你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Kusto 查询语言 (KQL) 包括用于时序分析、异常情况检测、预测和根本原因分析的机器学习运算符、函数和插件。 可以在 Azure Monitor 中使用这些 KQL 功能执行高级数据分析,而不会产生将数据导出到外部机器学习工具所带来的开销。
本教程介绍如何执行下列操作:
- 创建时序
- 识别时序中的异常
- 微调异常情况检测设置以细化结果
- 分析异常的根本原因
注意
本教程提供了一个可在其中运行 KQL 查询示例的 Log Analytics 演示环境的链接。 演示环境中的数据是动态的,因此查询结果与本文中显示的查询结果不同。 但是,可以在自己的环境和所有使用 KQL 的 Azure Monitor 工具中实现相同的 KQL 查询和主体。
先决条件
- 具有活动订阅的 Azure 帐户。 免费创建帐户。
- 包含日志数据的工作区。
所需的权限
你必须对你查询的 Log Analytics 工作区具有 Microsoft.OperationalInsights/workspaces/query/*/read 权限,例如,Log Analytics 读取者内置角色所提供的权限。
创建时序
使用 KQL make-series 运算符创建时序。
让我们根据使用情况表中的日志创建一个时序。该表保存有关工作区中的每个表每小时引入多少数据(包括可计费和不可计费数据)的信息。
此查询使用 make-series 来绘制工作区中每个表在过去 21 天内每天引入的可计费数据总量的图表:
let starttime = 21d; // The start date of the time series, counting back from the current date
let endtime = 0d; // The end date of the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we're analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Include only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| render timechart // Renders results in a timechart
在生成的图表中,可以清楚地看到一些异常情况 - 例如,在 AzureDiagnostics 和 SecurityEvent 数据类型中:
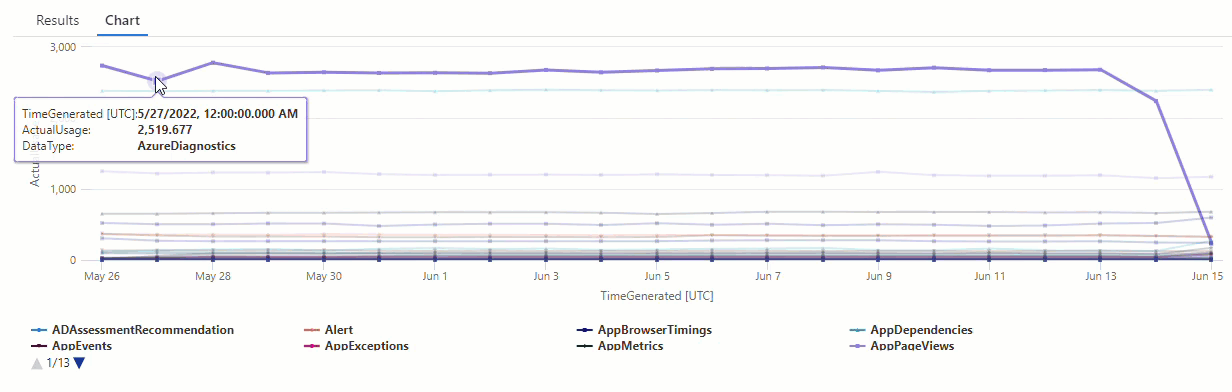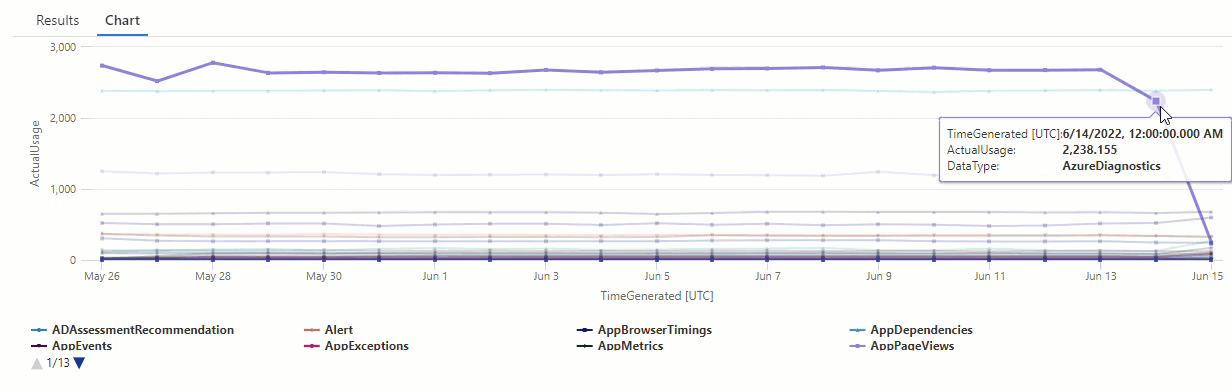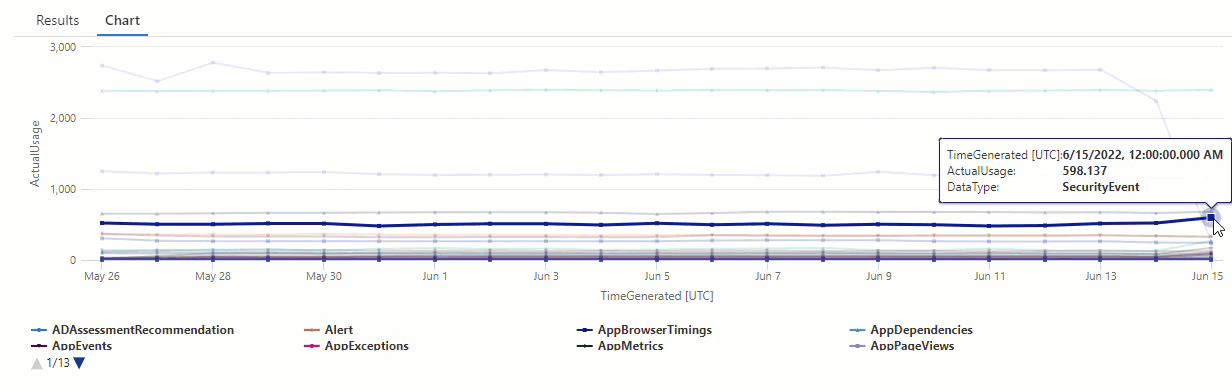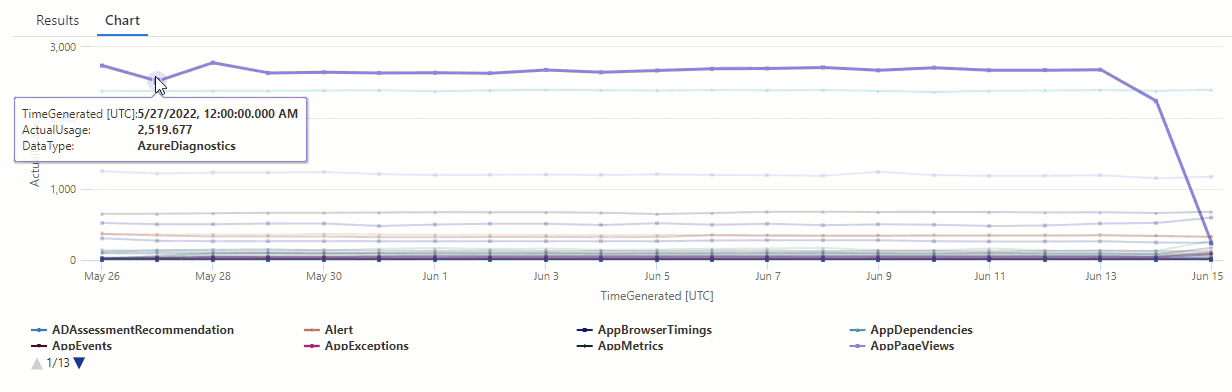
接下来,我们将使用 KQL 函数列出时序中的所有异常。
注意
有关 make-series 语法和用法的详细信息,请参阅 make-series 运算符。
查找时序中的异常
series_decompose_anomalies() 函数将一系列值用作输入并提取异常。
让我们将时序查询的结果集作为输入提供给 series_decompose_anomalies() 函数:
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we're analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage) // Scores and extracts anomalies based on the output of make-series
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
此查询返回过去三周内所有表的所有使用异常:

查看查询结果,可以看到该函数执行了以下操作:
- 计算每个表的预期每日使用量。
- 将实际每日使用量与预期使用量进行比较。
- 为每个数据点分配一个异常分数,指示实际使用量与预期使用量的偏差程度。
- 标识每个表中的正 (
1) 和负 (-1) 异常。
注意
有关 series_decompose_anomalies() 语法和用法的详细信息,请参阅 series_decompose_anomalies()。
微调异常情况检测设置以细化结果
最好查看初始查询结果,并在必要时对查询进行微调。 输入数据中的离群值可能影响函数的学习,你可能需要调整函数的异常情况检测设置才能获取更准确的结果。
筛选 series_decompose_anomalies() 查询的结果以显示 AzureDiagnostics 数据类型中的异常:

结果显示 6 月 14 日和 6 月 15 日有两个异常。 将这些结果与第一个 make-series 查询的图表进行比较,在其中可以看到 5 月 27 日和 28 日的其他异常:

之所以结果存在差异,是因为 series_decompose_anomalies() 函数相对于预期使用量值对异常进行评分,而该函数根据输入时序中的整个值范围进行计算。
若要从该函数获取更精确的结果,请在函数的学习过程中排除 6 月 15 日的数据,因为与时序中的其他值相比,它是一个离群值。
series_decompose_anomalies() 函数的语法为:
series_decompose_anomalies (Series[Threshold,Seasonality,Trend,Test_points,AD_method,Seasonality_threshold])
Test_points 指定要从学习(回归)过程中排除的时序末尾处的点的数量。
若要排除最后一个数据点,请将 Test_points 设置为 1:
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we're analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage,1.5,-1,'avg',1) // Scores and extracts anomalies based on the output of make-series, excluding the last value in the series - the Threshold, Seasonality, and Trend input values are the default values for the function
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
筛选 AzureDiagnostics 数据类型的结果:

第一个 make-series 查询的图表中的所有异常现在都出现在结果集中。
分析异常的根本原因
将预期值与离群值进行比较有助于了解两个集之间存在差异的原因。
KQL diffpatterns() 插件比较结构相同的两个数据集,并找出特征化这两个数据集之间的差异的模式。
此查询将 6 月 15 日的 AzureDiagnostics 使用量(示例中的极端离群值)与其他日期的表使用量进行比较:
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let anomalyDate = datetime_add('day',-1, make_datetime(startofday(ago(endtime)))); // Start of day of the anomaly date, which is the last full day in the time range in our example (you can replace this with a specific hard-coded anomaly date)
AzureDiagnostics
| extend AnomalyDate = iff(startofday(TimeGenerated) == anomalyDate, "AnomalyDate", "OtherDates") // Adds calculated column called AnomalyDate, which splits the result set into two data sets – AnomalyDate and OtherDates
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Defines the time range for the query
| project AnomalyDate, Resource // Defines which columns to return
| evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate") // Compares usage on the anomaly date with the regular usage pattern
该查询将表中的每个条目标识为发生在 AnomalyDate(6 月 15 日)或 OtherDates。 然后,diffpatterns() 插件拆分这些数据集 - 分别名为 A(示例中的 OtherDates)和 B(示例中的 AnomalyDate)- 并返回导致两个集出现差异的几种模式:

查看查询结果可以看到以下差异:
- 在查询时间范围内的所有其他日期,发生了 24,892,147 次从 CH1-GEARAMAAKS 资源引入数据的实例,而在 6 月 15 日,该资源没有数据引入。 从 CH1-GEARAMAAKS 资源引入的数据占查询时间范围内其他日期的总引入量的 73.36%,占 6 月 15 日总引入量的 0%。
- 在查询时间范围内的所有其他日期,有 2,168,448 个实例从 NSG-TESTSQLMI519 资源引入了数据;在 6 月 15 日,有 110,544 个实例从该资源引入了数据。 从 NSG-TESTSQLMI519 资源引入的数据占查询时间范围内其他日期的总引入量的 6.39%,占 6 月 15 日总引入量的 25.61%。
请注意,在构成其他日期时段的 20 天内,平均有 108,422 个实例(2,168,448 除以 20)从 NSG-TESTSQLMI519 资源引入。 因此,6 月 15 日从 NSG-TESTSQLMI519 资源引入的数据量与其他日期从该资源引入的数据量没有显著差异。 但是,由于 6 月 15 日未从 CH1-GEARAMAAKS 引入数据,因此与其他日期相比,从 NSG-TESTSQLMI519 引入的数据量占异常日期总引入量的百分比要大得多。
PercentDiffAB 列显示 A 和 B 之间的百分比差异绝对值 (|PercentA - PercentB|),即两个集之间的差异的主要度量值。 默认情况下,diffpatterns() 插件返回两个数据集之间超过 5% 的差异,但你可以微调此阈值。 例如,若要仅返回两个数据集之间 20% 或更大的差异,可以在上面的查询中设置 | evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate", "~", 0.20)。 该查询现在只返回一个结果:

注意
有关 diffpatterns() 语法和用法的详细信息,请参阅差异模式插件。
后续步骤
了解有关以下方面的详细信息: