你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Azure 中的业务连续性管理
Azure 维护了行业中最成熟且受尊重的业务连续性管理计划之一。 Azure 中业务连续性的目标是构建并提升所有可独立恢复服务的可恢复性和复原能力,无论服务是面向客户的(Azure 产品/服务的一部分)还是内部支持平台服务。
在了解业务连续性时,必须注意,许多产品/服务由多项服务组成。 在 Azure 中,每项服务都通过工具进行静态标识,并且是用于隐私、安全、库存、风险业务连续性管理和其他功能的度量单位。 为了正确度量服务的功能,无论服务类型如何,每项服务都包含人员、过程和技术这三个元素。
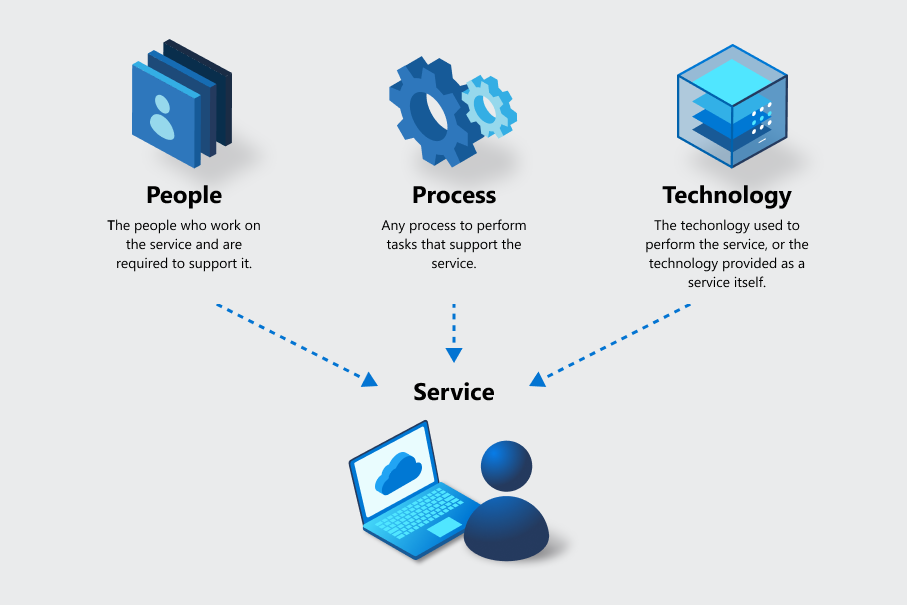
例如:
- 如果业务过程基于人员(例如支持人员或团队),则这些人员的工作内容就是交付的服务。 人们使用过程和技术来执行服务。
- 如果技术即服务(例如 Azure 虚拟机),则该技术连同支持其运行的人员和过程一起就是交付的服务。
共担责任模型
Azure 提供的许多产品/服务都要求你在多个区域中设置灾难恢复,并且不是 Microsoft 的责任。 并非所有 Azure 服务都会自动复制数据,或自动从故障区域回退以跨区域复制到另一个已启用区域。 在这些情况下,你负责配置恢复和副本 (replica)。
Microsoft 确实确保了基线基础结构和平台服务可用。 但在某些情况下,如果你选择,则使用情况要求在多区域容量中复制部署和存储。 这些示例说明了共担责任模型。 它是业务连续性和灾难恢复策略的基本支柱。
责任划分
在任何本地数据中心,你都拥有整个堆栈。 将资产转移到云时,一些责任也转移到了 Microsoft。 下图说明了你与 Microsoft 之间根据部署类型划分的责任范围和分工。
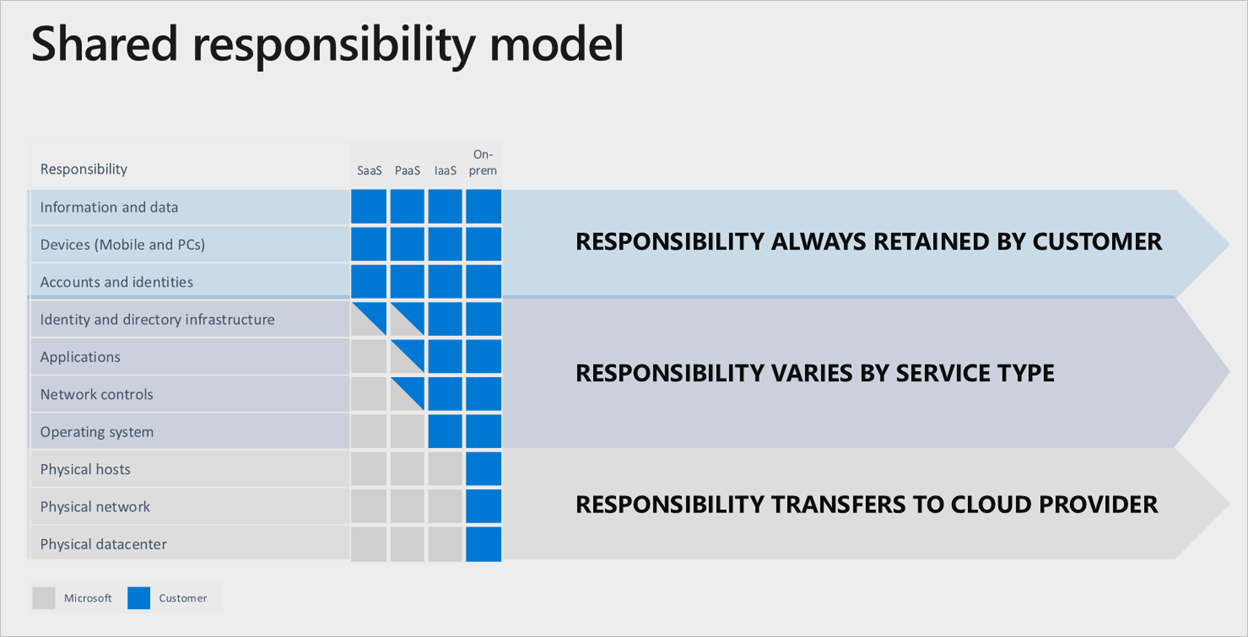
虚拟机部署是共担责任模型的一个很好的示例。 如果要在发生区域故障时设置跨区域副本 (replica)复原,则必须在备用启用的区域中部署一组重复的虚拟机。 如果出现故障,Azure 不会自动复制这些服务。 你有责任部署必要的资产。 必须有一个手动更改主要区域的过程,或者必须使用流量管理器来检测和自动故障转移。
所有支持客户的灾难恢复服务都会提供面向公众的指导文档。 有关面向公众的支持客户灾难恢复文档示例,请参阅 Azure Data Lake Analytics。
有关共担责任模型的详细信息,请参阅 Microsoft 信任中心。
业务连续性合规性:服务级别责任
每项服务都需要在 Azure 业务连续性管理器工具中完成业务连续性灾难恢复记录。 服务所有者可使用该工具在联合模型中工作,以完成并合并以下要求:
服务属性:定义服务以及如何实现灾难恢复和复原能力,并确定灾难恢复的责任方(技术方面)。 有关恢复所有权的详细信息,请参阅上一部分和关系图中有关共担责任模型的讨论。
业务影响分析:此分析可帮助服务所有者根据服务在影响表中的关键性定义恢复时间目标 (RTO) 和恢复点目标 (RPO)。 运营、法律、监管、品牌形象和财务影响都被用作恢复的目标。
注意
Microsoft 不会发布服务的 RTO 或 RTO,因为这些数据仅适用于内部度量。 所有客户承诺和度量都基于 SLA,因为它涵盖的范围比仅适用于灾难性损失的 RTO 或 RPO 的范围更广。
依赖项:无论关键性如何,每项服务都映射其运行所需的依赖项(其他服务),并映射到运行时、仅用于恢复需要或两者兼而有之。 如果存在存储依赖项,则映射其他数据,以定义存储内容以及其是否需要时间点快照等。
员工:正如服务定义中所指出,必须了解能够支持该服务的员工的位置和数量,确保没有单一故障点,以及关键员工是否分散,以避免因同居在一个位置而发生故障。
外部供应商:Microsoft 保留了一份全面的外部供应商名单,并对视为关键供应商的功能进行了度量。 由服务标识为依赖项的供应商功能将与服务需求进行比较,以确保第三方中断不会使 Azure 服务中断。
恢复评级:此评级为 Azure 业务连续性管理计划所独有。 此评级可度量创建复原能力分数的几个关键元素:
- 愿意执行故障转移:尽管可能存在一个过程,但它可能并非短期中断的首选。
- 自动执行故障转移。
- 自动制定执行故障转移的决策。
无需人工决策、自动执行的服务可实现最可靠而最短的故障转移时间。 自动化服务使用检测信号监视或综合事务来确定服务是否关闭并立即开始修正。
恢复计划和测试:Azure 要求每项服务都制定详细的恢复计划并测试该计划,就好像服务已因灾难性中断而故障一样。 需要编写恢复计划,以便具有类似技能和访问权限的人员能够完成任务。 书面计划可避免依赖于主题专家是否有空。
测试可通过多种方式完成,包括在生产或接近生产环境中进行自测,以及作为 Canary 区域集中 Azure 全区域停机演练的一部分。 这些启用的区域与生产区域相同,但可以禁用,而不会影响服务。 测试被认为具有集成性,因为所有服务同时受到影响。
客户启用:在负责设置灾难恢复时,需要 Azure 提供面向公众的文档指南。 对于所有此类服务,都提供了有关该过程的文档和详细信息的链接。
验证业务连续性合规性
当服务完成其业务连续性管理记录后,必须提交该记录以供审批。 它被分配给一位经验丰富的业务连续性管理实践者,该实践者会审查整个记录的完整性和质量。 如果记录满足所有要求,则获得批准。 如果没有,则会被拒绝并被要求返工。 此过程可确保双方都同意业务连续性合规性已得到满足,并且该工作仅由服务所有者证明。 Azure 内部审核和合规性团队还会定期执行随机采样,以确保提交最佳数据。
测试服务
Microsoft 和 Azure 对灾难恢复和可用性区域就绪情况都进行了广泛的测试。 服务在生产或预生产环境中进行自测,以证明不依赖于主要平台故障转移的服务的独立可恢复性。
为了确保服务可在真正的区域停机情景中以类似方式恢复,将在已全面部署与生产匹配的区域的 Canary 环境中执行“拔插”式测试。 例如,群集、机架和电源单元实际上已关闭,以模拟全区域故障。
在这些测试期间,Azure 使用相同的生产过程进行检测、通知、响应和恢复。 没有人期望进行演练,而恢复所依赖的工程师是正常的待命轮换资源。 此时间安排可避免依赖于在实际活动期间可能抽不出空的主题专家。
这些测试中包括负责在 Microsoft 面向公众的文档后设置灾难恢复的服务。 服务团队创建类似于客户的实例,以表明支持客户的灾难恢复按照预期方式工作,并且提供的说明准确无误。
有关认证详细信息,请参阅 Microsoft 信任中心和合规性部分。