你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
本文介绍在微服务体系结构中管理数据的注意事项。 每个微服务管理自己的数据,因此数据完整性和数据一致性构成了关键挑战。
两个服务不应共享数据存储。 每个服务都管理自己的专用数据存储,其他服务无法直接访问它。 此规则可防止服务之间的意外耦合,当服务共享相同的基础数据架构时,会发生这种耦合。 如果数据架构发生更改,则必须跨依赖于该数据库的每个服务协调更改。 隔离每个服务的数据存储会限制更改范围,并保留独立部署的灵活性。 每个微服务可能还具有唯一的数据模型、查询或读取和写入模式。 共享数据存储限制了每个团队优化其特定服务的数据存储的能力。
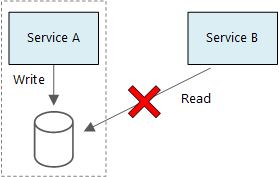
此图显示了左侧分区中的服务 A 和数据库。 标记有从服务 A 到数据库的写入点的箭头。 服务 B 位于右侧此部分之外。 标记为读取的箭头指向数据库。 红色 X 穿过此箭头。
此方法自然会导致 多语言持久化,这意味着在单个应用程序中使用多种数据存储技术。 一个服务可能需要文档数据库的架构读取功能。 另一个服务可能需要关系数据库管理系统(RDBMS)提供的引用完整性。 每个团队都可以为其服务选择最佳选项。
注释
服务可以安全地共享同一物理数据库服务器。 当服务共享同一架构或读取和写入同一组数据库表时,会出现问题。
挑战
管理数据的分布式方法带来了一些挑战。 首先,可以在数据存储之间实现冗余。 同一数据项可能出现在多个位置。 例如,数据可能作为事务的一部分存储,然后存储在其他位置进行分析、报告或存档。 重复或分区的数据可能会导致数据完整性和一致性问题。 当数据关系跨越多个服务时,传统数据管理技术无法强制实施这些关系。
传统数据建模遵循一个事实在一个地方的规则。 每个实体在模式中恰好出现一次。 其他实体可能会引用它,但不重复它。 传统方法的主要优点是更新发生在单个位置,从而防止数据一致性问题。 在微服务体系结构中,必须考虑如何在服务之间传播更新,以及如何在数据出现在多个位置且不具有强一致性时管理最终一致性。
管理数据的方法
对于所有情况,任何方法都不起作用。 请考虑以下一般准则来管理微服务体系结构中的数据:
为每个组件定义所需的一致性级别,并尽可能首选最终一致性。 确定系统中需要强一致性或原子性、一致性、隔离和持续性(ACID)事务的区域。 确定可以接受最终一致性的区域。 有关详细信息,请参阅对微服务使用战术域驱动设计(DDD)。
需要高度一致性时,请使用单一事实来源。 一个服务可能表示给定实体的真相来源,并通过 API 公开它。 其他服务可能保存其自己的数据副本或数据子集,最终与主要数据保持一致,但未被视为事实来源。 例如,在具有客户订单服务和推荐服务的电子商务系统中,建议服务可能会侦听订单服务中的事件。 但是,如果客户请求退款,则订单服务(而不是建议服务)具有完整的交易历史记录。
应用事务模式以保持服务之间的一致性。 使用 调度代理管理器 和 补偿性事务 等模式,使数据在多个服务之间保持一致。 若要避免多个服务中的部分故障,可能需要存储一个额外的数据片段,用于捕获跨多个服务的工作单元的状态。 例如,在多步骤事务进行期间,将工作项保留在持久队列中。
仅存储服务所需的数据。 服务可能只需要有关域实体的信息子集。 例如,在发货边界上下文中,需要知道哪个客户与特定交付相关联。 但不需要客户的帐单地址,因为帐户绑定上下文管理该信息。 谨慎的域分析和 DDD 方法可以强制实施此原则。
考虑你的服务是否一致且松散耦合。 如果两个服务不断相互交换信息并创建聊天 API,则可能需要重新绘制服务边界。 合并两个服务或重构其功能。
使用 事件驱动的体系结构样式。 在此体系结构样式中,服务在其公共模型或实体发生更改时发布事件。 其他服务可以订阅这些事件。 例如,另一个服务可以使用事件来构造更适合查询的数据的具体化视图。
发布事件的架构。 拥有事件的服务应发布架构以自动序列化和反序列化事件。 此方法可避免发布者和订阅者之间的紧密耦合。 考虑 JSON 架构或 Protobuf 或 Avro 等框架。
大规模减少事件瓶颈。 大规模事件可能会成为系统上的瓶颈。 请考虑使用聚合或批处理来减少总负载。
示例:为无人机交付应用程序选择数据存储
本系列前面的文章将无人机交付服务描述为正在运行的示例。 有关方案和相应体系结构的详细信息,请参阅 设计微服务体系结构。
为了回顾,此应用程序定义了多个微服务,用于计划无人机交付。 当用户计划新的交付时,客户端请求包括有关交付的信息,如取件和下车位置,以及包的大小和重量。 此信息定义一个工作单元。
各种后端服务使用请求中信息的不同部分,并且具有不同的读取和写入配置文件。

交付服务
配送服务存储有关每个已经安排或正在进行中的配送的信息。 它侦听来自无人机的信号,并跟踪配送过程中各项事务的状况。 它还发送包含投递状态更新的域事件。
用户在等待包裹时经常检查送达状态。 因此,传递服务需要一个数据存储,该数据存储优先考虑吞吐量(读取和写入),而不是长期存储。 传递服务不执行复杂的查询或分析。 它仅获取特定交付的最新状态。 交付服务团队选择 Azure 托管 Redis 来获得较高的读写性能。 存储在 Azure 托管 Redis 中的信息生存期较短。 交付完成后,传递历史记录服务将成为记录系统。
交付历史记录服务
传递历史记录服务侦听传递服务中的传递状态事件。 它将此数据存储在长期存储中。 此历史数据支持两种方案,每个方案具有不同的存储要求。
第一种方案聚合数据分析数据,以优化业务或提高服务质量。 传递历史记录服务不执行实际数据分析。 它只引入并存储数据。 对于此方案,存储必须针对大型数据集优化,以进行数据分析,并使用读时解析架构来适应各种数据源。 Azure Data Lake Storage 非常适合此方案,因为它是与 Hadoop 分布式文件系统(HDFS)兼容的 Apache Hadoop 文件系统。 它还针对数据分析方案的性能进行了优化。
第二种方案允许用户在交付完成后查找交付历史记录。 Data Lake Storage 不支持此方案。 为了获得最佳性能,请将时序数据存储在 Data Lake Storage 中,以按日期分区的文件夹存储。 但此结构使基于 ID 的单个查找效率低下。 除非还知道时间戳,否则进行 ID 查找时需要扫描整个集合。 为了解决此问题,传递历史记录服务还会将历史数据的子集存储在 Azure Cosmos DB 中,以便更快地查找。 记录不需要无限期地保留在 Azure Cosmos DB 中。 可以通过运行偶尔的批处理过程,在特定的时间段(如一个月)之后存档较旧的交付。 存档数据可以减少 Azure Cosmos DB 的成本,并使数据可供 Data Lake Storage 的历史报告使用。
有关详细信息,请参阅 优化 Data Lake Storage 以提高性能。
软件包服务
软件包服务存储有关所有软件包的信息。 包服务的数据存储必须满足以下要求:
- 长期存储
- 处理大量包的高写入吞吐量
- 按包 ID 进行的简单查询,无需复杂的联接或引用完整性约束
包数据不是关系型数据库,因此面向文档的数据库运行良好。 Azure DocumentDB 可以使用分片集合实现高吞吐量。 包服务团队熟悉 MongoDB、Express.js、AngularJS 和 Node.js (MEAN) 堆栈,因此他们选择实现 Azure DocumentDB。 通过此选项,他们可以使用其现有的 MongoDB 体验,同时获得完全托管的高性能 Azure 服务的优势。