你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Azure AI 自定义翻译工具模型面向特定语言对提供翻译。 成功培训的结果即为一种模型。 若要训练自定义模型,需要三种互斥的文档类型:训练、优化和测试。 如果在对训练进行排队时仅提供训练数据,则自定义翻译器会自动收集优化和测试数据。 它使用训练文档中的随机句子子集,并从训练数据本身中排除这些句子。 训练完整模型至少需要 10,000 个并行训练句子。
创建自定义模型
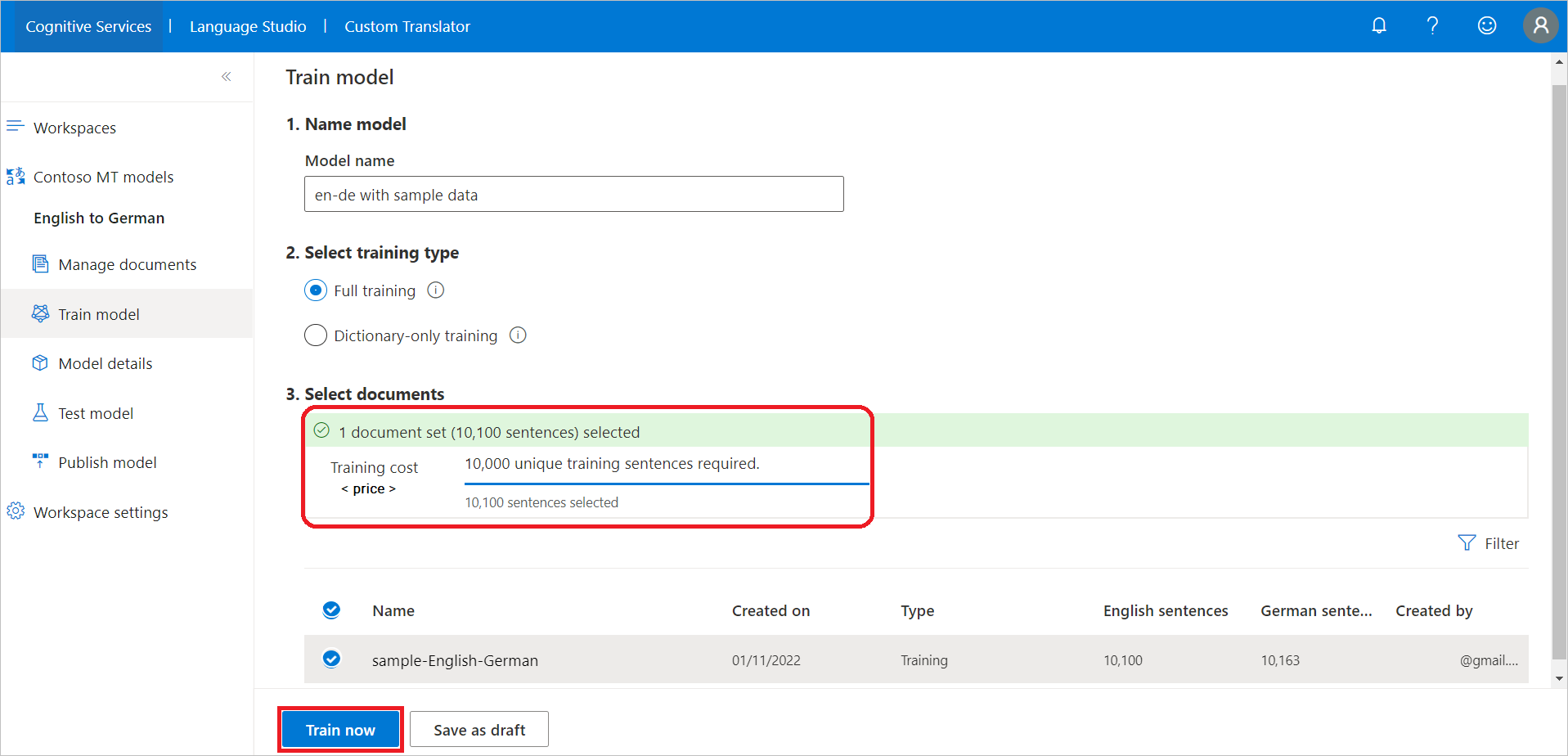
选择“训练模型”边栏选项卡。
键入模型名称。
保持选中默认的“完整训练”,或选择“仅字典训练”。
备注
完整训练显示所有上传的文档类型。 仅字典只显示字典文档。
在“选择文档”下,选择要用于训练模型的文档(例如 ),并查看与所选句子数关联的训练成本。
选择“立即训练”。
选择“训练”以确认。
备注
通知 显示正在进行中的模型训练,例如 提交数据 状态。 训练模型将花费几个小时,具体取决于选定的句子数。
什么情况下选择仅字典训练
我们建议让系统从训练数据中学习,以获得最佳结果。 但是,如果没有足够的并行句子来满足 10,000 的最低要求,或者句子和复合名词必须按原样呈现,请使用仅字典训练。 模型完成该训练的速度通常比完整训练更快。 生成的模型使用用于翻译的基准模型以及你添加的字典。 你没有看到 BLEU 分数,也没有获得测试报告。
备注
自定义翻译器不会在字典文件中进行句子对齐。 因此,重要的是字典文档中源和目标短语/句子的数量相等,并且它们精确对齐。 否则,文档上传将失败。
模型详细信息
成功进行模型训练后,选择“模型详细信息”边栏选项卡。
选择“模型名称”,查看训练日期/时间、总训练时间、用于训练、优化、测试、字典的句子数,以及系统是否生成测试和优化集。 你使用
Category ID发出翻译请求。评估模型
BLEU分数。 查看测试集:“BLEU 分数”是自定义模型分数,而“基线 BLEU”是用于自定义的预先训练的基线模型。 较高的 BLEU 分数意味着使用自定义模型的翻译质量较高。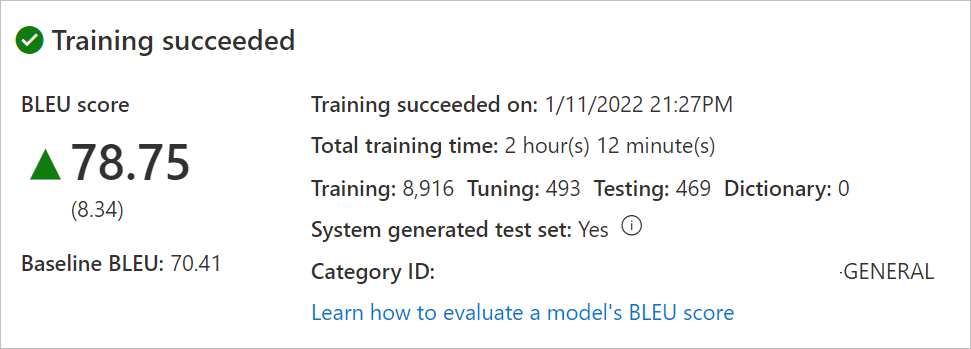
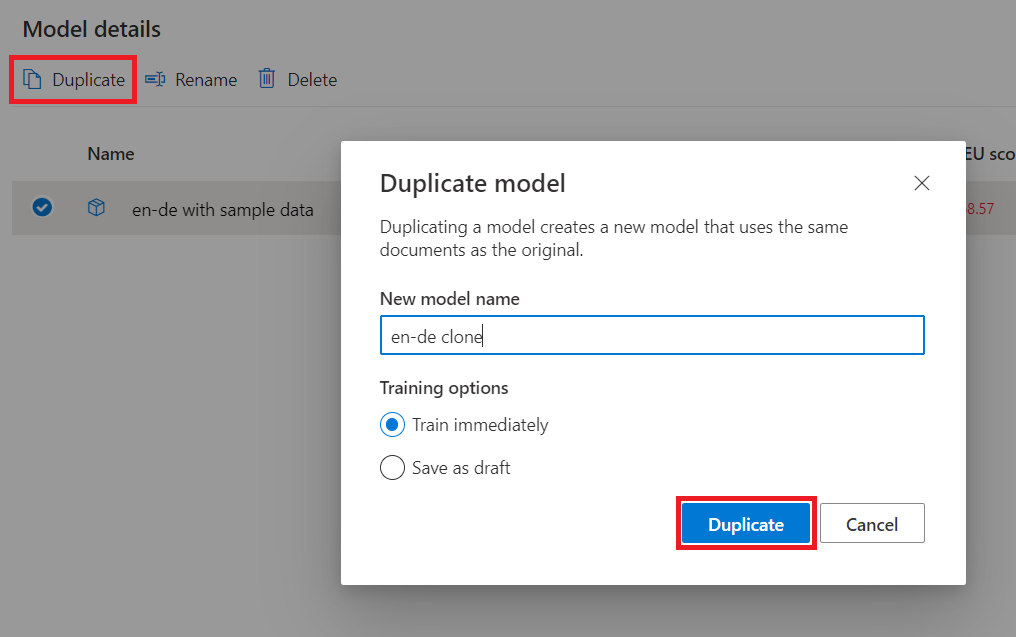
复制模型
选择“模型详细信息”边栏选项卡。
将鼠标悬停在模型名称上,并勾选选择按钮。
选择“复制”。
填写新模型名称。
如果不选择或上传更多数据,则保持“立即训练”处于选中状态,否则,选中“另存为草稿”
选择保存
后续步骤
- 了解如何测试和评估模型质量。
- 了解如何发布模型。
- 了解如何通过自定义模型进行翻译。