你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
建议使用这些最佳做法,在 Microsoft Azure 中使用云规模分析来操作数据科学项目。
开发模板
开发一个模板,用于捆绑一组数据科学项目的服务。 使用捆绑一组服务的模板来帮助跨各种数据科学团队的用例提供一致性。 建议以模板存储库的形式开发一致的蓝图。 可以将此存储库用于企业内的各种数据科学项目,以帮助缩短部署时间。
数据科学模板指南
使用以下准则为组织开发数据科学模板:
开发一组基础结构即代码(IaC)模板,以部署Azure 机器学习工作区。 包括密钥保管库、存储帐户、容器注册表和 Application Insights 等资源。
包括这些模板中的数据存储和计算目标的设置,例如计算实例、计算群集和 Azure Databricks。
部署最佳做法
实时
- 在模板和 Azure 认知服务中包含 Azure 数据工厂或 Azure Synapse 部署。
- 模板应提供所有必要的工具来执行数据科学探索阶段和模型的初始操作。
初始设置的注意事项
在某些情况下,组织中的数据科学家可能需要一个环境来快速进行按需分析。 如果未正式设置数据科学项目,则这种情况很常见。 例如,由于缺少的元素需要审批,因此可能需要在 Azure 中进行交叉收费的项目经理、成本代码或成本中心。 你的组织或团队中的用户可能需要访问数据科学环境以了解数据并可能评估项目的可行性。 此外,由于数据产品数量较少,某些项目可能不需要完整的数据科学环境。
在其他情况下,可能需要一个完整的数据科学项目,包括专用环境、项目管理、成本代码和成本中心。 完整的数据科学项目对于想要在探索阶段成功后协作、共享结果和需要操作模型的多个团队成员非常有用。
设置过程
模板应在设置后按每个项目进行部署。 每个项目应至少接收两个实例,以便分离开发和生产环境。 在生产环境中,不应有个人访问权限,所有内容都应通过持续集成或持续开发管道和服务主体进行部署。 这些生产环境原则非常重要,因为Azure 机器学习在工作区中不提供基于角色的精细访问控制模型。 不能限制用户访问特定的一组试验、终结点或管道。
相同的访问权限通常适用于不同类型的工件。 请务必将开发与生产区分开来防止删除工作区中的生产管道或终结点。 除了模板,还需要构建一个流程,让数据产品团队可以选择请求新环境。
我们建议为每个项目设置不同的 AI 服务,例如 Azure 认知服务。 通过为每个项目设置不同的 AI 服务,将针对每个数据产品资源组进行部署。 此策略从数据访问的角度明确分离,并缓解了错误团队未经授权的数据访问的风险。
流式传输方案
对于实时和流式处理用例,应在缩减Azure Kubernetes 服务(AKS)上测试部署。 在部署到容器的生产 AKS 或 Azure 应用服务之前,可以在开发环境中进行测试以节省成本。 应执行简单的输入和输出测试,以确保服务按预期响应。
接下来,你可以将模型部署到所需的服务。 此部署计算目标是唯一一个正式发布,并推荐用于 AKS 群集中的生产工作负载的目标。 如果需要图形处理单元 (GPU) 或现场可编程门阵列支持,则此步骤更为必要。 支持这些硬件要求的其他本机部署选项当前在 Azure 机器学习中不可用。
Azure 机器学习需要到 AKS 群集的一对一映射。 与 Azure 机器学习工作区的每个新连接都会中断 AKS 和 Azure 机器学习之间的先前连接。 解决该限制后,我们建议将中央 AKS 群集部署为共享资源,并将它们附加到各自的工作区。
如果应在将模型移至生产 AKS 之前进行压力测试,则应托管另一个中央测试 AKS 实例。 测试环境应提供与生产环境相同的计算资源,以确保结果尽可能与生产环境相似。
批处理方案
并非所有用例都需要 AKS 群集部署。 如果大量数据仅需要定期评分或基于事件,则用例不需要 AKS 群集部署。 例如,大量数据量可以基于数据放入特定存储帐户时。 在这些类型的方案中,应使用 Azure 机器学习管道和 Azure 机器学习计算集群进行部署。 这些管道应该在数据工厂中编排和执行。
确定正确的计算资源
在将 Azure 机器学习中的模型部署到 AKS 之前,用户需要指定应为相应模型分配的资源,例如 CPU、RAM 和 GPU。 定义这些参数可能是一个复杂而繁琐的过程。 需要使用不同的配置执行压力测试,以识别一组良好的参数。 可以使用 Azure 机器学习 中的模型分析功能简化此过程,这是一个长时间运行的作业,它测试不同的资源分配组合,并使用标识的延迟和往返时间(RTT)来推荐最佳组合。 此信息可以帮助在 AKS 上部署实际模型。
为了安全地更新 Azure 机器学习中的模型,团队应使用受控推出功能(预览版)来最大限度地减少停机时间并保持模型的 REST 终结点一致。
MLOps 的最佳做法和工作流程
在数据科研存储库中包括示例代码
如果团队具有某些项目和最佳做法,则可以简化和加速数据科学项目。 我们建议创建所有数据科学团队可以在处理Azure 机器学习和数据产品环境各自的工具时使用的项目。 数据和机器学习工程师应创建并提供项目。
这些工件应包括:
示例笔记本展示了如何执行以下操作:
- 加载、装载和使用数据产品。
- 记录指标和参数。
- 将训练作业提交到计算集群。
操作化所需要的工件:
- Azure 机器学习管道示例
- Azure Pipelines 示例
- 执行管道需要更多脚本
文档
使用设计良好的工件来操作管道
工件可以加快数据科学项目的探索和操作阶段。 DevOps 分叉策略有助于在所有项目中扩展这些工件。 由于此设置可提升 Git 的使用,因此用户和整个自动化过程可以从提供的项目中受益。
提示
Azure 机器学习示例管道应使用 Python 软件开发工具包 (SDK) 或基于 YAML 语言构建。 新的 YAML 体验将更具前瞻性,因为 Azure 机器学习产品团队目前正在开发新的 SDK 和命令行界面 (CLI)。 Azure 机器学习产品团队确信 YAML 将成为Azure 机器学习内所有项目的定义语言。
示例管道不适用于每个项目,但可用作基线。 可以调整项目的示例管道。 管道应包括每个项目最相关的方面。 例如,管道可以引用计算目标、引用数据产品、定义参数、定义输入以及定义执行步骤。 应为 Azure Pipelines 完成相同的过程。 Azure Pipelines 还应使用 Azure 机器学习 SDK 或 CLI。
Pipelines 应演示如何执行以下操作:
- 从 DevOps 管道连接到工作区。
- 检查所需的计算是否可用。
- 提交作业。
- 注册和部署模型。
项目不适合所有项目,可能需要自定义,但拥有基础可以加快项目的运营和部署速度。
构建 MLOps 存储库
用户可能会遇到用户无法找到和存储项目的位置的情况。 为了避免这些情况,应请求更多时间来通信和构造标准存储库的顶级文件夹结构。 所有项目都应遵循文件夹结构。
注意
本节中提到的概念可以在本地、Amazon Web Services、Palantir 和 Azure 环境中使用。
下图演示了 MLOps(机器学习操作)存储库建议的顶级文件夹结构:
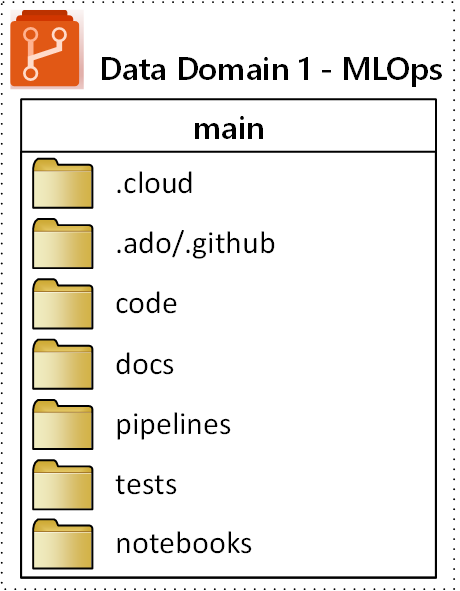
以下用途适用于存储库中的每个文件夹:
| Folder | 目的 |
|---|---|
.cloud |
在此文件夹中存储特定于云的代码和项目。 工件包括 Azure 机器学习工作区的配置文件,包括计算目标定义、作业、注册模型和终结点。 |
.ado/.github |
在此文件夹中存储 Azure DevOps 或 GitHub 项目,例如 YAML 管道或代码所有者。 |
code |
在此文件夹中包括作为项目一部分开发的实际代码。 此文件夹可以包含 Python 包和一些用于机器学习管道的各个步骤的脚本。 我们建议将需要在此文件夹中完成的各个步骤分开。 常见的步骤是预处理、模型训练和模型注册。 定义每个文件夹的依赖项,例如 Conda 依赖项、Docker 映像或其他依赖项。 |
docs |
将此文件夹用于文档目的。 此文件夹存储 Markdown 文件和图像以用于描述项目。 |
pipelines |
将此文件夹中Azure 机器学习管道定义存储在 YAML 或 Python 中。 |
tests |
编写需要执行的单元和集成测试,以发现此文件夹中项目早期出现的 bug 和问题。 |
notebooks |
使用此文件夹将 Jupyter 笔记本与实际的 Python 项目分开。 在文件夹内,每个人都应该有一个子文件夹来签入他们的笔记本并防止 Git 合并冲突。 |