你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
适用于: ![]() Azure SQL 数据库
Azure SQL 数据库 ![]() Azure SQL 托管实例
Azure SQL 托管实例
本页提供有关通过智能见解资源日志检测到的 Azure SQL 数据库和 Azure SQL 托管实例性能问题的信息。 指标和资源日志可以流式传输到 Azure Monitor 日志、Azure 事件中心、Azure 存储或用于自定义 DevOps 警报和报告功能的第三方解决方案中。
可检测的数据库性能模式
智能见解根据查询执行等待时间、错误或超时自动检测性能问题。 智能见解将检测到的性能模式输出到资源日志。 下表汇总了可检测的性能模式。
| 可检测性能模式 | Azure SQL 数据库 | Azure SQL 托管实例 |
|---|---|---|
| 达到资源限制 | 受监视订阅上的可用资源、数据库工作线程或数据库登录会话的消耗已达到其资源限制。 这会影响性能。 | CPU 资源的消耗达到其资源限制。 这会影响数据库性能。 |
| 工作负荷增大 | 检测到工作负荷增大,或数据库上的工作负荷持续累积。 这会影响性能。 | 检测到工作负荷增加。 这会影响数据库性能。 |
| 内存压力 | 请求内存授予的工作线程必须等待内存分配相当长的时间(就统计学意义来说),否则请求内存授予的工作线程会越积越多。 这会影响性能。 | 请求内存授予的工作线程会等待内存分配相当长的时间(就统计学意义来说)。 这会影响数据库性能。 |
| 锁定 | 检测到过度的数据库锁定,这影响性能。 | 检测到过度的数据库锁定,这影响数据库性能。 |
| MAXDOP 提升 | 最大并行度选项 (MAXDOP) 发生更改,影响查询执行效率。 这会影响性能。 | 最大并行度选项 (MAXDOP) 发生更改,影响查询执行效率。 这会影响性能。 |
| Pagelatch 争用 | 多个线程同时尝试访问相同的内存中数据缓冲区页面,导致等待时间变长并引发 Pagelatch 争用。 这会影响性能。 | 多个线程同时尝试访问相同的内存中数据缓冲区页面,导致等待时间变长并引发 Pagelatch 争用。 这会影响数据库性能。 |
| 缺少索引 | 检测到索引缺失,这影响性能。 | 检测到索引缺失,这影响数据库性能。 |
| 新建查询 | 检测到新查询,这影响总体性能。 | 检测到新查询,这影响数据库的总体性能。 |
| 等待时间延长统计信息 | 检测到数据库等待时间延长,这影响性能。 | 检测到数据库等待时间延长,这影响数据库的性能。 |
| TempDB 争用 | 多个线程尝试访问相同的 tempdb 资源,导致出现瓶颈。 这会影响性能。 |
多个线程尝试访问相同的 tempdb 资源,导致出现瓶颈。 这会影响数据库性能。 |
| 弹性池 DTU 不足 | 弹性池中的可用 eDTU 不足,这影响性能。 | 不适用于 Azure SQL 托管实例,因为它使用 vCore 模型。 |
| 计划回归 | 检测到新计划,或现有计划的工作负荷发生更改。 这会影响性能。 | 检测到新计划,或现有计划的工作负荷发生更改。 这会影响数据库性能。 |
| 数据库范围的配置值更改 | 检测到数据库中的配置更改,这影响数据库的性能。 | 检测到数据库中的配置更改,这影响数据库的性能。 |
| 客户端缓慢 | 应用程序客户端运行缓慢,无法以足够快的速度使用数据库的输出。 这会影响性能。 | 应用程序客户端运行缓慢,无法以足够快的速度使用数据库的输出。 这会影响数据库性能。 |
| 定价层降级 | 定价层降级操作减少了可用资源。 这会影响性能。 | 定价层降级操作减少了可用资源。 这会影响数据库性能。 |
提示
若要持续进行数据库性能优化,请启用自动优化。 此内置智能功能持续监视数据库、自动优化索引并应用查询执行计划更正措施。
以下部分更详细地描述了可检测性能模式。
达到资源限制
发生了什么
这种可检测性能模式合并了各种性能问题,涉及达到可用资源限制、工作线程限制和会话限制。 检测到这种性能问题之后,诊断日志的说明字段就会指示性能问题是否与资源、工作线程或会话限制相关。
Azure SQL 数据库上的资源通常称为 DTU 或 vCore 资源,Azure SQL 托管实例上的资源称为 vCore 资源。 如果检测到的查询性能下降是由于达到所度量资源限制而造成的,则认为出现了“达到资源限制”模式。
会话限制资源表示数据库允许的并发登录数量。 如果连接到数据库的应用程序数量达到了数据库允许的并发登录数量,则认为出现了此性能模式。 如果应用程序尝试使用的会话数超过了可在数据库中使用的数目,则会影响查询性能。
达到工作线程限制是一种特殊的达到资源限制的情况,因为可用工作线程数不会计入 DTU 或 vCore 用量。 数据库中达到工作线程限制可能会导致资源特定的等待时间延长,从而导致查询性能降低。
排查资源限制问题
诊断日志会输出影响性能和资源消耗百分比的查询的查询哈希。 可以使用此信息作为优化数据库工作负荷的入手点。 具体而言,可以通过添加索引优化那些导致性能降低的查询。 也可以让工作负荷分配更均衡,从而优化应用程序。 如果无法减少工作负载或进行优化,请考虑提高数据库订阅的定价层,以增加可用的资源量。
如果已达到可用会话限制,可以通过减少数据库登录次数来优化应用程序。 如果无法减少从应用程序到数据库的登录数,请考虑提高数据库订阅的定价层。 也可以将数据库拆分成多个数据库并进行移动,使工作负荷的分配更为均衡。
有关解决会话限制的更多建议,请参阅如何处理最大登录数的限制。 有关服务器和订阅级别限制的信息,请参阅 Azure SQL Database 中的资源管理。
工作负荷增大
发生了什么
此性能模式可识别由于工作负荷增大(更严重者,工作负荷堆积)而导致的问题。
这项检测是通过多个指标的组合来执行的。 度量的基本指标会根据以往的工作负荷基线检测工作负荷的增大情况。 另一种形式的检测基于对活动工作线程数的大幅提升的检测,这种提升率足以影响查询性能。
更严重时,由于数据库无法处理工作负载,导致工作负载不断堆积。 结果就是工作负荷不断增大,即出现工作负荷堆积情况。 因此,工作负荷等待执行的时间也增加。 这种情况代表最严重的数据库性能问题之一。 可通过监视已中止工作线程数的增加情况来检测此问题。
排查工作负载增长问题
诊断日志会输出执行时间已延长的查询数,以及对工作负荷增加影响最大的查询的查询哈希。 可以使用此信息作为优化工作负荷的入手点。 一开始可以确定对工作负荷增加影响最大的查询,这很有用。
可以考虑将工作负荷更均衡地分配到数据库。 考虑通过添加索引来优化影响性能的查询。 也可将工作负荷分配到多个数据库中。 如果此类解决方案不可行,请考虑提高数据库订阅的定价层,以增加可用的资源量。
内存压力
发生了什么
此性能模式指示由于出现内存压力(更严重者,出现内存堆积情况),当前数据库性能与过去七天的性能基线相比已降低。
内存压力表示一种性能状况,即有大量的工作线程在请求内存授予。 大量工作线程导致高内存利用率的状况,即数据库无法有效地将内存分配给请求内存的所有工作线程。 一方面,此问题最常见的原因之一与数据库的可用内存量有关。 另一方面,工作负荷增加导致工作线程数增加和内存压力增大。
内存压力增大时,更严重者会出现内存堆积的情况。 这种情况表明,请求内存授予的工作线程数超出释放内存的查询数。 请求内存授予的工作线程数量还可能会不断增加(堆积),因为数据库引擎无法足够有效地分配内存以满足需求。 内存堆积的情况代表最严重的数据库性能问题之一。
排查内存压力问题
诊断日志会输出内存对象存储详细信息,并输出已标记为内存使用率高最大原因的分配器(即工作线程)和相关时间戳。 可以将此信息用作故障排除的基础。
可以优化或删除与导致内存使用率最高的分配器相关的查询。 还可以确保不查询那些不打算使用的数据。 合理的做法是始终在查询中使用 WHERE 子句。 此外,建议创建非聚集索引来搜寻数据,而不是扫描数据。
还可以减少工作负荷,方法是对其进行优化,或者将其分配到多个数据库。 也可将工作负荷分配到多个数据库中。 如果此类解决方案不可行,请考虑提高数据库的定价层,以增加可供数据库使用的内存资源量。
有关其他故障排除建议,请参阅 Memory grants meditation: The mysterious SQL Server memory consumer with many names(内存授予探幽:有多个名称的神秘 SQL Server 内存消耗者)。 有关 Azure SQL 数据库中的内存不足错误的详细信息,请参阅排查 Azure SQL 数据库的内存不足错误。
锁定
发生了什么
此性能模式表示当前数据库性能降低,相比过去七天的性能基线,在这种性能情况下检测到的数据库锁定过多。
在现代 RDBMS 中,锁定对于实现多线程系统至关重要,这样可以通过尽可能地运行多个同步工作线程和并行数据库事务,最大程度地提高性能。 此上下文中的锁定是指一种内置访问机制,即只允许单个事务以独占方式访问所需的行、页、表和文件,不允许其他事务与之争用资源。 当锁定资源进行独占使用的事务用完资源后,对这些资源的锁定就会取消,允许其他事务访问所需资源。 有关锁定的详细信息,请参阅数据库引擎中的锁定。
如果 SQL 引擎执行的事务长时间等待访问已被锁定供独占使用的资源,这段等待时间会导致工作负荷在执行起来时变慢。
排查锁定和阻止问题
诊断日志会输出锁定详细信息,可将这些信息用作故障排除的基础。 可以分析报告的阻塞查询(即造成锁定性能降低的查询)并将其删除。 在某些情况下,可以成功优化阻塞查询。
缓解问题的最简单安全方法是保持较短的事务运行时间,并减少开销最高的查询的锁占用时间。 可以将大批操作分成小批操作。 合理的做法是尽量提高查询效率,减少查询时的锁定时间。 减少大型扫描,因为这些扫描会增大死锁的可能性,并对数据库总体性能造成负面影响。 对于识别出的导致锁定的查询,可以通过创建新索引或将列添加到现有索引来避免表扫描。
有关更多建议,请参阅:
增加的 MAXDOP
发生了什么
这种可检测的性能模式表示所选查询执行计划的并行化程度超出了预期。 查询优化器可以通过并行执行查询来提高工作负载性能,从而尽可能提高工作效率。 在某些情况下,处理查询的并行工作线程等待相互同步和合并结果所花费的时间,比使用较少的并行工作线程(有时甚至是一个工作线程)执行相同查询的时间还要长。
专家系统会对比基线期间来分析当前的数据库性能。 它会确定此前运行的某个查询是否运行得比以前更慢,因为查询执行计划的并行化程度比本来应有的程度更高。
MAXDOP 服务器配置选项用于控制并行执行同一查询时可以使用的 CPU 核心数。
排查并行问题
诊断日志会输出与查询相关的查询哈希,这些查询由于并行化程度超出预期,其执行持续时间延长。 日志还会输出 CXP 等待时间。 此时间表示单个组织器/协调器线程(线程 0)在合并结果并继续运行之前,等待其他所有线程完成的时间。 此外,诊断日志还会输出性能不佳的查询在执行过程中等待的总时间。 可以将此信息用作故障排除的基础。
首先,优化或简化复杂的查询。 合理的做法是将长时间运行的批处理作业分解成较小的作业。 此外,确保创建了用于支持查询的索引。 对于被标记为性能不佳的查询,也可通过手动方式强制实现最大并行度 (MAXDOP)。 若要使用 T-SQL 配置此操作,请参阅 Configure the MAXDOP server configuration option(配置 MAXDOP 服务器配置选项)。
将 MAXDOP 服务器配置选项设置为零 (0)(作为默认值)表示数据库可以使用所有可用的 CPU 核心来并行化线程以执行单个查询。 将 MAXDOP 设置为一 (1) 表示只能将一个核心用于单个查询的执行。 实际上,这意味着并行功能处于关闭状态。 根据具体的情况、数据库的可用核心数与诊断日志信息,可将 MAXDOP 选项优化成用于并行查询执行且能够解决具体问题的核心数。
Pagelatch 争用
发生了什么
此性能模式表示由于 Pagelatch 争用,当前数据库工作负荷的性能与过去七天的工作负荷基线相比有所降级。
闩锁是用于启用多线程处理的轻量同步机制。 该机制可保证内存中结构(包括索引、数据页以及其他内部结构)的一致性。
有多种类型的闩锁可用。 为了简单起见,可以使用缓冲区闩锁来保护缓冲池中的内存中页。 IO 闩锁用于保护尚未加载到缓冲池中的页。 每当在缓冲池的页中写入或读取数据时,工作线程需要首先获取该页的缓冲区闩锁。 每当工作线程尝试访问尚未在内存中缓冲池中提供的页时,就会发出 IO 请求,以便从存储中加载所需的信息。 这种事件序列指示更严重形式的性能降低。
当多个线程同时尝试获取同一内存中结构上的闩锁,从而造成查询执行的等待时间延长时,就会发生页闩锁争用。 如果在需要从存储访问数据时发生 Pagelatch IO 争用,这段等待时间甚至会更长, 并可能会显著影响工作负荷性能。 Pagelatch 争用是线程相互等待,在多个 CPU 系统上争用资源的最常见情景。
排查 pagelatch 争用问题
诊断日志输出 Pagelatch 争用详细信息。 可以将此信息用作故障排除的基础。
由于 Pagelatch 是一种内部控制机制,因此会自动确定何时使用它们。 应用程序决策(包括架构设计)可以影响因闩锁的确定性行为而导致的 Pagelatch 行为。
处理闩锁争用的一个方法是将有序索引键替换为无序键,以便在索引范围内均匀分配插入内容。 通常情况下,索引中的前导列可按比例分配工作负荷。 可考虑的另一种方法是表分区。 在分区表中创建一个包含计算列的哈希分区方案,是缓解过度闩锁争用的常用方法。 如果发生 Pagelatch IO 争用,可以引入索引来缓解此性能问题。
有关详细信息,请参阅 Diagnose and resolve latch contention on SQL Server(诊断和解决 SQL Server 上的闩锁争用)(PDF 下载)。
缺少索引
发生了什么
此性能模式表示由于缺少索引,当前数据库工作负荷的性能与过去七天的基线相比有所降级。
索引用于加速查询性能。 使用索引可以减少需要访问或扫描的数据集页数,因此能够快速访问表数据。
可以通过此项检测来识别导致性能降低的特定查询。创建索引对性能有利。
使用索引排查昂贵的查询问题
诊断日志会输出查询的查询哈希,这些查询已确定会影响工作负荷性能。 可以为这些查询生成索引。 还可以优化查询,或者删除不需要的那些查询。 在性能方面,合理的做法是避免查询不使用的数据。
新建查询
发生了什么
这种性能模式表示检测到一个性能不佳并影响工作负荷性能(与七天性能基线相比)的新查询。
有时,编写性能良好的查询很有难度。 有关编写查询的详细信息,请参阅 Writing SQL queries(编写 SQL 查询)。 若要优化现有的查询性能,请参阅查询优化。
查询性能故障排除
诊断日志会输出最多两个 CPU 消耗量最大的新查询的信息,包括其查询哈希。 由于检测到的查询影响工作负荷性能,可以优化查询。 最好是只检索需要使用的数据。 另外,建议使用带 WHERE 子句的查询。 并简化复杂的查询,将其分解成更小的查询。 将大批查询分解成小批查询也是好办法。 为新查询引入索引通常是缓解此性能问题的好办法。
在 Azure SQL 数据库中,请考虑使用适用于 Azure SQL 数据库的查询性能见解。
等待时间延长统计信息
发生了什么
这种可检测的性能模式表示确定的性能不佳的查询导致工作负荷的性能相比过去七天的工作负荷基线有所降级。
在这种情况下,系统无法将性能不佳的查询归到任何其他标准的可检测性能类别下,但确实检测到导致性能回归的等待统计信息。 因此,系统会将其视为具有等待时间延长统计信息的查询,并会在其中公开导致性能回归的等待时间统计信息。
排查等待统计信息问题
诊断日志会输出等待时间延长详情、受影响查询的查询哈希的信息。
由于系统无法成功识别查询性能不佳的根本原因,在手动故障排除时,诊断信息是很好的入手点。 可以优化这些查询的性能。 合理的做法是只提取需使用的数据,简化复杂的查询,将其分解成较小的查询。
有关优化查询性能的详细信息,请参阅查询优化。
tempdb 争用
发生了什么
这种可检测的性能模式表示这样一种数据库性能状况:尝试访问 tempdb 资源的线程存在瓶颈。 (此状况与 IO 无关。)此性能问题的典型情景是数百个并发查询都在创建、使用然后删除小型 tempdb 表。 系统已检测到使用相同 tempdb 表的并发请求数出现了统计学意义上的大幅增长,影响了数据库的性能(与过去七天的性能基线相比)。
排查 tempdb 争用问题
诊断日志输出 tempdb 争用详细信息。 可以将此信息用作故障排除的入手点。 可以通过两项操作来减轻此类争用并提高整个工作负荷的吞吐量:一是停止使用临时表, 二是使用内存优化表。
有关详细信息,请参阅内存优化表简介。
弹性池 DTU 不足
发生了什么
此可检测的性能模式表示当前数据库工作负荷的性能与过去七天的基线相比有所降级。 这是由于在订阅的弹性池中缺少可用的 DTU。
Azure 弹性池资源用作在多个数据库之间共享的可用资源,以实现缩放。 如果弹性池中的可用 eDTU 资源不够大,无法支持池中的所有数据库,则系统就会检测到“弹性池 DTU 不足”性能问题。
排查弹性池 DTU 短缺问题
诊断日志会输出有关弹性池的信息,列出 DTU 消耗量最大的数据库,并提供消耗量最大的数据库所使用的池 DTU 的百分比。
由于性能状况与使用弹性池中同一池 eDTU 的多个数据库相关,因此故障排除步骤侧重于 DTU 消耗量最大的数据库。 可以减少消耗量最大的数据库的工作负荷,包括优化这些数据库中消耗量最大的查询。 还可以确保不查询那些不使用的数据。 另一种做法是使用 DTU 消耗量最大的数据库来优化应用程序,在多个数据库之间重新分配工作负荷。
如果无法减少和优化 DTU 消耗量最大的数据库中的当前工作负荷,可以考虑提高弹性池定价层。 提高定价层可以增加弹性池中的可用 DTU。
计划回归
发生了什么
这种可检测的性能模式意味着数据库使用的不是最优的查询执行计划。 欠佳的计划通常会导致查询执行时间延长,从而导致当前查询和其他查询的等待时间变长。
数据库引擎确定查询执行开销最低的查询执行计划。 由于查询和工作负载的类型会发生变化,有时现有的计划不再有效,或者数据库引擎未能做出合理的评估。 作为一种纠正措施,可以手动强制查询执行计划。
这种可检测的性能模式合并了三种不同的计划回归情况:新计划回归、旧计划回归和现有计划更改的工作负荷。 诊断日志的“详细信息”属性中提供了出现的计划回归的特定类型。
新计划回归状况表示一种状态,即数据库引擎开始执行不如旧计划有效的新查询执行计划。 旧计划回归状况表示一种状态,即数据库引擎弃用更有效的新计划,改用不如新计划有效的旧计划。 现有计划更改的工作负荷回归表示这样一种状态:不断交替使用旧计划和新计划,天平逐渐倾向于性能不佳的计划。
有关计划回归的详细信息,请参阅 SQL Server 中的计划回归是什么?
排查计划回归问题
诊断日志输出查询哈希、正确计划 ID、错误计划 ID 和查询 ID。 可以将此信息用作故障排除的基础。
可以使用提供的查询哈希来分析哪个计划对于可识别的特定查询而言性能更好。 确定哪个计划更适合自己的查询后,可以手动强制该计划。
有关详细信息,请参阅 Learn how SQL Server prevents plan regressions(了解 SQL Server 如何阻止计划回归)。
数据库范围的配置值更改
发生了什么
这种可检测的性能模式表示数据库范围的配置发生更改,导致检测到性能回归(与过去七天的数据库工作负荷行为相比)。 此模式意味着,最近对数据库范围的配置所做的更改似乎对数据库性能不利。
可以针对每个数据库设置数据库范围的配置更改。 根据具体的情况使用此配置可以优化数据库的个体性能。 可以为每个单独的数据库配置以下选项:MAXDOP、LEGACY_CARDINALITY_ESTIMATION、PARAMETER_SNIFFING、QUERY_OPTIMIZER_HOTFIXES 和 CLEAR PROCEDURE_CACHE。
排查数据库范围的配置更改问题
诊断日志会输出最近进行的、导致性能相比过去七天的工作负荷行为有所降级的数据库范围配置更改。 可以将配置更改还原为以前的值。 也可对值逐个进行优化,直到达到所需性能级别。 可以从性能令人满意的类似数据库中复制数据库范围配置值。 如果无法排查性能问题,请还原为默认值,并尝试从此基线开始进行微调。
有关优化数据库范围配置的详细信息以及更改配置时使用的 T-SQL 语法,请参阅 Alter database-scoped configuration (Transact-SQL)(更改数据库范围的配置 (Transact SQL))。
客户端缓慢
发生了什么
这种可检测的性能模式表示,使用数据库的客户端使用数据库输出的速度赶不上数据库发送结果的速度。 由于数据库不会在缓冲区中存储所执行查询的结果,因此它的速度会变慢并等待客户端使用传输的查询输出,然后再继续。 此状况也可能与网络相关,即该网络无法以足够快的速度将输出从数据库传输到使用方客户端。
仅当检测到性能回归(与过去七天的数据库工作负荷行为相比)时,才会产生这种状况。 仅当性能与过去的性能行为相比,在统计学上有显著的降级时,才会检测到这种性能问题。
排查客户端应用程序问题
这种可检测的性能模式指示客户端的情况。 必须在客户端应用程序或客户端网络上进行故障排除。 诊断日志会输出在过去两小时内让客户端等待最长时间来使用的查询哈希和等待时间。 可以将此信息用作故障排除的基础。
可以优化应用程序在使用这些查询时的性能。 还可以考虑可能的网络延迟问题。 由于性能降低问题的检出是基于最近七天性能基线的更改,因此可以调查此性能回归事件是否因最近的应用程序或网络状况变化而导致。
定价层降级
发生了什么
这种可检测的性能模式表示数据库订阅的定价层已降级。 由于可供数据库使用的资源减少,系统检测到当前数据库性能相比过去七天的基线有所下降。
此外,可能会出现数据库订阅的定价层降级后,又在短时间内升级到更高层的情况。 检测到这种暂时性的性能降低时,会将检测结果作为定价层降级和升级输出到诊断日志的 details 节中。
排查定价层降级问题
如果降低了定价层,但对性能感到满意,则不需采取任何措施。 如果降低定价层后对数据库的性能不满意,请减少数据库工作负载,或考虑将定价层提升到更高的级别。
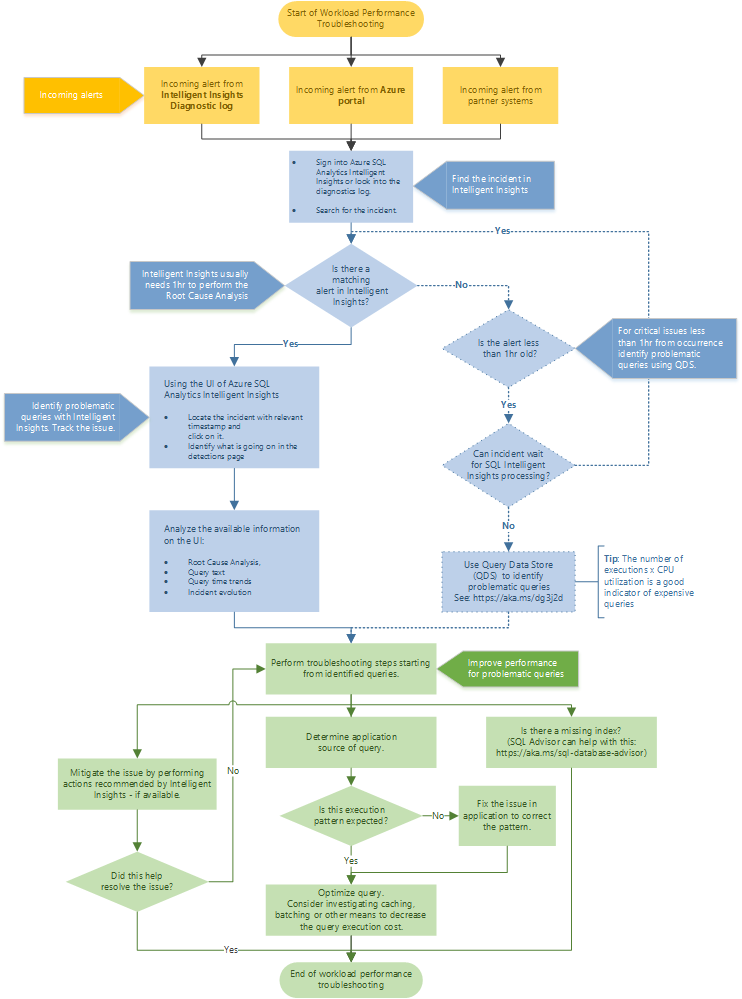
建议的故障排除流程
请遵循流程图,通过建议的方法使用 Intelligent Insights 排查性能问题。
通过在 Azure 门户中转到 Azure SQL Analytics 来访问 Intelligent Insights。 尝试找到传入的性能警报并选择它。 在检测页上确定发生了什么情况。 观察提供的问题根本原因分析、查询文本、查询时间趋势和事件演变情况。 使用用于缓解性能问题的 Intelligent Insights 建议来尝试解决问题。
提示
选择可下载 PDF 版本的流程图。
Intelligent Insights 通常需要花费一小时来针对性能问题执行根本原因分析。 如果在 Intelligent Insights 中找不到问题,而该问题又很重要,则请使用查询存储手动确定性能问题的根本原因。 (通常情况下,这些问题需要在一小时内找到。)有关详细信息,请参阅使用查询存储监视性能。