管道和筛选器模式
将一个执行复杂处理的任务分解为一系列可重复使用的单个元素。 这样做可以单独部署和缩放执行处理的任务元素,从而提高初始步骤的性能、可伸缩性和可重用性。 管道和筛选器模式支持高水平的模块化。
上下文和问题
你有一个需要处理的序列性任务的管道。 实施此应用程序的一种直接但不灵活的方法是将这种处理当作整体式模块来执行。 但是,这种方法可能会降低重构代码、优化代码或在应用程序的其他位置需要相同处理的部分时重复使用代码的机会。
下图说明了使用整体式方法处理数据时遇到的问题之一,即无法跨多个管道重复使用代码。 在本例中,应用程序接收并处理来自两个源的数据。 由单个模块处理来自每个源的数据,执行一系列的任务来转换这些数据,然后再将结果传递到应用程序的业务逻辑。
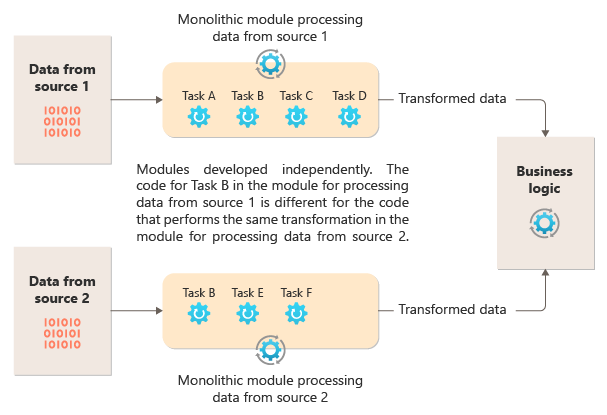
整体式模块执行的一些任务在功能上相似,但代码必须在两个模块中重复,并且很可能在其模块内紧密耦合。 除了无法重用逻辑之外,当需求发生变化时,这种方法还会带来风险。 必须记住在这两个位置更新代码。
整体式实现还有与多个管道或重用无关的其他挑战。 使用整体式时,无法在不同的环境中运行特定任务或独立扩展这些任务。 某些任务可能是计算密集型任务,并受益于在功能强大的硬件上运行或并行运行多个实例。 其他任务可能没有相同的要求。 此外,使用整体式,重新排序任务或在管道中注入新任务是一项挑战。 这些更改需要重新测试整个管道。
解决方案
将每个流所需的处理分解为一组单独的组件(或筛选器),每个组件执行一项任务。 复合任务使用多个筛选器而不是一个筛选器。 通过将筛选器与管道连接,将筛选器组成管道。 筛选器是独立、自包含的,且通常是无状态的。 筛选器从入站管道接收消息,并将消息发布到其他出站管道。 筛选器可以转换消息,或针对一个或多个条件对其进行测试,以包含条件逻辑。 管道不执行路由或任何其他逻辑。 它们只连接筛选器,将一个筛选器的输出消息作为输入传递给下一个筛选器。
筛选器独立运行,不知道其他筛选器。 他们只知道自己的输入和输出架构。 因此,只要任何筛选器的输入模式与上一个筛选器的输出模式匹配,筛选器就可以按任何顺序排列。 对所有筛选器使用标准化架构可增强重新排序筛选器的能力。 管道和筛选器体系结构鼓励组合重用。
筛选器的松散耦合使其易于:
- 创建由现有筛选器组成的新管道
- 更新或替换单个筛选器中的逻辑
- 必要时重新排序筛选器
- 根据需要在不同的硬件上运行筛选器
- 并行运行筛选器
下图显示了使用管道和筛选器实现的解决方案:
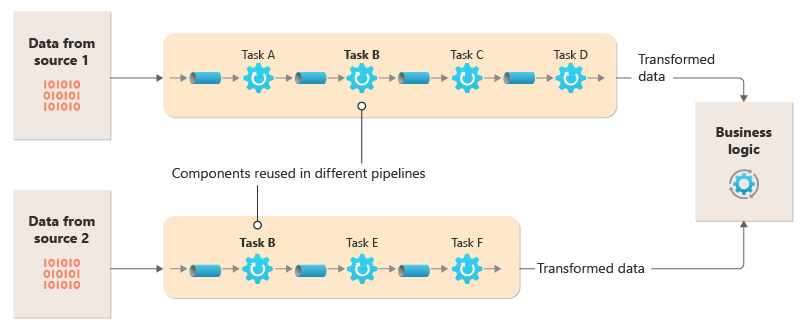
处理单个请求所花的时间取决于管道中最慢筛选器的速度。 一个或多个筛选器可能是瓶颈,尤其是在特定数据源的流中出现大量请求时。 运行慢速筛选器的并行实例的能力使系统能够分散负载并提高吞吐量。
在不同的计算实例上运行筛选器的能力使它们能够独立缩放,并利用许多云环境提供的弹性。 计算密集型筛选器可以在高性能硬件上运行,而其他要求较低的筛选器可以在成本较低的商用硬件上托管。 筛选器甚至不需要位于同一个数据中心或地理位置,使管道中的每个元素都可以在靠近自己所需资源的环境中运行。 这些工作需要特定的设计技术,如消息传送、多线程处理等,以最大程度地提高每个管道或筛选器的弹性。 下图显示了应用于来源 1 的数据管道的示例:
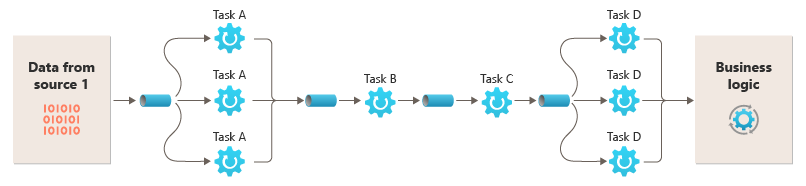
如果筛选器的输入和输出采用流结构,则可以为每个筛选器并行执行处理。 管道中的第一个筛选器可以启动其工作并输出其结果,然后在第一个筛选器完成工作之前,按顺序将结果直接传递到下一筛选器。
将管道和筛选器模式与补偿事务模式结合使用,这是实现分布式事务的另一种方法。 可以将分布式事务分解为单独的、可补偿的任务,每个任务都可以通过筛选器来实现,而筛选器还能实现补偿事务模式。 可以将管道中的筛选器作为单独的托管任务来实现,在靠近它们所维护数据的位置运行。
问题和注意事项
在决定如何实现此模式时,请考虑以下几点:
整体性。 此模式通常作为一个整体管道来实现,因此对于任何更改,都应该对整个筛选器链进行端到端的测试。 此外,还需要考虑整个过程的容错性;如果筛选器或管道出现故障,那么整个管道都可能出现故障。
复杂性。 此模式提供的较高灵活性也可能会引入复杂性,尤其是管道中的筛选器分布在不同的服务器上时。
可靠性。 使用基础结构来确保管道中的筛选器之间流动的数据不会丢失。
幂等性。 如果管道中的筛选器在接收消息后失败,并且将工作重新安排给筛选器的另一个实例,则部分工作可能已经完成。 如果这项工作仅更新全局状态的一些方面(例如存储在数据库中的信息),则可以重复一次更新。 如果筛选器在将其结果发布到管道中的下一个筛选器后失败,但在指示它已成功完成工作之前,则可能会发生类似的问题。 在这些情况下,筛选器的另一个实例重复执行该工作,导致相同的结果发布两次。 此方案可能会导致管道中的后续筛选器对相同数据处理两次。 因此,应将管道中的筛选器设计为幂等。 有关详细信息,请参阅 Jonathan Oliver 博客中的 Idempotency Patterns(幂等模式)。
重复消息。 如果管道中的筛选器在将消息发布到管道的下一阶段后失败,则可能会运行筛选器的另一个实例,并且它会将相同消息的副本发布到管道。 此方案可能会导致将相同消息的两个实例传递到下一个筛选器。 为了避免此问题,管道应该检测和消除重复的消息。
注意
如果通过使用消息队列(例如 Azure 服务总线队列)实现管道,则消息队列基础结构可能会提供自动重复消息检测和删除功能。
上下文和状态。 在管道中,每个筛选器基本上是分开运行的,不应对它的调用方式做任何假设。 因此,每个筛选器应提供足够的上下文来执行其工作。 此上下文可以包括大量状态信息。 如果筛选器使用外部状态(例如数据库或外部存储中的数据),则必须考虑对性能的影响。 每个筛选器必须加载、操作和保留该状态,这比一次性加载外部状态的解决方案增加了开销。
消息容差。 筛选器必须能够容忍传入消息中不对其操作的数据。 它们对与其相关的数据进行操作,并忽略其他数据,并在输出消息中不加更改地传递这些数据。
错误处理 - 每个筛选器都必须确定在发生中断性错误时要执行的操作。 筛选器必须确定是使管道失败还是传播异常。
何时使用此模式
在以下情况下使用此模式:
应用程序所需的处理可以轻松分解为一组独立的步骤。
应用程序执行的处理步骤具有不同的可伸缩性要求。
注意
可以将应一起缩放的筛选器分组到同一进程中。 有关详细信息,请参阅计算资源整合模式。
需要具备一定的灵活性,以便能够对应用程序执行的处理步骤重新排序;或启用添加和删除步骤的功能。
系统可以从将不同步骤的处理能力分配给不同的服务器中获益。
需要一种可靠的解决方案,在处理数据的同时,尽可能降低步骤失败带来的影响。
在以下情况下,此模式可能不起作用:
应用程序遵循请求-响应模式。
任务处理必须作为初始请求的一部分完成,例如请求/响应方案。
应用程序执行的处理步骤不是独立的,或者它们必须作为单个事务的一部分一起执行。
一个步骤所需的上下文或状态信息的数量使这种方法效率低下。 它可能能够将状态信息保留到数据库,但如果数据库的额外负载导致过度争用资源,请勿使用此策略。
工作负荷设计
架构师应评估如何在其工作负载的设计中使用“管道和筛选器模式”,以解决 Azure Well-Architected Framework 支柱中涵盖的目标和原则。 例如:
| 支柱 | 此模式如何支持支柱目标 |
|---|---|
| 可靠性设计决策有助于工作负荷在发生故障后复原,并确保它在发生故障后恢复到正常运行状态。 | 每个阶段的单一职责可以集中注意力,避免混合数据处理的分散。 - RE:01 简单性 - RE:07 后台作业 |
与任何设计决策一样,请考虑对可能采用此模式引入的其他支柱的目标进行权衡。
示例
可以使用一系列消息队列来提供实现管道所需的基础结构。 初始消息队列接收未处理的消息,这些消息将成为管道和筛选器模式实施的开头。 作为筛选器任务实施的组件侦听此队列中的消息,执行其工作,然后将新的或转换的消息发布到序列中的下一个队列。 另一个筛选器任务可以侦听此队列上的消息、处理这些消息、将结果发布到另一个队列等,直到结束管道和筛选器流程的最后一步。 下图演示了一个使用消息队列的管道:

可以使用此模式实施映像处理管道。 如果工作负荷采用映像,该映像可以传递一系列基本上独立的可重新排序的筛选器来执行如下操作:
- 内容审查
- 正在调整大小
- 水印
- 重新定向
- Exif 元数据删除
- 内容交付网络 (CDN) 发布
在此示例中,可以将筛选器作为单独部署的 Azure Functions 实施,甚至可以实施单个 Azure Function 应用,该应用包含每个筛选器作为独立部署。 使用 Azure 函数触发器、输入绑定和输出绑定可以简化筛选器代码,并使用要处理的映像的认领凭证来自动处理基于队列的管道。

下面是一个示例,其中一个筛选器作为 Azure 函数实施,该筛选器是从队列存储管道触发的,其中包含映像的认领凭证,并将新的认领凭证写入另一个队列存储管道可能如下所示。 为了简洁起见,已将该实施替换为注释中的伪代码。 在 GitHub 上提供的管道和筛选器模式演示中可以找到更多类似代码。
// This is the "Resize" filter. It handles claim checks from input pipe, performs the
// resize work, and places a claim check in the next pipe for anther filter to handle.
[Function(nameof(ResizeFilter))]
[QueueOutput("pipe-fjur", Connection = "pipe")] // Destination pipe claim check
public async Task<string> RunAsync(
[QueueTrigger("pipe-xfty", Connection = "pipe")] string imageFilePath, // Source pipe claim check
[BlobInput("{QueueTrigger}", Connection = "pipe")] BlockBlobClient imageBlob) // Image to process
{
_logger.LogInformation("Processing image {uri} for resizing.", imageBlob.Uri);
// Idempotency checks
// ...
// Download image based on claim check in queue message body
// ...
// Resize the image
// ...
// Write resized image back to storage
// ...
// Create claim check for image and place in the next pipe
// ...
_logger.LogInformation("Image resizing done or not needed. Adding image {filePath} into the next pipe.", imageFilePath);
return imageFilePath;
}
注意
Spring Integration Framework 具有管道和筛选器模式的实现。
后续步骤
实现此模式时,你可能会发现以下资源很有用:
- GitHub 上提供了使用映像处理场景的管道和筛选器模式演示。
- Jonathan Oliver 博客中的幂等模式。
相关资源
实现此模式时,以下模式也可能有用:
- 认领凭证模式。 使用队列实施的管道可能不会保存通过筛选器发送的实际项,而是指向需要处理的数据的指针。 此示例将 Azure 队列存储中的认领凭证用于 Azure Blob 存储中存储的映像。
- 使用者竞争模式。 管道可以包含一个或多个筛选器的多个实例。 此方法可用于为速度缓慢的筛选器运行并行实例。 它使系统能够分散负载并提高吞吐量。 每个筛选器实例将与其他实例争用输入,但筛选器的两个实例不能处理相同的数据。 本文介绍了该方法。
- 计算资源整合模式。 可以将应一起缩放的筛选器分组到单个进程中。 本文提供有关此策略的优点和缺点的详细信息。
- 补偿事务模式。 可将筛选器作为可逆转的操作、或在发生故障时会状态还原到先前版本的补偿操作来实现。 本文介绍如何实现此模式来维护或实现最终一致性。
- 管道和筛选器 - 企业集成模式。