目前仅支持英语(美国)和中文(普通话、简体)。
从列表中选择项目的名称。
若要为虚拟助理创建自定义关键字,请选择“创建新模型”。
输入模型的名称、说明和所选的关键字,然后选择“下一步” 。 有关如何选择有效关键字,请参阅指南。
门户为关键字创建候选发音。 通过选择播放按钮收听每个候选发音,并删除任何不正确发音旁边的复选标记。选择与你希望用户说出关键字的方式相对应的所有发音,然后选择“下一步”以开始生成关键字模型。
选择模型类型,然后选择“创建”。 可以在关键字识别区域支持文档中查看支持高级模型类型的区域列表。
由于需求量很大,训练基础模型可能需要几个小时。 训练高级模型可能需要一天时间才能完成。 训练完成后,状态将从“正在处理”更改为“成功”。
从左侧的可折叠菜单中,选择“优化”以获得优化和下载模型的选项。 下载的文件是
.zip存档。 提取存档,将看到一个扩展名为.table的文件。 你将.table文件与 SDK 一起使用,因此请务必记下其路径。
结合使用关键字模型和语音 SDK
请参阅参考文档,了解如何将自定义关键字模型与 Go SDK 配合使用。
适用于 Java 的语音 SDK 支持关键字识别,但我们尚未提供有关此内容的指南。 请选择其他编程语言开始了解相关概念,或参阅本文开头链接的 Java 引用和示例。
参考文档 | 包 (npm) | GitHub 上的其他示例 | 库源代码
适用于 JavaScript 的语音 SDK 不支持关键字识别。 请选择其他编程语言,或本文开头链接的 JavaScript 引用和示例。
参考文档 | 包(下载) | GitHub 上的其他示例
本快速入门介绍处理自定义关键字的基础知识。 关键字是使产品能够被语音激活的单词或短语。 你将在 Speech Studio 中创建关键字模型。 然后导出一个模型文件,在应用程序中与语音 SDK 一起使用。
先决条件
- Azure 订阅。 可以免费创建一个帐户。
- 在 Azure 门户中创建用于语音的 AI Foundry 资源。
- 获取语音资源密钥和区域。 部署语音资源后,选择“转到资源”以查看和管理密钥。
在 Speech Studio 中创建关键字
在使用自定义关键字之前,需使用 Speech Studio 上的自定义关键字页来创建关键字。 在你提供关键字后,它将生成一个 .table 文件,该文件可用于语音 SDK。
重要
自定义关键字模型以及生成的 .table 文件只能在 Speech Studio 中创建。
不能通过 SDK 或 REST 调用创建自定义关键字。
转到 Speech Studio 并登录。 如果没有语音订阅,请转到创建语音服务。
在自定义关键字页面上,选择“创建新项目”。
为自定义关键字项目输入“名称”、“说明”和“语言” 。 只能为每个项目选择一种语言,目前仅支持英语(美国)和中文(普通话、简体)。
从列表中选择项目的名称。
若要为虚拟助理创建自定义关键字,请选择“创建新模型”。
输入模型的名称、说明和所选的关键字,然后选择“下一步” 。 有关如何选择有效关键字,请参阅指南。
门户为关键字创建候选发音。 通过选择播放按钮收听每个候选发音,并删除任何不正确发音旁边的复选标记。选择与你希望用户说出关键字的方式相对应的所有发音,然后选择“下一步”以开始生成关键字模型。
选择模型类型,然后选择“创建”。 可以在关键字识别区域支持文档中查看支持高级模型类型的区域列表。
由于需求量很大,训练基础模型可能需要几个小时。 训练高级模型可能需要一天时间才能完成。 训练完成后,状态将从“正在处理”更改为“成功”。
从左侧的可折叠菜单中,选择“优化”以获得优化和下载模型的选项。 下载的文件是
.zip存档。 提取存档,将看到一个扩展名为.table的文件。 你将.table文件与 SDK 一起使用,因此请务必记下其路径。
结合使用关键字模型和语音 SDK
请参阅 GitHub 上的示例,了解如何将自定义关键字模型与 Objective C SDK 配合使用。
参考文档 | 包(下载) | GitHub 上的其他示例
本快速入门介绍处理自定义关键字的基础知识。 关键字是使产品能够被语音激活的单词或短语。 你将在 Speech Studio 中创建关键字模型。 然后导出一个模型文件,在应用程序中与语音 SDK 一起使用。
先决条件
- Azure 订阅。 可以免费创建一个帐户。
- 在 Azure 门户中创建用于语音的 AI Foundry 资源。
- 获取语音资源密钥和区域。 部署语音资源后,选择“转到资源”以查看和管理密钥。
在 Speech Studio 中创建关键字
在使用自定义关键字之前,需使用 Speech Studio 上的自定义关键字页来创建关键字。 在你提供关键字后,它将生成一个 .table 文件,该文件可用于语音 SDK。
重要
自定义关键字模型以及生成的 .table 文件只能在 Speech Studio 中创建。
不能通过 SDK 或 REST 调用创建自定义关键字。
转到 Speech Studio 并登录。 如果没有语音订阅,请转到创建语音服务。
在自定义关键字页面上,选择“创建新项目”。
为自定义关键字项目输入“名称”、“说明”和“语言” 。 只能为每个项目选择一种语言,目前仅支持英语(美国)和中文(普通话、简体)。
从列表中选择项目的名称。
若要为虚拟助理创建自定义关键字,请选择“创建新模型”。
输入模型的名称、说明和所选的关键字,然后选择“下一步” 。 有关如何选择有效关键字,请参阅指南。
门户为关键字创建候选发音。 通过选择播放按钮收听每个候选发音,并删除任何不正确发音旁边的复选标记。选择与你希望用户说出关键字的方式相对应的所有发音,然后选择“下一步”以开始生成关键字模型。
选择模型类型,然后选择“创建”。 可以在关键字识别区域支持文档中查看支持高级模型类型的区域列表。
由于需求量很大,训练基础模型可能需要几个小时。 训练高级模型可能需要一天时间才能完成。 训练完成后,状态将从“正在处理”更改为“成功”。
从左侧的可折叠菜单中,选择“优化”以获得优化和下载模型的选项。 下载的文件是
.zip存档。 提取存档,将看到一个扩展名为.table的文件。 你将.table文件与 SDK 一起使用,因此请务必记下其路径。
结合使用关键字模型和语音 SDK
请参阅 GitHub 上的示例,了解如何将自定义关键字模型与 Objective C SDK 配合使用。 虽然我们目前没有用于奇偶校验的 Swift 示例,但概念是相似的。
注意
如果要在 iOS 上的 Swift 应用程序中使用关键字识别,请注意,在 Speech Studio 中创建的新关键字模型需要使用来自 https://aka.ms/csspeech/iosbinaryembedded 的语音 SDK xcframework 捆绑包或项目中的 MicrosoftCognitiveServicesSpeechEmbedded-iOS Pod。
参考文档 | 包 (PyPi) | GitHub 上的其他示例
本快速入门介绍处理自定义关键字的基础知识。 关键字是使产品能够被语音激活的单词或短语。 你将在 Speech Studio 中创建关键字模型。 然后导出一个模型文件,在应用程序中与语音 SDK 一起使用。
先决条件
- Azure 订阅。 可以免费创建一个帐户。
- 在 Azure 门户中创建用于语音的 AI Foundry 资源。
- 获取语音资源密钥和区域。 部署语音资源后,选择“转到资源”以查看和管理密钥。
在 Speech Studio 中创建关键字
在使用自定义关键字之前,需使用 Speech Studio 上的自定义关键字页来创建关键字。 在你提供关键字后,它将生成一个 .table 文件,该文件可用于语音 SDK。
重要
自定义关键字模型以及生成的 .table 文件只能在 Speech Studio 中创建。
不能通过 SDK 或 REST 调用创建自定义关键字。
转到 Speech Studio 并登录。 如果没有语音订阅,请转到创建语音服务。
在自定义关键字页面上,选择“创建新项目”。
为自定义关键字项目输入“名称”、“说明”和“语言” 。 只能为每个项目选择一种语言,目前仅支持英语(美国)和中文(普通话、简体)。
从列表中选择项目的名称。
若要为虚拟助理创建自定义关键字,请选择“创建新模型”。
输入模型的名称、说明和所选的关键字,然后选择“下一步” 。 有关如何选择有效关键字,请参阅指南。
门户为关键字创建候选发音。 通过选择播放按钮收听每个候选发音,并删除任何不正确发音旁边的复选标记。选择与你希望用户说出关键字的方式相对应的所有发音,然后选择“下一步”以开始生成关键字模型。
选择模型类型,然后选择“创建”。 可以在关键字识别区域支持文档中查看支持高级模型类型的区域列表。
由于需求量很大,训练基础模型可能需要几个小时。 训练高级模型可能需要一天时间才能完成。 训练完成后,状态将从“正在处理”更改为“成功”。
从左侧的可折叠菜单中,选择“优化”以获得优化和下载模型的选项。 下载的文件是
.zip存档。 提取存档,将看到一个扩展名为.table的文件。 你将.table文件与 SDK 一起使用,因此请务必记下其路径。
结合使用关键字模型和语音 SDK
请参阅 GitHub 上的示例,了解如何将自定义关键字模型与 Python SDK 配合使用。
语音转文本 REST API 参考 | 适用于短音频的语音转文本 REST API 参考 | GitHub 上的其他示例
语音转文本 REST API 不支持关键字识别。 请选择其他编程语言,或从本文开头链接的引用和示例。
语音 CLI 支持关键字识别,但我们尚未提供有关此内容的指南。 请选择其他编程语言以开始学习并了解相关概念。