你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
重试风暴反模式
当某个服务不可用或繁忙时,让客户端过于频繁地重试其连接可能会导致服务难以恢复,并可能使问题变得更糟。 长久地重试也没有意义,因为请求通常只在定义的时间段内有效。
问题描述
在云中,服务有时会遇到问题,变得对客户端不可用,或者客户端或客户端速率必须经过限制。 对客户端来说,虽然重试与服务的失败连接是一种良好做法,但重要的是不要过于频繁地重试或重试过长时间。 在短时间内重试不太可能成功,因为服务可能还未恢复。 此外,如果在服务尝试恢复时进行了大量连接尝试,则其可能会承受更大压力,并且反复的连接尝试甚至可能使服务不堪重负,导致潜在问题变得更加严重。
下面的示例演示了客户端连接到基于服务器的 API 的场景。 如果请求未成功,则客户端会立即重试,并始终进行重试。 通常,这种行为比此示例中更为微妙,但适用相同的原则。
public async Task<string> GetDataFromServer()
{
while(true)
{
var result = await httpClient.GetAsync(string.Format("http://{0}:8080/api/...", hostName));
if (result.IsSuccessStatusCode) break;
}
// ... Process result.
}
如何解决问题
客户端应用程序应遵循一些最佳做法,以避免导致重试风暴。
- 限制重试次数,不要长时间重试。 虽然编写一个
while(true)循环看起来很简单,但几乎可以肯定的是,你并不希望长时间重试,因为导致发出请求的情况可能已发生更改。 在大多数应用程序中,重试几秒钟或几分钟就足够了。 - 在重试尝试之间暂停。 如果服务不可用,立即重试不太可能成功。 逐渐增加两次尝试之间的等待时间,例如使用指数退避策略。
- 妥善处理错误。 如果服务没有响应,请考虑是否有必要中止尝试并向用户或组件的调用方返回错误。 设计应用程序时,请考虑这些失败情况。
- 考虑使用断路器模式,该模式专用于帮助避免重试风暴。
- 如果服务器提供了
retry-after响应头,请确保在经过指定的时间段之后再尝试重试。 - 与 Azure 服务进行通信时,请使用官方 SDK。 这些 SDK 通常具有内置的重试策略和保护措施,可防止引发重试风暴。 如果要与没有 SDK 或 SDK 不能正确处理重试逻辑的服务进行通信,请考虑使用 Polly(对于 .NET)或 retry(对于 JavaScript)之类的库来正确处理重试逻辑,并避免自行编写代码。
- 如果在支持它的环境中运行,请使用服务网格(或其他抽象层)方出站调用。 通常,这些工具(例如 Dapr)支持重试测试并自动遵循最佳做法,例如在重复尝试后退避。 此方法意味着无需自行编写重试代码。
- 考虑使用批处理请求和请求池(如果可用)。 许多 SDK 会代表你处理请求批处理和连接池,这将减少应用程序尝试出站连接的总次数,但你仍需要仔细避免过于频繁地重试这些连接。
服务还应防范重试风暴。
- 添加网关层,以便在事件发生期间关闭连接。 这是一个隔舱模式示例。 Azure 为不同类型的解决方案提供了许多不同的网关服务,包括 Front Door、应用程序网关和 API 管理。
- 在网关上限制请求,这样可以确保你不会接受太多请求,从而导致后端组件无法继续运行。
- 如果要进行限制,请发回
retry-after标头以帮助客户端了解何时重新尝试连接。
注意事项
- 客户端应考虑返回的错误类型。 某些错误类型并不表示服务发生故障,而是表示客户端发送的请求无效。 例如,如果客户端应用程序接收到
400 Bad Request错误响应,重试相同的请求可能无济于事,因为服务器告知你你的请求无效。 - 客户端应考虑重新尝试连接的合理时间长度。 应重试的时间长度取决于业务需求,以及是否可以合理地将错误传播回用户或调用方。 在大多数应用程序中,重试几秒钟或几分钟就足够了。
如何检测问题
从客户端的角度来看,此问题的症状可能包括响应或处理时间过长,以及指示反复尝试重试连接的遥测。
从服务的角度来看,此问题的症状可能包括短时间内接收到来自同一个客户端的大量请求,或者在从中断恢复时接收到来自单个客户端的大量请求。 症状还可能包括难以恢复服务,或在故障修复后服务发生连锁故障。
示例诊断
下面的部分说明了一种在客户端和服务端检测潜在重试风暴的方法。
从客户端遥测数据中确定
Azure Application Insights 记录来自应用程序的遥测数据,并使数据可用于查询和可视化。 将出站连接作为依赖项进行跟踪,并可以访问和绘制其相关信息,以确定客户端何时向同一服务发出大量出站请求。
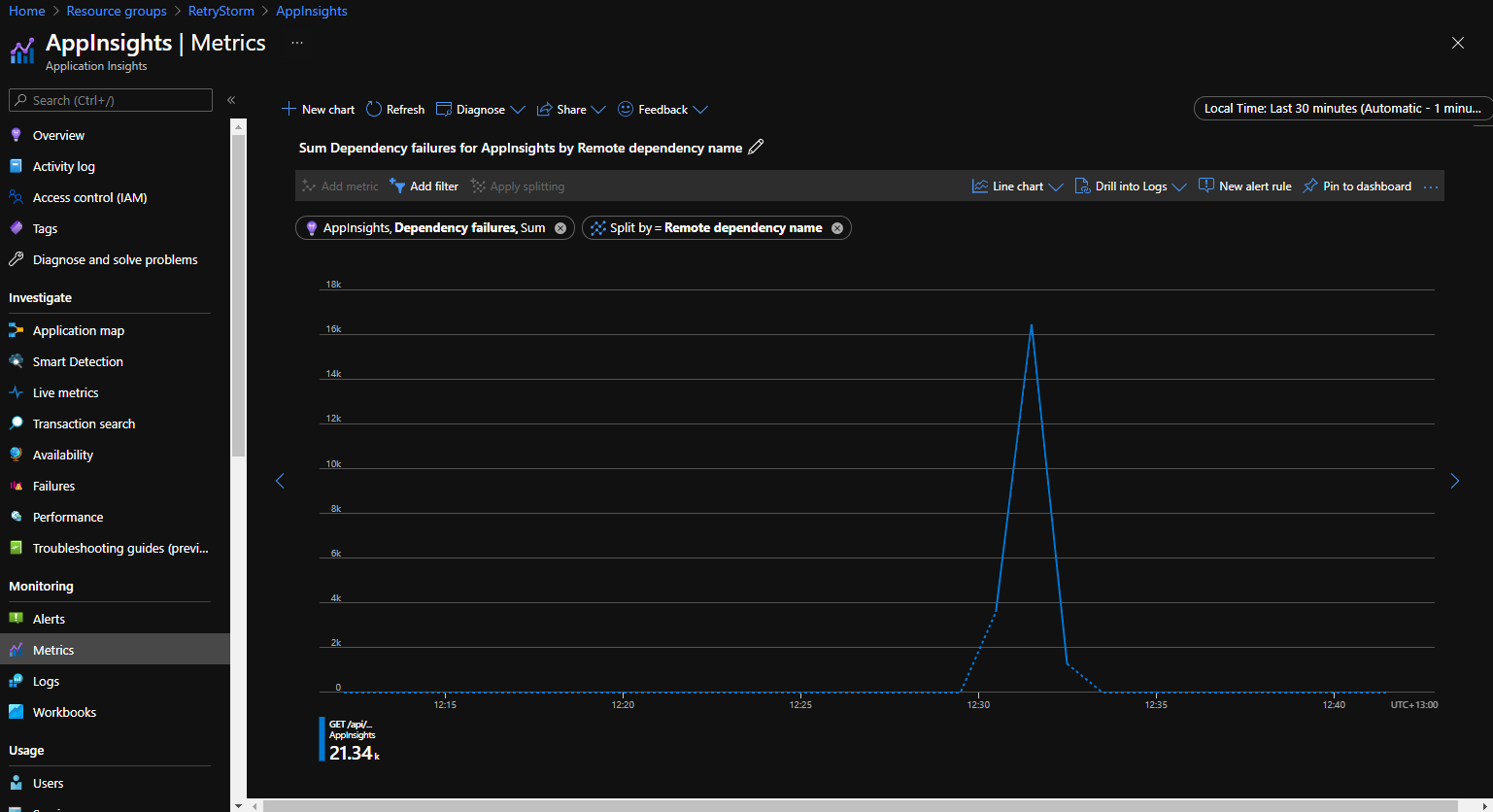
下图摘自 Application Insights 门户中的“指标”选项卡,其中显示了按“远程依赖项名称”拆分的“依赖项失败”指标 。 这演示了在短时间内有大量(超过 21,000 次)尝试连接依赖项失败的情况。
从服务器遥测数据中确定
服务器应用程序也许能够检测到来自单个客户端的大量连接。 在以下示例中,Azure Front Door 充当应用程序的网关,并且已被配置为将所有请求记录到 Log Analytics 工作区。
可对 Log Analytics 执行以下 Kusto 查询。 它可确定过去一天内向应用程序发送大量请求的客户端 IP 地址。
AzureDiagnostics
| where ResourceType == "FRONTDOORS" and Category == "FrontdoorAccessLog"
| where TimeGenerated > ago(1d)
| summarize count() by bin(TimeGenerated, 1h), clientIp_s
| order by count_ desc
在重试风暴期间执行此查询会显示来自单个 IP 地址的大量连接尝试。

相关资源
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈