你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
适用对象:
![]() NoSQL
NoSQL
![]() MongoDB
MongoDB
![]() Cassandra
Cassandra
![]() Gremlin
Gremlin
![]() 表
表
Azure Cosmos DB 允许对数据库和容器设置预配吞吐量。 有两种类型的预配吞吐量:标准(手动)或自动缩放。 本文概述了预配吞吐量的工作原理。
Azure Cosmos DB 数据库是一组容器的管理单元。 数据库包含一组不限架构的容器。 Azure Cosmos DB 容器是吞吐量和存储的缩放单元。 容器跨 Azure 区域中的一组计算机进行水平分区,分布在与 Azure Cosmos DB 帐户关联的所有 Azure 区域中。
使用 Azure Cosmos DB 时,可以在两个粒度级别预配吞吐量:
- Azure Cosmos DB 容器
- Azure Cosmos DB 数据库
对容器设置吞吐量
在 Azure Cosmos DB 容器上预配的吞吐量专门保留给该容器使用。 容器始终可获得预配的吞吐量。 对容器预配的吞吐量有 SLA 提供的经济保障。 若要了解如何在容器上配置标准(手动)吞吐量,请参阅在 Azure Cosmos DB 容器上预配吞吐量。 若要了解如何对容器配置自动缩放吞吐量,请参阅预配自动缩放吞吐量。
对容器设置预配吞吐量是最常用的选项。 可以通过使用请求单位 (RU) 预配任意数量的吞吐量来弹性缩放容器的吞吐量。
为容器预配的吞吐量在其物理分区之间均匀分布。假设有一个适当的分区键,它在物理分区之间均匀分配逻辑分区,那么吞吐量也均匀分布在容器的所有逻辑分区上。 你无法有选择性地指定逻辑分区的吞吐量。 由于某个容器的一个或多个逻辑分区由物理分区托管,因此,物理分区专属于该容器,并支持对该容器预配的吞吐量。
如果在逻辑分区上运行的工作负荷消耗的吞吐量超过分配给底层物理分区的吞吐量,则操作可能会受到速率限制。 当一个逻辑分区的请求比其他分区键值多得多时,就会出现所谓的“热分区”。
出现速率限制时,可以增大整个容器的预配吞吐量,或重试操作。 还应确保选择均匀分配存储和请求卷的分区键。 有关分区的详细信息,请参阅 Azure Cosmos DB 中的分区和横向缩放。
如果你希望容器的性能可预测,建议你以容器粒度配置吞吐量。
下图显示了物理分区如何托管容器的一个或多个逻辑分区:
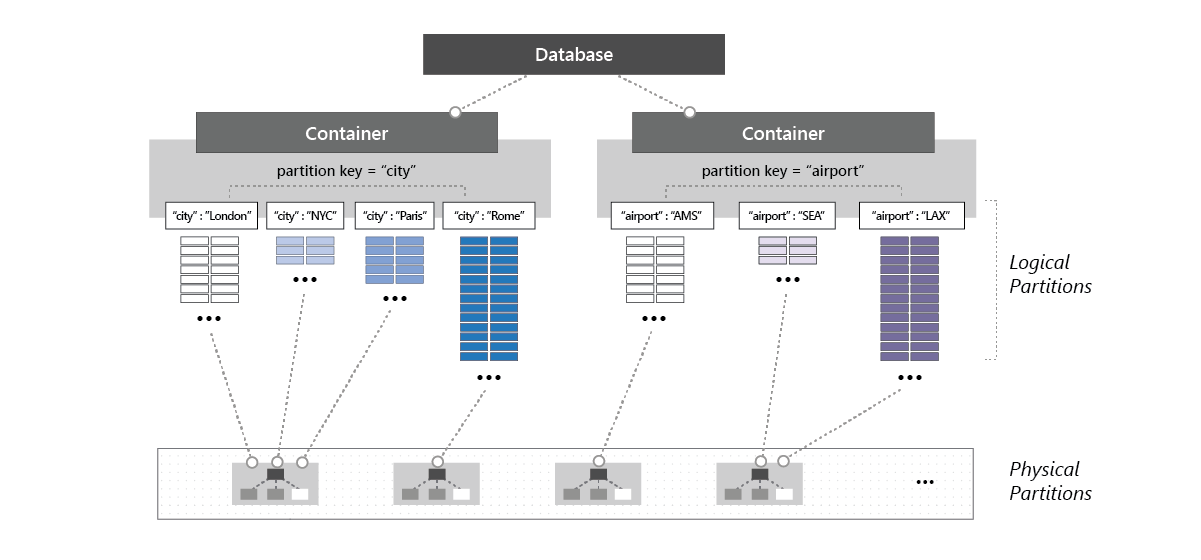
对数据库设置吞吐量
在 Azure Cosmos DB 数据库上预配吞吐量时,会在该数据库中的所有容器(称作共享的数据库容器)之间共享吞吐量。 一种例外是在数据库中的特定容器上指定了预配的吞吐量。 在容器之间共享数据库级预配吞吐量相当于在计算机群集上托管数据库。 由于数据库中的所有容器共享一台计算机上的可用资源,因此,任何特定容器的性能自然不可预测。 若要了解如何在数据库上配置预配吞吐量,请参阅在 Azure Cosmos DB 数据库上配置预配吞吐量。 若要了解如何对数据库配置自动缩放吞吐量,请参阅预配自动缩放吞吐量。
由于数据库中的所有容器共享预配的吞吐量,因此,Azure Cosmos DB 不会针对该数据库中的特定容器提供任何可预测的吞吐量保证。 特定容器可获得的吞吐量部分取决于:
- 容器数量。
- 为各个容器选择的分区键。
- 工作负荷在容器的各个逻辑分区之间的分布形式。
若要在多个容器之间共享吞吐量,而不希望将吞吐量专门提供给任何特定的容器使用,则我们建议对数据库配置吞吐量。
以下示例演示了最适合在数据库级别的哪个位置预配吞吐量:
对于多租户应用程序来说,在一组容器之间共享数据库的预配吞吐量非常有用。 每个用户可由不同的 Azure Cosmos DB 容器表示。
将 VM 群集或本地物理服务器中托管的 NoSQL 数据库(例如 MongoDB 或 Cassandra)迁移到 Azure Cosmos DB 时,在一组容器之间共享数据库的预配吞吐量非常有利。 可将在 Azure Cosmos DB 数据库上配置的预配吞吐量视为在逻辑上等同于(但更具成本效益和弹性)MongoDB 或 Cassandra 群集的计算容量。
必须使用分区键创建在具有预配吞吐量的数据库内创建的所有容器。 在任何给定的时间点,数据库上配置的吞吐量由该数据库内的所有容器共享。 如果有容器共享对数据库配置的预配吞吐量,则无法选择性地将吞吐量应用到特定的容器或逻辑分区。
如果一个或多个逻辑分区上的工作负荷总计超过了基础物理分区的已分配吞吐量,则会对操作进行速率限制。 出现速率限制时,可以增大整个数据库的吞吐量,或重试操作。 有关分区的详细信息,请参阅分区。
共享吞吐量数据库中的容器共享分配给该数据库的吞吐量(RU/秒)。 使用标准(手动)预配吞吐量,数据库中最多可以有 25 个最小吞吐量为 400 RU/秒的容器。 如果使用自动缩放预配吞吐量,那么一个数据库中最多可以有 25 个容器,其吞吐量可自动缩放到的最小值是 1000 RU/秒(在 100 - 1000 RU/秒之间缩放)。
注意
2020 年 2 月,我们引入了一项更改,允许在一个共享吞吐量数据库中最多包含 25 个容器,以方便实现跨容器共享吞吐量。 有了头 25 个容器之后,仅当容器预配了专用吞吐量(与数据库的共享吞吐量分离)时,才能向数据库添加更多容器。
如果 Azure Cosmos DB 帐户已包含一个具有 >=25 个容器的共享吞吐量数据库,则该帐户和同一 Azure 订阅中的所有其他帐户均不受此更改限制。 如果有反馈或疑问,请联系产品支持。
如果工作负荷涉及到删除数据库中的所有集合并重新创建集合,则我们建议删除空数据库,再重新创建新的数据库,然后创建集合。 下图显示了物理分区如何托管属于数据库中不同容器的一个或多个逻辑分区:
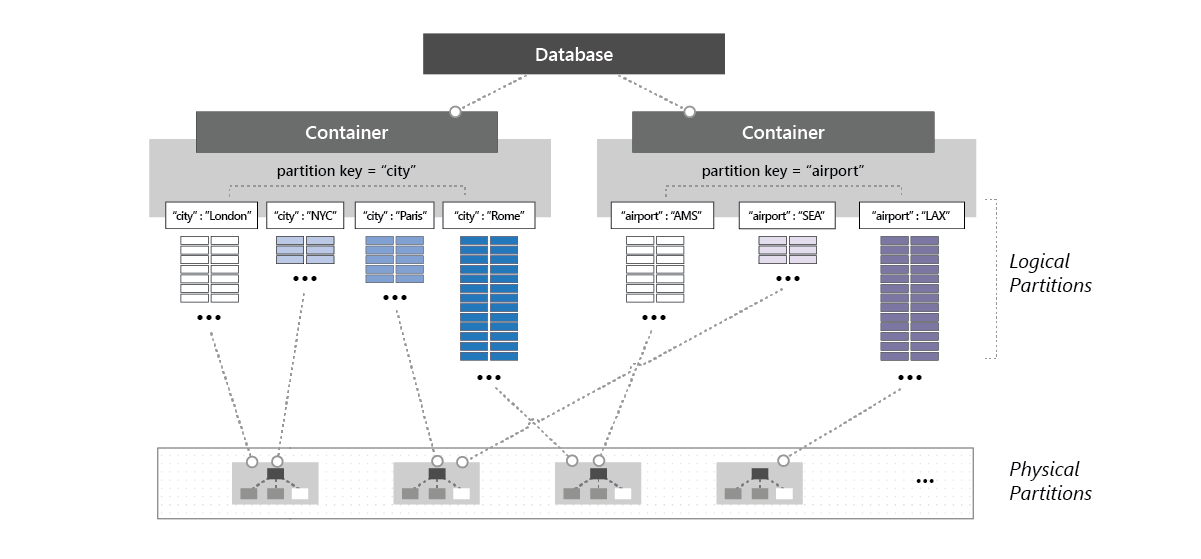
对数据库和容器设置吞吐量
可以合并两个模型。 同时对数据库和容器预配吞吐量。 以下示例演示如何在 Azure Cosmos DB 数据库和容器上预配标准(手动)预配吞吐量:
可以创建一个具有标准(手动)预配吞吐量(“K”RU)且名为 Z 的 Azure Cosmos DB 数据库。
接下来,在该数据库中创建名为 A、B、C、D 和 E 的五个容器。 创建容器 B 时,请确保启用“为此容器预配专用吞吐量”选项,并在此容器上显式配置“P”个 RU 的预配吞吐量。 只有在创建数据库和容器时,才能配置共享吞吐量和专用吞吐量。
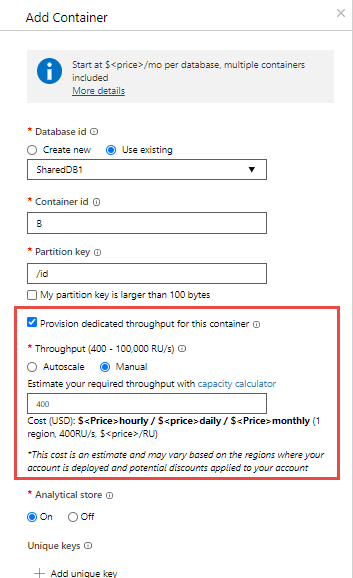
“K”RU/s 吞吐量在 A、C、D 和 E 这四个容器之间共享。A、C、D 或 E 可用的确切吞吐量因情况而异。 每个容器的吞吐量没有 SLA 的保障。
名为 B 的容器已被确保始终可以获得“P”RU/s 吞吐量。 该容器有 SLA 的保障。
注意
具有预配吞吐量的容器无法转换为共享的数据库容器。 反之,共享的数据库容器无法转换为具有专用吞吐量的容器。 需要将数据移动到具有所需吞吐量设置的容器中。 (NoSQL、MongoDB 和 Cassandra API 的容器复制作业有助于完成此过程。)
更新数据库或容器的吞吐量
创建 Azure Cosmos DB 容器或数据库后,可以更新预配的吞吐量。 可对数据库或容器配置的最大预配吞吐量没有限制。
当前的预配的吞吐量
可以通过 Azure 门户或 SDK 来检索容器或数据库的预配吞吐量:
- .NET SDK 上的 Container.ReadThroughputAsync。
- Java SDK 上的 CosmosContainer.readThroughput。
这些方法的响应还包含容器或数据库的最小预配吞吐量:
- .NET SDK 上的 ThroughputResponse.MinThroughput。
- Java SDK 上的 ThroughputResponse.getMinThroughput()。
实际的最小 RU/s 可能因帐户配置而异。 有关详细信息,请参阅自动缩放 FAQ。
更改预配吞吐量
可以通过 Azure 门户或 SDK 来缩放容器或数据库的预配吞吐量:
- .NET SDK 上的 Container.ReplaceThroughputAsync。
- Java SDK 上的 CosmosContainer.replaceThroughput。
如果你减小预配吞吐量,则最多可以将其减小到最小值。
如果你增大预配吞吐量,则在大多数情况下,操作是即时的。 但是在某些情况下,由于系统任务的原因,该操作可能需要较长的时间来预配所需的资源。 在这种情况下,如果尝试在此操作正在进行时修改预配的吞吐量,则会生成一个 HTTP 423 响应,并会出现一条错误消息,指出另一个缩放操作正在进行。
在缩放预配吞吐量的最佳做法(RU/秒)文章中了解详细信息。
注意
如果你正在规划非常大的引入工作负荷,并且该工作负荷需要大大增加预配的吞吐量,则请记住:缩放操作没有 SLA,当增加量很大时可能需要很长时间,如上一段所述。 你可能需要提前规划并在工作负荷启动之前开始缩放,同时使用以下方法来检查进度。
你可以通过编程方式检查缩放进度,方法是:读取当前预配的吞吐量并使用以下项:
- .NET SDK 上的 ThroughputResponse.IsReplacePending。
- Java SDK 上的 ThroughputResponse.isReplacePending()。
可以使用 Azure Monitor 指标来查看资源上预配吞吐量 (RU/s) 和存储的历史记录。
模型比较
下表显示了对数据库与容器预配标准(手动)吞吐量时的差异比较。
| 参数 | 对数据库预配标准(手动)吞吐量 | 对容器预配标准(手动)吞吐量 | 对数据库预配自动缩放吞吐量 | 对容器预配自动缩放吞吐量 |
|---|---|---|---|---|
| 入口点(最小 RU/秒) | 400 RU/秒。 最多可以有 25 个容器,每个容器没有最小的 RU/秒吞吐量。 | 400 | 在 100 - 1000 RU/秒之间自动缩放。 最多可以有 25 个容器,每个容器没有最小的 RU/秒吞吐量。 | 在 100 - 1000 RU/秒之间自动缩放。 |
| 每个容器的最小 RU/秒吞吐量 | -- | 400 | -- | 在 100 - 1000 RU/秒之间自动缩放 |
| 最大 RU 数 | 对于数据库无限。 | 对于容器无限。 | 对于数据库无限。 | 对于容器无限。 |
| 分配或提供给特定容器的 RU 数 | 无保证。 为给定容器分配的 RU 数取决于多种属性。 属性可以是为共享吞吐量的容器选择的分区键、工作负荷的分布,以及容器的数量。 | 对容器配置的所有 RU 专门保留给该容器使用。 | 无保证。 为给定容器分配的 RU 数取决于多种属性。 属性可以是为共享吞吐量的容器选择的分区键、工作负荷的分布,以及容器的数量。 | 对容器配置的所有 RU 专门保留给该容器使用。 |
| 容器的最大存储 | 不受限制。 | 无限制 | 无限制 | 无限制 |
| 容器的每个逻辑分区的最大吞吐量 | 10K RU/秒 | 10K RU/秒 | 10K RU/秒 | 10K RU/秒 |
| 容器的每个逻辑分区的最大存储(数据 + 索引) | 20 GB | 20 GB | 20 GB | 20 GB |
后续步骤
- 详细了解逻辑分区。
- 了解如何在 Azure Cosmos DB 容器上预配标准(手动)吞吐量。
- 了解如何在 Azure Cosmos DB 数据库上预配标准(手动)吞吐量。
- 了解如何在 Azure Cosmos DB 数据库或容器上预配自动缩放吞吐量。
- 尝试为迁移到 Azure Cosmos DB 进行容量计划? 可以使用有关现有数据库群集的信息进行容量规划。
- 如果只知道现有数据库群集中的 vCore 和服务器数量,请阅读使用 vCore 或 vCPU 估算请求单位
- 若知道当前数据库工作负载的典型请求速率,请阅读使用 Azure Cosmos DB 容量计划工具估算请求单位