Microsoft Fabric是一个支持端到端数据工作流的分析平台,包括数据引入、转换、实时流处理、分析和报告。 它提供数据工程、数据工厂、数据科学、实时智能、Data Warehouse和数据库等集成体验,这些体验通过共享计算和存储模型运行。
Fabric作为软件即服务(SaaS)平台提供,并将 OneLake 用作集中的逻辑数据湖,用于跨所有工作负荷存储和访问数据。 与 OneLake 一同,OneLake 目录为发现、探索和管理租户中的数据与分析工件提供了集中化体验。 AI 功能内置于平台中,可帮助完成数据准备、分析和开发任务,减少手动服务集成的需求,并高效分析大规模数据。
注释
- Fabric分析师一日培训(FAIAD)研讨会是免费提供的实战培训,专为使用Power BI和Fabric的分析师设计。 获取使用Fabric分析数据和生成报表的实践经验。 研讨会涵盖了使用 lakehouses、创建报表和分析Fabric环境中数据等关键概念。
- 加入新的Fabric用户面板,共享反馈并帮助塑造Fabric和Power BI。 参与产品团队的调查和一对一会话。 在
Fabric 用户组0 中了解详细信息并注册。
Fabric的功能
Microsoft Fabric提供了多种集成功能:
角色特定的工作任务:Fabric为数据工程师、数据科学家、业务分析师和数据库管理员提供不同的工作任务。 每个工作负荷都提供针对常见任务(如数据引入、转换、建模、查询和报告)优化的工具、API 和用户体验。 还可以在单个解决方案中组合它们以支持端到端方案。
OneLake(存储):所有Fabric工作负荷在 OneLake 上运行,这是一个基于Azure Data Lake Storage构建的统一逻辑数据湖。 OneLake 允许跨工作负荷共享访问数据,而无需数据移动或重复。
Copilot support: Fabric包括Copilot功能,这些功能可帮助创作查询、管道和代码、生成摘要和见解,以及加速常见的开发和分析工作流。
Microsoft 365 integration: Fabric与Microsoft 365应用程序集成,使数据能够在Excel等工具中进行分析和使用,并通过协作图面(如Microsoft Teams)进行共享。
Microsoft Foundry 集成: Fabric与 Microsoft Foundry 集成,以便对机器学习和 AI 方案(包括模型开发、部署和推理)使用预生成模型和工具。
统一的数据管理和管理: Fabric提供集中式数据发现、访问控制和治理功能,帮助组织跨工作负载一致管理数据访问、共享和合规性。
Microsoft Fabric体系结构
下图说明了如何基于软件即服务(SaaS)平台构建Microsoft Fabric,该平台在单个环境中统一多个分析体验。

关系图顶部是核心Fabric工作负载,例如数据工厂、分析、数据库、实时智能、IQ 和Power BI。 每个工作负荷都提供针对不同分析任务定制的专用功能,但所有工作负荷在同一Fabric环境中运行,并且可以共享数据和项目,而无需重复。
这些工作负载下方是Fabric平台层,该层提供跨体验一致使用的共享服务:
OneLake是用于Fabric的集中式逻辑数据湖。 所有工作负载都通过 OneLake 存储和访问数据,允许零复制访问模式,并允许数据保留在其原始位置,同时在体验中重复使用。
Copilot 提供直接嵌入到 Fabric 工作负载中的 AI 辅助,以帮助创作、探索和例行开发任务,同时遵守租户、数据和权限边界。
治理 表示集中式管理和数据管理,包括权限、敏感度标签和审核。 这些控件会自动应用,并跨Fabric组件继承。 治理由 Purview 提供支持,它内置于Fabric中。 Purview 支持的治理通过 OneLake 数据共享扩展到跨租户共享的数据,因此无论使用共享数据的位置如何,敏感度标签、访问策略和合规性控制都会保持强制实施。 Microsoft Fabric 在 OneLake 目录中集中管理和发现功能,作为一个统一的中心,帮助您查找、浏览、保护和使用所需的 Fabric 组件,并管理您拥有的数据。 可以评估治理状态、接收建议的操作,并在跨域和工作区中提高数据信任和合规性。 若要了解详细信息,请参阅什么是 OneLake 目录?
此 SaaS 基础支持端到端分析方案,例如使用数据工厂引入数据、使用工程或实时工作负荷进行处理,并在Power BI中可视化数据,而无需手动集成单独的服务或管理底层基础结构。 Fabric集中数据发现、管理和治理,内置Microsoft Purview,以在整个平台上强制实施一致的安全性和合规性。
Microsoft Fabric组件
Microsoft Fabric提供以下工作负载,每个工作负载都针对特定角色和任务进行自定义:
Power BI - Power BI使你可以连接到数据源、创建交互式图表和仪表板,以及在整个组织中共享见解。 这样,企业主就可以快速有效地访问Fabric中的所有数据,从而做出更注重数据的决策。 有关详细信息,请参阅 什么是 Power BI?
Databases - Fabric中的数据库是一个开发人员友好的事务数据库,例如 Azure SQL Database,可用于在Fabric中轻松创建操作数据库。 使用镜像功能,可以将各种系统中的数据汇集到 OneLake 中。 可以直接将现有数据资产复制到 Fabric 的 OneLake 中,包括来自 Azure SQL Database、Azure Cosmos DB、Azure Databricks、Snowflake 和 Fabric SQL 数据库的数据。 有关详细信息,请参阅 Microsoft Fabric 中的 SQL 数据库 和 Fabric 中的镜像是什么?
数据工厂 - 数据工厂提供新式数据集成体验,用于从丰富的数据源引入、准备和转换数据。 它结合了Power Query的简单性,可以使用 200 多个本机连接器连接到本地和云中的数据源。 有关详细信息,请参阅 Microsoft Fabric 中的数据工厂是什么?
Industry Solutions - Fabric提供行业特定的数据解决方案,可满足独特的行业需求和挑战,包括数据管理、分析和决策。 有关详细信息,请参阅 Microsoft Fabric 中的 Industry Solutions。
实时智能 - 实时智能分析实时到达的数据,例如,物联网传感器数据、应用程序日志或网站点击流。 它通过处理数据引入、转换、存储、建模、分析、可视化、跟踪、AI 以及实时操作,来实现从动态数据中获取见解、可视化信息并采取相应行动。 Real-Time Intelligence 中的“Real-Time hub”提供多种无代码连接器,并融合为一个组织数据目录,这些数据在 Fabric 之间受到保护、管理和集成。 有关更多信息,请参阅 Fabric 中的实时智能是什么?。
Data Engineering - Fabric数据工程为处理大型数据集提供 Apache Spark,以及用于编写和计划数据转换作业的笔记本和工具。 它使你能够创建、管理和优化基础结构,以便收集、存储、处理和分析大量数据。 Fabric Spark 与数据工厂的集成使你可以计划和协调笔记本和 Spark 作业。 有关详细信息,请参阅 Microsoft Fabric 中的数据工程是什么?
Fabric数据科学 - Fabric数据科学使你能够从Fabric生成、部署和操作机器学习模型。 它与Azure Machine Learning集成以提供内置的试验跟踪和模型注册表。 数据科学家可以使用预测来丰富组织数据,业务分析师可以将这些预测集成到其 BI 报表中,从而从描述性见解向预测见解转变。 有关详细信息,请参阅 Microsoft Fabric 中的数据科学是什么?
Fabric Data Warehouse - Fabric Data Warehouse提供行业领先的 SQL 性能和规模。 它将计算与存储分开,从而实现这两个组件的独立扩展。 此外,它还以 Delta Lake 开放格式原生存储数据。 有关详细信息,请参阅 Microsoft Fabric 中的数据仓库是什么?
Fabric IQ(预览版) - Fabric IQ(预览版)是跨数据、模型和系统统一业务语义的新工作负载。 它包括本体、计划、Fabric Graph、数据代理、操作代理和语义模型。 Fabric IQ 支持跨 Fabric 平台的一致决策、可重用指标和上下文感知自动化。 有关详细信息,请参阅 Fabric IQ(预览版)是什么?
Fabric可帮助组织和个人分析其数据,并创建报表、仪表板和机器学习模型。 它实现数据网格体系结构。 有关详细信息,请参阅 什么是数据网格?
OneLake:湖屋的统一
Microsoft Fabric平台跨企业统一 OneLake 和 Lakehouse 体系结构。
OneLake
Data Lake 是所有Fabric工作负荷的基础。 在 Fabric 中,此湖称为 OneLake。 OneLake 内置于平台中,充当所有组织数据的单个存储。
OneLake 基于 ADLS (Azure Data Lake Storage) Gen2 构建。 它提供单一的 SaaS 体验和一个面向整个租户的数据存储,为专业开发人员和普通开发者服务。 它通过消除了解复杂基础结构详细信息(如资源组、RBAC、Azure Resource Manager、冗余或区域)的需求,从而简化了用户体验。 无需Azure帐户即可使用Fabric。
OneLake 通过提供统一的存储系统来防止数据孤岛,使数据发现、共享和一致的策略实施变得容易。 有关详细信息,请参阅 什么是 OneLake?
OneLake 还支持跨租户数据共享,这样就可以跨Microsoft Entra租户边界与外部组织共享实时治理的数据集,而无需复制数据。 接收者可以直接访问共享数据,并且治理策略在源头持续强制执行。 有关详细信息,请参阅 外部数据共享。
OneLake 和 Lakehouse 数据层次结构
OneLake 的分层设计简化了组织范围的管理。 默认情况下,Fabric包括 OneLake,因此不需要预先预配。 每个租户获取一个统一的 OneLake,其中包含跨用户、区域和云的单个文件系统命名空间。 OneLake 将数据组织到容器中,以便轻松处理。 租户会映射到 OneLake 的根目录,且位于层次结构的顶层。 可以在租户中创建多个工作区(类似于文件夹)。
下图显示了Fabric如何在 OneLake 中存储数据。 每个租户可以有多个工作区,每个工作区中可以有多个湖屋。 湖屋是文件、文件夹、和表的集合,充当数据湖的数据库。 若要了解详细信息,请参阅 什么是湖屋?。
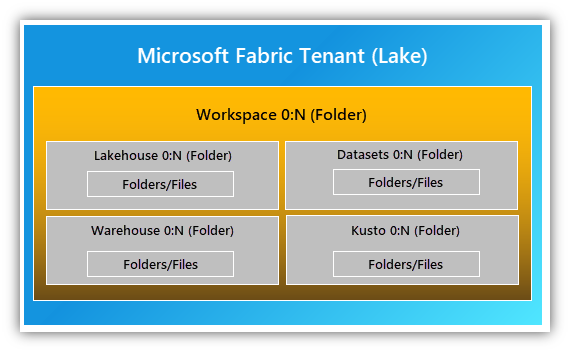
租户中的每个开发人员和业务部门都在 OneLake 中创建自己的工作区。 他们将数据引入 lakehouses,并开始处理、分析和合作处理这些数据,就像在 Microsoft Office 中使用 OneDrive 一样。
Real-Time 中心:数据流的统一
实时中心是动态数据的基础位置。 它为流式处理数据提供统一的 SaaS 体验和租户范围的逻辑环境。 它列出来自每个源的数据,允许用户发现、引入、管理和响应数据。 它包含 流 和 KQL 数据库 表。 流包括 数据流,Microsoft 源(如 Azure Event Hubs、Azure IoT Hub、Azure SQL Database (DB) 更改数据捕获 (CDC)、Azure Cosmos DB CDC、Azure Data Explorer 和 PostgreSQL DB CDC),Fabric 事件(工作区项目事件、OneLake 事件 和 作业事件)和 Azure 事件,包括 Azure Blob Storage 事件以及来自 Microsoft 365 或其他云服务的外部事件。
借助 Real-Time 中心,可以轻松地从各种源发现、引入、管理和使用动态数据,从而在一个位置协作和开发流式处理应用程序。 有关详细信息,请参阅 什么是 Real-Time 中心?
Fabric计算引擎
所有 Microsoft Fabric 计算环境都预配置了 OneLake,类似于 Office 应用程序自动使用组织的 OneDrive。 数据工程、数据仓库、数据工厂、Power BI 和实时智能等体验使用 OneLake 作为其本机存储,无需额外设置。

OneLake 允许使用 快捷方式 功能立即装载现有的 PaaS 存储帐户。 快捷方式提供对外部数据源(如 Azure Data Lake Storage、Amazon S3 和 Google 云存储)的零复制访问权限,无需 ETL 或数据迁移。 还可以为其他存储系统创建快捷方式,从而使用智能缓存分析跨云数据。这不仅降低了数据出口成本,还能使数据处理更贴近计算资源。
适用于 ISV 的 Fabric 解决方案
如果你是一家独立软件供应商(ISV),希望将解决方案与Microsoft Fabric集成,则可以根据所需的集成级别使用以下路径之一:
- Interop - 将解决方案与 OneLake Foundation 集成,并与Fabric建立基本连接和互操作性。
- 开发Fabric - 在Fabric平台的基础上构建解决方案,或将Fabric的功能无缝嵌入到现有应用程序中。 可以使用此选项轻松使用Fabric功能。
- 构建Fabric工作负荷 - 在Fabric创建自定义工作负载和体验,定制产品/服务,使其在Fabric生态系统中发挥最大效果。
ISV 还可以使用 OneLake 快捷方式和治理的跨租户数据共享安全地访问和集成跨租户边界的客户数据,而无需复制数据。
有关详细信息,请参阅 Fabric ISV 合作伙伴生态系统。