你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用 Azure 数据工厂或 Synapse Analytics 从 SAP HANA 复制数据
适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
提示
试用 Microsoft Fabric 中的数据工厂,这是一种适用于企业的一站式分析解决方案。 Microsoft Fabric 涵盖从数据移动到数据科学、实时分析、商业智能和报告的所有内容。 了解如何免费开始新的试用!
本文概述如何在 Azure 数据工厂和 Synapse Analytics 管道中使用复制活动从 SAP HANA 数据库复制数据。 它是基于概述复制活动总体的复制活动概述一文。
提示
若要了解对 SAP 数据集成方案的总体支持,请参阅 SAP 数据集成白皮书,其中包含有关每个 SAP 连接器的详细介绍、比较和指导。
支持的功能
此 SAP HANA 连接器支持以下功能:
| 支持的功能 | IR |
|---|---|
| 复制活动(源/接收器) | ② |
| Lookup 活动 | ② |
① Azure 集成运行时 ② 自承载集成运行时
有关复制活动支持作为源/接收器的数据存储列表,请参阅支持的数据存储表。
具体而言,此 SAP HANA 连接器支持:
- 从任何版本的 SAP HANA 数据库复制数据。
- 从 HANA 信息模型(如分析和计算视图)和行/列表中复制数据。
- 使用基本或 Windows 身份验证复制数据。
- 从 SAP HANA 源进行并行复制。 有关详细信息,请参阅从 SAP HANA 进行并行复制部分。
提示
要将数据复制到 SAP HANA 数据存储,请使用泛型 ODBC 连接器。 有关详细信息,请参阅 SAP HANA 接收器部分。 注意:适用于 SAP HANA 连接器和 ODBC 连接器的链接服务采用不同的类型,因此不能重用。
先决条件
要使用此 SAP HANA 连接器,需要:
- 设置自承载集成运行时。 有关详细信息,请参阅自承载集成运行时一文。
- 在集成运行时计算机上安装 SAP HANA ODBC 驱动程序。 可以从 SAP 软件下载中心下载 SAP HANA ODBC 驱动程序。 使用关键字 SAP HANA CLIENT for Windows 进行搜索。
入门
若要使用管道执行复制活动,可以使用以下工具或 SDK 之一:
使用 UI 创建到 SAP HANA 的链接服务
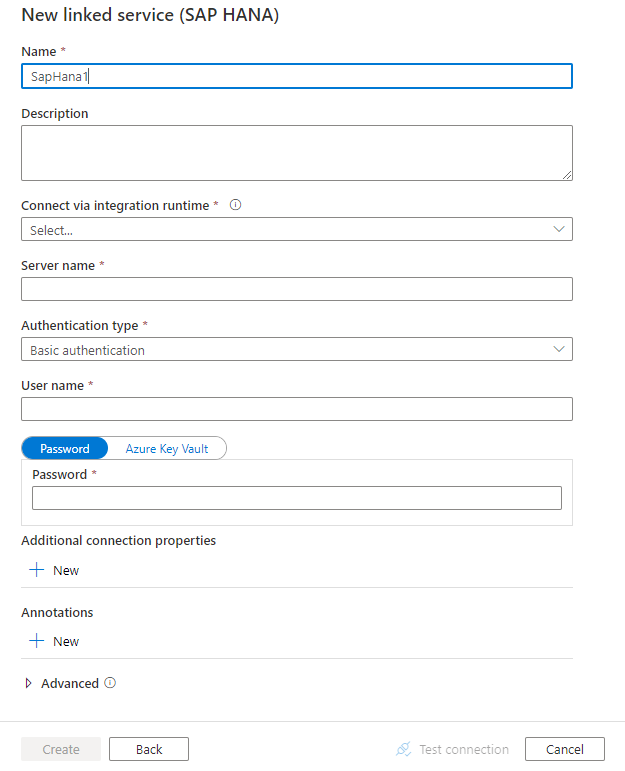
使用以下步骤在 Azure 门户 UI 中创建一个到 SAP HANA 的链接服务。
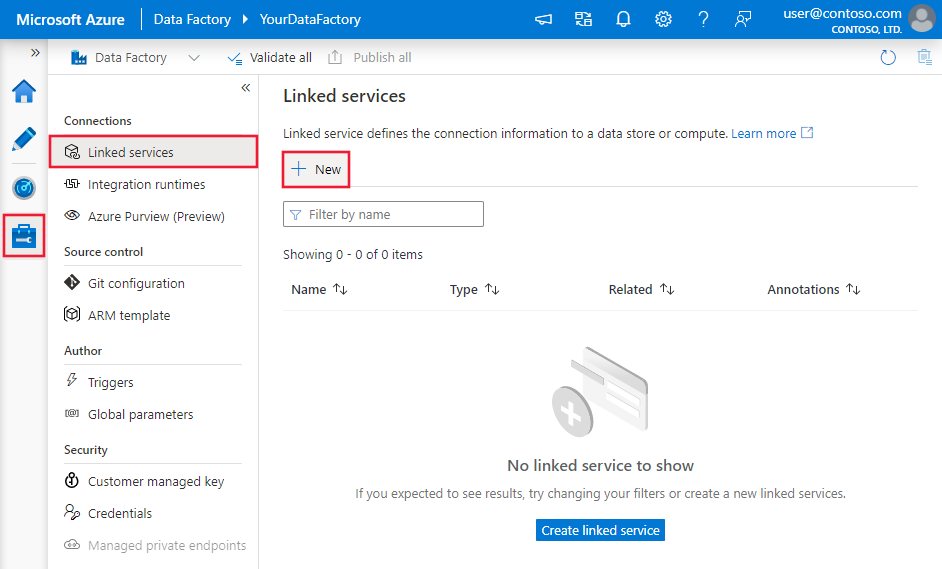
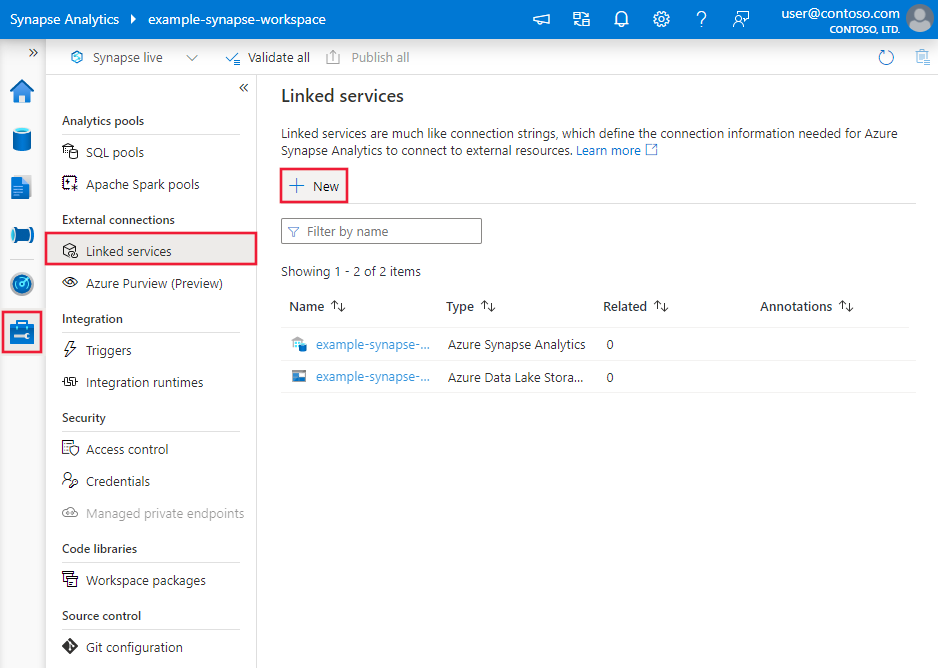
浏览到 Azure 数据工厂或 Synapse 工作区中的“管理”选项卡并选择“链接服务”,然后单击“新建”:
搜索“SAP”并选择“SAP HANA 连接器”。

配置服务详细信息、测试连接并创建新的链接服务。
连接器配置详细信息
对于特定于 SAP HANA 连接器的数据工厂实体,以下部分提供有关用于定义这些实体的属性的详细信息。
链接服务属性
SAP HANA 链接的服务支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| type | type 属性必须设置为:SapHana | 是 |
| connectionString | 指定使用基本身份验证或 Windows 身份验证连接到 SAP HANA 时所需的信息。 请参阅以下示例。 在连接字符串中,服务器/端口是必需的(默认端口为 30015)。在使用基本身份验证时,用户名和密码是必需的。 有关其他高级设置,请参阅 SAP HANA ODBC 连接属性 还可以将密码放在 Azure 密钥保管库中,并从连接字符串中拉取密码配置。 有关更多详细信息,请参阅在 Azure Key Vault 中存储凭据一文。 |
是 |
| userName | 使用 Windows 身份验证时,请指定用户名。 示例: user@domain.com |
否 |
| password | 指定用户帐户的密码。 将此字段标记为 SecureString 以安全地存储它,或引用 Azure Key Vault 中存储的机密。 | 否 |
| connectVia | 用于连接到数据存储的集成运行时。 如先决条件中所述,需要自承载集成运行时。 | 是 |
示例:使用基本身份验证
{
"name": "SapHanaLinkedService",
"properties": {
"type": "SapHana",
"typeProperties": {
"connectionString": "SERVERNODE=<server>:<port (optional)>;UID=<userName>;PWD=<Password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
示例:使用 Windows 身份验证
{
"name": "SapHanaLinkedService",
"properties": {
"type": "SapHana",
"typeProperties": {
"connectionString": "SERVERNODE=<server>:<port (optional)>;",
"userName": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
如果使用的是具有以下有效负载的 SAP HANA 链接服务,它仍然按原样受支持,但建议使用新的版本。
示例:
{
"name": "SapHanaLinkedService",
"properties": {
"type": "SapHana",
"typeProperties": {
"server": "<server>:<port (optional)>",
"authenticationType": "Basic",
"userName": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
数据集属性
有关可用于定义数据集的各部分和属性的完整列表,请参阅数据集一文。 本部分提供 SAP HANA 数据集支持的属性列表。
支持使用以下属性从 SAP HANA 复制数据:
| 属性 | 描述 | 必需 |
|---|---|---|
| type | 数据集的 type 属性必须设置为:SapHanaTable | 是 |
| 架构 | SAP HANA 数据库中架构的名称。 | 否(如果指定了活动源中的“query”) |
| 表 | SAP HANA 数据库中表的名称。 | 否(如果指定了活动源中的“query”) |
示例:
{
"name": "SAPHANADataset",
"properties": {
"type": "SapHanaTable",
"typeProperties": {
"schema": "<schema name>",
"table": "<table name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<SAP HANA linked service name>",
"type": "LinkedServiceReference"
}
}
}
如果使用 RelationalTable 类型数据集,该数据集仍按原样受支持,但我们建议今后使用新数据集。
复制活动属性
有关可用于定义活动的各部分和属性的完整列表,请参阅管道一文。 本部分提供 SAP HANA 源支持的属性列表。
以 SAP HANA 作为源
提示
若要详细了解如何使用数据分区从 SAP HANA 有效引入数据,请参阅从 SAP HANA 进行并行复制部分。
若要从 SAP HANA 复制数据,复制活动的 source 节支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| type | 复制活动 source 的 type 属性必须设置为:SapHanaSource | 是 |
| 查询 | 指定要从 SAP HANA 实例读取数据的 SQL 查询。 | 是 |
| partitionOptions | 指定用于从 SAP HANA 引入数据的数据分区选项。 从从 SAP HANA 进行并行复制部分了解详细信息。 允许的值为:None(默认值)、PhysicalPartitionsOfTable、SapHanaDynamicRange。 从从 SAP HANA 进行并行复制部分了解详细信息。 PhysicalPartitionsOfTable 只能在从表而非查询中复制数据时使用。 启用分区选项(即,该选项不为 None)时,用于从 SAP HANA 并行加载数据的并行度由复制活动上的 parallelCopies 设置控制。 |
False |
| partitionSettings | 指定数据分区的设置组。 当分区选项是 SapHanaDynamicRange 时适用。 |
False |
| partitionColumnName | 指定将由分区用于并行复制的源列的名称。 如果未指定,系统会自动检测表的索引或主键并将其用作分区列。 当分区选项是 SapHanaDynamicRange 时适用。 如果使用查询来检索源数据,请在 WHERE 子句中挂接 ?AdfHanaDynamicRangePartitionCondition。 请参阅从 SAP HANA 进行并行复制部分的示例。 |
在使用 SapHanaDynamicRange 分区时为“是”。 |
| packetSize | 指定网络数据包大小 (KB),以便将数据拆分成多个块。 如果有大量的数据需要复制,则大多数情况下,提高数据包大小可以提高从 SAP HANA 读取数据的速度。 调整数据包大小时,建议进行性能测试。 | 否。 默认值为 2048 (2MB)。 |
示例:
"activities":[
{
"name": "CopyFromSAPHANA",
"type": "Copy",
"inputs": [
{
"referenceName": "<SAP HANA input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SapHanaSource",
"query": "<SQL query for SAP HANA>"
},
"sink": {
"type": "<sink type>"
}
}
}
]
如果使用 RelationalSource 类型复制源,该源仍按原样受支持,但我们建议今后使用新源。
从 SAP HANA 进行并行复制
SAP HANA 连接器提供内置的数据分区,用于从 SAP HANA 并行复制数据。 可以在复制活动的“源”表中找到数据分区选项。
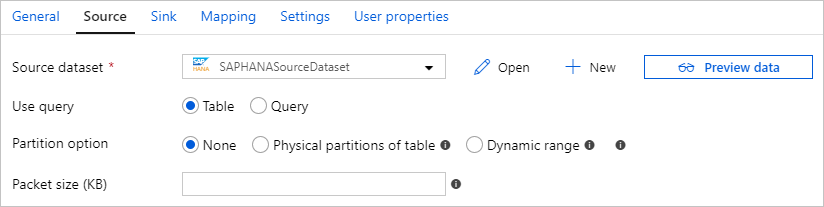
启用分区复制时,该服务将对 SAP HANA 源运行并行查询,以按分区检索数据。 可通过复制活动中的 parallelCopies 设置控制并行度。 例如,如果将 parallelCopies 设置为 4,则该服务会根据指定的分区选项和设置并行生成并运行 4 个查询,每个查询从 SAP HANA 检索一部分数据。
建议同时启用并行复制和数据分区,尤其是从 SAP HANA 引入大量数据时。 下面是适用于不同方案的建议配置。 将数据复制到基于文件的数据存储中时,建议将数据作为多个文件写入文件夹(仅指定文件夹名称),在这种情况下,性能优于写入单个文件。
| 方案 | 建议的设置 |
|---|---|
| 从大型表进行完整加载。 | 分区选项:表的物理分区。 在执行期间,该服务会自动检测指定 SAP HANA 表的物理分区类型,并选择相应的分区策略: - 范围分区:获取为表定义的分区列和分区范围,然后按范围复制数据。 - 哈希分区:使用哈希分区键作为分区列,然后根据服务所计算的范围对数据进行分区和复制。 - 轮循分区或无分区:使用主键作为分区列,然后根据服务所计算的范围对数据进行分区和复制。 |
| 使用自定义查询加载大量数据。 | 分区选项:动态范围分区。 查询: SELECT * FROM <TABLENAME> WHERE ?AdfHanaDynamicRangePartitionCondition AND <your_additional_where_clause>。分区列:指定用于应用动态范围分区的列。 在执行期间,服务首先计算指定分区列的取值范围,方法是根据并行复制设置的不同分区列值的数量将行平均分配到多个桶中,然后将 ?AdfHanaDynamicRangePartitionCondition 替换为筛选每个分区的分区列值范围,并发送到 SAP HANA。如果要使用多个列作为分区列,可以在查询中将每列的值连接为一个列,并将其指定为分区列,如 SELECT * FROM (SELECT *, CONCAT(<KeyColumn1>, <KeyColumn2>) AS PARTITIONCOLUMN FROM <TABLENAME>) WHERE ?AdfHanaDynamicRangePartitionCondition。 |
示例:使用表的物理分区进行查询
"source": {
"type": "SapHanaSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
示例:使用动态范围分区进行查询
"source": {
"type": "SapHanaSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfHanaDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "SapHanaDynamicRange",
"partitionSettings": {
"partitionColumnName": "<Partition_column_name>"
}
}
SAP HANA 的数据类型映射
从 SAP HANA 复制数据时,以下映射用于从 SAP HANA 数据类型映射到在服务内部使用的临时数据类型。 若要了解复制活动如何将源架构和数据类型映射到接收器,请参阅架构和数据类型映射。
| SAP HANA 数据类型 | 临时服务数据类型 |
|---|---|
| ALPHANUM | String |
| BIGINT | Int64 |
| BINARY | Byte[] |
| BINTEXT | String |
| BLOB | Byte[] |
| BOOL | Byte |
| CLOB | 字符串 |
| DATE | DateTime |
| DECIMAL | Decimal |
| DOUBLE | Double |
| FLOAT | Double |
| INTEGER | Int32 |
| NCLOB | String |
| NVARCHAR | String |
| real | Single |
| SECONDDATE | DateTime |
| SHORTTEXT | String |
| SMALLDECIMAL | 小数 |
| SMALLINT | Int16 |
| STGEOMETRYTYPE | Byte[] |
| STPOINTTYPE | Byte[] |
| TEXT | String |
| TIME | TimeSpan |
| TINYINT | Byte |
| VARCHAR | String |
| TIMESTAMP | DateTime |
| VARBINARY | Byte[] |
SAP HANA 接收器
目前,不支持将 SAP HANA 连接器用作接收器,你可以将通用 ODBC 连接器与 SAP HANA 驱动程序结合使用,以将数据写入 SAP HANA。
按照先决条件来设置自承载集成运行时,并首先安装 SAP HANA ODBC 驱动程序。 如以下示例所示,创建 ODBC 链接服务以连接到 SAP HANA 数据存储,然后相应地使用 ODBC 类型创建数据集和复制活动接收器。 若要了解详细信息,请参阅 ODBC 连接器一文。
{
"name": "SAPHANAViaODBCLinkedService",
"properties": {
"type": "Odbc",
"typeProperties": {
"connectionString": "Driver={HDBODBC};servernode=<HANA server>.clouddatahub-int.net:30015",
"authenticationType": "Basic",
"userName": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
查找活动属性
若要了解有关属性的详细信息,请查看 Lookup 活动。
相关内容
有关复制活动支持作为源和接收器的数据存储的列表,请参阅支持的数据存储。