你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
数据登陆区域通过虚拟网络 (VNet) 对等互连连接到数据管理登陆区域。 每个数据登陆区域都被视为与 Azure 登陆区域体系结构相关的登陆区域。
重要
预配数据登陆区域之前,请确保已准备好 DevOps 和 CI/CD 操作模型,并部署好数据管理登陆区域。
每个数据登陆区域具有多个层,可灵活处理区域中包含的服务数据集成和数据产品。 可以使用一组标准服务来部署新的数据登陆区域,使数据登陆区域能够开始引入和分析数据。
与数据登陆区域关联的 Azure 订阅具有以下结构:
| 层 | 必须 | 资源组 |
|---|---|---|
| 核心服务 | 是 | |
| 数据应用程序 | 可选 |
|
| 可视化 | 可选 |
注意
数据应用程序生成一个或多个数据产品。
数据登陆区域体系结构
数据登陆区域的体系结构阐明了层、层中资源组以及每个资源组中包含的服务。 此体系结构还概述了与数据登陆区域关联的所有组和角色,以及其对控制和数据平面的访问程度。

提示
在部署数据登陆区域之前,请确保考虑要部署的初始数据登陆区域数。
使用此体系结构作为起点。 下载 Visio 文件,并在计划数据登陆区域实现时根据特定的业务和技术要求对其进行修改。
核心服务层
核心服务层包括在云级分析上下文中启用数据登陆区域所需的所有服务。 下表列出了在部署的每个数据登陆区域中提供标准可用服务套件的资源组。
| 资源组 | 必须 | 说明 |
|---|---|---|
network-rg |
是 | 网络 |
databricks-monitoring-rg |
可选 | 监视 Azure Databricks 工作区 |
hive-rg |
可选 | Azure Databricks 的 Hive 元存储 |
storage-rg |
是 | 数据湖服务 |
external-data-rg |
是 | 上传引入存储 |
runtimes-rg |
是 | 共享集成运行时 |
mgmt-rg |
是 | CI/CD 代理 |
metadata-ingestion-rg |
可选 | 与数据无关的引入 |
databricks-monitoring-rg |
可选 | 登陆区域中 Databricks 工作区的 Log Analytics 工作区 |
shared-synapse-rg |
可选 | 共享 Azure Synapse |
shared-databricks-rg |
可选 | 共享 Azure Databricks 工作区 |
网络
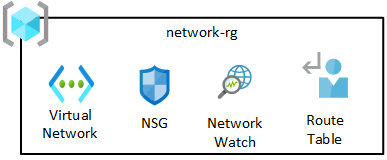
网络资源组包含核心组件,包括 Azure 网络观察程序、网络安全组 (NSG) 和虚拟网络。 所有这些服务都部署到单个资源组中。
数据登陆区域的虚拟网络会与数据管理登陆区域的 VNet 和连接订阅的 VNet 自动进行对等互连。
Azure Databricks 工作区监视
此资源组是可选的,仅使用 Azure Databricks 进行部署。
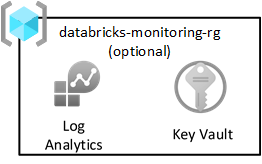
Azure 登陆区域模式建议将所有日志发送到中央 Log Analytics 工作区。 但是,每个数据登陆区域还包括一个监视资源组,用于从 Databricks 中捕获 Spark 日志。 每个资源组都包含共享 Log Analytics 工作区和 Azure Key Vault,用于存储 Log Analytics 密钥。
重要
仅在 Databricks 监视资源组中使用 Log Analytics 工作区来捕获 Azure Databricks Spark 日志。
有关详细信息,请参阅监视 Azure Databricks。
Azure Databricks 的 Hive 元存储
此资源组是可选的,应仅使用 Azure Databricks 进行部署。
Azure Databricks 的 Hive 元存储预配 Azure Database for MySQL 数据库和密钥保管库。 数据登陆区域中的所有 Azure Databricks 工作区都将此元存储用作其外部 Apache Hive 元存储。
有关详细信息,请参阅外部 Apache Hive 元存储。
数据湖服务
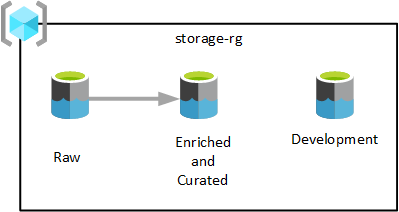
如上图所示,单个数据湖服务资源组中预配了三个 Azure Data Lake Storage Gen2 帐户。 在不同阶段转换的数据保存在数据登陆区域的其中一个数据湖中。 数据可供分析、数据科学和可视化团队使用。
数据湖层使用的术语因技术和供应商而异。 下表提供了有关如何应用云级分析术语的指导:
| 云规模分析 | Delta Lake | 其他术语 | 说明 |
|---|---|---|---|
| 原始 | Bronze | 登陆和合规性 | 引入表 |
| 扩充 | Silver | 标准化区域 | 优化表。 记录系统中存储的完整实体及待用的记录集。 |
| 策划 | Gold | 产品区域 | 功能表或聚合表。 应用程序、团队和用户使用数据产品的主要区域。 |
| 开发 | -- | 开发区域 | 数据工程师和数据科学家所在的位置,由分析沙盒和产品开发区域构成。 |
注意
在上图中,每个数据登陆区域都有三个数据湖。 但是,根据你的需求,你可能想要将原始层、扩充层和策展层合并到一个存储帐户中,并维护另一个名为“开发”的存储帐户,供数据使用者引入其他有用的数据产品。
有关详细信息,请参阅:
- 用于云级分析的 Azure 数据湖存储概述
- 数据标准化
- 为每个数据登陆区域预配 Azure Data Lake Storage Gen2 帐户
- Azure Data Lake Storage 的重要注意事项
- Azure Data Lake Storage 中的访问控制和数据湖配置
上传引入存储
第三方数据发布者需要将数据移入平台中,以便数据应用程序团队可以将数据拉取到其数据湖中。 如下图所示,通过上传引入存储资源组可以为第三方预配 Blob 存储。
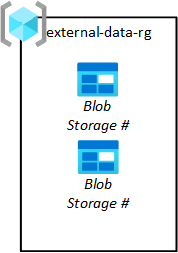
数据应用程序团队请求这些存储 Blob。 然后,数据登陆区域操作团队批准其请求。 将数据从其源存储 Blob 拉取到原始层后,应从该存储 Blob 中删除数据。
重要
由于 Azure 存储 Blob 是按需预配的,因此最初应在每个数据登陆区域中部署一个空的存储服务资源组。
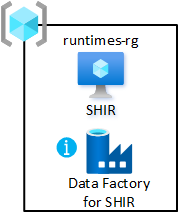
共享集成运行时
将具有自承载集成运行时的虚拟机部署到数据登陆区域。 将其托管在共享集成资源组中。 通过此部署,可以将数据产品快速加入到数据登陆区域。
若要启用资源组:
- 在数据登陆区域的共享集成资源组中创建至少一个 Azure 数据工厂。 它仅用于链接共享的自承载集成运行时,不用于数据管道。
- 在虚拟机上创建和配置自承载集成运行时 。
- 将自承载集成运行时与数据登陆区域中的 Azure 数据工厂相关联。
- 设置 Azure 自动化定期更新自承载集成运行时。
注意
上述部署提供具有自承载集成运行时的单个虚拟机部署。 可将一个自承载集成运行时关联到 Azure 中的多个本地计算机或虚拟机。 这些计算机称为节点。 最多可将 4 个节点与一个自承载集成运行时相关联。 在安装了某个网关作为逻辑网关的本地计算机上配置多个节点的好处如下:
- 更高的自承载集成运行时可用性,使其不再是大数据解决方案或云数据集成中的单点故障。 这种可用性有助于确保使用最多 4 个节点来实现连续性。
- 在本地和云数据存储之间移动数据期间提高了性能和吞吐量。 获取有关性能比较的更多信息。
可以通过从下载中心安装自承载集成运行时来关联多个节点。 然后,根据此教程中所述,使用通过 New-AzDataFactoryV2IntegrationRuntimeKey cmdlet 获取的任一身份验证密钥来注册自承载集成运行时。
Azure Datafactory 高可用性和可伸缩性中详细介绍了 Futher 信息。
重要
尽可能靠近数据源部署共享集成运行时。 这些部署不会限制数据登陆区域或第三方云中的集成运行时部署。 它会为云原生的区域内数据源提供回退。
CI/CD 代理
CI/CD 代理可帮助将数据应用程序及更改部署到数据登陆区域。
有关详细信息,请参阅 Azure 管道代理。
与数据无关的引入
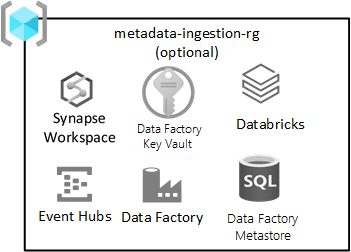
此资源组是可选的,它不会禁止你部署登陆区域。
如果具有(或正在开发)与数据无关的引入引擎,其根据注册元数据(包括连接字符串、数据复制路径以及引入计划)自动引入数据,则此资源组适用。 引入和处理资源组为此类框架提供关键服务。
部署 Azure SQL 数据库实例以保留 Azure 数据工厂使用的元数据。 预配 Azure Key Vault 以存储与自动化引入服务相关的机密。 这些机密可能包括:
- Azure 数据工厂元存储凭据
- 用于自动化引入过程的服务主体凭据
有关详细信息,请参阅自动化引入框架如何为 Azure 中的云级分析提供支持。
此资源组中包含的服务包括:
| 服务 | 必须 | 准则 |
|---|---|---|
| Azure 数据工厂 | 是 | Azure 数据工厂是业务流程引擎,用于与数据无关的引入。 |
| Azure SQL DB | 是 | Azure SQL DB 是 Azure 数据工厂的元存储。 |
| 事件中心或 IoT 中心 | 可选 | 事件中心或 IoT 中心可实时流式传输到事件中心,并通过 Databricks 工程工作区进行批量处理和流式处理。 |
| Azure Databricks | 可选 | 可以部署 Azure Databricks 或 Azure Synapse Spark,以便结合使用与数据无关的引入引擎。 |
| Azure Synapse | 可选 | 可以部署 Azure Databricks 或 Azure Synapse Spark,以便结合使用与数据无关的引入引擎。 |
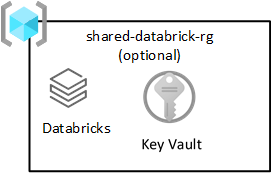
共享 Databricks
此资源组是可选的,仅使用 Azure Databricks 进行部署。 数据登陆区域中的每个人都可以使用 Databricks 工作区。
Azure Databricks 是 Azure Data Lake Storage 服务的关键使用方。 原子文件操作已针对 Spark 分析引擎进行了优化。 优化加快了 Azure Databricks 服务发出的 Spark 作业的完成速度。
重要
如共享产品资源组中所示,预配了一个名为 Azure Databricks(分析)工作区的 Azure Databricks 工作区,供所有数据科学家和 DataOps 使用。
可以将此工作区配置为使用 Microsoft Entra 直通或表访问控制连接到 Azure Data Lake。 根据用例,可以将条件访问配置为另一种安全措施。
遵循云级分析最佳做法集成 Azure Databricks:
Azure 登陆区域模式建议将所有日志发送到中央 Log Analytics 工作区。 但是,每个数据登陆区域还包含一个监视资源组,用于从 Databricks 中捕获 Spark 日志。
共享 Azure Synapse Analytics
此资源组是可选的。
在最初设置数据登陆区域的过程中,部署单个 Azure Synapse Analytics 工作区,以供共享产品资源组中的所有数据分析人员和数据科学家使用。
如果需要进行成本管理和重新交费,可以为数据产品设置更多 synapse 工作区。 数据应用程序团队可能会利用专用 Azure Synapse Analytics 工作区来创建专用 Azure SQL 数据库池,作为由可视化层使用的读取数据存储。
重要
通过将共享 Azure Synapse 工作区锁定为仅允许 SQL 按需查询,可防止将工作区用于创建数据产品。 它仅用于分析攻击行为。
数据应用程序
每个数据登陆区域可以有多个数据产品。 可以通过从源引入数据来创建这些数据产品。 也可以通过同一数据登陆区域内的其他数据产品创建数据产品,或从其他数据登陆区域创建数据产品。 创建数据产品需要经过数据专员的批准。
数据产品资源组
数据产品资源组产品包括制造该数据产品所需的所有服务。 例如,可视化工具使用的 MySQL 需要用到 Azure 数据库。 在将数据移入该 MySQL 数据库之前,必须引入和转换数据。 在这种情况下,可以将 Azure Database for MySQL 和 Azure 数据工厂部署到数据产品资源组。
提示
如果不选择实现与数据无关的引擎以从操作源进行一次引入,或者与数据无关的引擎中没有实现复杂连接,请创建一个源对齐数据应用程序。 有关详细信息,请参阅数据应用程序(源对齐)
有关如何加入数据产品的详细信息,请参阅 Azure 中的云级分析数据产品。
可视化效果
为每个数据登陆区域创建一个空的可视化效果资源组。 使用实现可视化解决方案所需的服务填充此资源组。 通过使用现有的 VNet 可以使解决方案连接到数据产品。
此资源组可以托管第三方可视化服务的虚拟机。
提示
由于许可成本,将第三方可视化产品部署到数据管理登陆区域并让这些产品跨数据登陆区域连接以拉回数据可能更经济。