你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
重要
新项目不再支持 Azure Cosmos DB for PostgreSQL。 不要将此服务用于新项目。 请改用以下两个服务之一:
将 Azure Cosmos DB for NoSQL 用于分布式数据库解决方案,该方案专为高规模场景设计,并提供 99.999% 的可用性服务级别协议(SLA)、即时自动缩放和跨多个区域的自动故障转移功能。
使用 Azure Database For PostgreSQL 的弹性群集功能,利用开源 Citus 扩展进行 PostgreSQL 的分片。
在本教程中,你将使用 Azure Cosmos DB for PostgreSQL 来了解如何执行以下操作:
- 创建哈希分布式分片
- 查看表分片的放置位置
- 识别倾斜分布
- 对分布式表创建约束
- 对分布式数据运行查询
先决条件
本教程需要一个正在运行的群集,该群集具有两个工作器节点。 如果没有正在运行的群集,请按照创建群集教程操作,然后再回到本教程。
哈希分布式数据
在多个 PostgreSQL 服务器之间分布表行是 Azure Cosmos DB for PostgreSQL 中可缩放查询的一项关键技术。 同时,多个节点可容纳的数据比传统数据库更多,并且在许多情况下,可并行使用工作器 CPU 来执行查询。 哈希分布式表概念也称为基于行的分片。
在先决条件部分,我们创建了一个包含两个工作器节点的群集。
协调器节点的元数据表跟踪工作器和分布式数据。 可在 pg_dist_node 表中检查活动工作器。
select nodeid, nodename from pg_dist_node where isactive;
nodeid | nodename
--------+-----------
1 | 10.0.0.21
2 | 10.0.0.23
注意
Azure Cosmos DB for PostgreSQL 上的节点名称是虚拟网络中的内部 IP 地址,你看到的实际地址可能会有所不同。
行、分片和放置
若要使用工作器节点的 CPU 和存储资源,必须在整个群集中分布表数据。 分布表会将每一行分配给一个名为“分片”的逻辑组。接下来创建一个表并将其分布:
-- create a table on the coordinator
create table users ( email text primary key, bday date not null );
-- distribute it into shards on workers
select create_distributed_table('users', 'email');
Azure Cosmos DB for PostgreSQL 根据分布列的值将每一行分配给一个分片,在本例中,我们将其指定为 。 每一行只能分配到一个分片,每个分片可以包含多行。
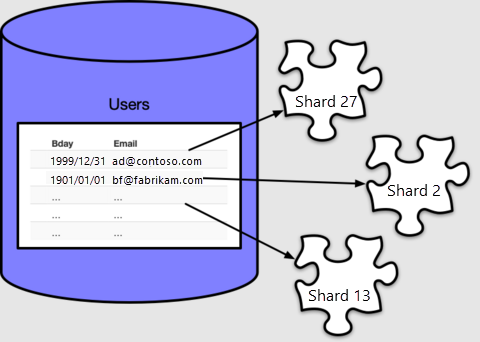
默认情况下,create_distributed_table() 会生成 32 个分片,在元数据表 pg_dist_shard 中计数即可得到此值:
select logicalrelid, count(shardid)
from pg_dist_shard
group by logicalrelid;
logicalrelid | count
--------------+-------
users | 32
Azure Cosmos DB for PostgreSQL 根据分布列中的值的哈希,使用 pg_dist_shard 表将行分配给分片。 对于本教程而言,哈希详细信息并不重要。 重要的是,可通过查询来查看哪些值映射到哪些分片 ID:
-- Where would a row containing hi@test.com be stored?
-- (The value doesn't have to actually be present in users, the mapping
-- is a mathematical operation consulting pg_dist_shard.)
select get_shard_id_for_distribution_column('users', 'hi@test.com');
get_shard_id_for_distribution_column
--------------------------------------
102008
行到分片的映射是纯逻辑性的。 分片必须分配给特定工作器节点进行存储,这在 Azure Cosmos DB for PostgreSQL 中称为“分片放置”。
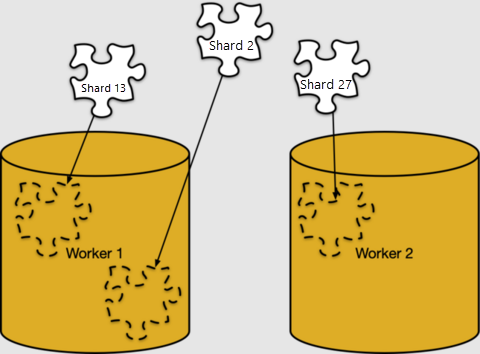
可在 pg_dist_placement 中查看分片放置。 将其与我们已看到的其他元数据表联接,可显示每个分片的所在位置。
-- limit the output to the first five placements
select
shard.logicalrelid as table,
placement.shardid as shard,
node.nodename as host
from
pg_dist_placement placement,
pg_dist_node node,
pg_dist_shard shard
where placement.groupid = node.groupid
and shard.shardid = placement.shardid
order by shard
limit 5;
table | shard | host
-------+--------+------------
users | 102008 | 10.0.0.21
users | 102009 | 10.0.0.23
users | 102010 | 10.0.0.21
users | 102011 | 10.0.0.23
users | 102012 | 10.0.0.21
数据倾斜
将数据均匀地置于工作器节点上,并将相关数据一起放置在同一工作器上时,群集的运行效率最高。 本节将重点介绍第一部分,即放置的一致性。
为了演示,接下来为 users 表创建示例数据:
-- load sample data
insert into users
select
md5(random()::text) || '@test.com',
date_trunc('day', now() - random()*'100 years'::interval)
from generate_series(1, 1000);
若要查看分片大小,可在分片上运行表大小函数。
-- sizes of the first five shards
select *
from
run_command_on_shards('users', $cmd$
select pg_size_pretty(pg_table_size('%1$s'));
$cmd$)
order by shardid
limit 5;
shardid | success | result
---------+---------+--------
102008 | t | 16 kB
102009 | t | 16 kB
102010 | t | 16 kB
102011 | t | 16 kB
102012 | t | 16 kB
我们可以看到分片的大小相等。 我们已看到放置在工作器节点之间均匀分布,因此可推断这些工作器节点拥有的行数大致相等。
users 示例中的行因分布列 email 的属性而均匀分布。
- 电子邮件地址数大于或等于分片数。
- 每个电子邮件地址的行数类似(在我们的示例中,每个地址正好占一行,因为我们将电子邮件声明为键)。
对于选择的任何表和分布列,如果其中任一属性失败,都将导致工作器上的数据大小不均匀,即数据倾斜。
对分布式数据添加约束
使用 Azure Cosmos DB for PostgreSQL,你可继续享有关系数据库的安全性,包括数据库约束。 但是,存在一个限制。 由于分布式系统的性质,Azure Cosmos DB for PostgreSQL 不会在工作器节点之间交叉引用唯一性约束或引用完整性。
接下来考虑使用具有相关表的 users 表示例。
-- books that users own
create table books (
owner_email text references users (email),
isbn text not null,
title text not null
);
-- distribute it
select create_distributed_table('books', 'owner_email');
为提高效率,我们以与 books 相同的方式分布 users:按所有者的电子邮件地址。 按类似的列值进行分布称为归置。
由于键在分布列上,因此可以轻松地向用户分发具有外键的书籍。 但是很难将 isbn 设为键:
-- will not work
alter table books add constraint books_isbn unique (isbn);
ERROR: cannot create constraint on "books"
DETAIL: Distributed relations cannot have UNIQUE, EXCLUDE, or
PRIMARY KEY constraints that do not include the partition column
(with an equality operator if EXCLUDE).
在分布式表中,最佳做法是使列对分布列进行唯一取模:
-- a weaker constraint is allowed
alter table books add constraint books_isbn unique (owner_email, isbn);
上述约束只是使每个用户的 isbn 是唯一的。 另一种方法是使书籍成为引用表而不是分布式表,并创建单独的分布式表,将书籍与用户相关联。
查询分布式表
在前面的部分中,我们看到了分布式表行如何放置在工作器节点上的分片中。 大多数情况下,不需要知道数据在群集中的存储方式或存储位置。 Azure Cosmos DB for PostgreSQL 具有分布式查询执行程序,可自动拆分常规 SQL 查询。 它在靠近数据的工作器节点上并行运行这些查询。
例如,可运行查询来查找用户的平均年龄,将分布式 users 表视为协调器上的普通表。
select avg(current_date - bday) as avg_days_old from users;
avg_days_old
--------------------
17926.348000000000
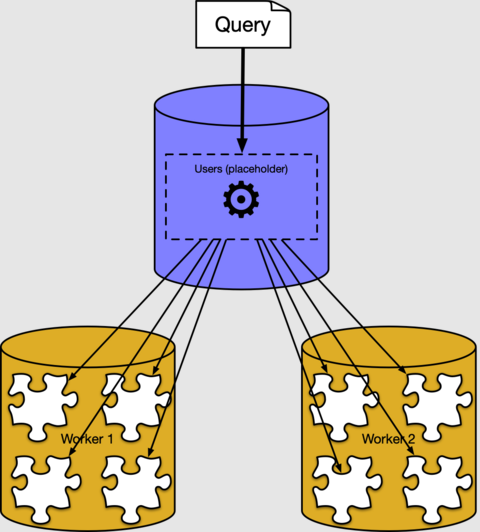
在后台,Azure Cosmos DB for PostgreSQL 执行程序为每个分片创建一个单独的查询,在工作器上运行这些查询,并将结果组合在一起。 如果使用 PostgreSQL EXPLAIN 命令,可以看到:
explain select avg(current_date - bday) from users;
QUERY PLAN
----------------------------------------------------------------------------------
Aggregate (cost=500.00..500.02 rows=1 width=32)
-> Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=100000 width=16)
Task Count: 32
Tasks Shown: One of 32
-> Task
Node: host=10.0.0.21 port=5432 dbname=citus
-> Aggregate (cost=41.75..41.76 rows=1 width=16)
-> Seq Scan on users_102040 users (cost=0.00..22.70 rows=1270 width=4)
输出显示了在分片 102040(工作器 10.0.0.21 上的表 )上运行的查询片段的执行计划示例。 未显示其他片段,因为它们类似。 可以看到工作器节点扫描了分片表,并应用了聚合。 协调器节点合并聚合以获得最终结果。
后续步骤
在本教程中,我们创建了一个分布式表,并了解了其分片和放置。 我们了解了使用唯一性和外键约束的挑战,最后大致了解了分布式查询的工作原理。