你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
本文重点介绍如何 将数据 从 Amazon DynamoDB 迁移到 Azure Cosmos DB for NoSQL。 在开始之前,请务必了解数据迁移与应用程序迁移之间的差异:
- 数据迁移可能具有许多步骤,包括从源系统(在本例中为 DynamoDB)导出数据、执行其他处理(例如转换),最后将数据写入 Azure Cosmos DB。
- 应用程序迁移包括重构应用程序以使用 Azure Cosmos DB 而不是 DynamoDB。 此过程可能包括调整和重写查询、重新设计分区策略、索引编制、确保一致性等。
根据要求,可以并行迁移数据以及迁移应用程序。 但数据迁移通常是应用程序迁移的先决条件。 若要了解有关应用程序迁移的详细信息,请参阅 将应用程序从 Amazon DynamoDB 迁移到 Azure Cosmos DB。
迁移技术
可以使用各种迁移技术。 两种常用技术包括:
联机迁移:如果应用程序无法容忍停机时间,并且需要实时数据迁移,请选择此技术。
脱机迁移:如果在维护时段内可以暂时停止应用程序,则可以在脱机模式下执行数据迁移。 首先,将数据从 DynamoDB 导出到中间位置。 然后,将数据导入 Azure Cosmos DB。
此方法有多种选项。 本文介绍一种此类选项。
根据特定要求选择技术。 也可以将它们组合在一起。 例如,可以使用脱机进程批量迁移数据,然后切换到联机模式。 如果需要(暂时)与 Azure Cosmos DB 并行使用 DynamoDB,并且希望数据实时同步,则此选项可能适用。
建议在实际迁移之前使用概念证明阶段全面评估和测试选项。 此阶段有助于评估复杂性、评估可行性并微调迁移计划。
脱机迁移方法
本文遵循的方法只是将数据从 DynamoDB 迁移到 Azure Cosmos DB 的多种方法之一。 它有自己的一套利弊。 下面是脱机迁移方法的非详尽列表:
| 方法 | Pros | Cons |
|---|---|---|
| 从 DynamoDB 导出到 S3,使用 Azure 数据工厂加载到 Azure Data Lake Storage Gen2,并使用 Azure Databricks 上的 Spark 写入 Azure Cosmos DB。 | 将存储和处理相分离。 Spark 提供可伸缩性和灵活性(其他数据转换、处理)。 | 多阶段进程会增加复杂性和整体延迟。 需要具备 Spark 知识。 |
| 从 DynamoDB 导出到 S3,并使用 Azure 数据工厂从 S3 读取和写入 Azure Cosmos DB。 | 低/无代码方法。 无需 Spark 技能。 适用于简单的数据转换。 | 复杂的转换可能难以实现。 |
| 使用 Azure Databricks 上的 Spark 从 DynamoDB 读取和写入 Azure Cosmos DB。 | 适合小型数据集,因为直接处理可避免额外的存储成本。 支持复杂转换 (Spark)。 | 由于 RCU 消耗量,DynamoDB 端的成本更高。 (未使用 S3 导出。需要了解 Spark。 |
在线迁移方法
联机迁移通常使用变更数据捕获(CDC)机制从 DynamoDB 流式传输数据更改。 这些更改往往是实时的或近乎实时的。 需要生成另一个组件来处理流数据并将其写入 Azure Cosmos DB。 下面是联机迁移方法的非详尽列表:
| 方法 | Pros | Cons |
|---|---|---|
| 将 DynamoDB CDC 与 DynamoDB 流配合使用,使用 AWS Lambda 进行处理,并写入 Azure Cosmos DB。 | DynamoDB 流提供排序保证。 事件驱动的处理。 适用于简单的数据转换。 | DynamoDB 流数据保留期为 24 小时。 需要编写自定义逻辑(Lambda 函数)。 |
| 将 DynamoDB CDC 与 Kinesis 数据流配合使用,使用 Kinesis 或 Flink 进行处理,并写入 Azure Cosmos DB。 | 支持复杂的数据转换(使用 Flink 进行开窗/聚合),并更好地控制处理。 保留期很灵活(从 24 小时延长到 365 天)。 | 不提供排序保证。 需要编写自定义逻辑(Flink 作业、Kinesis 数据流使用者)。 需要流处理专业知识。 |
离线迁移演练
本部分介绍了如何使用 Azure 数据工厂、Azure Data Lake Storage 和 Azure Databricks 上的 Spark 进行数据迁移。 下图演示了主要步骤。

- 使用原生 DynamoDB 导出功能将数据从 DynamoDB 表导出到 S3,采用 DynamoDB JSON 格式。
- 使用 Azure 数据工厂管道将 S3 中的 DynamoDB 表数据写入 Data Lake Storage Gen2。
- 使用 Azure Databricks 上的 Spark 处理 Azure 存储中的数据,并将数据写入 Azure Cosmos DB。
先决条件
在继续之前,请创建以下项目:
- Azure Cosmos DB 帐户
- 标准常规用途 v2 类型的存储帐户
- Azure 数据工厂
- 要从以下内容中迁移数据的 AWS 帐户和 Amazon DynamoDB 表
小窍门
如果要在新的 DynamoDB 表中尝试本演练,可以使用 此数据加载程序工具 使用示例数据填充表。
步骤 1:将数据从 DynamoDB 导出到 Amazon S3
DynamoDB S3 导出是一种内置解决方案,用于将 DynamoDB 数据导出到 Amazon S3 存储桶。 有关如何执行此过程(包括设置必要的 S3 权限)的步骤,请遵循 DynamoDB 文档。 DynamoDB 支持将 DynamoDB JSON 和 Amazon Ion 作为导出数据的文件格式。
本演练使用 DynamoDB JSON 格式导出的数据。
步骤 2:使用 Azure Data Factory 将 S3 数据传输到 Azure 存储
使用以下命令将 GitHub 存储库克隆到本地计算机。 存储库包含 Azure 数据工厂管道模板和本文稍后将使用的 Spark 笔记本。
git clone https://github.com/AzureCosmosDB/migration-dynamodb-to-cosmosdb-nosql
使用 Azure 门户创建链接服务:
在 Azure 门户中,转到 Azure 数据工厂。 选择 Launch Studio 以打开 Azure 数据工厂工作室。
为 Amazon S3 创建 Azure 数据工厂链接服务。 输入你之前将表数据导出到的 S3 存储桶的详细信息。
创建 Azure Data Lake Storage Gen2 链接服务。 输入前面创建的存储帐户的详细信息。

使用 Azure 门户 创建 Azure 数据工厂管道。 数据工厂管道是共同执行某项任务的活动的逻辑分组。
在数据工厂工作室中,转到“ 创作 ”选项卡。
选择加号。 在显示的菜单上,选择 “管道”,然后选择“ 从管道模板导入”。
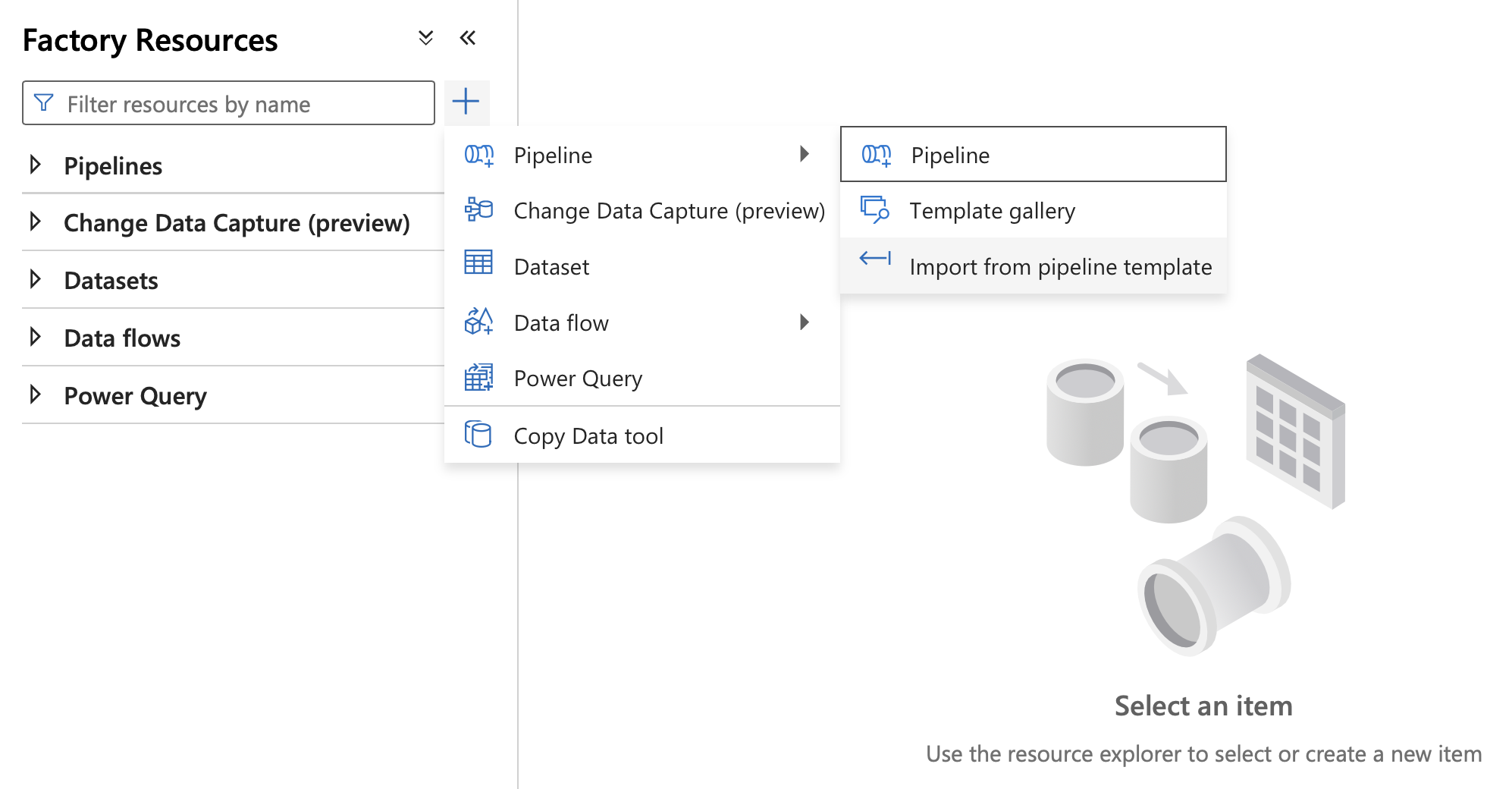
选择从 GitHub 存储库克隆的模板文件(S3ToADLSGen2.zip)。
在配置中,选择为 Amazon S3 和 Azure Data Lake Storage Gen2 创建的链接服务。 然后选择“ 使用此模板 创建管道”。

选择管道,转到 “源”,然后编辑源(Amazon S3)数据集。
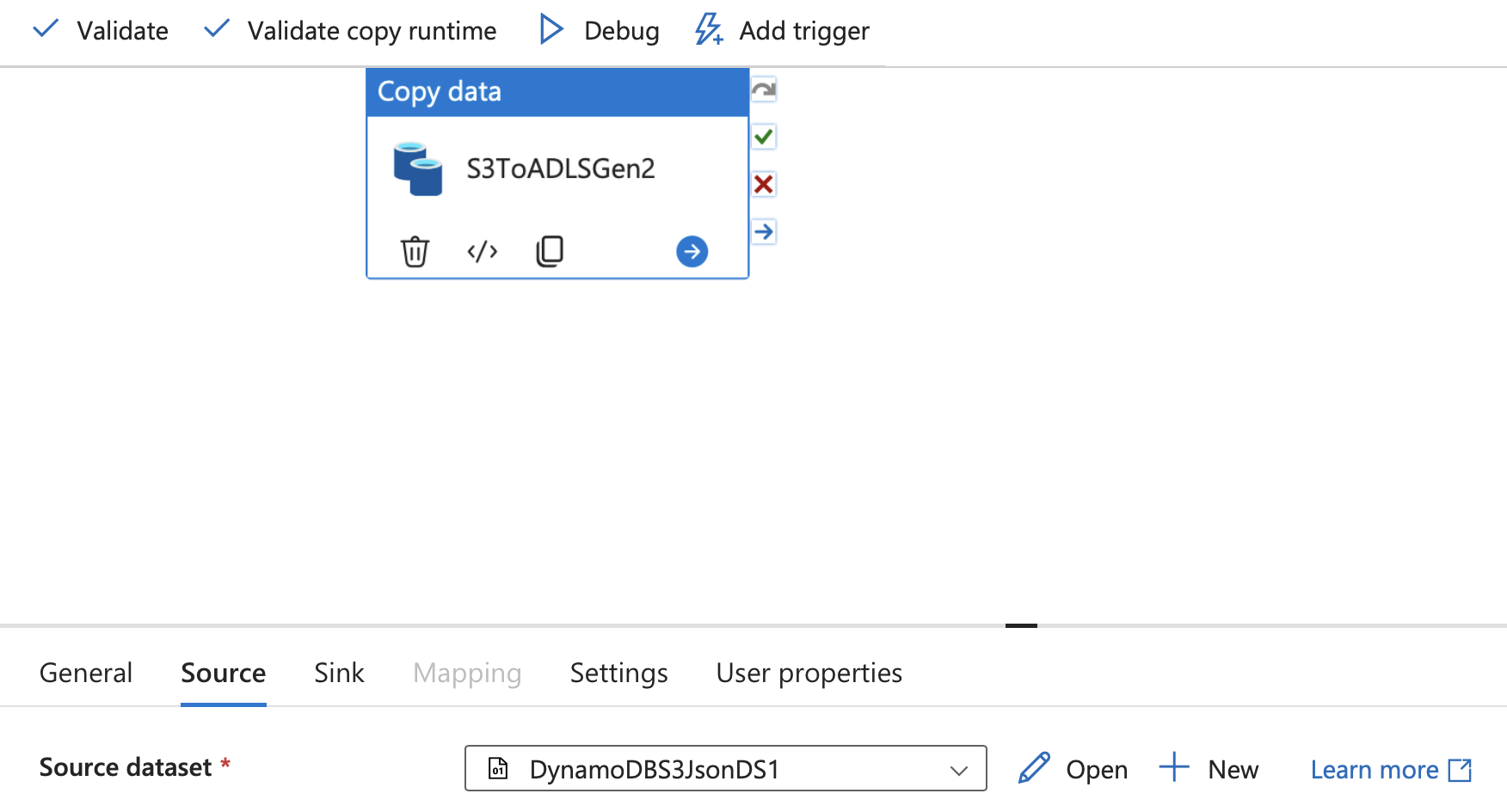
在“文件路径”中,输入 Amazon S3 存储桶中导出的文件的路径。
重要
你还可以编辑接收器数据集以更新存储来自 S3 的数据的存储容器的名称。 默认情况下,容器命名
s3datacopy。完成更改后,选择“ 全部发布 ”以发布管道。




若要手动触发管道,请执行以下操作:
选择管道。 在管道编辑器顶部,选择 “添加触发器”。
选择立即触发,然后选择确定。
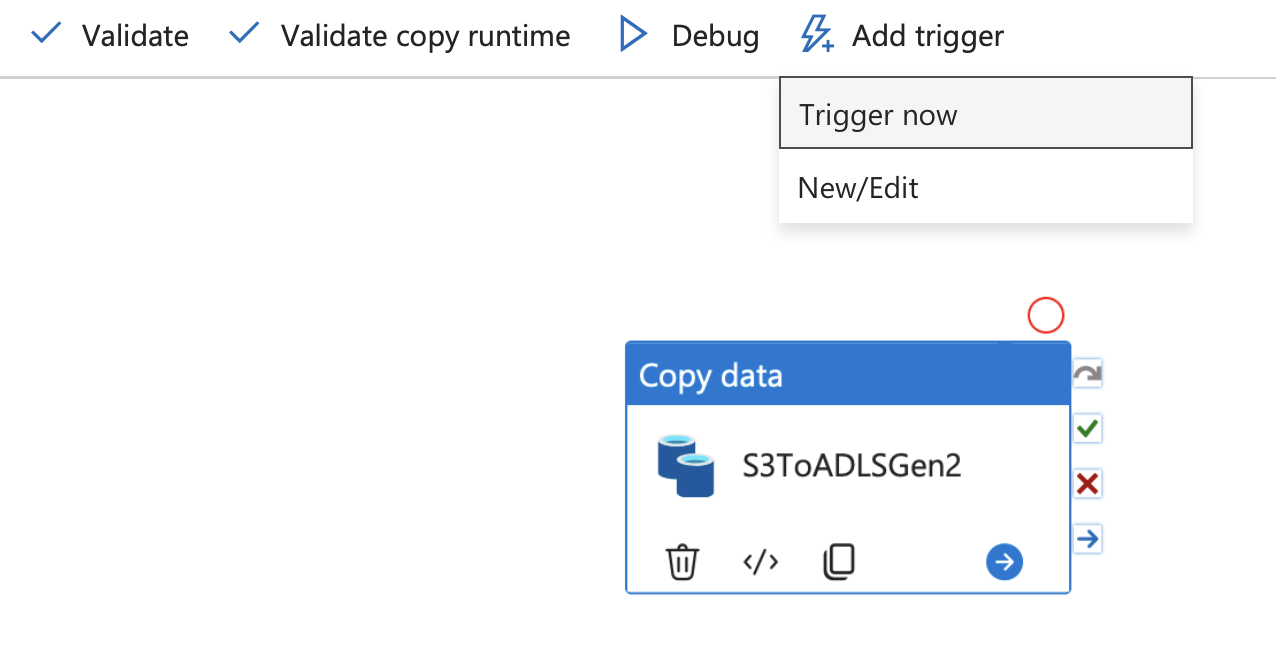

当管道继续运行时,您可以 监视它。 成功完成后,请检查前面创建的 Azure 存储帐户中的容器列表。

验证是否已创建新容器以及 S3 存储桶的内容。

步骤 3:在 Azure Databricks 上使用 Spark 将 Data Lake Storage Gen2 数据导入 Azure Cosmos DB
本部分介绍了如何使用 Azure Cosmos DB Spark 连接器 在 Azure Cosmos DB 中写入数据。 Azure Cosmos DB Spark 连接器为 Azure Cosmos DB NoSQL API 提供 Apache Spark 支持。 可以使用它通过 Python 和 Scala 中的 Apache Spark 数据帧读取和写入 Azure Cosmos DB。
首先创建一个 Azure Databricks 工作区。 若要了解 Azure Cosmos DB Spark 连接器、Apache Spark、JVM、Scala 和 Databricks Runtime 等组件的版本兼容性,请参阅 兼容性矩阵。

创建 Azure Databricks 工作区后,请按照 文档安装相应的 Spark 连接器版本。 本文的其余步骤适用于 Databricks Runtime 15.4(带 Scala 2.12)上的连接器版本 4.36.0 和 Spark 3.5.0。 有关连接器的 Maven 坐标,请参阅 Maven Central 存储库。

GitHub(migration.ipynb)上的笔记本包含 Spark 代码,用于从 Data Lake Storage Gen2 读取数据并将其写入 Azure Cosmos DB。
将笔记本导入 Azure Databricks 工作区。
配置 Microsoft Entra ID 身份验证
将 OAuth 2.0 凭据与 Microsoft Entra ID 服务主体配合使用,从 Azure Databricks 连接到 Azure 存储。 按照 文档 完成以下步骤:
注册一个 Microsoft Entra 应用程序,并创建一个新的客户端密码。 这是一个一次性步骤,
在此过程中,请注意客户端 ID、客户端密码和租户 ID。 后续步骤中会用到它们。
在 Azure 存储帐户的 访问控制(IAM)下,将 存储 Blob 数据读取者 角色分配给创建的 Microsoft Entra ID 应用程序。
按照以下步骤配置 Azure Cosmos DB 的 Microsoft Entra 身份验证:
在 Azure Cosmos DB 帐户的 访问控制(IAM)下,将 Cosmos DB作员 角色分配给创建的 Microsoft Entra ID 应用程序。
在 Azure CLI 中使用以下命令创建 Azure Cosmos DB 角色定义并获取角色定义 ID。 如果没有 设置 Azure CLI,可以选择直接从 Azure 门户使用 Azure Cloud Shell 。
az cosmosdb sql role definition create --resource-group "<resource-group-name>" --account-name "<account-name>" --body '{ "RoleName": "<role-definition-name>", "Type": "CustomRole", "AssignableScopes": ["/"], "Permissions": [{ "DataActions": [ "Microsoft.DocumentDB/databaseAccounts/readMetadata", "Microsoft.DocumentDB/databaseAccounts/sqlDatabases/containers/items/*", "Microsoft.DocumentDB/databaseAccounts/sqlDatabases/containers/*" ] }] }' // List the role definition you created to fetch its unique identifier in the JSON output. Record the id value of the JSON output. az cosmosdb sql role definition list --resource-group "<resource-group-name>" --account-name "<account-name>"创建角色定义并获取角色定义 ID 后,使用以下命令 获取与 Microsoft Entra ID 应用程序关联的服务主体 ID。 用客户端 ID 替换
AppId,这是 Microsoft Entra ID 应用程序的客户端 ID。SP_ID=$(az ad sp list --filter "appId eq '{AppId}'" | jq -r '.[0].id')使用以下命令创建角色分配。 请确保替换资源组名称、Azure Cosmos DB 帐户名称和角色定义 ID。
az cosmosdb sql role assignment create --resource-group <enter resource group name> --account-name <enter cosmosdb account name> --scope "/" --principal-id $SP_ID --role-definition-id <enter role definition ID> --scope "/"
在笔记本里运行各个步骤
运行前两个步骤来安装所需的依赖项:
pip install azure-cosmos azure-mgmt-cosmosdb azure.mgmt.authorization
dbutils.library.restartPython()
第三步从 Data Lake Storage Gen2 读取 DynamoDB 数据并将其存储在 DataFrame 中。 在运行该步骤之前,请将以下信息替换为设置中的相应值:
| Variable | Description |
|---|---|
storage_account_name |
Azure 存储帐户名称。 |
container_name |
Azure 存储容器名称。 例如: s3datacopy。 |
file_path |
包含 Azure 存储容器中导出的 JSON 文件的文件夹的路径。 例如: AWSDynamoDB/01738047791106-7ba095a9/data/*。 |
client_id |
Microsoft Entra ID 应用程序的应用程序(客户端)ID(在 “概述 ”页上找到)。 |
tenant_id |
Microsoft Entra ID 应用程序的目录(租户)ID(在 “概述 ”页上找到)。 |
client_secret |
与 Microsoft Entra ID 应用程序关联的客户端密码的值(在 证书和机密中找到)。 |
如有必要,可以运行下一个单元(第四步)来执行任何数据转换或实现自定义逻辑。 例如,可以在将数据写入 Azure Cosmos DB 之前向数据添加字段 id 。
运行第五步以创建 Azure Cosmos DB 数据库和容器。 使用 Azure Cosmos DB Spark 连接器的 Catalog API。 将以下信息替换为你的设置中的相应值:
| Variable | Description |
|---|---|
cosmosEndpoint |
Azure Cosmos DB 帐户的 URI。 |
cosmosDatabaseName |
要创建的 Azure Cosmos DB 数据库的名称。 |
cosmosContainerName |
要创建的 Azure Cosmos DB 容器的名称。 |
subscriptionId |
Azure 订阅 ID。 |
resourceGroupName |
Azure Cosmos DB 资源组名称。 |
partitionKeyPath |
容器的分区键。 例如: /id。 |
throughput |
容器吞吐量。 例如: 1000。请注意与容器关联的吞吐量。 可能需要根据要迁移的数据量调整此值。 |
client_id |
Microsoft Entra ID 应用程序的应用程序(客户端)ID(在 “概述 ”页上找到)。 |
tenant_id |
Microsoft Entra ID 应用程序的目录(租户)ID(在 “概述 ”页上找到)。 |
client_secret |
与 Microsoft Entra ID 应用程序关联的客户端密码的值(在 证书和机密中找到)。 |
运行第六步,最后一步将数据写入 Azure Cosmos DB。 将以下信息替换为你的设置中的相应值:
| Variable | Description |
|---|---|
cosmosEndpoint |
Azure Cosmos DB 帐户的 URI。 |
cosmosDatabaseName |
要创建的 Azure Cosmos DB 数据库的名称。 |
cosmosContainerName |
要创建的 Azure Cosmos DB 容器的名称。 |
subscriptionId |
Azure 订阅 ID。 |
resourceGroupName |
Azure Cosmos DB 资源组名称。 |
client_id |
Microsoft Entra ID 应用程序的应用程序(客户端)ID(在 “概述 ”页上找到)。 |
tenant_id |
Microsoft Entra ID 应用程序的目录(租户)ID(在 “概述 ”页上找到)。 |
client_secret |
与 Microsoft Entra ID 应用程序关联的客户端密码的值(在 证书和机密中找到)。 |
单元执行完成后,请检查 Azure Cosmos DB 容器,验证是否已成功迁移数据。