你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
重要
新项目不再支持 Azure Cosmos DB for PostgreSQL。 不要将此服务用于新项目。 请改用以下两个服务之一:
将 Azure Cosmos DB for NoSQL 用于分布式数据库解决方案,该方案专为高规模场景设计,并提供 99.999% 的可用性服务级别协议(SLA)、即时自动缩放和跨多个区域的自动故障转移功能。
使用 Azure Database For PostgreSQL 的弹性群集功能,利用开源 Citus 扩展进行 PostgreSQL 的分片。
本文介绍如何使用 Azure 门户设置 Azure Cosmos DB for PostgreSQL 警报。 可根据监视指标接收 Azure 服务的警报。
我们将设置一个将在指定指标的值超出阈值时触发的警报。 首次满足条件时,将触发警报,之后也将继续触发。
可配置警报,使警报触发时执行以下操作:
- 向服务管理员和共同管理员发送电子邮件通知。
- 将电子邮件发送到指定的其他电子邮件地址。
- 调用 Webhook。
可使用以下项配置并获取预警规则相关信息:
通过 Azure 门户针对指标创建警报规则
在 Azure 门户中,选择要监视的 Azure Cosmos DB for PostgreSQL 服务器。
在边栏的“监视”部分选择“警报”,然后选择“创建”或“创建警报规则”。
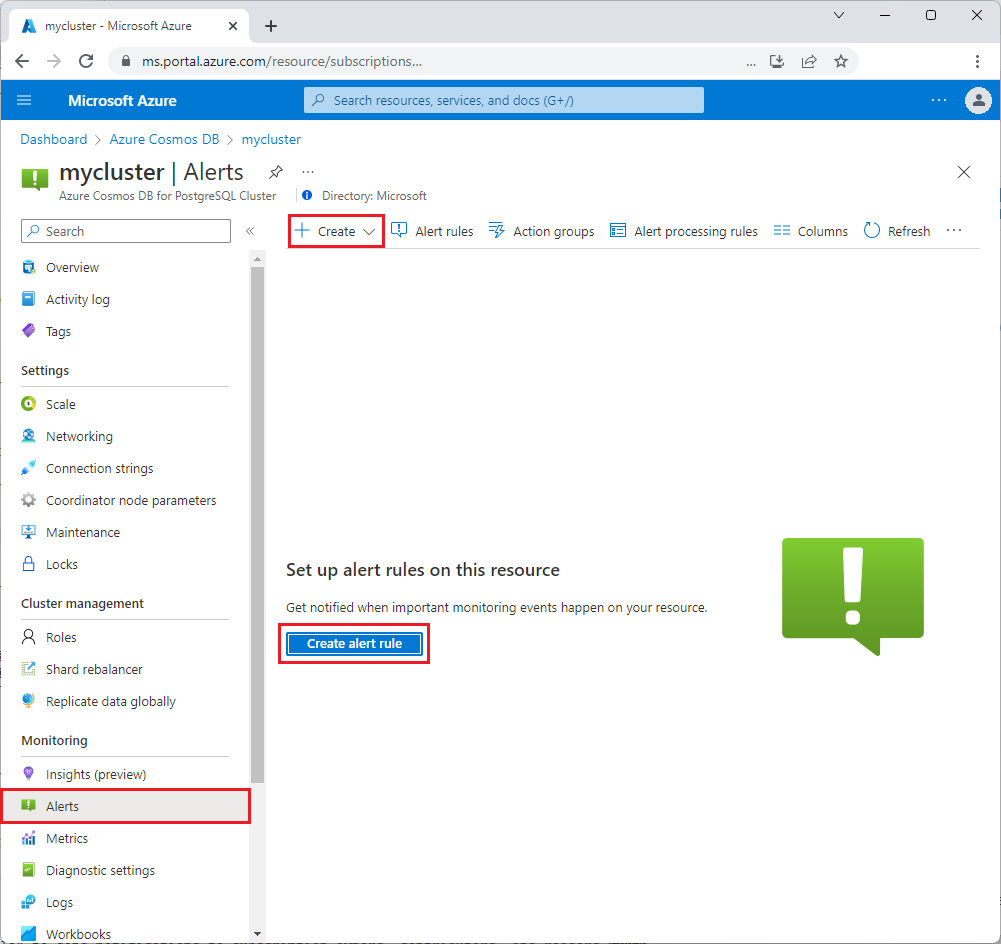
“选择信号”界面打开。 从要发出警报的信号列表中选择一个指标。 对于此示例,请选择存储百分率。
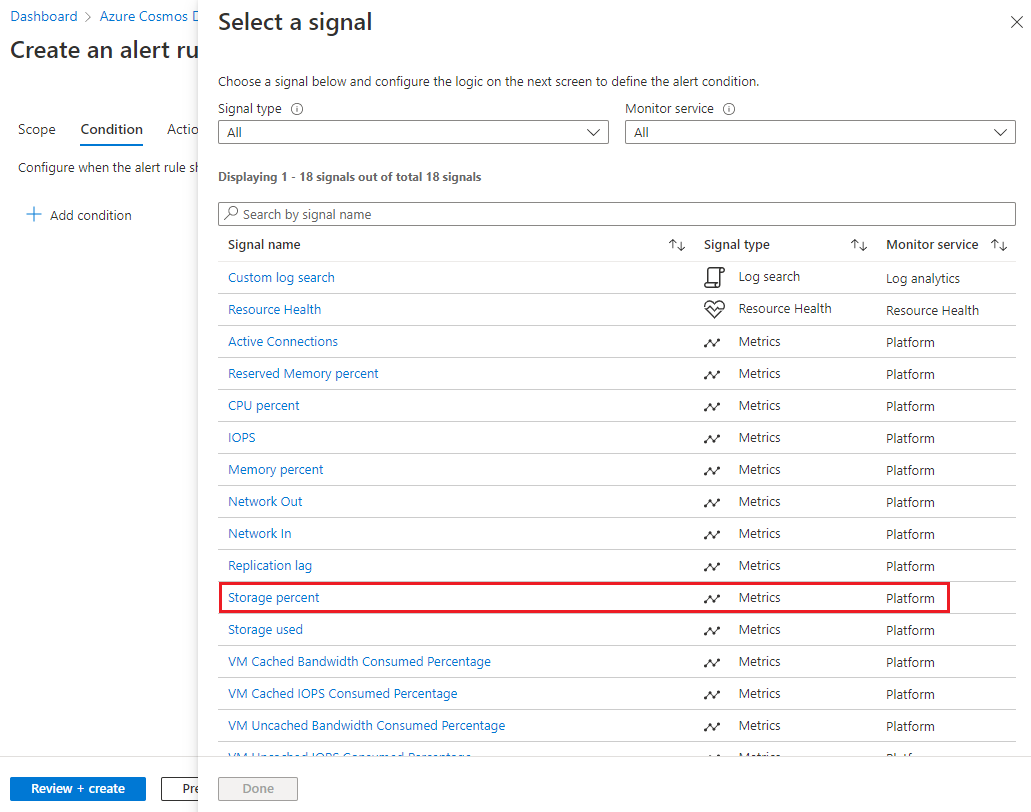
在“创建警报规则”页的“条件”选项卡上的“警报逻辑”下,完成以下项:
- 对于“阈值”,请选择“静态”。
- 对于“聚合类型”,请选择“平均值”。
- 对于“运算符”,请选择“大于”。
- 对于“阈值”,请输入 85。
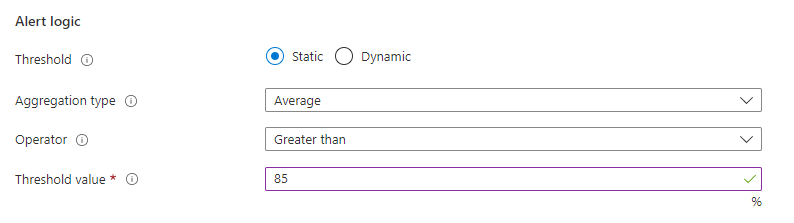
选择“操作”选项卡,然后选择“创建操作组”以创建用于接收警报通知的新组。
在“创建操作组”窗体上,选择“订阅”、“资源组”和“区域”,然后输入组的名称和显示名称。
选择页面底部的“下一步: 通知”。
在“通知”选项卡的“通知类型”下,选择“电子邮件/短信/推送/语音”。
在“电子邮件/短信/推送/语音”窗体上,填写与所需的通知类型和收件人对应的电子邮件地址和电话号码,然后选择“确定”。
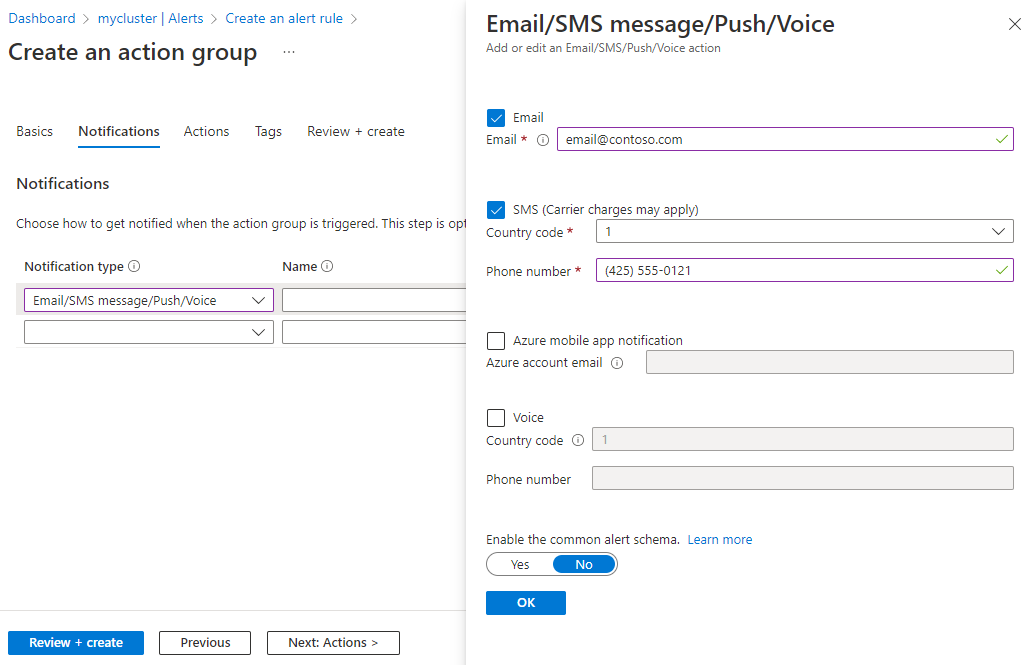
在“创建操作组”窗体上,输入新通知的名称。
选择“查看 + 创建”,然后选择“创建”以创建操作组。 此时会创建新操作组,并在“创建警报规则”页的“操作”选项卡上的“操作组名称”下显示它。
选择页面底部的“下一步: 详细信息”。
在“详细信息”选项卡上,选择规则的严重性。 为规则提供易于识别的名称,并添加可选说明。
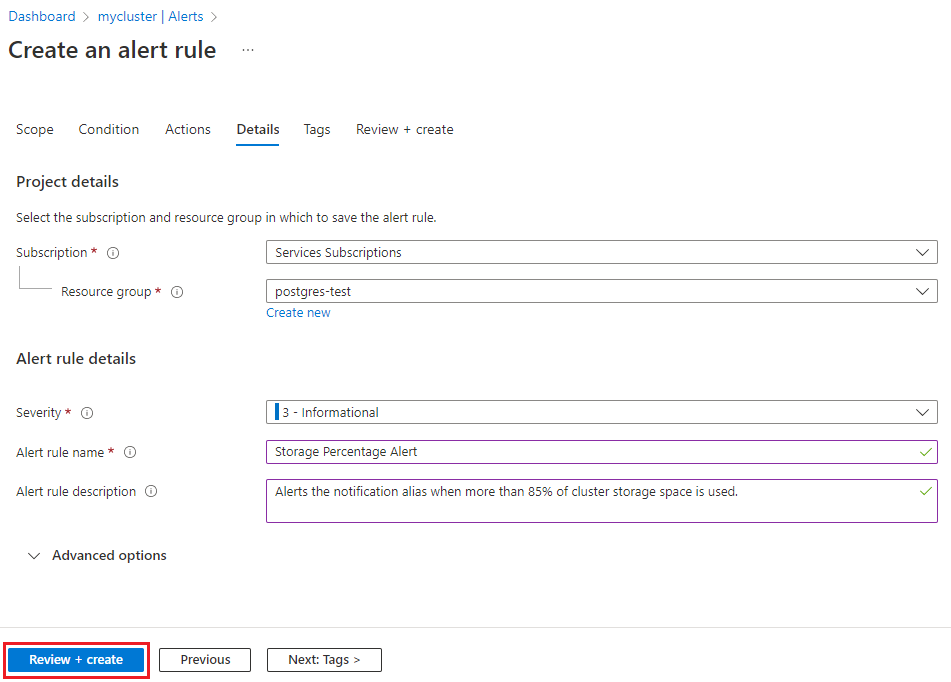
选择“查看 + 创建”,再选择“创建”以创建警报。 几分钟内,警报将按之前描述的方式激活并触发。
管理警报
创建警报后,可选择它并执行以下操作:
- 查看图,了解与此警报相关的指标阈值和前一天实际值。
- 编辑或删除预警规则 。
- 如果要暂时停止或恢复接收通知,可禁用或启用警报 。
建议的警报
以下是一些建议设置的警报示例。
磁盘空间
监视和警报对于每个生产群集都至关重要。 底层 PostgreSQL 数据库需要磁盘具有可用空间才能正常运行。 如果磁盘已满,数据库服务器节点将处于脱机状态并拒绝启动,直到磁盘有可用空间为止。 此时,需要发起 Microsoft 支持请求来处理这种情况。
建议对每个群集中的每个节点设置磁盘空间警报,即使是非生产性使用。 磁盘空间使用情况警报提供进行干预并使节点保持正常运行所需的高级警告。 为获得最佳结果,可尝试设置一系列在使用率达到 75%、85% 和 95% 时发出的警报。 选择的百分比取决于数据引入速度,因为数据引入速度快,磁盘也会更快地被填满。
磁盘快要达到其空间限制时,可尝试以下方法获取更多可用空间:
- 查看数据保留策略。 如果可行,请将较旧的数据移到冷存储。
- 考虑向群集添加节点并重新平衡分片。 重新平衡可让数据在多台计算机中分配。
- 考虑增加工作器节点的容量。 每个员工最多可拥有 2 TiB 的存储空间。 但应该先尝试添加节点,再调整节点大小,因为添加节点过程可更快完成。
CPU 使用率
监视 CPU 使用率有助于建立性能基线。 例如,你可能会注意到,CPU 使用率通常约为 40-60%。 如果 CPU 使用率突然开始停留在 95%,则可以识别出异常情况。 CPU 使用率可反映自然增长,但也可能会反映出意外的查询。 创建 CPU 警报时,请设置较长的聚合粒度来捕获长期的增长情况,并忽略短暂的峰值。
后续步骤
- 了解更多关于在警报中配置 Webhook的方法。
- 获取指标集合概述以确保服务可用且响应迅速。