你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
数据网格可帮助组织从集中式数据湖或数据仓库迁移到域驱动的分析数据分散,并强调以下四个原则:域所有权、数据即产品、自助服务数据平台和联合计算治理。 数据网格 提供分布式数据所有权和改进的数据质量和治理的优势,可加快组织的业务和价值实现时间。
数据网格实现
典型的数据网格实现包括域团队和生成数据管道的数据工程师。 团队维护操作和分析数据存储,如数据湖、数据仓库或数据湖屋。 他们将管道作为 数据产品 发布,供其他域团队或数据科学团队使用。 其他团队使用中央数据治理平台使用数据产品,如下图所示。
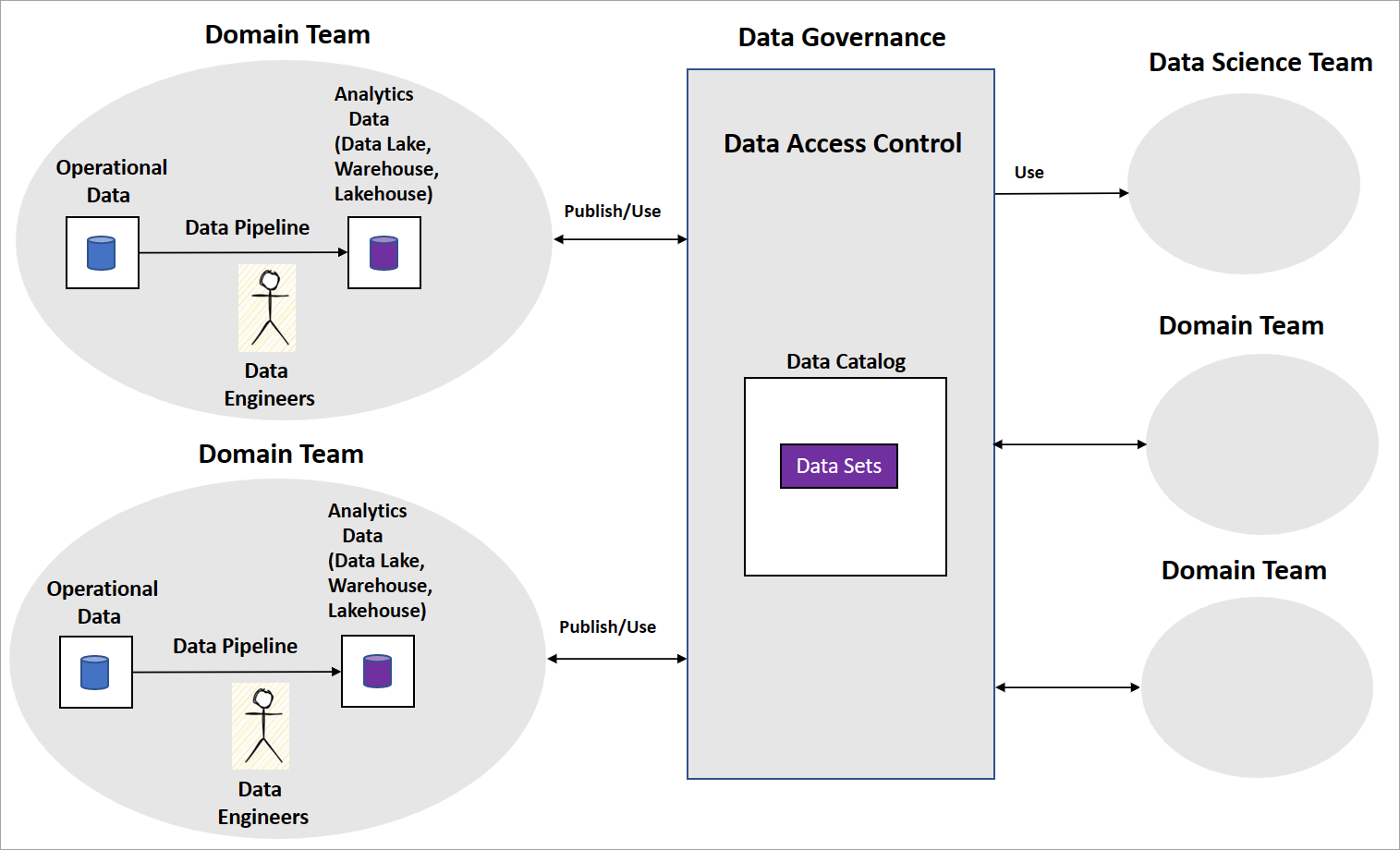
数据网格明确了数据产品如何为商业智能提供转换和聚合数据集。 但是,组织构建 AI/ML 模型时应采用的方法并不明确。 也没有有关如何构建其数据科学团队、AI/ML 模型治理以及如何在域团队之间共享 AI/ML 模型或功能的指南。
以下部分概述了组织可用于在数据网格中开发 AI/ML 功能的几个策略。 你会看到域驱动特征工程或特征网格策略的建议。
数据网格的 AI/ML 策略
组织采用数据科学团队作为数据使用者的一种常见策略。 这些团队根据用例访问数据网格中的各种域数据产品。 他们执行数据探索和特征工程,以开发和生成 AI/ML 模型。 在某些情况下,域团队还会使用其数据和其他团队的数据产品来扩展和派生新功能,从而开发自己的 AI/ML 模型。
特征工程 是模型构建的核心,通常很复杂,需要领域专业知识。 上述策略可能很耗时,因为数据科学团队随后需要分析各种数据产品。 他们可能没有完整的领域知识来构建高质量的功能。 缺乏域知识可能会导致域团队之间的功能工程工作重复。 此外,由于跨团队的功能集不一致,AI/ML 模型可重现性等问题。 随着新版本的数据产品的发布,数据科学或域团队需要不断刷新功能。
另一种策略是让域团队以 Open Neural Network Exchange (ONNX) 等格式发布 AI/ML 模型,但这些结果是黑盒,并且很难跨域组合 AI/模型或功能。
是否有方法可以跨域和数据科学团队分散 AI/ML 模型构建来应对挑战? 建议的域驱动特征工程或特征网格策略是一个选项。
域驱动的特征工程或特征网格
域驱动的特征工程或特征网格策略提供了一种分散的方法,用于在数据网格设置中构建 AI/ML 模型。 下图显示了策略及其如何解决数据网格的四main原则。
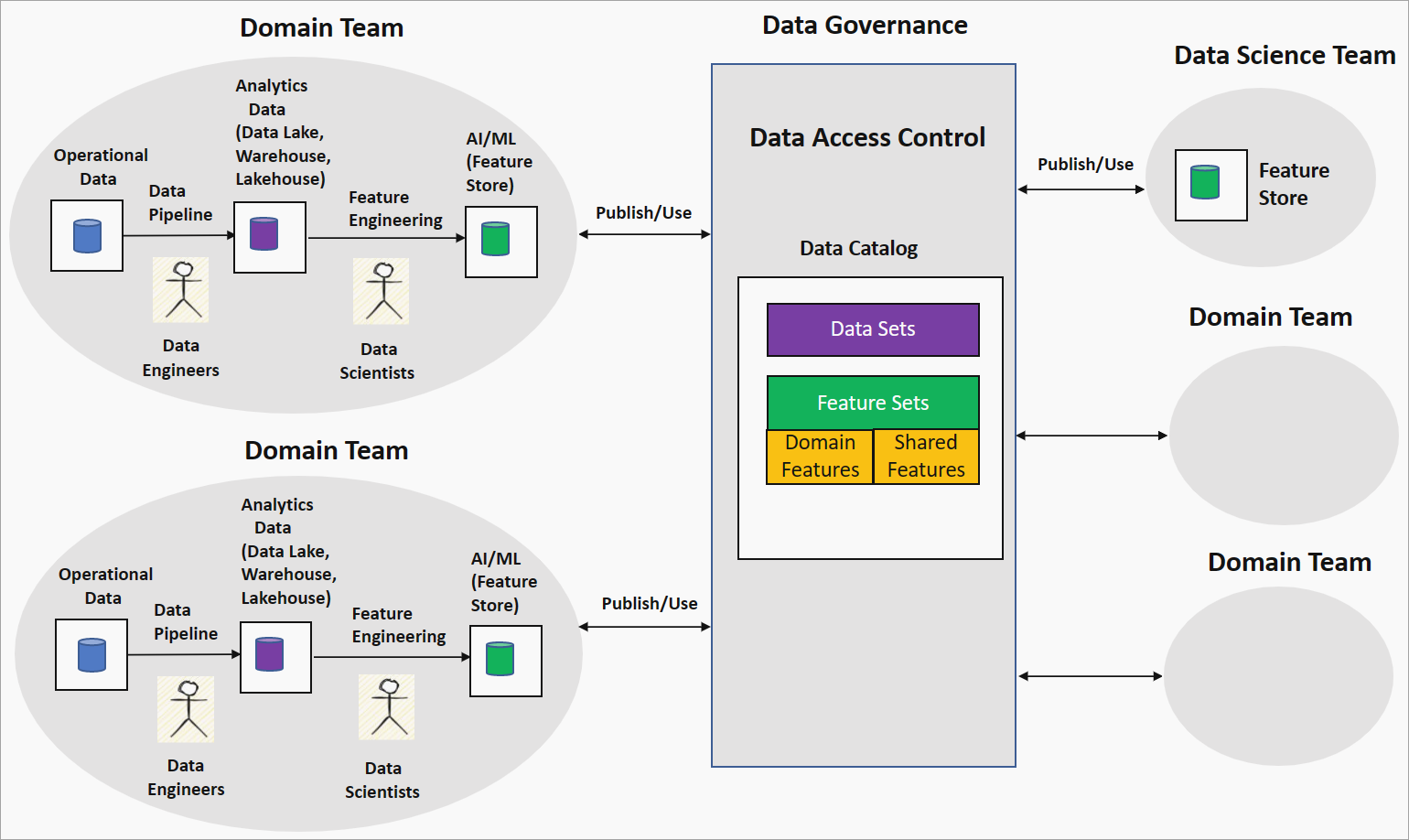
域团队的域所有权特征工程
在此策略中,组织将数据科学家与域团队中的数据工程师配对,以在数据湖(例如数据湖)中对干净和转换的数据运行数据探索。 工程生成存储在特征存储中的特征。 特征存储是一个数据存储库,它提供训练和推理功能,并帮助跟踪功能版本、元数据和统计信息。 此功能使域团队中的数据科学家能够与域专家密切合作,并在域中的数据更改时使功能保持刷新状态。
数据即产品:功能集
域团队生成的功能(称为域或本地功能)作为功能集发布到数据治理平台中的数据目录。 数据科学团队或其他域团队可以使用这些功能集来生成 AI/ML 模型。 在 AI/ML 模型开发期间,数据科学或域团队可以结合域功能来生成称为共享或全局特征的新功能。 这些共享功能将发布回功能集目录以供使用。
自助服务数据平台和联合计算治理:功能标准化和质量
此策略可能导致对功能工程管道采用不同的技术堆栈,并且域团队之间的功能定义不一致。 自助服务数据平台原则确保域团队使用通用基础结构和工具来构建功能工程管道并强制实施访问控制。 联合计算治理原则通过全球标准化和功能质量检查来确保特征集的互操作性。
使用域驱动的特征工程或特征网格策略为组织提供了一种分散的 AI/ML 模型构建方法,以帮助缩短 AI/ML 模型开发时间。 此策略有助于使各域团队的功能保持一致。 它避免了重复工作,并生成更准确的 AI/ML 模型的高质量功能,从而为业务增加价值。
Azure 中的数据网格实现
本文介绍有关在数据网格中实施 AI/ML 的概念,但不介绍用于构建这些策略的工具或体系结构。 Azure 提供的功能存储产品/服务,例如 Azure Databricks 功能存储和来自 LinkedIn 的 Feathr 。 可以开发 Microsoft Purview 自定义连接器来管理和管理功能存储。