你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Azure
当应用程序尝试连接到服务或网络资源时,使应用程序能够通过以透明方式重试失败的操作来处理临时故障。 这可以提高应用程序的稳定性。
上下文和问题
与在云中运行的元素进行通信的应用程序必须能够敏感地察觉到此环境中可能会出现的暂时性错误。 这类故障包括组件和服务瞬间断开网络连接、服务暂时不可用,或者当服务繁忙时出现超时。
这些错误通常可以自己修复,如果在延迟合适的时间后重新执行触发了错误的操作,该操作可能会成功。 例如,处理大量并发请求的数据库服务可以实现限制策略,该策略会暂时拒绝任何后续请求,直到其工作负荷得以减轻。 尝试访问该数据库的应用程序可能无法连接,但如果它在延迟一段时间后再次尝试,则可能会成功。
解决方案
在云中,暂时性错误是意料之中的,因此应用程序的设计应能完美、透明地处理这些故障。 这样可以尽量降低错误可能会给应用程序正在执行的业务任务带来的影响。 最常见的设计模式是引入重试机制。
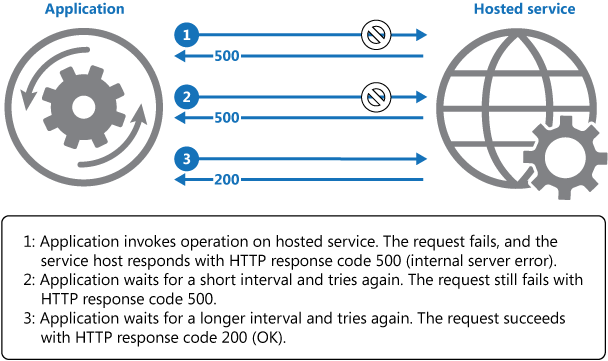
上图说明了使用重试机制在托管服务中调用操作的情况。 如果请求在经历预定义的尝试次数后没有成功,则应用程序应当将该错误视为异常并相应地对其进行处理。
注意
由于暂时性故障的常见性,许多客户端库和云服务现在都提供了内置重试机制,并可对最大重试次数、重试之间的延迟和其他参数进行一定程度的配置。 Microsoft Entity Framework 提供了 失败的数据库作重试的设施。
重试策略
如果应用程序在尝试将请求发送到远程服务时检测到故障,则它可以使用以下策略来处理故障:
取消。 如果错误表明故障不是暂时性的或者在重新执行的情况下不可能成功,则应用程序应当取消操作并报告异常。
立即重试。 如果报告的特定故障异常或罕见,例如在传输网络数据包时损坏,则最佳作过程可能是立即重试请求。
在延迟一段时间后重试。 如果故障是由一个更常见的连接或繁忙故障引起的,则网络或服务可能需要一小段时间,同时更正连接问题或清除积压工作积压工作,因此以编程方式延迟重试是一个很好的策略。 在许多情况下,重试间隔时间的选择应尽可能均匀地分散来自多个应用程序实例的请求,以减少繁忙服务继续超载的机会。
如果请求仍然失败,则应用程序可以等待并进行另一尝试。 如果需要,可以在增大重试尝试之间的延迟时间的情况下不断重复此过程,直到已尝试的请求数目达到某个最大数目。 可以采用递增方式或指数方式增大延迟时间,具体取决于故障的类型和它在此时间段内被更正的可能性。
应用程序应当将访问远程服务的所有尝试包装在代码中并在代码中实现与上面列出的策略之一匹配的重试策略。 发送到不同服务的请求遵守不同的策略。
应用程序应当记录错误和失败操作的详细信息。 此信息对操作员比较有用。 尽管如此,为避免操作员在随后的重试尝试成功后收到大量操作警报,最好将早期失败记录为信息性条目,并仅将最后一次重试尝试失败记录为错误。 以下是此日志记录模型的示例。
如果某个服务频繁不可用或繁忙,通常是由于该服务已耗尽了其资源。 可以通过横向扩展该服务来降低出现这些错误的频率。 例如,如果某个数据库服务持续过载,则对数据库进行分区并将负载分布到多个服务器中可能有助于解决问题。
问题和注意事项
在决定如何实现此模式时,应考虑以下几点。
对性能的影响
应当对重试策略进行调整以匹配应用程序的业务要求和故障性质。 对于某些非关键操作,快速失败是更好的选择,而不是重试多次并影响应用程序的吞吐量。 例如,在访问远程服务的交互式 Web 应用中,最好是在重试较少次数后失败并且重试尝试之间的延迟时间应当很短,而且最好向用户显示合适的消息(例如“请稍后重试”)。 对于批处理应用程序,增加重试尝试次数并且在尝试之间采用呈指数级增长的延迟时间可能更为合适。
对于运行状况已接近或处于其容量上限的繁忙服务,如果采用尝试延迟时间间隔最小且尝试次数较多的积极重试策略,则可能会进一步降低性能。 如果此重试策略不断尝试执行失败的操作,则它还可能会影响应用程序的响应能力。
如果请求在大量重试后仍然失败,则应用程序最好防止进一步的请求进入同一资源并立即报告失败。 当期限过期后,应用程序可以试探性地允许一个或多个请求通过以查看它们是否成功。 有关此策略的详细信息,请参阅 断路器模式。
幂等性
请考虑操作是否是幂等的。 如果是,则可以放心地进行重试。 否则,重试可能会导致操作执行多次并产生意外的副作用。 例如,某个服务可以收到请求,成功处理该请求,但无法发送响应。 此时,重试逻辑可能会认为第一个请求没有收到并重新发送请求。
例外类型
由于各种原因,对服务的请求可能会失败,从而引发不同的异常,具体取决于失败的性质。 某些异常表明故障可以快速解决,而另一些异常表明故障会持续较长时间。 根据异常类型为重试策略调整重试尝试之间的时间间隔会起作用。
事务一致性
请考虑属于事务一部分的操作将如何影响总体的事务一致性。 请优调事务操作的重试策略以尽量提高成功几率并降低撤消所有事务步骤的需求。
通用指南
确保所有重试代码都针对各种故障条件进行了全面测试。 检查它是否不会严重影响应用程序的性能或可靠性,导致服务和资源负载过大,或者产生争用条件或瓶颈。
只有充分了解失败操作的完整上下文后才应实现重试逻辑。 例如,如果某个任务包含的重试策略会调用也包含重试策略的另一任务,则这一层额外的重试可能会给处理增加很长的延迟。 更好的解决方案可能是将较低级别的任务配置为快速失败并将失败原因报告给调用它的任务。 然后,此较高级别的任务可以根据自己的策略处理失败。
记录导致重试的所有连接故障,以便可以查明应用程序、服务或资源的底层问题。
请调查服务或资源最有可能发生的错误以查明它们可能持续很长时间还是已处于末期。 如果可能持续很长时间,则最好将错误作为异常进行处理。 应用程序可以报告或记录异常,然后尝试通过调用备用服务(如果有)或通过提供降级的功能来继续运行。 有关如何检测和处理持续时间很长的错误的详细信息,请参阅断路器模式。
何时使用此模式
当应用程序与远程服务进行交互或者访问远程资源时可能会遇到暂时性错误时,请使用此模式。 这些错误预计只会短时存在,并且通过后续尝试重复执行之前失败的请求可能会成功。
在下列情况下,此模式可能不适用:
- 当错误可能会持续很长时间时,因为此模式可能会影响应用程序的响应能力。 如果应用程序尝试重复执行可能会失败的请求,可能会浪费时间和资源。
- 处理不是由于出现暂时性错误而导致的故障,例如,由应用程序的业务逻辑中的错误导致的内部异常。
- 作为替代方法来解决系统中的可伸缩性问题。 如果应用程序遇到频繁的繁忙错误,则这通常表明应当纵向扩展正在访问的服务或资源。
工作负荷设计
架构师应评估如何在其工作负荷的设计中使用“重试模式”,以解决 Azure Well-Architected Framework 支柱中涵盖的目标和原则。 例如:
| 支柱 | 此模式如何支持支柱目标 |
|---|---|
| 可靠性设计决策有助于工作负荷在发生故障后复原,并确保它在发生故障后恢复到正常运行状态。 | 减轻分布式系统中的暂时性故障是提高工作负荷弹性的核心技术。 - RE:07 自我保护 - RE:07 暂时性故障 |
与任何设计决策一样,请考虑对可能采用此模式引入的其他支柱的目标进行权衡。
示例
有关使用 Azure SDK 内置重试机制支持的详细示例,请参阅使用 .NET 实现重试策略指南。
后续步骤
编写自定义重试逻辑之前,请考虑使用通用框架,例如适用于 .NET 的 Polly 或适用于 Java 的 Resilience4j。
处理更改业务数据的命令时,请注意,重试可能会导致该操作执行两次,如果该操作类似于要求客户使用信用卡付费,则可能会出现问题。 使用这篇博客文章中描述的幂等模式可以处理这些情况。
相关资源
可靠 Web 应用模式演示了如何将重试模式应用于云上聚合的 Web 应用程序。
对于大多数 Azure 服务,客户端 SDK 包含内置的重试逻辑。
断路器模式。 如果预计故障会持续较长时间,则实现断路器模式可能更为合适。 结合使用重试和断路器模式可综合地处理故障。