你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
本文是指南在 Azure Monitor 中监视虚拟机及其工作负载的一部分。 Azure Monitor 中的警报会主动通知你在监视数据中发现的值得关注的数据和模式。 未针对虚拟机预配置警报规则,但你可以根据从 Azure Monitor 代理收集的数据创建自己的警报规则。 本文介绍特定于虚拟机的警报概念以及其他 Azure Monitor 客户经常使用的警报规则。
本方案描述如何实现对 Azure 和混合虚拟机环境的完整监视:
若要开始监视你的第一台 Azure 虚拟机,请参阅监视 Azure 虚拟机。
若要快速启用一组建议的警报,请参阅为 Azure 虚拟机启用建议的警报规则。
重要
大多数警报规则都会产生成本,具体成本取决于规则类型、规则包含的维度数量以及规则运行的频率。 在创建预警规则之前,请参阅 Azure Monitor 定价中的“预警规则”部分。
数据收集
警报规则检查已在 Azure Monitor 中收集的数据。 在创建警报规则之前,需要确保正在为特定方案收集数据。 请参阅使用 Azure Monitor 监视虚拟机:收集数据,获取有关为各种场景(包括本文中的所有警报规则)配置数据收集的指导。
建议的预警规则
Azure Monitor 提供了一组建议的警报规则,你可为任何 Azure 虚拟机快速启用这些规则。 这些规则是基本监控的良好起点。 但是,单独使用它们无法为大多数企业实现提供足够的警报,原因如下:
- 建议的警报仅适用于 Azure 虚拟机,而不适用于混合计算机。
- 建议的警报仅包括主机指标,而不包括来宾指标或日志。 这些指标可用于监视计算机本身的运行状况。 但是,它们仅提供了对机器上运行的工作负载和应用程序的有限可见性。
- 建议的警报与创建过多警报规则的单个计算机相关联。 请参阅缩放警报规则来了解为多个计算机使用极少量的警报规则的策略,而不要依赖于对每个计算机使用此方法。
警报类型
Azure Monitor 中最常见的警报规则类型是指标警报和日志搜索警报。 为特定方案创建的警报规则类型取决于触发警报的数据所在的位置。
你可能会遇到这种情况:某一特定警报方案的数据在指标和日志中都有提供。 如果是这样,则需要决定使用哪种规则类型。 你还可以灵活地收集某些数据,并由你所决定的警报规则类型来决定采用何种数据收集方法。
指标警报
指标警报的常见用途:
- 当特定指标超过阈值时发出警报。 例如,当计算机 CPU 的使用率较高时。
指标警报的数据源:
- 用于 Azure 虚拟机的主机指标,系统会自动收集这些指标
- Azure Monitor 代理从来宾操作系统中收集的指标
日志搜索警报
日志搜索警报的常见用途:
- 当找到 Windows 事件日志或 syslog 中的特定事件或事件模式时发出警报。 这些警报规则通常会度量从查询返回的表行。
- 根据多个计算机中数字数据的计算发出警报。 这些警报规则通常会度量查询结果中数字列的计算。
日志搜索警报的数据源:
- 在 Log Analytics 工作区中收集的所有数据
缩放警报规则
由于你可能需要以相同的方式监视许多虚拟机,因此你希望避免为每个虚拟机创建单独的警报规则。 你还想要确保有不同的策略根据规则类型来限制需要管理的警报规则数量。 其中每个策略取决于对警报规则的目标资源的理解程度。
指标警报规则
虚拟机支持多个资源指标警报规则,如监视多个资源中所述。 利用此功能,你便可以创建应用于同一区域内某个资源组或订阅中的所有虚拟机的单个指标警报规则。
从建议的警报开始,使用你的订阅或资源组作为目标资源来为每个警报创建相应的规则。 如果你在多个区域中部署了计算机,则需要为每个区域创建重复的规则。
确定更多指标警报规则的要求时,请遵循相同的策略,将订阅或资源组用作目标资源,以便:
- 最大程度地减少需要管理的警报规则数。
- 确保它们自动应用于任何新计算机。
日志搜索预警规则
如果将日志搜索预警规则的目标资源设置为特定计算机,则查询将仅限于与该计算机关联的数据,从而为它提供单独的警报。 对于这种安排,需要为每个计算机设置单独的警报规则。
如果将日志搜索预警规则的目标资源设置为 Log Analytics 工作区,则可以访问该工作区中的所有数据。 出于此原因,可以使用单个规则针对工作组中所有计算机的数据发出警报。 此安排让你可以选择为所有计算机创建单个警报。 然后,可以使用维度来为每个计算机创建单独的警报。
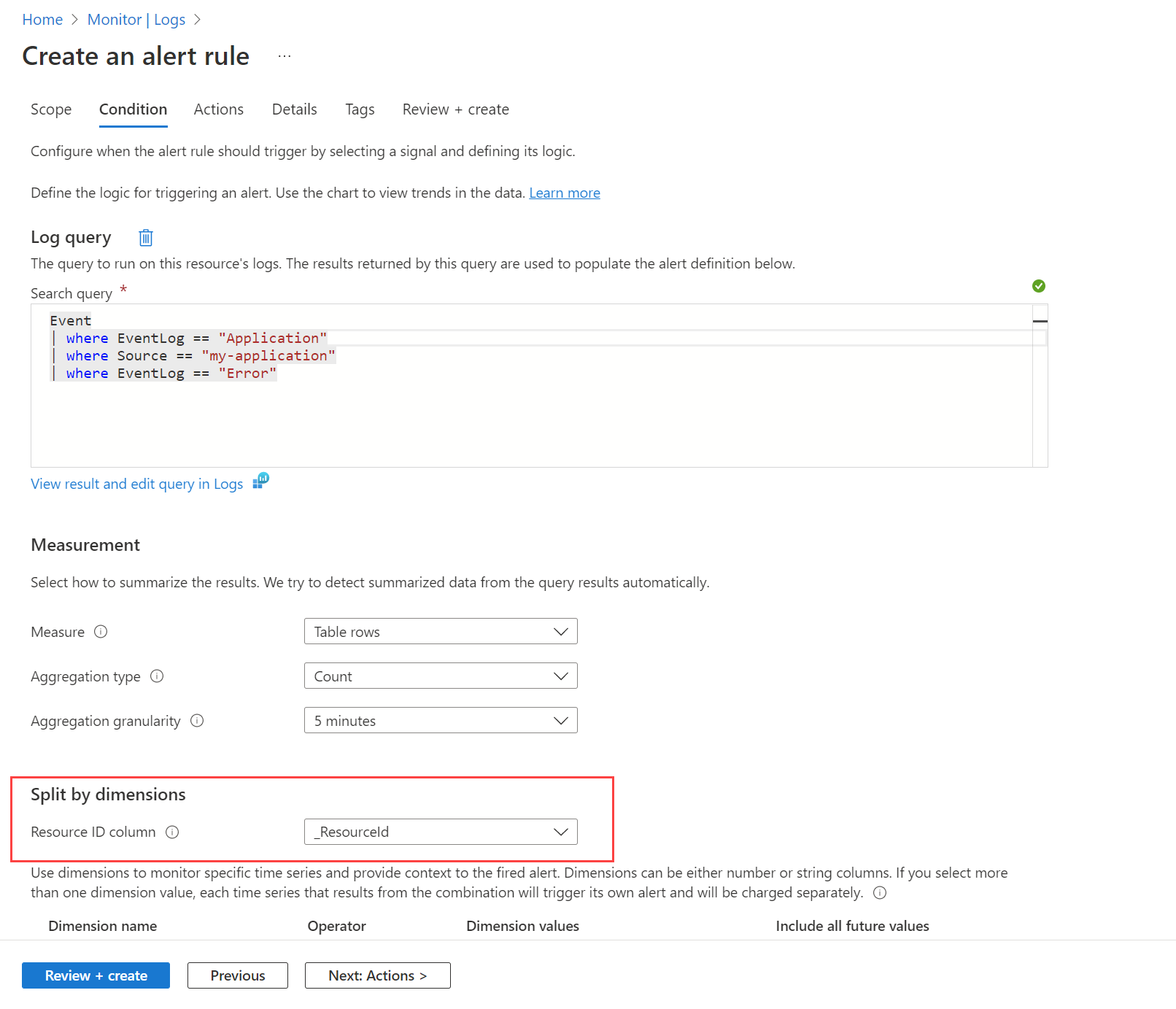
例如,您可能希望在任一计算机在 Windows 事件日志中创建错误事件时发送警报。 首先,需要按使用 Azure Monitor 代理收集数据中所述创建数据收集规则,以将这些事件发送到 Log Analytics 工作区中的 Event 表。 然后可以创建一个警报规则,以便使用工作区作为目标资源并使用如下图所示的条件来查询此表。
该查询会返回任何计算机上任何错误消息的记录。 使用“按维度拆分”选项并指定“_ResourceId”,以指示规则在结果中返回多个计算机时为每个计算机创建警报。
维度
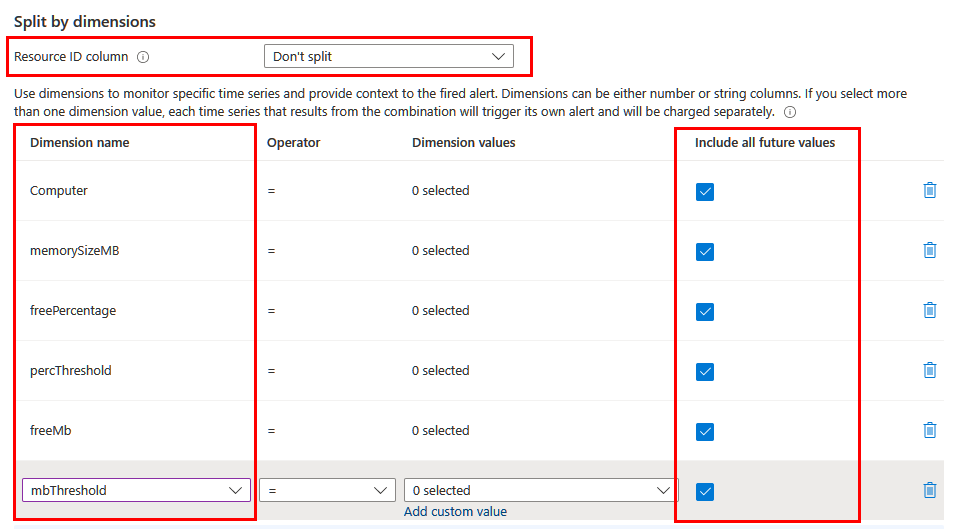
根据你要包含在警报中的信息,可能需要使用不同的维度进行拆分。 在这种情况下,请确保使用 project 或 extend 运算符在查询中投影所需的维度。 将“资源 ID 列”字段设置为“不拆分”,并在列表中包含所有有意义的维度。 确保选择“包含所有将来值”,以便包含从查询返回的任何值。
动态阈值
使用日志搜索预警规则的另一个好处是能够在用于确定阈值的查询中包含复杂逻辑。 可以对阈值进行硬编码,将其应用于所有资源,或者根据某个字段或计算值动态计算阈值。 阈值仅根据特定条件应用于资源。 例如,可以根据可用内存创建警报,但仅为具有特定总内存量的计算机创建该警报。
常用警报规则
以下部分列出了 Azure Monitor 中适用于虚拟机的常见警报规则。 将为每个指标警报和日志搜索警报提供详细信息。 有关应使用哪种警报类型的指导,请参阅警报类型。 如果不熟悉在 Azure Monitor 中创建警报规则的过程,请参阅有关新建警报规则的说明。
注意
此处提供的日志搜索警报详细信息使用通过 VM 见解收集的数据,VM 见解为客户端操作系统提供一组通用的性能计数器。 此名称与操作系统类型无关。
计算机可用性
虚拟机最常见的监视要求之一是在虚拟机停止运行时创建警报。 最佳方法是使用 VM 可用性指标在 Azure Monitor 中创建指标警报规则。 有关此指标的完整演练,请参阅为 Azure 虚拟机创建可用性警报规则。
警报规则限制为一个活动日志信号。 因此,对于每个条件,必须创建一个警报规则。 例如,“启动或停止虚拟机”需要两个警报规则。 但是,要在重启 VM 时发出警报,只需要一个警报规则。
如缩放警报规则中所述,使用订阅或资源组作为目标资源来创建可用性警报规则。 该规则应用于多个虚拟机,包括在警报规则之后创建的新计算机。
代理检测信号
代理心跳与计算机不可用警报略有不同,因为它依赖于 Azure Monitor 代理发送心跳信号。 如果计算机正在运行,但代理无响应,则代理检测信号会发出警报。
指标警报规则
每个 Log Analytics 工作区都包含一个称为“心跳”的指标。 连接到该工作区的每个虚拟机会每分钟发送一个检测信号指标值。 由于计算机是一个指标维度,因此当有任何计算机无法发送检测信号时,就可以触发警报。 将聚合类型设置为计数,并将阈值的数值调整为与评估粒度相匹配。
日志搜索预警规则
日志搜索警报使用心跳表,该表应每分钟从每台计算机获取一条心跳记录。
将规则与以下查询一起使用:
Heartbeat
| summarize TimeGenerated=max(TimeGenerated) by Computer, _ResourceId
| extend Duration = datetime_diff('minute',now(),TimeGenerated)
| summarize MinutesSinceLastHeartbeat = min(Duration) by Computer, bin(TimeGenerated,5m), _ResourceId
CPU 警报
本部分介绍 CPU 警报。
指标警报规则
| 目标 | 指标 |
|---|---|
| 主机 | CPU 百分比(建议的警报中包含) |
| Windows 来宾 | \处理器信息(_Total)% 处理器时间 |
| Linux 来宾 | 处理器/使用情况_活跃 |
日志搜索预警规则
CPU 使用率
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Processor" and Name == "UtilizationPercentage"
| summarize CPUPercentageAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
内存警报
本部分介绍内存警报。
指标警报规则
| 目标 | 指标 |
|---|---|
| 主机 | 可用内存字节数(预览版)(包含在建议的警报中) |
| Windows 来宾 | \Memory% Committed Bytes in Use \内存\可用字节 |
| Linux 来宾 | 内存/可用量 内存/可用百分比 |
日志搜索预警规则
注意
如果需要将警报指定到一个光盘,可将以下语句添加到查询中:| where parse_json(Tags).["vm.azm.ms/mountId"] == "C:" 可用内存 (MB)
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Memory" and Name == "AvailableMB"
| summarize AvailableMemoryInMBAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
可用内存(百分比)
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Memory" and Name == "AvailableMB"
| extend TotalMemory = toreal(todynamic(Tags)["vm.azm.ms/memorySizeMB"]) | extend AvailableMemoryPercentage = (toreal(Val) / TotalMemory) * 100.0
| summarize AvailableMemoryInPercentageAverage = avg(AvailableMemoryPercentage) by bin(TimeGenerated, 15m), Computer, _ResourceId
磁盘警报
本部分介绍磁盘警报。
指标警报规则
| 目标 | 指标 |
|---|---|
| Windows 来宾 | \Logical Disk(_Total)% Free Space \逻辑磁盘(_Total)\空闲兆字节 |
| Linux 来宾 | disk/free disk/free_percent |
日志搜索预警规则
使用的逻辑磁盘 - 每台计算机上的所有磁盘
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "FreeSpacePercentage"
| summarize LogicalDiskSpacePercentageFreeAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
使用的逻辑磁盘 - 独立磁盘
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "FreeSpacePercentage"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize LogicalDiskSpacePercentageFreeAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
逻辑磁盘 IOPS
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "TransfersPerSecond"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize DiskIOPSAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
逻辑磁盘数据速率
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "BytesPerSecond"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize DiskBytesPerSecondAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
网络警报
指标警报规则
| 目标 | 指标 |
|---|---|
| 主机 | 网络流入量总计、网络流出量总计(建议的警报中包含) |
| Windows 来宾 | \网络接口\每秒发送字节数 \逻辑磁盘(_Total)\空闲兆字节 |
| Linux 来宾 | disk/free disk/free_percent |
日志搜索预警规则
接收的网络接口字节数 - 所有接口
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "ReadBytesPerSecond"
| summarize BytesReceivedAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
接收的网络接口字节数 - 个别接口
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "ReadBytesPerSecond"
| extend NetworkInterface=tostring(todynamic(Tags)["vm.azm.ms/networkDeviceId"])
| summarize BytesReceievedAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, NetworkInterface
发送的网络接口字节数 - 所有接口
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "WriteBytesPerSecond"
| summarize BytesSentAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
发送的网络接口字节数 - 个别接口
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "WriteBytesPerSecond"
| extend NetworkInterface=tostring(todynamic(Tags)["vm.azm.ms/networkDeviceId"])
| summarize BytesSentAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, NetworkInterface
Windows 和 Linux 事件
在创建特定 Windows 事件时,以下示例将创建一个警报。 该示例使用指标测量警报规则为每台计算机创建单独的警报。
针对特定的 Windows 事件创建警报规则。 此示例显示了应用程序日志中的一个事件。 指定阈值 0,且连续违反次数大于 0。
Event | where EventLog == "Application" | where EventID == 123 | summarize NumberOfEvents = count() by Computer, bin(TimeGenerated, 15m)针对具有特定严重性的 Syslog 事件创建警报规则。 下面的示例显示了错误授权事件。 指定阈值 0,且连续违反次数大于 0。
Syslog | where Facility == "auth" | where SeverityLevel == "err" | summarize NumberOfEvents = count() by Computer, bin(TimeGenerated, 15m)
自定义性能计数器
创建有关计数器最大值的警报。
Perf | where CounterName == "My Counter" | summarize AggregatedValue = max(CounterValue) by Computer创建有关计数器平均值的警报。
Perf | where CounterName == "My Counter" | summarize AggregatedValue = avg(CounterValue) by Computer