你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
适用对象:![]() NoSQL
NoSQL![]() MongoDB
MongoDB![]() 格林姆林
格林姆林
重要
Microsoft Fabric 中的镜像 Azure Cosmos DB 现在适用于 NoSql API。 此功能提供 Azure Synapse Link 的所有功能,具有更好的分析性能,能够将数据资产与 Fabric OneLake 统一,并支持开放访问 Delta Parquet 格式的数据。 如果考虑使用 Azure Synapse Link,建议尝试镜像以评估它在组织中的整体适合情况。 Microsoft Fabric 中的镜像入门。
若要开始使用 Azure Synapse Link,请参阅 “Azure Synapse Link 入门”
Azure Cosmos DB 分析存储是完全独立的列存储,可以借助它对 Azure Cosmos DB 中的操作数据进行大型分析,这对事务性工作负载没有任何影响。
Azure Cosmos DB 事务性存储架构不可知,因此你能够迭代事务性应用程序,而无需处理架构或索引管理。 与此相反,Azure Cosmos DB 分析存储已架构化,以便优化分析查询性能。 本文详细介绍分析存储。
对操作数据进行大型分析面临的挑战
Azure Cosmos DB 容器中的多模型操作数据存储在已编索的基于行的“事务性存储”内部。 行存储格式旨在快速实现事务性读写(以毫秒级的响应时间)和操作查询。 如果数据集增长得很大,就以此格式存储的数据的预配吞吐量而言,复杂的分析查询可能会非常昂贵。 预配吞吐量的高消耗反过来会影响你的实时应用程序和服务所使用的事务工作负荷的性能。
通常,若要分析大量的数据,则从 Azure Cosmos DB 的事务性存储中提取操作数据,并将其存储在单独的数据层中。 例如,采用适当的格式将数据存储在数据仓库或数据湖中。 稍后,这些数据将用于进行大规模分析,并且系统将使用计算引擎(如 Apache Spark 群集)来分析它们。 分析与操作数据的分离会导致想要使用最新数据的分析师遭遇延迟问题。
相对于仅处理新引入的操作数据而言,处理操作数据更新时,ETL 管道也会变得复杂。
面向列的分析存储
Azure Cosmos DB 分析存储解决了传统 ETL 管道所具有的复杂和延迟问题。 Azure Cosmos DB 分析存储可以自动将操作数据同步到单独的列存储。 列存储格式适用于采用优化的方式执行大型分析查询,可改进此类查询的延迟性。
借助 Azure Synapse Link,现可直接从 Azure Synapse Analytics 链接到 Azure Cosmos DB 分析存储,构建不用 ETL HTAP 的解决方案。 借助它,你可以以接近实时的速度对操作数据运行的大型分析。
分析存储的功能
在 Azure Cosmos DB 容器中启用分析存储时,将基于容器中的操作数据在内部创建新的列存储。 此列存储与内部订阅中 Azure Cosmos DB 完全管理的存储帐户中该容器的面向行的事务存储分开保存。 客户无需花时间进行存储管理。 对操作数据的插入、更新和删除将自动同步到分析存储。 无需使用更改源或 ETL 即可同步数据。
用于操作数据分析工作负荷的列存储
分析工作负荷通常涉及聚合和按顺序扫描选定字段。 数据分析存储以列为主顺序存储,允许将每个字段的值一起序列化(如果适用)。 此格式减少了扫描或计算特定字段中统计信息所需的 IOPS。 它极大地改进了扫描大型数据集所需的查询响应时间。
例如,操作表采用下面的格式时:
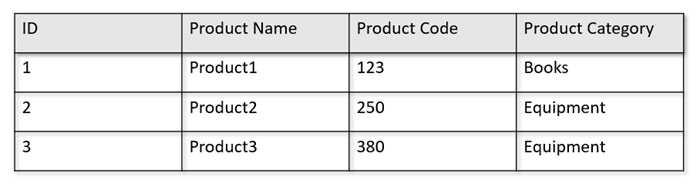
行存储会采用序列化格式将上面的数据按行保存到磁盘中。 此格式可以加快事务性读写和操作查询,如“返回产品 1 的相关信息”。 不过,随着数据集增大,如果你想要对数据运行复杂的分析查询,它的成本可能会很高。 例如,如果想要获取“‘设备’类别下的某个产品在不同业务单位和月份的销量趋势”,则需要运行复杂查询。 就预配的吞吐量而言,对此数据集执行大型扫描的成本可能会变得很高,这还可能会影响支持实时应用程序和服务的事务性工作负荷的性能。
分析存储是列存储,它更适用于此类查询,因为它会将相似的数据字段一起序列化,减少磁盘 IOPS。
下图说明了 Azure Cosmos DB 中的事务性行存储与分析列存储:
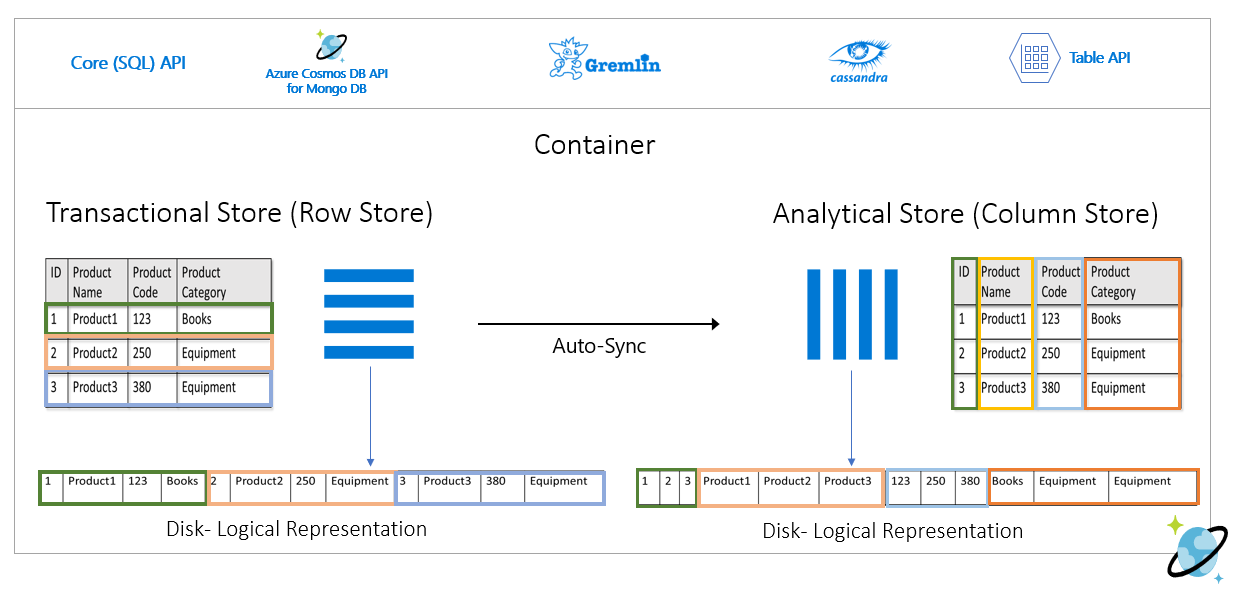
分析工作负荷性能已分离
分析查询不会影响事务工作负载的性能,因为分析存储已与事务存储分开。 分析存储无需分配单独的请求单位 (RU)。
自动同步
自动同步是指 Azure Cosmos DB 的完全托管功能,对操作数据执行的插入、更新、删除将准实时自动从事务存储同步到分析存储。 自动同步延迟通常在 2 分钟内。 如果共享吞吐量数据库拥有大量容器,则单个容器的自动同步延迟可能会更高,最长可能达 5 分钟。
每次执行自动同步过程结束时,事务数据将立即可用于 Azure Synapse Analytics 运行时:
Azure Synapse Analytics Spark 池可以通过自动更新的 Spark 表读取所有数据(包括最新更新),也可以通过始终读取数据最新状态的
spark.read命令读取。Azure Synapse Analytics SQL 无服务器池可以通过自动更新的视图读取所有数据(包括最新更新),也可以通过将
SELECT和OPENROWSET命令一起使用来进行读取,这将始终读取数据的最新状态。
注意
即使事务性生存时间 (TTL) 小于 2 分钟,事务数据也会同步到分析存储。
注意
请注意,如果删除容器,也会删除分析存储。
可伸缩性和弹性
Azure Cosmos DB 事务性存储使用水平分区,无需停机即可弹性缩放存储和吞吐量。 事务性存储中的水平分区为自动同步提供了可伸缩性和弹性,确保数据以接近实时的速度同步到分析存储。 无论事务流量吞吐量如何数据同步都会执行(无论是 1000 个操作/秒还是 1 百万个操作/秒),并且它不会影响事务存储的预配吞吐量。
自动处理架构更新
Azure Cosmos DB 事务性存储架构不可知,因此你能够迭代事务性应用程序,而无需处理架构或索引管理。 与此相反,Azure Cosmos DB 分析存储已架构化,以便优化分析查询性能。 借助自动同步功能,Azure Cosmos DB 可管理对事务存储中最新更新的架构推断。 它还管理现成分析存储中的架构表示形式,其中包括处理嵌套数据类型。
随着架构不断演化,并且将随时间推移添加新属性,分析存储会自动跨事务存储中的所有历史架构呈现联合架构。
注意
在分析存储的上下文中,我们将以下结构视为属性:
- JSON“元素”或“由
:分隔的字符串值对”。 - JSON 对象,由
{和}分隔。 - JSON 数组,由
[和]分隔。
架构约束
当启用分析存储以自动推断并正确表示架构时,以下约束适用于 Azure Cosmos DB 中的操作数据:
文档架构中的所有嵌套级别最多可以有 1000 个属性,最大嵌套深度为 127。
- 分析存储中只表示前 1000 个属性。
- 分析存储中只表示前 127 个嵌套层级。
- JSON 文档的第一个级别是它的
/根级别。 - 文档中第一级的属性将以列的形式表示。
示例方案:
- 如果文档的第一级具有 2000 个属性,则同步过程将表示其中前 1000 个属性。
- 如果文档有五个级别,每个级别有 200 个属性,则同步过程将表示所有属性。
- 如果文档有 10 个级别,每个级别有 400 个属性,则同步过程将表示前两个级别的全部属性,以及第三个级别的仅一半属性。
下面的假设文档包含 4 个属性和 3 个级别。
- 其中的级别为
root、myArray和myArray中的嵌套结构。 - 属性为
id、myArray、myArray.nested1和myArray.nested2。 - 分析存储表示形式将具有两列:
id和myArray。 使用 Spark 或 T-SQL 函数也可以将嵌套结构作为列公开。
- 其中的级别为
{
"id": "1",
"myArray": [
"string1",
"string2",
{
"nested1": "abc",
"nested2": "cde"
}
]
}
尽管从唯一性角度来看,JSON 文档(和 Azure Cosmos DB 集合/容器)区分大小写,但分析存储不区分大小写。
- 在同一文档中:以不区分大小写的方式进行比较时,相同级别的属性名称应是唯一的。 例如,以下 JSON 文档在同一级别具有“Name”和“name”。 尽管它是有效的 JSON 文档,但不满足唯一性约束,因此不会完全表示在分析存储中。 在本示例中,以不区分大小写的方式进行比较时,“Name”和“name”是相同的。 只有
"Name": "fred"表示在分析存储中,因为它是第一个出现的。 完全不会表示"name": "john"。
{"id": 1, "Name": "fred", "name": "john"}- 在不同文档中:同一级别同名但大小写不同的属性会在同一列中表示,使用第一次出现的项目的名称格式。 例如,以下 JSON 文档在同一级别具有
"Name"和"name"。 由于第一个文档格式是"Name",则分析存储中将使用该格式来表示该属性名称。 换言之,分析存储中的列名称将为"Name"。"fred"和"john"都会在"Name"列表示。
{"id": 1, "Name": "fred"} {"id": 2, "name": "john"}- 在同一文档中:以不区分大小写的方式进行比较时,相同级别的属性名称应是唯一的。 例如,以下 JSON 文档在同一级别具有“Name”和“name”。 尽管它是有效的 JSON 文档,但不满足唯一性约束,因此不会完全表示在分析存储中。 在本示例中,以不区分大小写的方式进行比较时,“Name”和“name”是相同的。 只有
集合的第一个文档定义初始分析存储架构。
- 属性数量超过初始架构的文档将在分析存储中生成新列。
- 不能删除列。
- 删除集合中的所有文档不会重置分析存储架构。
- 架构没有版本控制。 在分析存储中看到的版本是从事务存储中推断出的最后一个版本。
目前,Azure Synapse Spark 无法读取下列名称中包含某些特殊字符的属性。 Azure Synapse SQL 无服务器不受影响。
- 解码的字符:
- `
- ,
- ;
- {}
- ()
- \n
- \t
- =
- "
注意
在达到此限制时,返回的 Spark 错误消息中还会列出空格。 但我们已经添加了对空格的特殊处理,请在以下各项中查看详细信息。
- 如果你的属性名称使用上面列出的字符,则可以改用以下方法:
- 提前更改数据模型,以避免这些字符。
- 由于目前不支持架构重置,因此你可以更改应用程序以添加具有相似名称的冗余属性,避免使用这些字符。
- 通过更改源在属性名称中创建容器的具体化视图,不使用这些字符。
- 使用
dropColumnSpark 选项可忽略受影响的列,并将所有其他列加载到数据帧中。 语法为:
# Removing one column:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName")\
.load()
# Removing multiple columns:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName;StreetName,StreetNumber")\
.option("spark.cosmos.dropMultiColumnSeparator", ";")\
.load()
- 现在,Azure Synapse Spark 支持名称中包含空格的属性。 为此,需要使用
allowWhiteSpaceInFieldNamesSpark 选项,以将受影响的列加载到数据帧中,保留原始名称。 语法为:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.allowWhiteSpaceInFieldNames", "true")\
.load()
以下 BSON 数据类型不受支持,并且不会在分析存储中表示:
- Decimal128
- 正则表达式
- DB 指针
- Javascript
- 符号
- MinKey/MaxKey
使用符合 ISO 8601 UTC 标准的日期/时间字符串时,预计会出现以下行为:
- Azure Synapse 中的 Spark 池会将这些列表示为
string。 - Azure Synapse 中的 SQL 无服务器池会将这些列表示为
varchar(8000)。
- Azure Synapse 中的 Spark 池会将这些列表示为
UNIQUEIDENTIFIER (guid)类型的属性在分析存储中表示为string,应在 SQL 中转换为VARCHAR,在 Spark 中转换为 ,以便进行正确的可视化。Azure Synapse 中的 SQL 无服务器池支持最多 1000 列的结果集,并且公开嵌套列也计入该限制。 最好在事务数据体系结构和建模中考虑此信息。
如果重命名一个或多个文档中的属性,则该属性将会被视为新列。 如果在集合中的所有文档中执行相同的重命名,则所有数据都将迁移到新列,并且旧列将会用
NULL值来表示。
架构表示形式
分析存储中有两种架构表示方法,它们对数据库帐户中的所有容器都有效。 它们在简化查询体验与为多态架构采用更具包容性的列式表示形式的便利性之间进行了权衡。
- 明确定义的架构表示形式,是 API for NoSQL 和 Gremlin 帐户的默认选项。
- 全保真架构表示形式,是 API for MongoDB 帐户的默认选项。
定义明确的架构表示形式
定义明确的架构表示形式可在事务存储中创建与架构无关的数据的简单表格表示形式。 定义明确的架构表示形式具有以下注意事项:
- 第一个文档定义基本架构,属性必须始终在所有文档中具有相同的类型。 仅有的例外情况是:
- 对于 Azure Synapse 中的 SQL 无服务器池:从
NULL到任何其他数据类型。 列数据类型由第一个出现的非 null 项定义。 任何不符合第一个非 null 数据类型的文档将不会在分析存储中呈现。 - 对于 Azure Synapse 中的 Spark 池和 Azure 数据工厂变更数据捕获:从
NULL到INT。 Spark 池和 Azure Synapse 中的 Azure 数据工厂变更数据捕获不支持从 null 属性演变为 INT 以外的数据类型。 第一个非 null 值必须是整数,并且具有不同数据类型的任何文档都不会在分析存储中表示。 - 从
float到integer。 所有文档都将在分析存储中表示。 - 从
integer到float。 所有文档都将在分析存储中表示。 但是,若要使用 Azure Synapse SQL 无服务器池读取此数据,必须使用 WITH 子句将列转换为varchar。 完成这种初始转换后,可以再次将列转换为数字。 请查看以下示例,其中的 num 初始值是整数,第二个值是浮点数。
- 对于 Azure Synapse 中的 SQL 无服务器池:从
SELECT CAST (num as float) as num
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
)
WITH (num varchar(100)) AS [IntToFloat]
不符合基本架构数据类型的属性不会在分析存储中呈现。 例如,请看下面的文档:第一个定义了分析存储基本架构。 第二个文档(其中的
id为"2")没有明确定义的架构,因为属性 是字符串,而第一个文档中的"code"是数字。 在这种情况下,分析存储会在容器生存期内将"code"数据类型注册为integer。 第二个文档仍会包含在分析存储中,但其"code"属性则不会。{"id": "1", "code":123}{"id": "2", "code": "123"}
注意
上述条件不适用于 NULL 属性。 例如,{"a":123} and {"a":NULL} 仍是完善定义的。
注意
如果将文档 "code" 的 "1" 更新为事务存储中的字符串,则上述条件不会变化。 在分析存储中,"code" 将会保留为 integer,因为当前我们不支持架构重置。
- 数组类型必须包含单个重复的类型。 例如,
{"a": ["str",12]}不是完善定义的架构,因为此数组包含整数和字符串类型组合。
注意
如果 Azure Cosmos DB 分析存储遵循定义完善的架构表示形式,但某些项违反了上述规范,则这些项不会包含在分析存储中。
对于定义完善的架构中的不同类型,需要不同的行为:
- Azure Synapse 中的 Spark 池会将这些值表示为
undefined。 - Azure Synapse 中的 SQL 无服务器池会将这些值表示为
NULL。
- Azure Synapse 中的 Spark 池会将这些值表示为
对于显式
NULL值,需要不同的行为:- Azure Synapse 中的 Spark 池会将这些值读取为
0(零),并在相应列具有非 null 值时立即将这些值读取为undefined。 - Azure Synapse 中的 SQL 无服务器池会将这些值读取为
NULL。
- Azure Synapse 中的 Spark 池会将这些值读取为
对于缺少的列,预期存在不同的行为:
- Azure Synapse 中的 Spark 池会将这些列表示为
undefined。 - Azure Synapse 中的 SQL 无服务器池会将这些列表示为
NULL。
- Azure Synapse 中的 Spark 池会将这些列表示为
表示挑战解决方法
可能使用了架构不正确的旧文档来创建容器的分析存储基本架构。 根据上述所有规则,在使用 Azure Synapse Link 查询分析存储时,可能会收到某些属性的 NULL。 删除或更新有问题的文档无济于事,因为目前不支持基本架构重置。 可能的解决方法包括:
- 要将数据迁移到新容器,请确保所有文档都具有正确的架构。
- 放弃具有错误架构的属性,添加一个在所有文档中都具有正确架构的其他名称的新属性。 示例:你在 Orders 容器中有数十亿个文档,其中 status 属性为字符串。 但该容器中的第一个文档具有整数定义的 status。 因此,一个文档的 status 将正确表示,所有其他文档将为
NULL。 可以将 status2 属性添加到所有文档并开始使用它,以替代原始属性。
完全保真架构表示形式
完全保真架构表示形式旨在处理与架构无关的操作数据中的各种多态架构。 在此架构表示形式中,即使违反定义明确的架构约束(也就是既没有混合数据类型字段也没有混合数据类型数组),也不会从分析存储中删除任何项。
这是通过将操作数据的叶属性转换为 JSON key-value 对形式的分析存储来实现的,其中的数据类型为 key,属性内容为 value。 此 JSON 对象表示形式使查询没有歧义,你可以单独分析每种数据类型。
换句话说,在全保真架构表示形式中,每个文档的每个属性的每个数据类型都会在该属性的 JSON 对象中生成一个 key-value 对。 存在最多 1000 个属性的限制,每个属性都计为其中之一。
例如,在事务存储中获取以下示例文档:
{
name: "John Doe",
age: 32,
profession: "Doctor",
address: {
streetNo: 15850,
streetName: "NE 40th St.",
zip: 98052
},
salary: 1000000
}
嵌套对象 address 是文档根级别中的属性,将表示为列。 address 对象中的每个叶属性都将表示为 JSON 对象:{"object":{"streetNo":{"int32":15850},"streetName":{"string":"NE 40th St."},"zip":{"int32":98052}}}。
与定义完善的架构表示形式不同,完全保真方法允许数据类型的变化。 如果上述示例的此集合中的下一个文档使用 streetNo 作为字符串,则会在分析存储中将它表示为 "streetNo":{"string":15850}。 在定义完善的架构方法中,不会表示它。
全保真架构的数据类型对照表
下图展示了 MongoDB 数据类型及其在采用全保真架构表示形式的分析存储中的表示形式。 该图对 NoSQL API 帐户无效。
| 原始数据类型 | 后缀 | 示例 |
|---|---|---|
| 加倍 | “.float64” | 24.99 |
| 数组 | ".array" | [“a”, “b”] |
| 二进制 | ".binary" | 0 |
| 布尔 | “.bool” | 真 实 |
| Int32 | “.int32” | 123 |
| Int64 | “.int64” | 255486129307 |
| Null | ".NULL" | Null |
| 字符串 | ".string" | “ABC” |
| 时间戳 | ".timestamp" | 时间戳(0,0) |
| 对象标识符 (ObjectId) | ".objectId" | ObjectId(“5f3f7b59330ec25c132623a2”) |
| 文档 | ".object" | {"a": "a"} |
对于显式
NULL值,需要不同的行为:- Azure Synapse 中的 Spark 池会将这些值作为
0(零)读取。 - Azure Synapse 中的 SQL 无服务器池将这些值读取为
NULL。
- Azure Synapse 中的 Spark 池会将这些值作为
对于缺少的列,预期存在不同的行为:
- Azure Synapse 中的 Spark 池会将这些列表示为
undefined。 - Azure Synapse 中的 SQL 无服务器池会将这些列表示为
NULL。
- Azure Synapse 中的 Spark 池会将这些列表示为
对于
timestamp值,预期存在不同的行为:- Azure Synapse 中的 Spark 池会将这些值作为
TimestampType、DateType或Float读取。 这取决于范围和时间戳的生成方式。 - Azure Synapse 中的 SQL 无服务器池将这些值读取为
DATETIME2,范围介于0001-01-01至9999-12-31之间。 超出此范围的值不受支持,并且这些值会导致查询执行失败。 如果是这种情况,你可以:- 从查询中移除列。 要保留表示形式,可在支持的范围内创建一个镜像此列的新属性, 并在查询中使用它。
- 使用分析存储中的变更数据捕获(无 RU 成本),在支持的接收器之一中将数据转换并加载为新格式。
- Azure Synapse 中的 Spark 池会将这些值作为
在 Spark 中使用全保真架构
Spark 会将每个数据类型作为列进行管理(当加载到 DataFrame 中时)。 我们假设一个包含以下文档的集合。
{
"_id" : "1" ,
"item" : "Pizza",
"price" : 3.49,
"rating" : 3,
"timestamp" : 1604021952.6790195
},
{
"_id" : "2" ,
"item" : "Ice Cream",
"price" : 1.59,
"rating" : "4" ,
"timestamp" : "2022-11-11 10:00 AM"
}
第一个文档使用的 rating 采用数字格式,使用的 timestamp 采用 utc 格式,而第二个文档使用的 rating 和 timestamp 都采用字符串格式。 假设此集合是在没有进行任何数据转换的情况下加载到 DataFrame 中的,则 df.printSchema() 的输出为:
root
|-- _rid: string (nullable = true)
|-- _ts: long (nullable = true)
|-- id: string (nullable = true)
|-- _etag: string (nullable = true)
|-- _id: struct (nullable = true)
| |-- objectId: string (nullable = true)
|-- item: struct (nullable = true)
| |-- string: string (nullable = true)
|-- price: struct (nullable = true)
| |-- float64: double (nullable = true)
|-- rating: struct (nullable = true)
| |-- int32: integer (nullable = true)
| |-- string: string (nullable = true)
|-- timestamp: struct (nullable = true)
| |-- float64: double (nullable = true)
| |-- string: string (nullable = true)
|-- _partitionKey: struct (nullable = true)
| |-- string: string (nullable = true)
在明确定义的架构表示形式中,第二个文档的 rating 和 timestamp 都不会进行表示。 在全保真架构中,可以使用以下示例单独访问每个数据类型的每个值。
在下面的示例中,可以使用 PySpark 来运行聚合:
df.groupBy(df.item.string).sum().show()
在下面的示例中,可以使用 PySQL 来运行另一个聚合:
df.createOrReplaceTempView("Pizza")
sql_results = spark.sql("SELECT sum(price.float64),count(*) FROM Pizza where timestamp.string is not null and item.string = 'Pizza'")
sql_results.show()
在 SQL 中使用全保真架构
可以结合上述 Spark 示例的相同文档使用以下语法示例:
SELECT rating,timestamp_string,timestamp_utc
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) WITH (
rating integer '$.rating.int32',
timestamp varchar(50) '$.timestamp.string',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp is not null or timestamp_utc is not null
可以使用 cast、convert 或任何其他 T-SQL 函数来操作数据来实现转换。 还可以使用视图来隐藏复杂的数据类型结构。
create view MyView as
SELECT MyRating=rating,MyTimestamp = convert(varchar(50),timestamp_utc)
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) (
rating integer '$.rating.int32',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp_utc is not null
union all
SELECT MyRating=convert(integer,rating_string),MyTimestamp = timestamp_string
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) WITH (
rating_string varchar(50) '$.rating.string',
timestamp_string varchar(50) '$.timestamp.string'
) as HTAP
WHERE timestamp_string is not null
使用 MongoDB _id 字段
MongoDB _id 字段是 MongoDB 中每个集合的基础,最初具有十六进制表示形式。 如上表所示,全保真架构将保留其特征,这为它在 Azure Synapse Analytics 中的可视化处理带来了挑战。 若要正确进行可视化,必须按如下所示转换 _id 数据类型:
在 Spark 中使用 MongoDB _id 字段
以下示例适用于 Spark 2.x 和 3.x 版本:
val df = spark.read.format("cosmos.olap").option("spark.synapse.linkedService", "xxxx").option("spark.cosmos.container", "xxxx").load()
val convertObjectId = udf((bytes: Array[Byte]) => {
val builder = new StringBuilder
for (b <- bytes) {
builder.append(String.format("%02x", Byte.box(b)))
}
builder.toString
}
)
val dfConverted = df.withColumn("objectId", col("_id.objectId")).withColumn("convertedObjectId", convertObjectId(col("_id.objectId"))).select("id", "objectId", "convertedObjectId")
display(dfConverted)
在 SQL 中使用 MongoDB _id 字段
SELECT TOP 100 id=CAST(_id as VARBINARY(1000))
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
HTAP) WITH (_id VARCHAR(1000)) as HTAP
使用 MongoDB id 字段
使用分析存储中“_id”属性的 Base64 表示形式自动替代 MongoDB 容器中的 id 属性。 “id”字段旨在供 MongoDB 应用程序内部使用。 目前,唯一的解决方法是将“id”属性重命名为“id”以外的其他名称。
API for NoSQL 或 Gremlin 帐户的全保真架构
首次在 Azure Cosmos DB 帐户上启用 Synapse Link 时,通过设置架构类型,可以使用 API for NoSQL 帐户的全保真架构,而不是默认选项。 下面是有关更改默认架构表示形式类型的注意事项:
- 目前,如果使用 Azure 门户在 NoSQL API 帐户中启用 Synapse Link,则会将其作为定义完善的架构启用。
- 目前,如果要对 NoSQL 或 Gremlin API 帐户使用完全保真架构,则必须在同一 CLI 或 PowerShell 命令(将在帐户级别启用 Synapse Link)中在帐户级别对其进行设置。
- 目前,Azure Cosmos DB for MongoDB 无法支持以这种方式更改架构表示形式。 所有 MongoDB 帐户都将具有全保真架构表示形式类型。
- 上述完全保真架构数据类型图对使用 JSON 数据类型的 NoSQL API 帐户无效。 例如,
float和integer值在分析存储中表示为num。 - 无法将架构表示形式类型从定义完善的架构重置为全保真架构,反之亦然。
- 目前,分析存储中的容器架构是在创建容器时定义的,即使数据库帐户中尚未启用 Synapse Link 也是如此。
- 在帐户级别为 Synapse Link 启用全保真架构之前创建的容器或图将具有定义完善的架构。
- 在帐户级别为 Synapse Link 启用全保真架构之后创建的容器或图将具有全保真架构。
必须在帐户上启用 Synapse Link 时,使用 Azure CLI 或 PowerShell 决定架构表示形式类型。
使用 Azure CLI:
az cosmosdb create --name MyCosmosDBDatabaseAccount --resource-group MyResourceGroup --subscription MySubscription --analytical-storage-schema-type "FullFidelity" --enable-analytical-storage true
注意
在以上命令中,请将针对现有帐户运行的 create 替换为 update。
使用 PowerShell:
New-AzCosmosDBAccount -ResourceGroupName MyResourceGroup -Name MyCosmosDBDatabaseAccount -EnableAnalyticalStorage true -AnalyticalStorageSchemaType "FullFidelity"
注意
在以上命令中,请将针对现有帐户运行的 New-AzCosmosDBAccount 替换为 Update-AzCosmosDBAccount。
分析生存时间 (TTL)
分析 TTL (ATTL) 表示应将容器的分析存储中的数据保留多久。
使用除 NULL 和 0 以外的值设置 ATTL 时,将启用分析存储。 启用后,无论事务 TTL (TTTL) 配置如何,都会从事务存储中将对操作数据执行的插入、更新、删除自动同步到分析存储。 此事务数据在分析存储中的保留期可以在容器级别通过 AnalyticalStoreTimeToLiveInSeconds 属性来控制。
可能的 ATTL 配置包括:
如果将值设置为
0:将禁用分析存储,不会将任何数据从事务存储复制到分析存储。 请打开支持案例以禁用容器中的分析存储。如果省略该字段,则不会发生任何操作,并且保留以前的值。
如果值设置为
-1:无论事务存储中数据的保留期是多久,分析存储都将保留所有历史数据。 此设置表示分析存储会无限期保留操作数据如果值设置为任意正整数
n:距在事务存储中上次修改时间n秒后,项将从分析存储中过期。 如果想要在有限的一段时间内将操作数据保留在分析存储中,而不考虑该数据在事务性存储中的保留期,可利用此设置。
考虑的要点:
- 使用 ATTL 值启用分析存储后,可以在以后将其更新为其他有效值。
- 尽管可在容器或项级别设置 TTTL,但目前只能在容器级别设置 ATTL。
- 在容器级别设置 ATTL >= TTTL,可将操作数据存档在分析存储中更长时间。
- 如果设置 ATTL = TTTL,分析存储可镜像事务存储。
- 如果 ATTL 大于 TTTL,则在某些时间点,某些数据只存在于分析存储中。 此数据为只读。
- 目前,我们不会从分析存储中删除任何数据。 如果将 ATTL 设置为任何正整数,则数据不会包含在查询中,并且不会为其计费。 但是,如果将 ATTL 更改回
-1,所有数据将再次显示,你将开始承担所有数据量的费用。
如何在容器上启用分析存储:
在 Azure 门户中,当打开 ATTL 选项时,它设置为默认值 -1。 可以通过导航到数据资源管理器下的容器设置,将此值更改为“n”秒。
在 Azure 管理 SDK、Azure Cosmos DB SDK、PowerShell 或 Azure CLI 中,可以通过将 ATTL 选项设置为 -1 或“n”秒来启用该选项。
若要了解详细信息,请参阅如何对容器配置分析 TTL。
对历史数据进行经济高效的分析
数据分层指在存储基础结构之间分隔数据,以适用于不同的方案, 从而提高端到端数据堆栈的整体性能和经济高效性。 Azure Cosmos DB 借助分析存储,现在支持使用不同的数据布局将事务性存储中的数据自动分层到分析存储。 相对于事务性存储,分析存储在存储成本方面实现了优化,你可以将操作数据保留更长时间,来进行历史分析。
启用分析存储后,可以根据事务工作负载的数据保留需求来配置 transactional TTL 属性,以便超过特定时间后即自动从事务存储删除记录。 同样,可以通过 analytical TTL 管理分析存储(独立于事务存储)中保留的数据的生命周期。 通过启用分析存储并配置事务和分析 TTL 属性,可以进行无缝分层,并定义两个存储的数据保留期。
注意
当 analytical TTL 设置为大于 transactional TTL 值的值时,容器将具有仅存在于分析存储中的数据。 此数据是只读的,目前我们不支持分析存储中的文档级别 TTL。 如果在将来的某个时间点需要更新或删除容器数据,请不要使用大于 analytical TTL 的 transactional TTL。 对于将来不需要更新或删除的数据,建议使用此功能。
注意
如果你的方案不需要进行物理删除,则可以采用逻辑删除/更新方法。 在事务存储中插入仅存在于分析存储中的、但需要逻辑删除/更新的同一文档的另一个版本。 可能会有一个标志指示该操作是删除或更新已过期的文档。 同一文档的两个版本将在分析存储中共存,但应用程序应该只考虑最后一个版本。
复原能力
分析存储依赖于 Azure 存储,它针对物理故障提供以下保护:
- 默认情况下,Azure Cosmos DB 数据库帐户在本地冗余存储 (LRS) 帐户中分配分析存储。 LRS 可在一年中提供至少 99.999999999%(11 个 9)的对象持久性。
- 如果数据库帐户的任何地理区域配置为区域冗余,则会在区域冗余存储 (ZRS) 帐户中分配该区域。 需要在其 Azure Cosmos DB 数据库帐户的某个地区上启用可用性区域,才能将该地区的分析数据存储在区域冗余存储中。 ZRS 在一年中提供至少 99.9999999999%(12 个 9)的存储资源持久性。
有关 Azure 存储持续性的详细信息,请参阅此链接。
备份
尽管分析存储针对物理故障提供内置保护,但可能需要采用备份来防范事务存储中发生意外删除或更新。 在这种情况下,可以还原容器并使用已还原的容器来回填原始容器中的数据,或者在必要时完全重建分析存储。
注意
目前分析存储没有备份,因此无法还原。 你的备份策略不能依赖于此信息进行规划。
因此,Synapse Link 和分析存储的兼容性级别与 Azure Cosmos DB 备份模式不同:
- 定期备份模式与 Synapse Link 完全兼容,这两项功能可以在同一个数据库帐户中使用。
- 使用连续备份模式的数据库帐户的 Synapse Link 是正式发布版。
- 已启用 Synapse Link 的帐户的连续备份模式为公共预览版。 目前,如果在 Cosmos DB 帐户中的任何集合上禁用 Synapse Link,则无法迁移到连续备份。
备份策略
有两种可能的备份策略,若要了解如何加以使用,必须了解有关 Azure Cosmos DB 备份的以下详细信息:
- 在两种备份模式下,可以在没有分析存储的情况下还原原始容器。
- Azure Cosmos DB 不支持通过还原覆盖容器。
现在让我们从分析存储的角度来了解如何使用备份和还原。
当 TTTL >= ATTL 时还原容器
当 transactional TTL 等于或大于 analytical TTL 时,分析存储中的所有数据仍存在于事务存储中。 在还原时,有两种可能的情况:
- 使用已还原的容器来替代原始容器。 若要重建分析存储,只需在帐户级别和容器级别启用 Synapse Link 即可。
- 将已还原的容器用作数据源,以回填或更新原容器中的数据。 对于这种情况,分析存储会自动反映数据操作。
当 TTTL < ATTL 时还原容器
当 transactional TTL 小于 analytical TTL 时,某些数据只存在于分析存储中,而不在已还原的容器中。 同样有两种可能的情况:
- 使用已还原的容器来替代原始容器。 在这种情况下,当你在容器级别启用 Synapse Link 时,只有事务存储中的数据才会包含在新的分析存储中。 但请注意,只要原始容器存在,原始容器的分析存储就仍可供查询。 你可能需要更改应用程序以查询两者。
- 将已还原的容器用作数据源,以回填或更新原容器中的数据:
- 分析存储将自动反映事务存储中数据的数据操作。
- 如果重新插入先前因
transactional TTL设置而从事务存储中删除的数据,此数据将复制到分析存储中。
示例:
- 容器
OnlineOrders的 TTTL 设置为一个月,ATTL 设置为一年。 - 将此容器还原到
OnlineOrdersNew并启用分析存储以重建分析存储时,事务存储和分析存储中都只有一个月的数据。 - 原始容器
OnlineOrders未被删除,其分析存储仍然可用。 - 新数据只会引入到
OnlineOrdersNew中。 - 分析查询将从分析存储执行 UNION ALL,而原始数据仍然相关。
若要删除原始容器但又不想丢失其分析存储数据,可将原始容器的分析存储持久保存在另一个 Azure 数据服务中。 Synapse Analytics 能够在不同位置存储的数据之间执行联接。 示例:Synapse Analytics 查询将分析存储数据与位于 Azure Blob 存储、Azure Data Lake Store 等位置的外部表相联接。
必须注意的是,分析存储中数据的架构不同于事务存储中已存在的架构。 虽然可以生成分析存储数据的快照并将其导出到任何 Azure 数据服务,而不会产生任何 RU 成本,但我们不能保证使用此快照可为事务存储回馈数据。 此过程不受支持。
全球分布
若你拥有全局分发的 Azure Cosmos DB 帐户,为容器启用分析存储后,它将适用于该帐户的所有区域。 对操作数据的任何更改均将全局复制到所有区域。 你可以高效地对 Azure Cosmos DB 中距离最近的区域的数据副本运行分析查询。
分区
分析存储分区完全独立于事务存储中的分区。 默认情况下,分析存储中的数据未分区。 如果分析查询频繁使用筛选器,则可以选择根据这些字段进行分区,以获得更好的查询性能。 要了解详细信息,请参阅自定义分区简介和如何配置自定义分区。
安全性
使用分析存储进行身份验证 - 支持的身份验证方法因是否启用了网络功能而异。
基于密钥的身份验证:所有方案中的所有帐户都支持此方案,包括未启用专用终结点或 VNet 的帐户。
服务主体或托管标识:仅支持不使用专用终结点或不启用 VNet 访问的帐户使用 Entra ID 或托管标识身份验证。 若要使用此类型的身份验证,用户必须应用 数据平面 RBAC ,并按照以下数据操作创建新的只读角色。
- 使用 PowerShell 添加自定义 MyAnalyticsReadOnlyRole ,并将“readMetadata”和“readAnalytics”RBAC动作映射到角色。
$resourceGroupName = "<myResourceGroup>" $accountName = "<myCosmosAccount>" New-AzCosmosDBSqlRoleDefinition -AccountName $accountName ` -ResourceGroupName $resourceGroupName ` -Type CustomRole -RoleName 'MyAnalyticsReadOnlyRole' ` -DataAction @( ` 'Microsoft.DocumentDB/databaseAccounts/readMetadata', 'Microsoft.DocumentDB/databaseAccounts/readAnalytics' ) ` -AssignableScope "/"- 列出帐户的角色定义以获取新的角色定义 ID。
$roleDefinitionId = Get-AzCosmosDBSqlRoleDefinition -AccountName $accountName ` -ResourceGroupName $resourceGroupName- 通过将新角色分配给 Synapse MSI 主体来创建角色分配。
$synapsePrincipalId = "<Synapse MSI Principal>" New-AzCosmosDBSqlRoleAssignment -AccountName $accountName ` -ResourceGroupName $resourceGroupName ` -RoleDefinitionId $readOnlyRoleDefinitionId ` -Scope "/" ` -PrincipalId $synapsePrincipalId
使用专用终结点的网络隔离 - 可以单独控制对事务性和分析存储中的数据的网络访问。 在 Azure Synapse 工作区的托管虚拟网络内,为每个存储使用单独的托管专用终结点进行网络隔离。 如要了解详细信息,请参阅如何为分析存储配置专用终结点一文。 注意:启用此项时必须使用基于密钥的身份验证。 请参阅上一部分。
静态数据加密 - 默认启用分析存储加密。
使用客户管理的密钥进行数据加密 - 可以采用自动且透明的方式使用相同的客户管理密钥无缝地跨事务存储和分析存储加密数据。 Azure Synapse Link 仅支持使用 Azure Cosmos DB 帐户的托管标识配置客户管理的密钥。 在帐户上启用 Azure Synapse Link 之前,必须在 Azure Key Vault 访问策略中配置帐户的托管标识。 若要了解详细信息,请参阅如何使用 Azure Cosmos DB 帐户的托管标识配置客户管理的密钥一文。
注意
如果将数据库帐户从第一方标识更改为系统分配的标识或用户分配的标识,并在数据库帐户中启用 Azure Synapse Link,则无法返回到第一方标识,因为无法从数据库帐户中禁用 Synapse Link。
支持多个 Azure Synapse Analytics 运行时
分析存储已经过优化,无需依赖计算运行时即可为分析工作负荷提供可伸缩性、弹性和性能。 存储技术是自行管理,无需手动操作即可优化分析工作负荷。
可以从 Azure Synapse Analytics 支持的不同分析运行时同时查询 Azure Cosmos DB 分析存储中的数据。 Azure Synapse Analytics 支持 Apache Spark 和无服务器 SQL 池使用 Azure Cosmos DB 分析存储。
注意
只能使用 Azure Synapse Analytics 运行时从分析存储中读取内容。 反过来也是如此,Azure Synapse Analytics 运行时只能从分析存储中读取内容。 只有自动同步过程才能更改分析存储中的数据。 可以使用 Azure Synapse Analytics Spark 池通过内置的 Azure Cosmos DB OLTP SDK 将数据写回到 Azure Cosmos DB 事务存储。
定价
分析存储遵循基于消耗量的定价模型,计费项包括:
存储:分析存储每个月保留的数据量,包括分析 TTL 定义的历史数据。
分析写入操作:从事务性存储将操作数据更新以完全托管的方式同步到分析存储(自动同步)
分析读取操作:从 Azure Synapse Analytics Spark 池和无服务器 SQL 池运行时对分析存储执行的读取操作。
分析存储定价与事务性存储定价模型不同。 分析存储中没有预配 RU 这一概念。 有关分析存储定价模型的完整详细信息,请参阅 Azure Cosmos DB 定价页。
分析存储中的数据只能通过 Azure Synapse Link 进行访问,而这需要在 Azure Synapse Analytics 运行时(Azure Synapse Apache Spark 池和 Azure Synapse 无服务器 SQL 池)中来完成。 有关访问分析存储中的数据的定价模型的完整详细信息,请参阅 Azure Synapse Analytics 定价页。
从分析存储的角度,若要为在 Azure Cosmos DB 容器中启用分析存储进行高级别成本估算,可以使用 Azure Cosmos DB 容量规划器,来获得分析存储和写入操作成本的估算值。
Azure Cosmos DB 成本计算器不包括分析存储读取操作估计,因为它们是分析工作负载的函数。 但作为一种大概的估算,在分析存储中扫描 1 TB 的数据通常会引发 130,000 个分析读取操作,产生的成本为 0.065 美元。 例如,如果使用 Azure Synapse 无服务器 SQL 池执行此 1 TB 的扫描,则根据 Azure Synapse Analytics 定价页中的信息,成本为 5.00 美元。 此 1 TB 的扫描的最终总成本为 5.065 美元。
尽管上述估计可用于扫描分析存储中 1 TB 的数据,但应用筛选器可减少扫描的数据量,并且可在给定消耗定价模型的情况下分析读取操作的确切数目。 围绕分析工作负载的概念证明可提供对分析读取操作的更精细估计。 此估算值不包括 Azure Synapse Analytics 的成本。
后续步骤
若要了解更多信息,请参阅下列文档: