你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
创建自定义图像分析模型(预览版)
图像分析 4.0 允许你使用自己的训练图像来训练自定义模型。 通过手动标记图像,你可以训练模型来将自定义标记应用于图像(图像分类)或检测自定义对象(对象检测)。 图像分析 4.0 模型在进行少样本学习时特别有效,因此使用较少训练数据即可获得准确的模型。
本指南介绍如何创建和训练自定义图像分类模型。 指出了训练图像分类模型和对象检测模型之间的一些差异。
先决条件
- Azure 订阅 - 免费创建订阅
- 拥有 Azure 订阅后,请在 Azure 门户中创建视觉资源,以获取密钥和终结点。 如果使用 Vision Studio 遵循本指南,则必须在美国东部区域创建资源。 部署后,选择”转到资源”。 将密钥和终结点复制到临时位置以供以后使用。
- Azure 存储资源 - 创建一个
- 一组用于训练分类模型的图像。 可以使用 GitHub 上的一组示例图像, 也可以使用自己的图像。 每个类只需要大约 3-5 个图像。
注意
不建议将自定义模型用于业务关键型环境,因为可能发生较高延迟。 当客户在 Vision Studio 中训练自定义模型时,这些自定义模型属于在其下训练它们的视觉资源,客户可以使用分析图像 API 调用这些模型。 当它们进行这些调用时,自定义模型将加载到内存中,并初始化预测基础结构。 发生这种情况时,客户在接收预测结果时可能会经历比预期更长的延迟。
创建新的自定义模型
首先转到 Vision Studio 并选择“图像分析”选项卡。然后选择“自定义模型”磁贴。
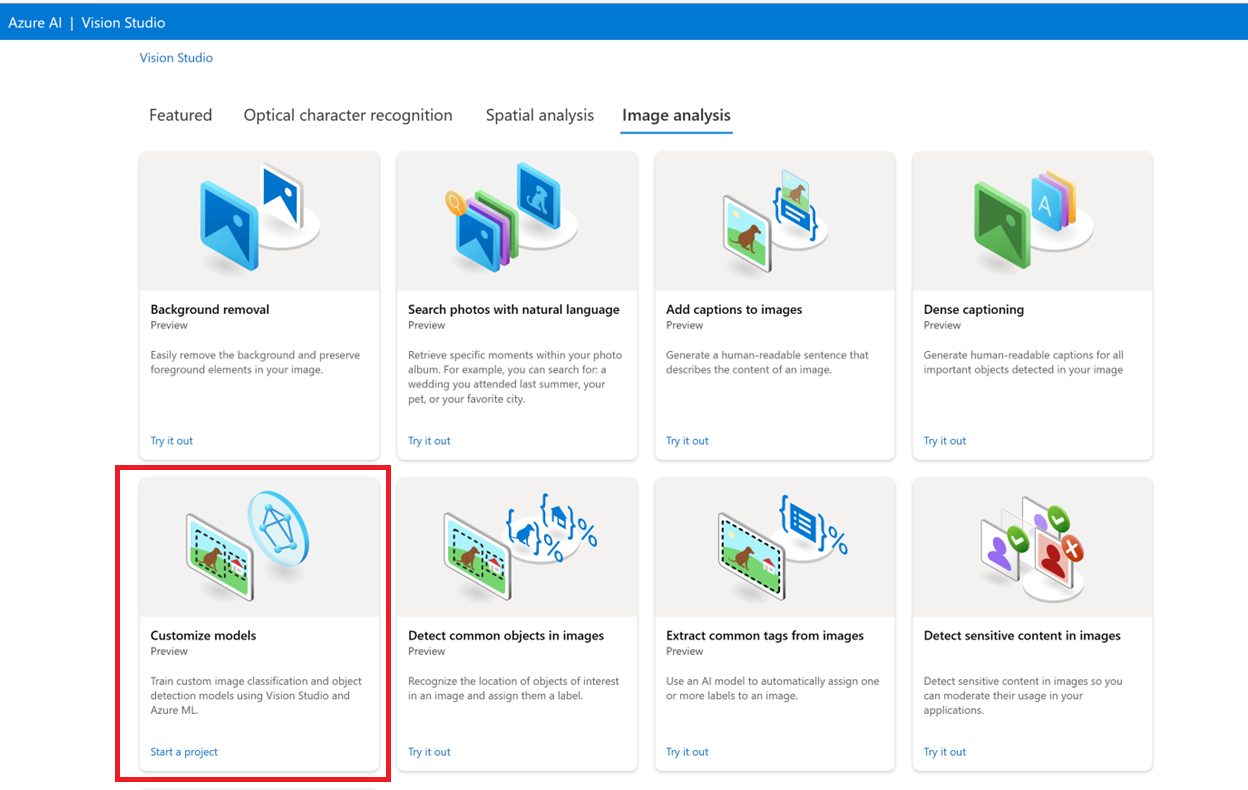
然后,使用 Azure 帐户登录并选择视觉资源。 如果你没有资源,可以在此屏幕中创建一个。
重要
若要在 Vision Studio 中训练自定义模型,你的 Azure 订阅需要获得访问许可。 请使用此表单请求访问权限。
准备训练图像
需要将训练图像上传到 Azure Blob 存储容器。 转到 Azure 门户中的存储资源,然后导航到“存储浏览器”选项卡。可以在此处创建 Blob 容器并上传图像。 将它们全部放在容器的根目录中。
添加数据集
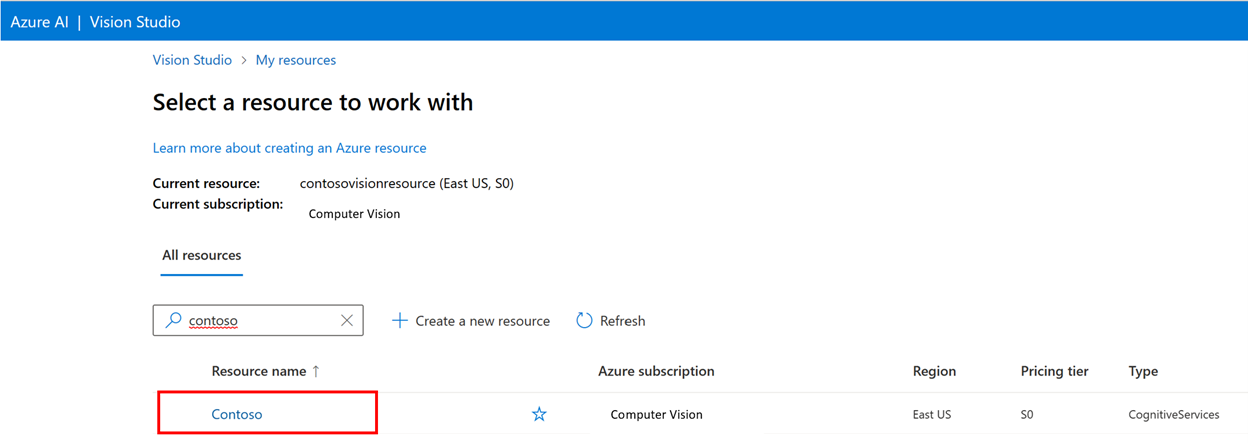
若要训练自定义模型,需要将其与你在其中提供图像及其标签信息作为训练数据的数据集相关联。 在 Vision Studio 中,选择“数据集”选项卡以查看数据集。
若要创建新数据集,请选择“添加新数据集”。 在弹出窗口中,输入名称并选择用例的数据集类型。 图像分类模型将内容标签应用于整个图像,而对象检测模型将对象标签应用于图像中的特定位置。 产品识别模型是针对检测零售产品的优化对象检测模型的子类别。
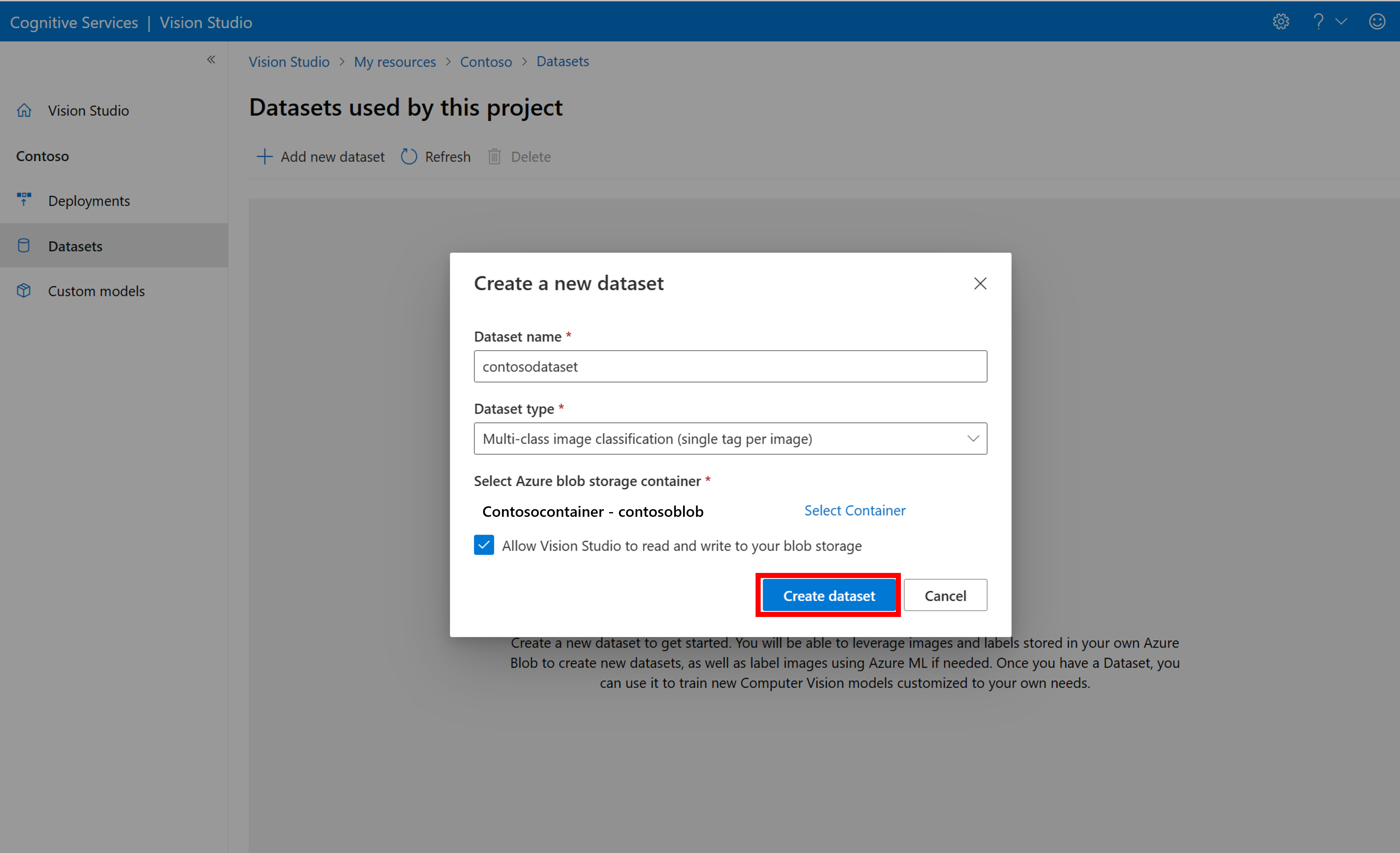
然后,从存储训练图像的 Azure Blob 存储帐户中选择容器。 选中该框以允许 Vision Studio 读取和写入 Blob 存储容器。 这是导入标记数据的必要步骤。 创建数据集。
创建 Azure 机器学习标记项目
你需要一个 COCO 文件来传达标记信息。 生成 COCO 文件的一种简单方法是创建 Azure 机器学习项目,该项目附带数据标记工作流。
在数据集详细信息页中,选择“添加新的数据标记项目”。 为其命名,然后选择“新建工作区”。 这会打开一个新的 Azure 门户选项卡,可在其中创建 Azure 机器学习项目。
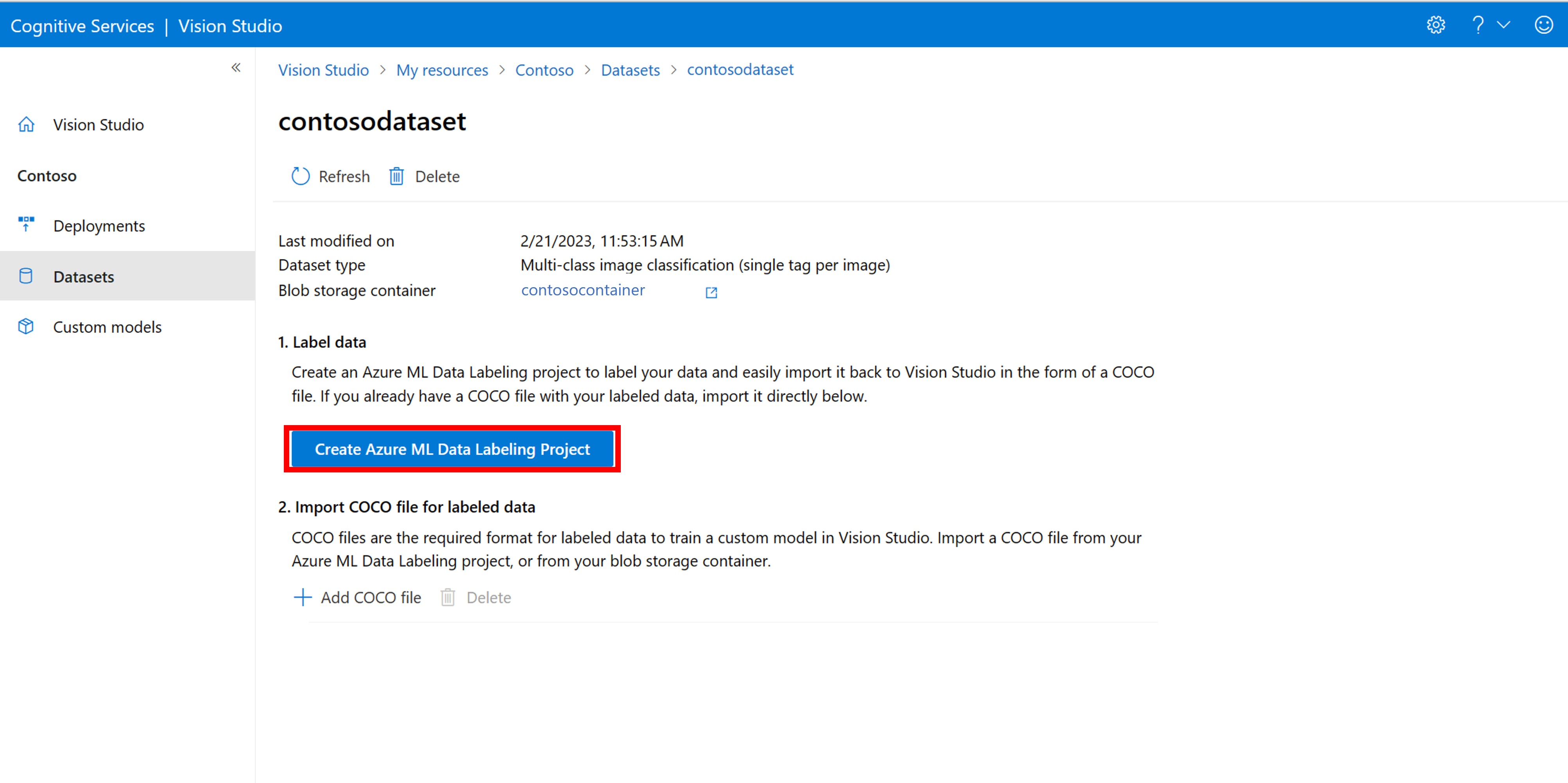
创建 Azure 机器学习项目后,返回到“Vision Studio”选项卡,并在“工作区”下选择它。 然后,Azure 机器学习门户将在新的浏览器选项卡中打开。
Azure 机器学习:创建标签
若要开始标记,请按照“请添加标签类”提示添加标签类。
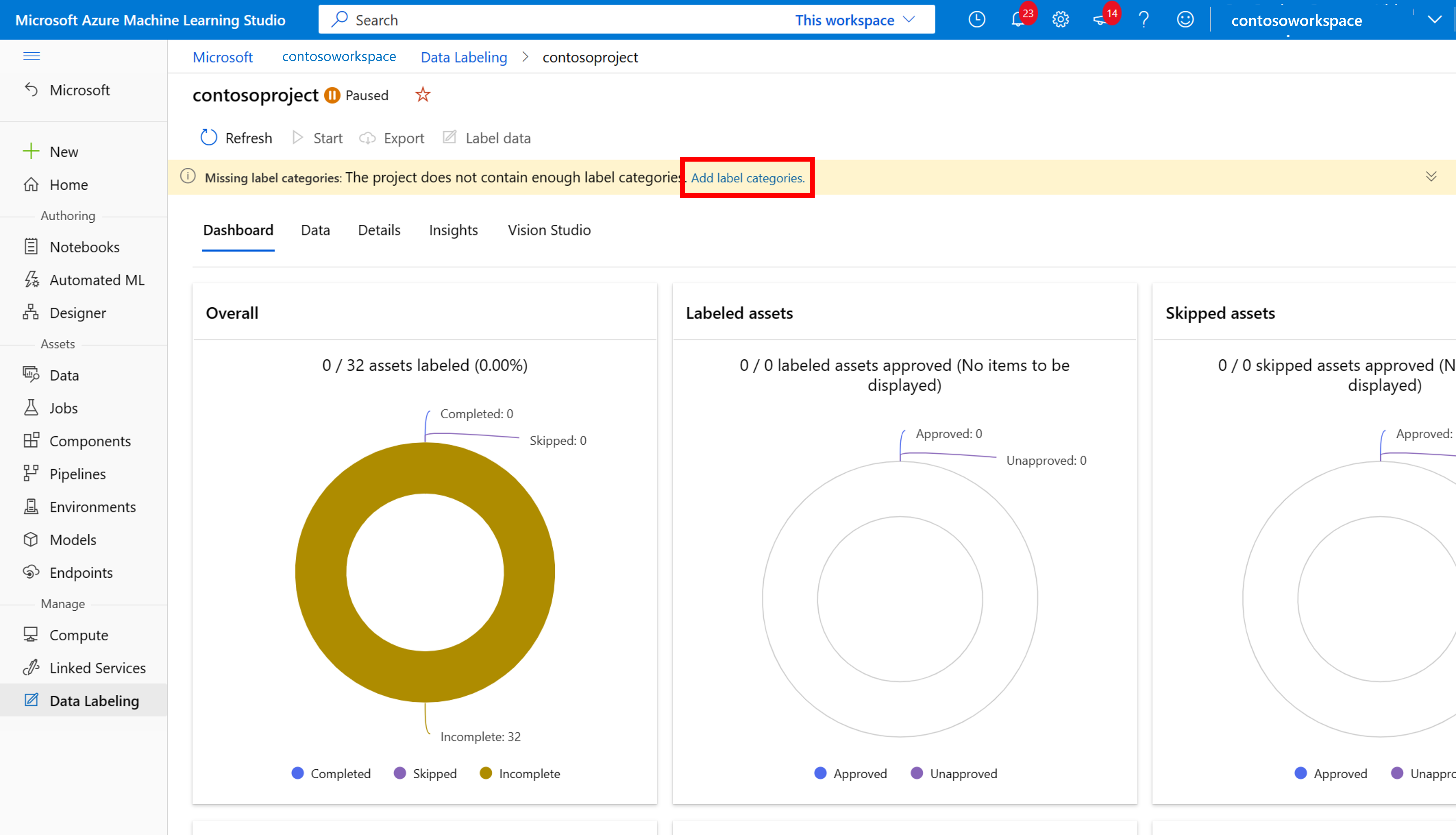
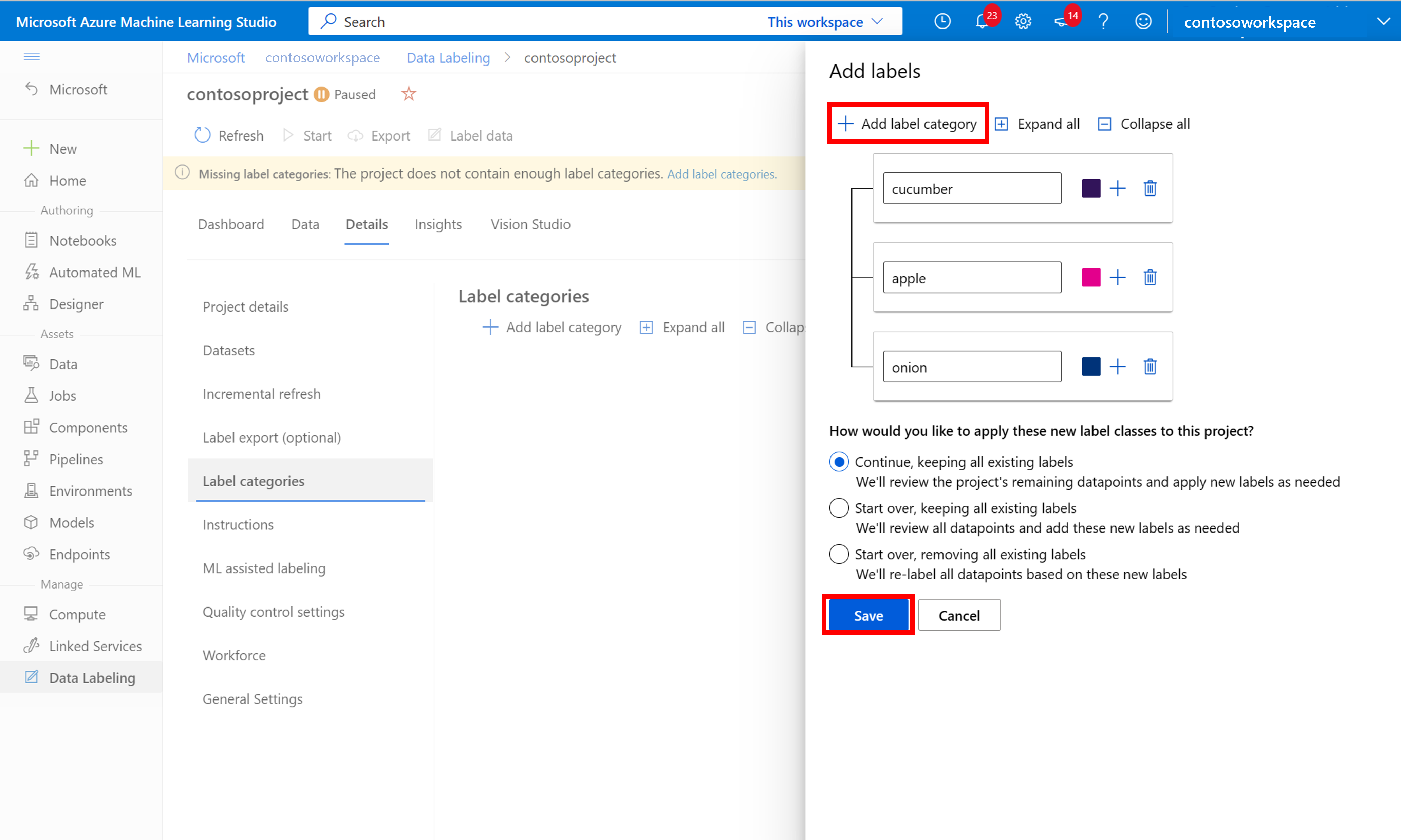
添加所有类标签后,保存它们,在项目上选择“开始”,然后选择顶部的“标记数据”。
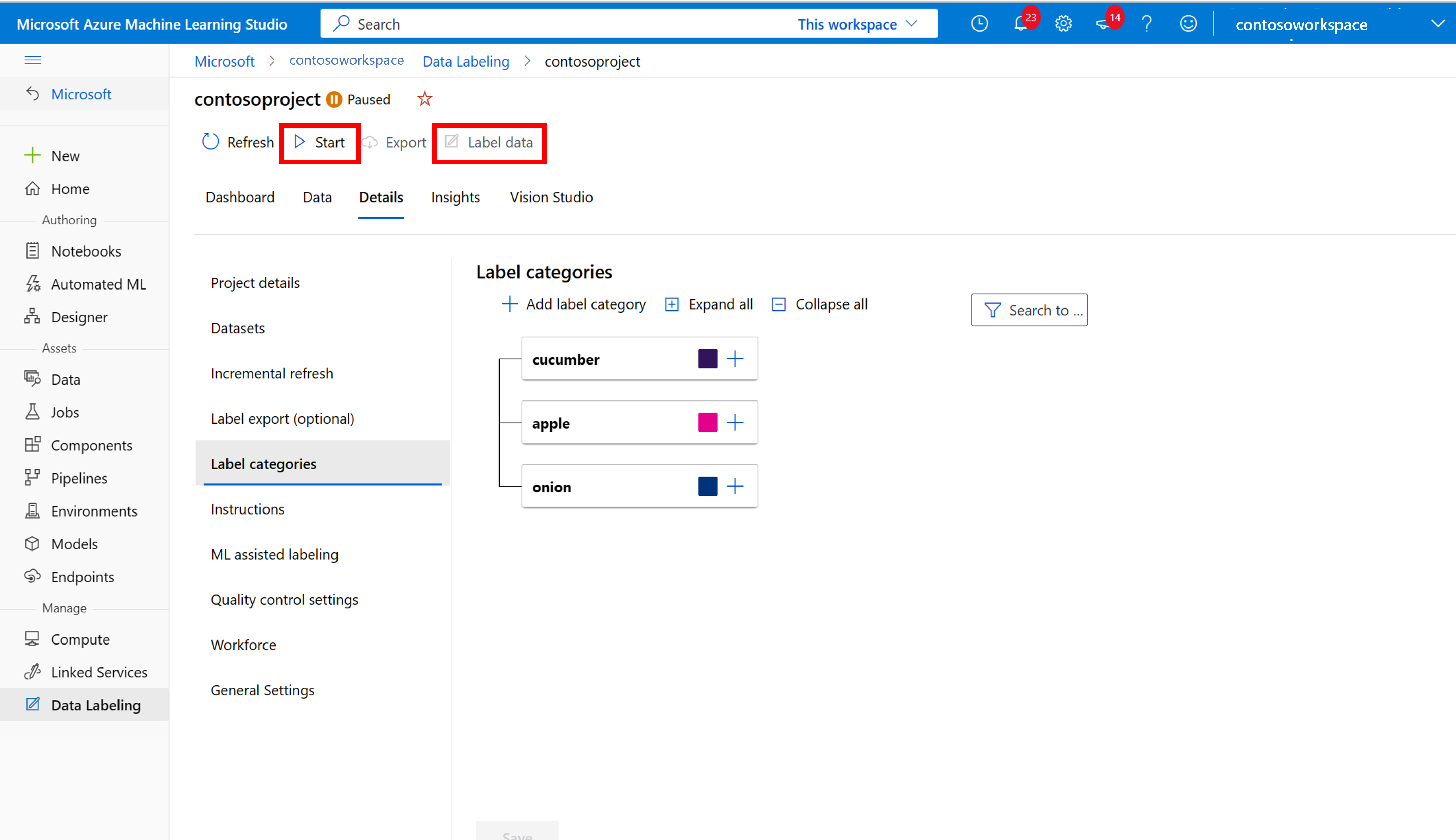
Azure 机器学习:手动标记训练数据
选择“开始标记”,并按照提示标记所有图像。 完成后,返回到浏览器中的“Vision Studio”选项卡。
现在,选择“添加 COCO 文件”,然后选择“从 Azure ML 数据标记项目导入 COCO 文件”。 这会从 Azure 机器学习导入标记的数据。
刚刚创建的 COCO 文件现在存储在链接到此项目的 Azure 存储容器中。 现在可以将其导入模型自定义工作流。 从下拉列表中选择它。 将 COCO 文件导入数据集后,数据集可用于训练模型。
注意
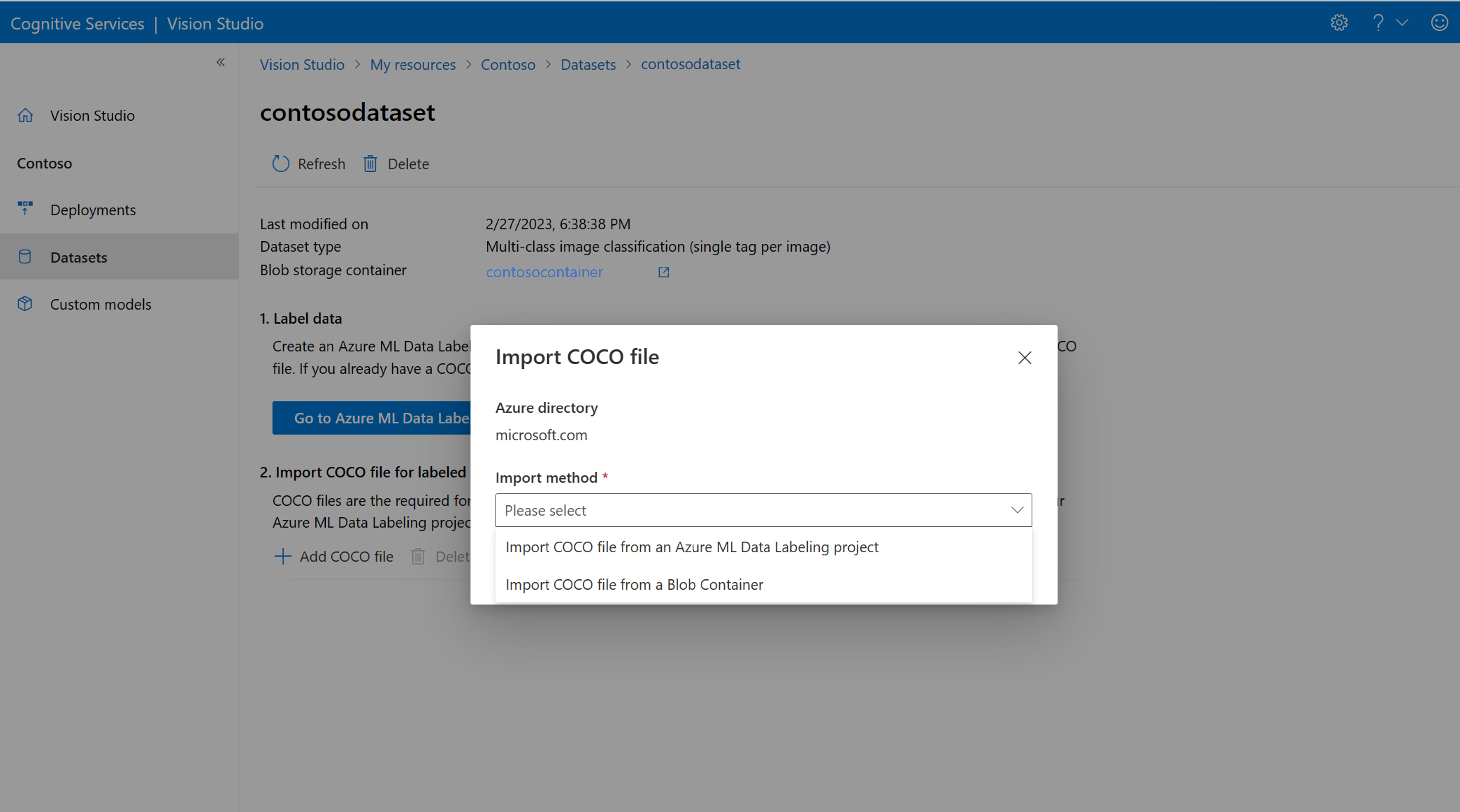
从其他位置导入 COCO 文件
如果要导入的现成 COCO 文件,请转到“数据集”选项卡并选择 Add COCO files to this dataset。 可以选择从 Blob 存储帐户添加特定 COCO 文件,也可以从 Azure 机器学习标记项目导入。
目前,Microsoft 正着手解决在 Vision Studio 中启动时大型数据集的 COCO 文件导入失败这一问题。 若要使用大型数据集进行训练,建议改用 REST API。
关于 COCO 文件
COCO 文件是包含特定必填字段的 JSON 文件:"images"、"annotations" 和 "categories"。 示例 COCO 文件如下所示:
{
"images": [
{
"id": 1,
"width": 500,
"height": 828,
"file_name": "0.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/0.jpg"
},
{
"id": 2,
"width": 754,
"height": 832,
"file_name": "1.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/1.jpg"
},
...
],
"annotations": [
{
"id": 1,
"category_id": 7,
"image_id": 1,
"area": 0.407,
"bbox": [
0.02663142641129032,
0.40691584277841153,
0.9524163571731749,
0.42766634515266866
]
},
{
"id": 2,
"category_id": 9,
"image_id": 2,
"area": 0.27,
"bbox": [
0.11803319477782331,
0.41586723392402375,
0.7765206955096307,
0.3483334397217212
]
},
...
],
"categories": [
{
"id": 1,
"name": "vegall original mixed vegetables"
},
{
"id": 2,
"name": "Amy's organic soups lentil vegetable"
},
{
"id": 3,
"name": "Arrowhead 8oz"
},
...
]
}
COCO 文件字段引用
如果要从头开始生成自己的 COCO 文件,请确保所有必填字段都填充了正确的详细信息。 下表描述了 COCO 文件中的每个字段:
“图像”
| 密钥 | 类型 | 说明 | 必需? |
|---|---|---|---|
id |
integer | 唯一图像 ID,从 1 开始 | 是 |
width |
integer | 图像的宽度(以像素为单位) | 是 |
height |
integer | 图像的高度(以像素为单位) | 是 |
file_name |
字符串 | 图像的唯一名称 | 是 |
absolute_url 或 coco_url |
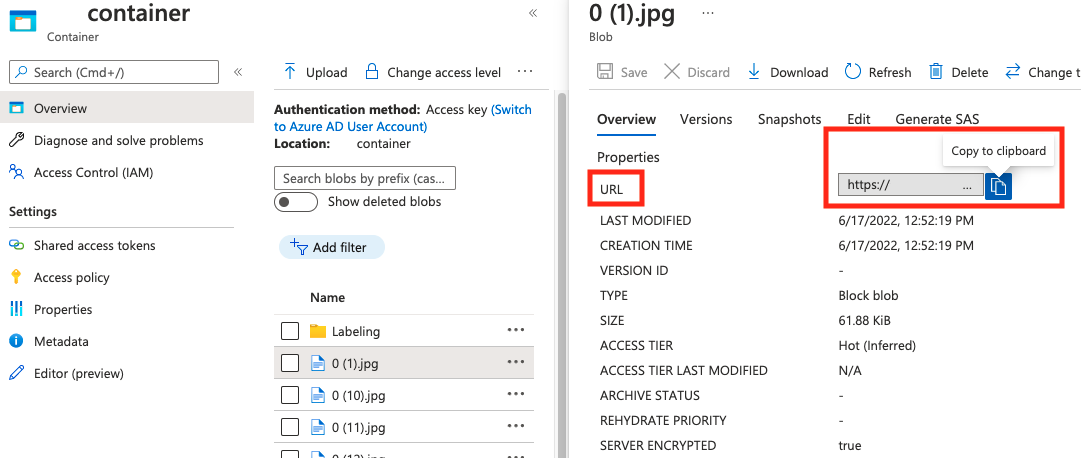
字符串 | 用作 Blob 容器中 Blob 的绝对 URI 的图像路径。 视觉资源必须有权读取注释文件和所有引用的图像文件。 | 是 |
可以在 Blob 容器的属性中找到 absolute_url 的值:
“注释”
| 密钥 | 类型 | 说明 | 必需? |
|---|---|---|---|
id |
integer | 注释的 ID | 是 |
category_id |
integer | categories 部分中定义的类别的 ID |
是 |
image_id |
integer | 图像的 ID | 是 |
area |
integer | “宽度”x“高度”的值(bbox 的第三和第四个值) |
否 |
bbox |
list[float] | 边界框的相对坐标(0 到 1),按“左”、“上”、“宽度”、“高度”的顺序排列 | 是 |
“类别”
| 密钥 | 类型 | 说明 | 必需? |
|---|---|---|---|
id |
integer | 每个类别(标签类)的唯一 ID。 这些内容应出现在 annotations 部分中。 |
是 |
name |
字符串 | 类别(标签类)的名称 | 是 |
COCO 文件验证
可以使用 Python 示例代码检查 COCO 文件的格式。
训练自定义模型
若要开始使用 COCO 文件训练模型,请转到“自定义模型”选项卡,然后选择“添加新模型”。 输入模型的名称,并选择 Image classification 或 Object detection 作为模型类型。
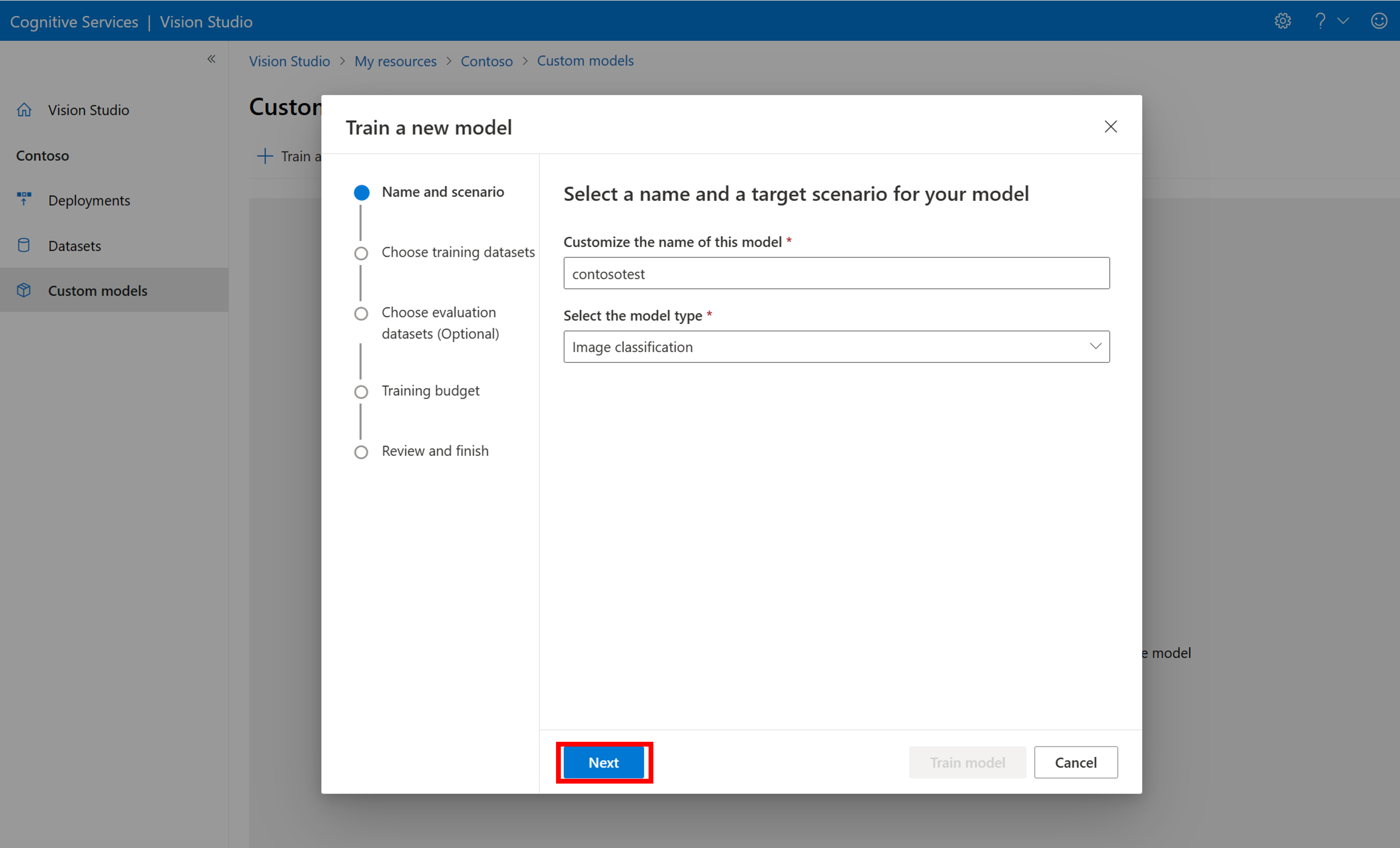
选择数据集,该数据集现在与包含标记信息的 COCO 文件相关联。
然后选择时间预算并训练模型。 对于小型示例,可以使用 1 hour 预算。
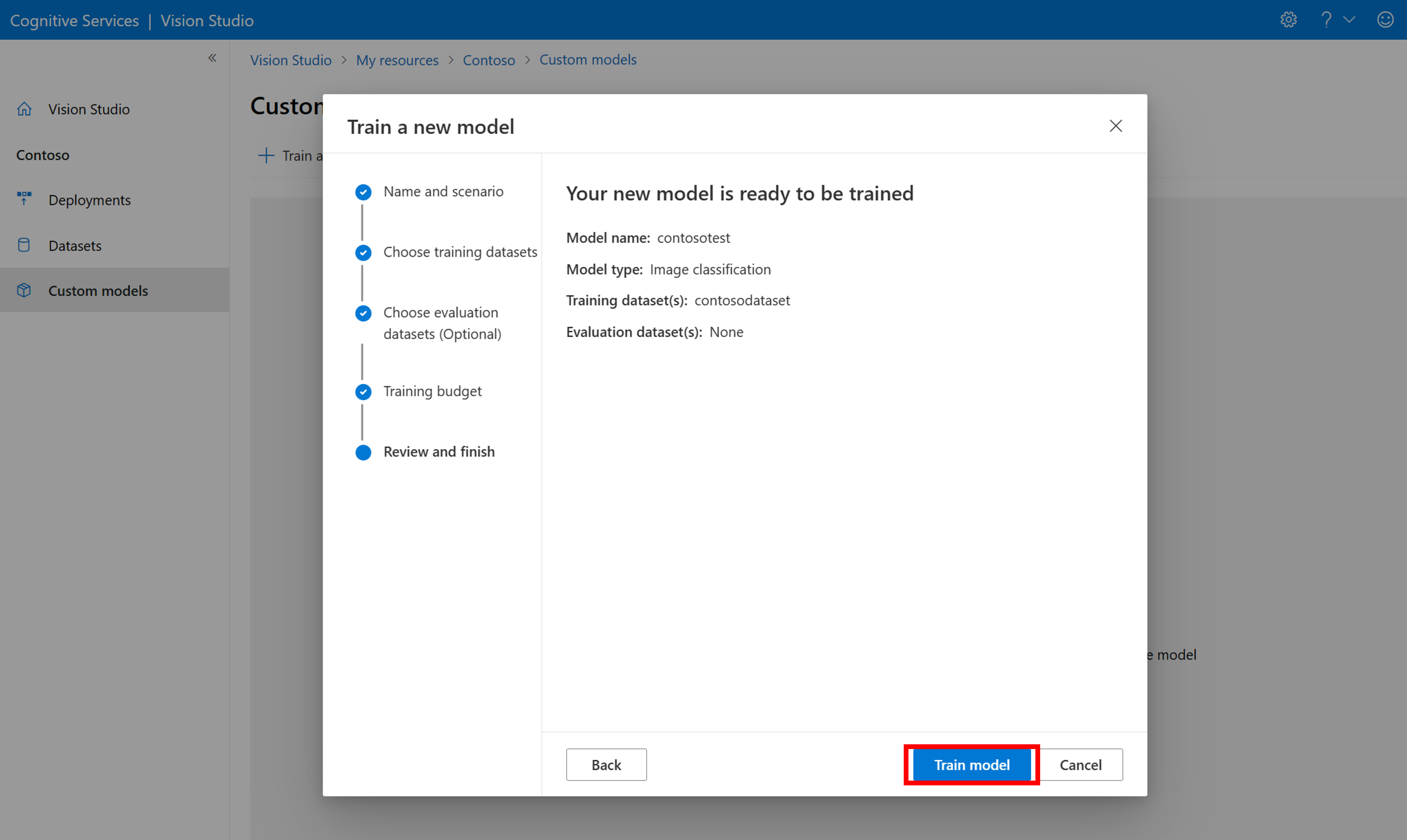
完成训练可能需要一些时间。 图像分析 4.0 模型只需一小组训练数据即可保持准确,但训练时间比以前的模型要长。
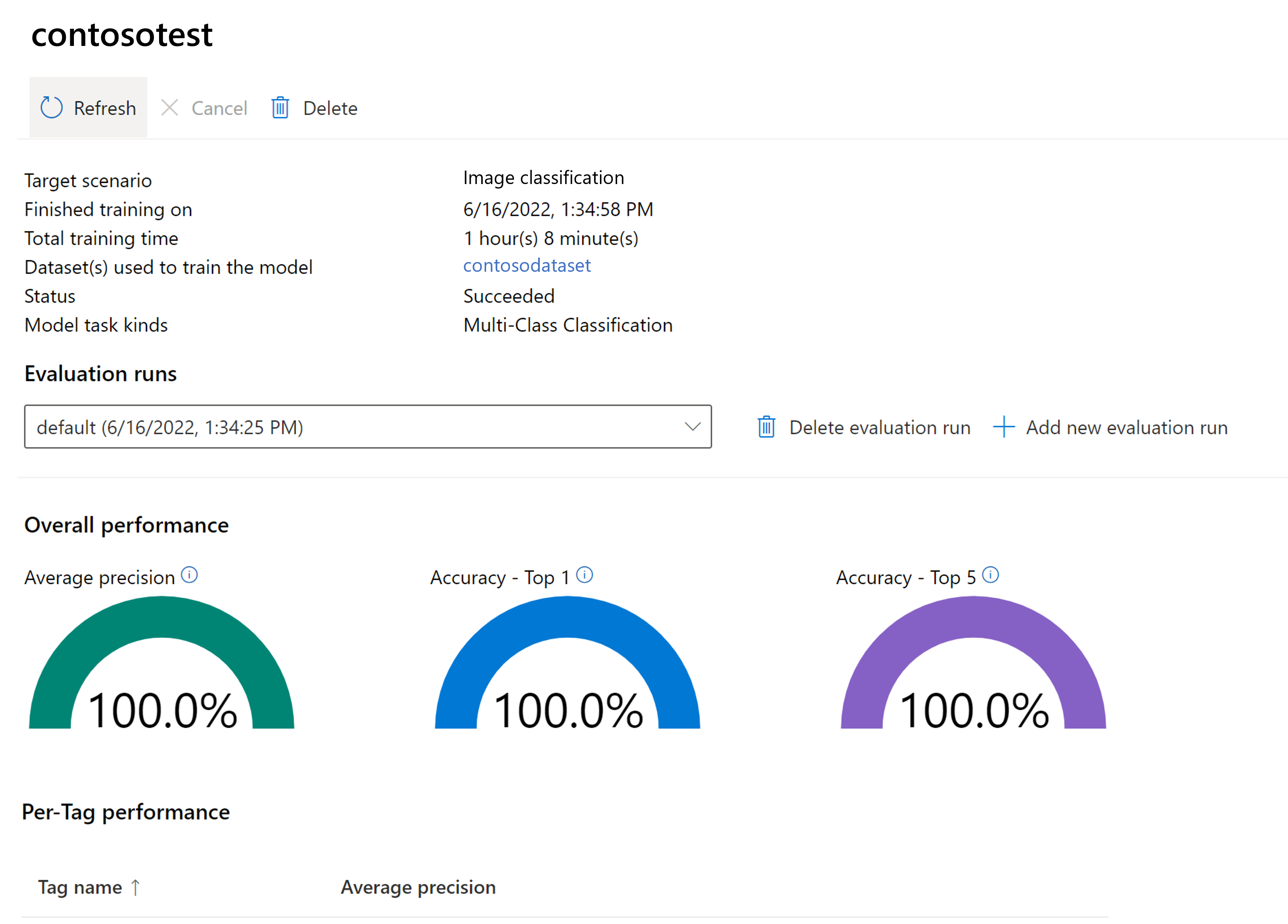
评估已训练的模型
训练完成后,可以查看模型的性能评估。 使用以下指标:
- 图像分类:平均精度、准确度前 1、准确度前 5
- 对象检测:平均精度均值 @ 30、平均精度均值 @ 50、平均精度均值 @ 75
如果在训练模型时未提供评估集,则根据训练集的一部分估算报告的性能。 强烈建议使用评估数据集(使用与上述相同的过程)来可靠地评估模型性能。
在 Vision Studio 中测试自定义模型
生成自定义模型后,可以通过选择模型评估屏幕上的“试用”按钮进行测试。
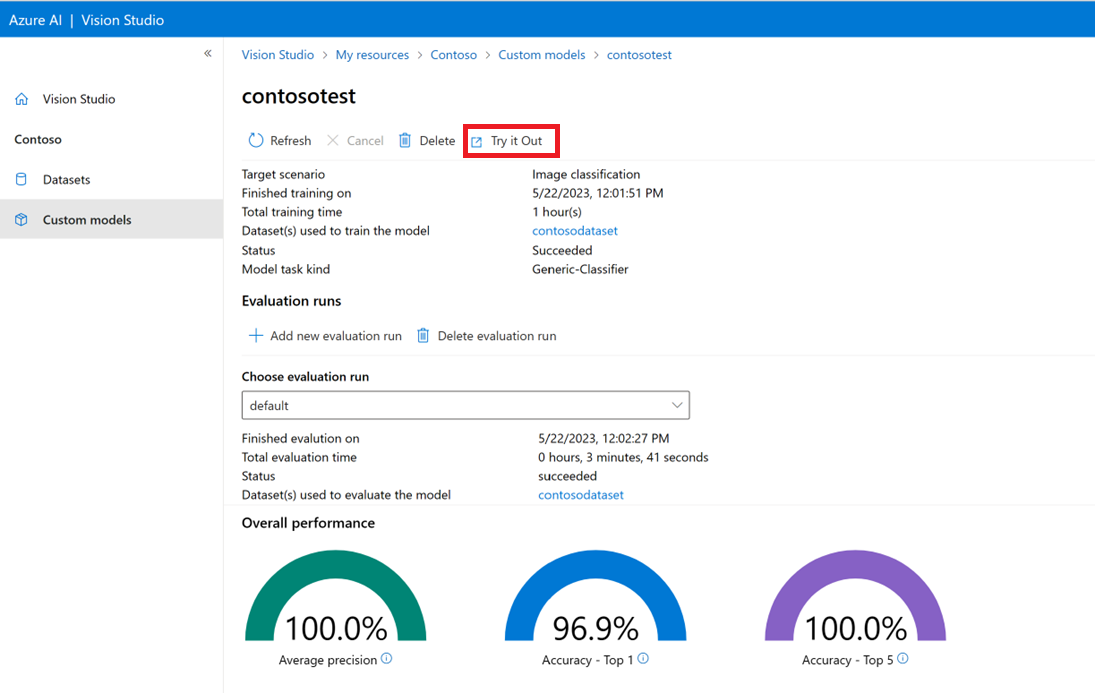
这会转到“从图像中提取通用标记”页。 从下拉菜单中选择你的自定义模型,然后上传测试图像。
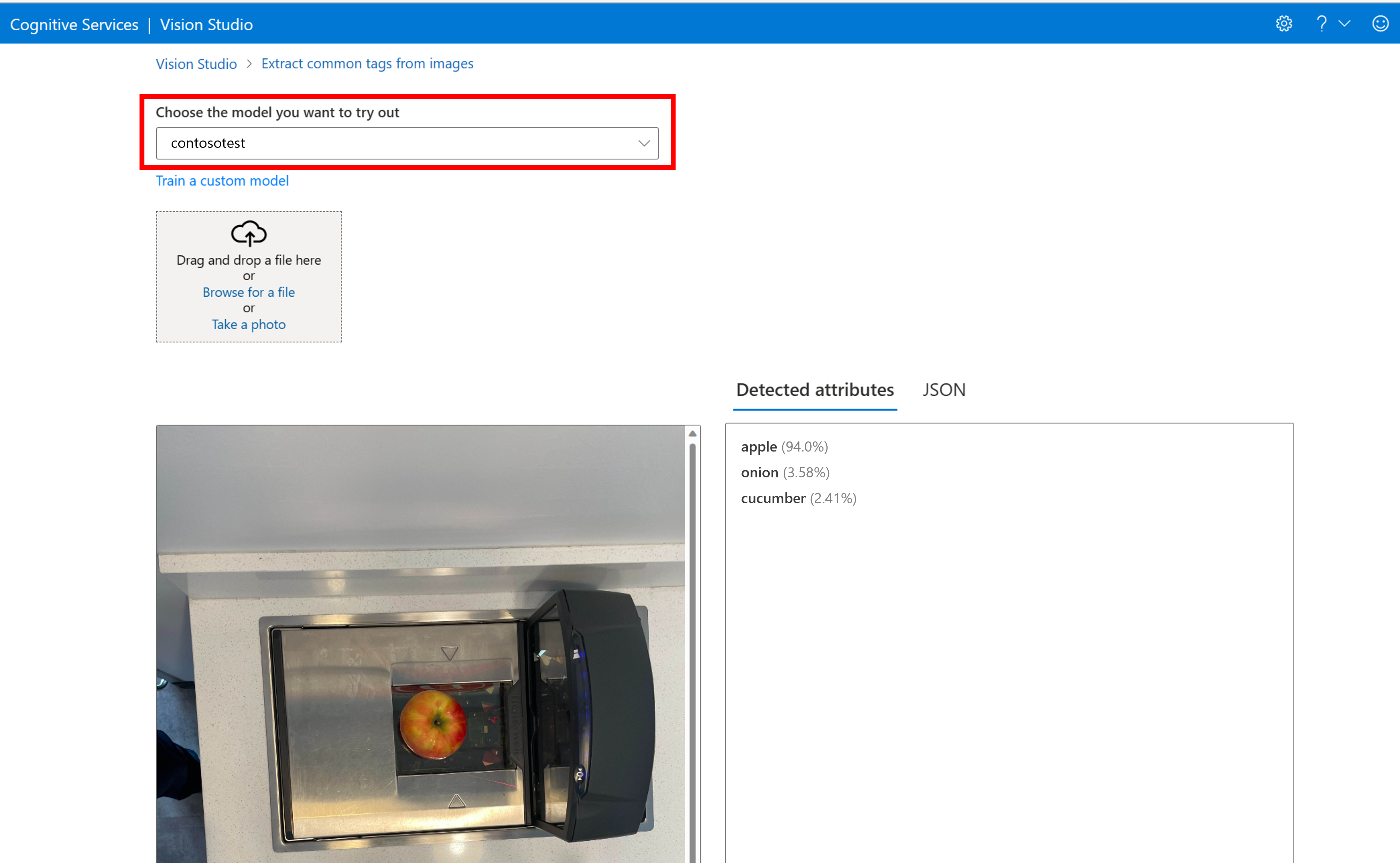
预测结果显示在右侧列中。
后续步骤
在本指南中,你已使用图像分析创建并训练了自定义图像分类模型。 接下来,了解有关“分析图像”4.0 API 的详细信息,以便可以使用 REST 或库 SDK 从应用程序调用自定义模型。
- 有关此功能的广泛概述和常见问题列表,请参阅模型自定义概念指南。
- 调用分析图像 API。