你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
由 Azure Arc 启用的 SQL 托管实例作为容器化应用程序部署在 Kubernetes 上。 它利用 Kubernetes 构造(如有状态集和持久性存储),提供以下内置功能:
- 运行状况监视
- 故障检测
- 自动故障转移以维护服务运行状况。
为了提高可靠性,还可以对 Azure Arc 启用的 SQL 托管实例进行配置,在高可用性配置中部署额外副本。 Arc 数据服务数据控制器管理:
- 监视
- 故障检测
- 自动故障转移
已启用 Arc 的数据服务无需用户干预即可提供这种服务。 服务:
- 设置可用性组
- 配置数据库镜像终结点
- 将数据库添加到可用性组
- 协调故障转移和升级。
本文档介绍这两种类型的高可用性。
Azure Arc 启用的 SQL 托管实例提供不同级别的高可用性,具体取决于 SQL 托管实例是部署为“常规用途”服务层级还是“业务关键”服务层级。
常规用途服务层级的高可用性
在常规用途服务层级中,只有一个副本可用,高可用性是通过 Kubernetes 业务流程来实现。 例如,如果包含托管实例容器映像的 Pod 或节点崩溃,Kubernetes 会尝试启动另一个 Pod 或节点,并附加到同一永久性存储。 在此期间,SQL 托管实例对应用程序不可用。 启动新 Pod 时,应用程序需要重新连接并重试该事务。 如果使用的服务类型是 load balancer,则应用程序可以重新连接到同一主终结点,Kubernetes 会将连接重定向到新的主终结点。 如果服务类型为 nodeport,则应用程序需要重新连接到新的 IP 地址。
验证内置高可用性
若要验证 Kubernetes 提供的内置高可用性,可以执行以下步骤:
- 删除现有托管实例的 Pod
- 验证 Kubernetes 是否从此操作中恢复
在恢复过程中,Kubernetes 会启动另一个 Pod 并附加到永久性存储。
先决条件
- Kubernetes 群集需要共享的远程存储
- Azure Arc 启用的 SQL 托管实例部署了一个副本(默认)
查看 Pod。
kubectl get pods -n <namespace of data controller>删除托管实例 Pod。
kubectl delete pod <name of managed instance>-0 -n <namespace of data controller>例如
user@pc:/# kubectl delete pod sql1-0 -n arc pod "sql1-0" deleted查看 Pod,验证托管实例是否正在恢复。
kubectl get pods -n <namespace of data controller>例如:
user@pc:/# kubectl get pods -n arc NAME READY STATUS RESTARTS AGE sql1-0 2/3 Running 0 22s
在 Pod 中的所有容器都恢复之后,可以连接到托管实例。
业务关键服务层级的高可用性
在“关键业务”服务层级中,除了 Kubernetes 编排以原生方式提供的内容外,适用于 Azure Arc 的 SQL 托管实例还提供了一个包含的可用性组。 包含的可用性组基于 SQL Server Always On 技术构建。 它可提供更高级别的可用性。 部署了“关键业务”服务层级的 Azure Arc 启用的 SQL 托管实例,可以部署 2 个或 3 个副本。 这些副本始终保持同步。
使用包含的可用性组时,任何 Pod 崩溃或节点故障对于应用程序都是透明的。 包含的可用性组提供至少一个其他的 Pod,该 Pod 包含主 Pod 中的所有数据,并可随时接受连接。
包含的可用性组
可用性组将一个或多个用户数据库绑定到逻辑组,以便发生故障转移时,整个数据库组作为单个单元故障转移到次要副本。 可用性组仅复制用户数据库中的数据,而不复制系统数据库中的数据(如登录名、权限或代理作业)。 包含的可用性组包括来自系统数据库(如 msdb 和 master 数据库)的元数据。 在主要副本中创建或修改登录名时,次要副本中也会自动创建这些登录名。 同样地,在主要副本中创建或修改代理作业时,次要副本中也会相应修改。
Azure Arc 启用的 SQL 托管实例采用了包含的可用性组这一概念,并添加了 Kubernetes 运算符,以便大规模部署和管理这些可用性组。
包含的可用性组可实现的功能:
使用多个副本进行部署时,将创建一个与已启用 Azure Arc 的 SQL 托管实例同名的可用性组。 默认情况下,包含的可用性组有三个副本,包括主要副本在内。 可用性组的所有 CRUD 操作都在内部进行管理,包括创建可用性组或将副本联接到创建的可用性组。 无法在一个实例中创建更多可用性组。
所有数据库都将自动添加到可用性组,包括所有用户和系统数据库(如
master和msdb)。 此功能提供跨可用性组副本的单系统视图。 如果直接连接到实例,请注意containedag_master和containedag_msdb数据库。containedag_*数据库表示可用性组中的master和msdb。系统会自动预配外部终结点,以便与可用性组中的数据库建立连接。 此终结点
<managed_instance_name>-external-svc扮演可用性组侦听器的角色。
使用 Azure 门户为由 Azure Arc 启用的 SQL 托管实例部署多个副本
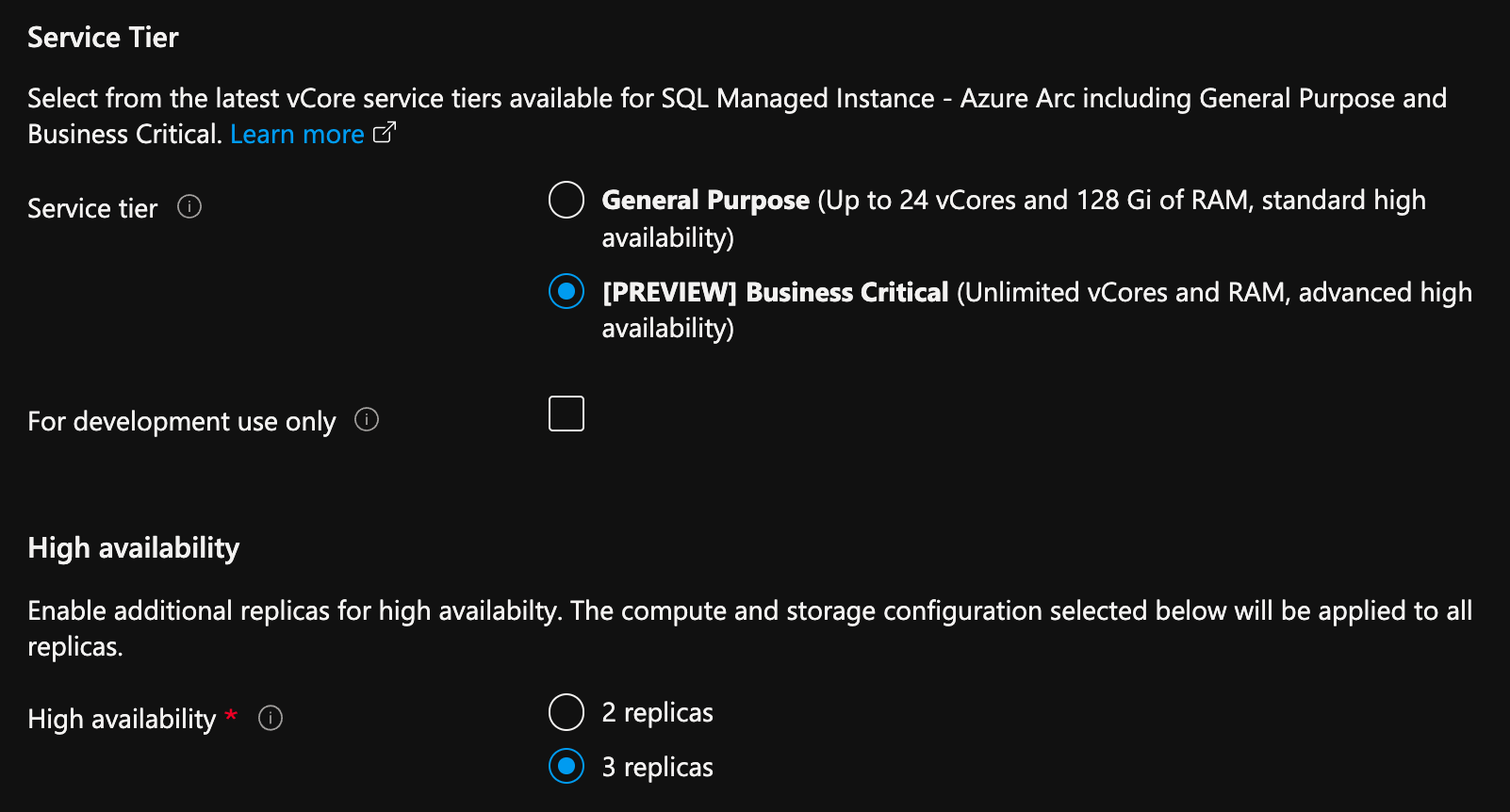
进入 Azure 门户,在由 Azure Arc 启用的 SQL 托管实例的创建页面上:
- 在“计算 + 存储”下选择“配置计算 + 存储”。 门户显示高级设置。
- 在服务层级下,选择“业务关键”。
- 如用于开发目的,请勾选“仅供开发使用”。
- 在“高可用性”下,选择 2 个副本或 3 个副本。
使用 Azure CLI 部署多个副本
在业务关键服务层级部署由 Azure Arc 启用的 SQL 托管实例时,部署会创建多个副本。 预配期间会自动在这些实例之间设置和配置包含的可用性组。
例如,以下命令可创建具有 3 个副本的托管实例。
间接连接模式:
az sql mi-arc create -n <instanceName> --k8s-namespace <namespace> --use-k8s --tier <tier> --replicas <number of replicas>
示例:
az sql mi-arc create -n sqldemo --k8s-namespace my-namespace --use-k8s --tier BusinessCritical --replicas 3
直接连接模式:
az sql mi-arc create --name <name> --resource-group <group> --location <Azure location> –subscription <subscription> --custom-location <custom-location> --tier <tier> --replicas <number of replicas>
示例:
az sql mi-arc create --name sqldemo --resource-group rg --location uswest2 –subscription xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx --custom-location private-location --tier BusinessCritical --replcias 3
所有副本默认在同步模式下配置。 这意味着主要实例上的任何更新都会同步复制到每个次要实例。
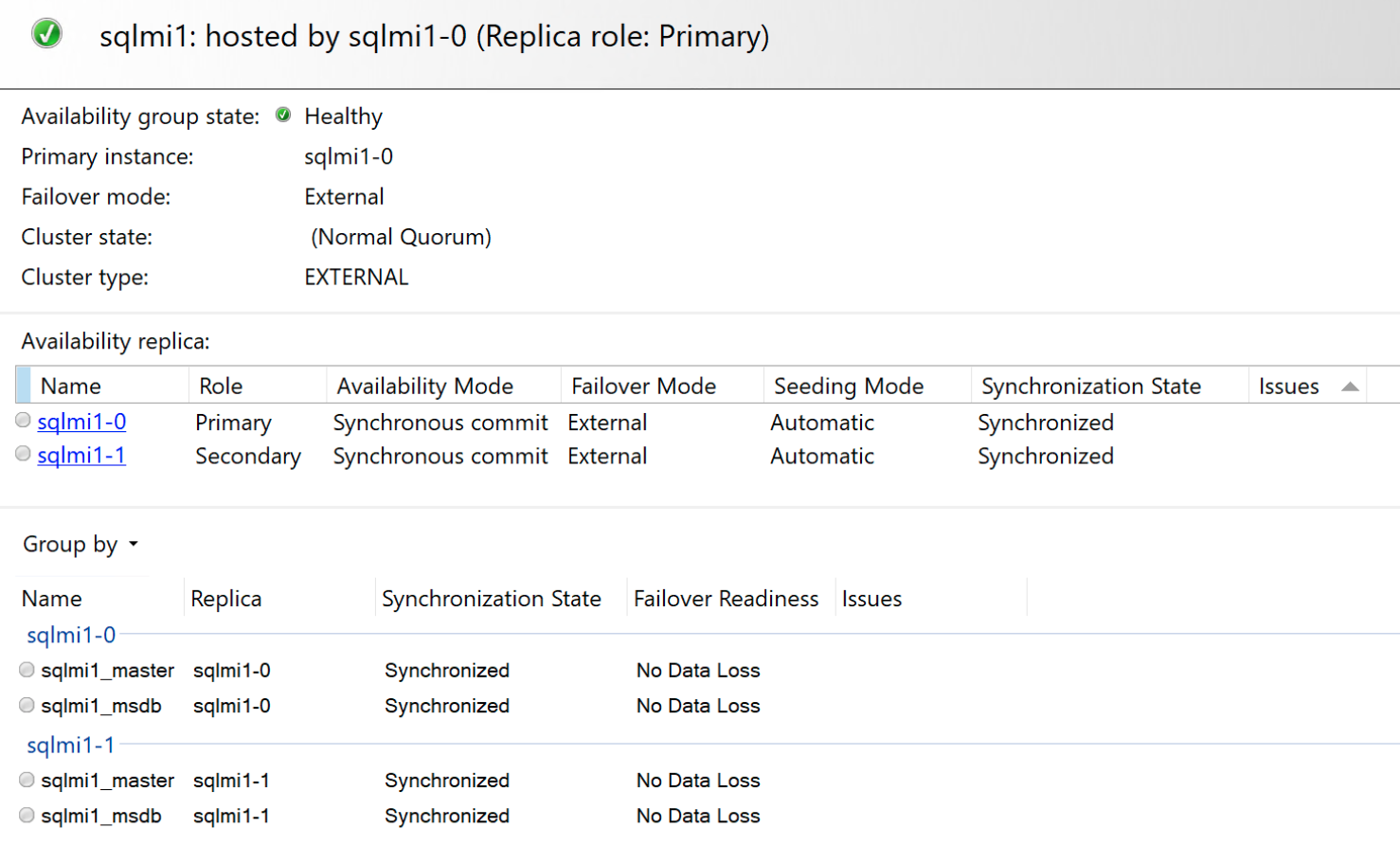
查看和监视可用性组状态
部署完成后,从 SQL Server Management Studio 连接到主终结点。
验证并检索主要副本的终结点,然后从 SQL Server Management Studio 连接到该终结点。
例如,如果使用 service-type=loadbalancer 部署 SQL 实例,请运行以下命令来检索要连接到的终结点:
az sql mi-arc list --k8s-namespace my-namespace --use-k8s
或
kubectl get sqlmi -A
获取主终结点和次终结点以及可用性组状态
使用命令 kubectl describe sqlmi 或 az sql mi-arc show 查看主终结点和次终结点以及高可用性状态。
示例:
kubectl describe sqlmi sqldemo -n my-namespace
或
az sql mi-arc show --name sqldemo --k8s-namespace my-namespace --use-k8s
示例输出:
"status": {
"endpoints": {
"logSearchDashboard": "https://10.120.230.404:5601/app/kibana#/discover?_a=(query:(language:kuery,query:'custom_resource_name:sqldemo'))",
"metricsDashboard": "https://10.120.230.46:3000/d/40q72HnGk/sql-managed-instance-metrics?var-hostname=sqldemo-0",
"mirroring": "10.15.100.150:5022",
"primary": "10.15.100.150,1433",
"secondary": "10.15.100.156,1433"
},
"highAvailability": {
"healthState": "OK",
"mirroringCertificate": "-----BEGIN CERTIFICATE-----\n...\n-----END CERTIFICATE-----"
},
"observedGeneration": 1,
"readyReplicas": "2/2",
"state": "Ready"
}
可以使用 SQL Server Management Studio 连接到主终结点,并按以下方式验证 DMV:
SELECT * FROM sys.dm_hadr_availability_replica_states
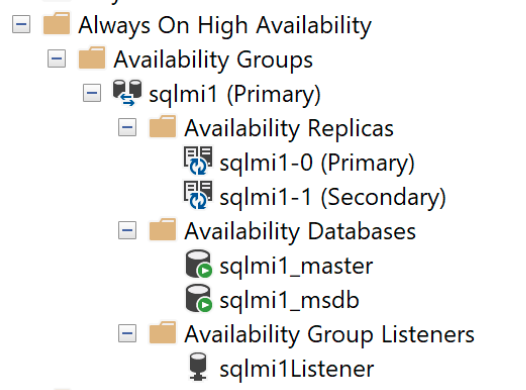
包含的可用性仪表板:
故障转移方案
与 SQL Server Always On 可用性组不同,包含的可用性组是托管的高可用性解决方案。 因此,与可用于 SQL Server Always On 可用性组的典型模式相比,故障转移模式存在局限性。
在双副本配置或三副本配置中部署业务关键服务层级 SQL 管理实例。 故障的影响以及后续可恢复性因配置不同而不同。 有三个副本的实例比有两个副本的实例提供的可用性和恢复能力更高。
在双副本配置中,当两个节点的状态都为 SYNCHRONIZED 时,如果主要副本不可用,则次要副本将自动提升为主要副本。 当发生故障的副本可用时,会使用所有挂起的更改对它进行更新。 如果副本之间存在连接问题,则主要副本可能不会提交任何事务,因为每个事务都需要在两个副本上提交,然后才能向主要副本返回成功消息。
在三副本配置中,事务至少需要在 3 个副本中的 2 个中提交,然后才能将成功消息返回给应用程序。 发生故障时,Kubernetes 尝试恢复失败的副本时,其中一个次要副本会自动提升为主要副本。 当副本可用时,它会自动重新联接到包含的可用性组,并同步挂起的更改。 如果副本之间存在连接问题,并且 2 个以上副本未同步,则主要副本不会提交任何事务。
注意
建议在三副本配置(而非双副本配置)中部署业务关键 SQL 托管实例,以实现近零数据丢失。
若需针对计划事件从主要副本故障转移到其中一个次要副本,请运行以下命令:
如果连接到主要副本,则可以使用以下 Transact-SQL 将 SQL 实例故障转移到其中一个次要副本:
ALTER AVAILABILITY GROUP current SET (ROLE = SECONDARY);
如果连接到次要副本,则可以使用以下 Transact-SQL 将所需次要副本提升为主要副本。
ALTER AVAILABILITY GROUP current SET (ROLE = PRIMARY);
首选主要副本
还可使用 AZ CLI 将特定副本设置为主要副本,如下所示:
az sql mi-arc update --name <sqlinstance name> --k8s-namespace <namespace> --use-k8s --preferred-primary-replica <replica>
示例:
az sql mi-arc update --name sqldemo --k8s-namespace my-namespace --use-k8s --preferred-primary-replica sqldemo-3
注意
Kubernetes 会尝试设置首选副本,但不能保证一定成功。
将数据库还原到多副本实例
将数据库还原到可用性组则还需要执行其他步骤。 以下步骤演示如何将数据库还原到托管实例,并将其添加到可用性组。
通过创建新的 Kubernetes 服务来公开主实例外部终结点。
确定托管主要副本的 Pod。 连接到托管实例并运行:
SELECT @@SERVERNAME查询返回托管主要副本的 Pod。
如果 Kubernetes 群集使用
NodePort服务,请运行以下命令,为主实例创建 Kubernetes 服务。 将<podName>替换为在上一步骤中返回的服务器的名称,将<serviceName>替换为创建的 Kubernetes 服务的首选名称。kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=NodePort对于 LoadBalancer 服务,运行相同的命令,但所创建的服务的类型为
LoadBalancer。 例如:kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=LoadBalancer下面是针对 Azure Kubernetes 服务运行此命令的示例,其中托管主副本的 Pod 为
sql2-0:kubectl -n arc-cluster expose pod sql2-0 --port=1533 --name=sql2-0-p --type=LoadBalancer获取创建的 Kubernetes 服务的 IP:
kubectl get services -n <namespaceName>将数据库还原到主实例终结点。
将数据库备份文件添加到主实例容器。
kubectl cp <source file location> <pod name>:var/opt/mssql/data/<file name> -c <serviceName> -n <namespaceName>示例
kubectl cp /home/WideWorldImporters-Full.bak sql2-1:var/opt/mssql/data/WideWorldImporters-Full.bak -c arc-sqlmi -n arc通过运行以下命令,还原数据库备份文件。
RESTORE DATABASE test FROM DISK = '/var/opt/mssql/data/<file name>.bak' WITH MOVE '<database name>' to '/var/opt/mssql/data/<file name>.mdf' ,MOVE '<database name>' to '/var/opt/mssql/data/<file name>_log.ldf' ,RECOVERY, REPLACE, STATS = 5; GO示例
RESTORE Database WideWorldImporters FROM DISK = '/var/opt/mssql/data/WideWorldImporters-Full.BAK' WITH MOVE 'WWI_Primary' TO '/var/opt/mssql/data/WideWorldImporters.mdf', MOVE 'WWI_UserData' TO '/var/opt/mssql/data/WideWorldImporters_UserData.ndf', MOVE 'WWI_Log' TO '/var/opt/mssql/data/WideWorldImporters.ldf', MOVE 'WWI_InMemory_Data_1' TO '/var/opt/mssql/data/WideWorldImporters_InMemory_Data_1', RECOVERY, REPLACE, STATS = 5; GO将数据库添加到可用性组。
对于要添加到 AG 的数据库,必须在完整恢复模式下运行,并且必须执行日志备份。 运行以下 TSQL 语句,将还原的数据库添加到可用性组中。
ALTER DATABASE <databaseName> SET RECOVERY FULL; BACKUP DATABASE <databaseName> TO DISK='<filePath>' ALTER AVAILABILITY GROUP containedag ADD DATABASE <databaseName>以下示例添加了一个名为
WideWorldImporters的数据库,该数据库在实例上已还原:ALTER DATABASE WideWorldImporters SET RECOVERY FULL; BACKUP DATABASE WideWorldImporters TO DISK='/var/opt/mssql/data/WideWorldImporters.bak' ALTER AVAILABILITY GROUP containedag ADD DATABASE WideWorldImporters
重要
最佳做法是,应通过运行以下命令删除上面创建的 Kubernetes 服务:
kubectl delete svc sql2-0-p -n arc
限制
Azure Arc 启用的 SQL 托管实例可用性组的限制和大数据群集可用性组相同。 有关详细信息,请参阅部署高可用性 SQL Server 大数据群集。