你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
本指南介绍如何在 Azure SQL 数据库中获取现有的规范化数据库架构,并将其转换为 Azure Cosmos DB 非规范化架构以加载到 Azure Cosmos DB。
SQL 架构通常使用第三种普通窗体进行建模,从而生成规范化架构,这些架构提供高度的数据完整性和较少的重复数据值。 查询可跨表将实体联接在一起以进行读取。 Azure Cosmos DB 经过优化,可实现超快速事物并在集合或容器内通过非规范化架构对文档中自包含的数据进行查询。
借助 Azure 数据工厂,我们将构建一个使用单个映射数据流从两个 Azure SQL 数据库规范化表中读取数据的管道,这两个表包含主键和外键作为实体关系。 数据工厂将使用数据流 Spark 引擎将这些表加入单个流,将联接的行收集到数组中,并生成单独的已清理文档以插入新的 Azure Cosmos DB 容器中。
本指南将动态构建一个名为“orders”的新容器,该容器将使用标准 SQL Server Adventure Works 示例数据库中的 SalesOrderHeader 和 SalesOrderDetail 表。 这些表表示由 SalesOrderID 联接的销售事务。 每个唯一的详细信息记录都具有自己的主键 SalesOrderDetailID。 标头与详细信息之间的关系是 1:M。 我们通过 ADF 联接 SalesOrderID,然后将每个相关的详细记录滚动到名为“detail”的数组中。
本指南的典型 SQL 查询是:
SELECT
o.SalesOrderID,
o.OrderDate,
o.Status,
o.ShipDate,
o.SalesOrderNumber,
o.ShipMethod,
o.SubTotal,
(select SalesOrderDetailID, UnitPrice, OrderQty from SalesLT.SalesOrderDetail od where od.SalesOrderID = o.SalesOrderID for json auto) as OrderDetails
FROM SalesLT.SalesOrderHeader o;
生成的 Azure Cosmos DB 容器将内部查询嵌入到单个文档中,如下所示:

创建管道
选择“+新建管道”以创建新管道。
添加数据流活动
在数据流活动中,选择“新建映射数据流”。
构造此数据流图:
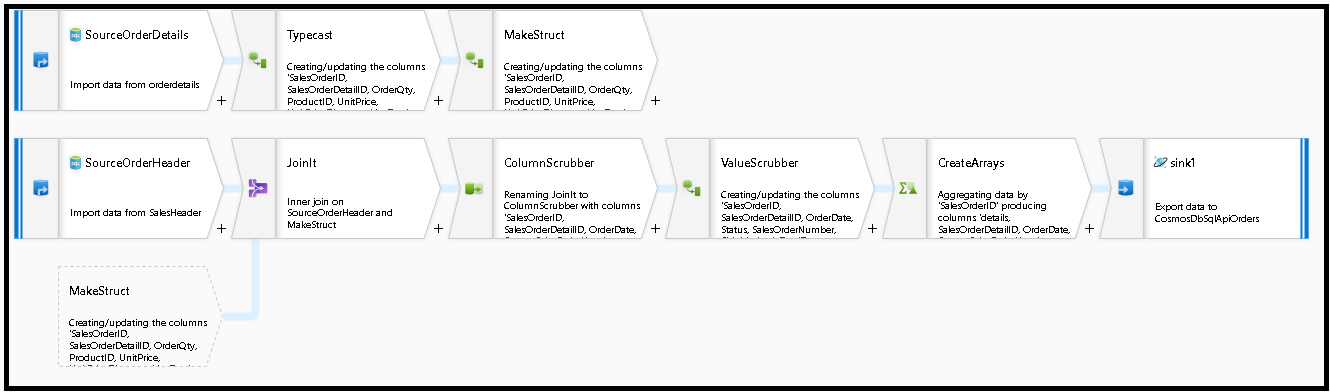
定义“SourceOrderDetails”的源。 对于数据集,请新建一个指向
SalesOrderDetail表的 Azure SQL 数据库数据集。定义“SourceOrderHeader”的源。 对于数据集,请新建一个指向
SalesOrderHeader表的 Azure SQL 数据库数据集。在顶部的源中,在“SourceOrderDetails”之后添加派生列转换。 调用新转换“TypeCast”。 需要将
UnitPrice列舍入,并将其强制转换为 Azure Cosmos DB 的 double 数据类型。 将公式设置为:toDouble(round(UnitPrice,2))。添加另一个派生列并将其称为“MakeStruct”。 我们在此处创建一个层次结构来保存详细信息表中的值。 请记住,详细信息与标头的关系是
M:1。 将新结构命名为orderdetailsstruct并以这种方式创建层次结构,将每个子列设置为传入列名: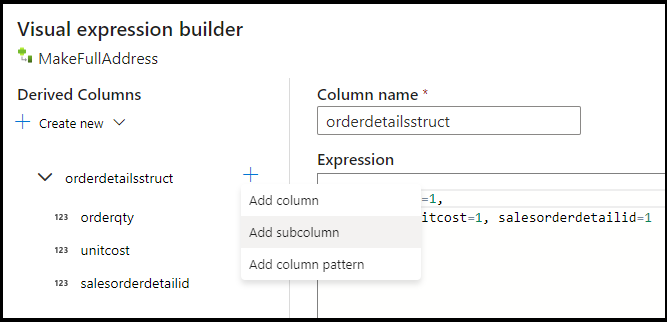
接下来转到销售标头源。 添加联接转换。 对于右侧,选择“MakeStruct”。 将其设置为“内联”,然后在联接条件两侧均选择
SalesOrderID。在你添加的新联接中选择“数据预览”选项卡,这样便可查看目前结果。 应该会看到所有与详细信息行联接的标头行。 这是从
SalesOrderID形成的联接结果。 接下来,我们将公共行中的详细信息合并到详细信息结构中并聚合公共行。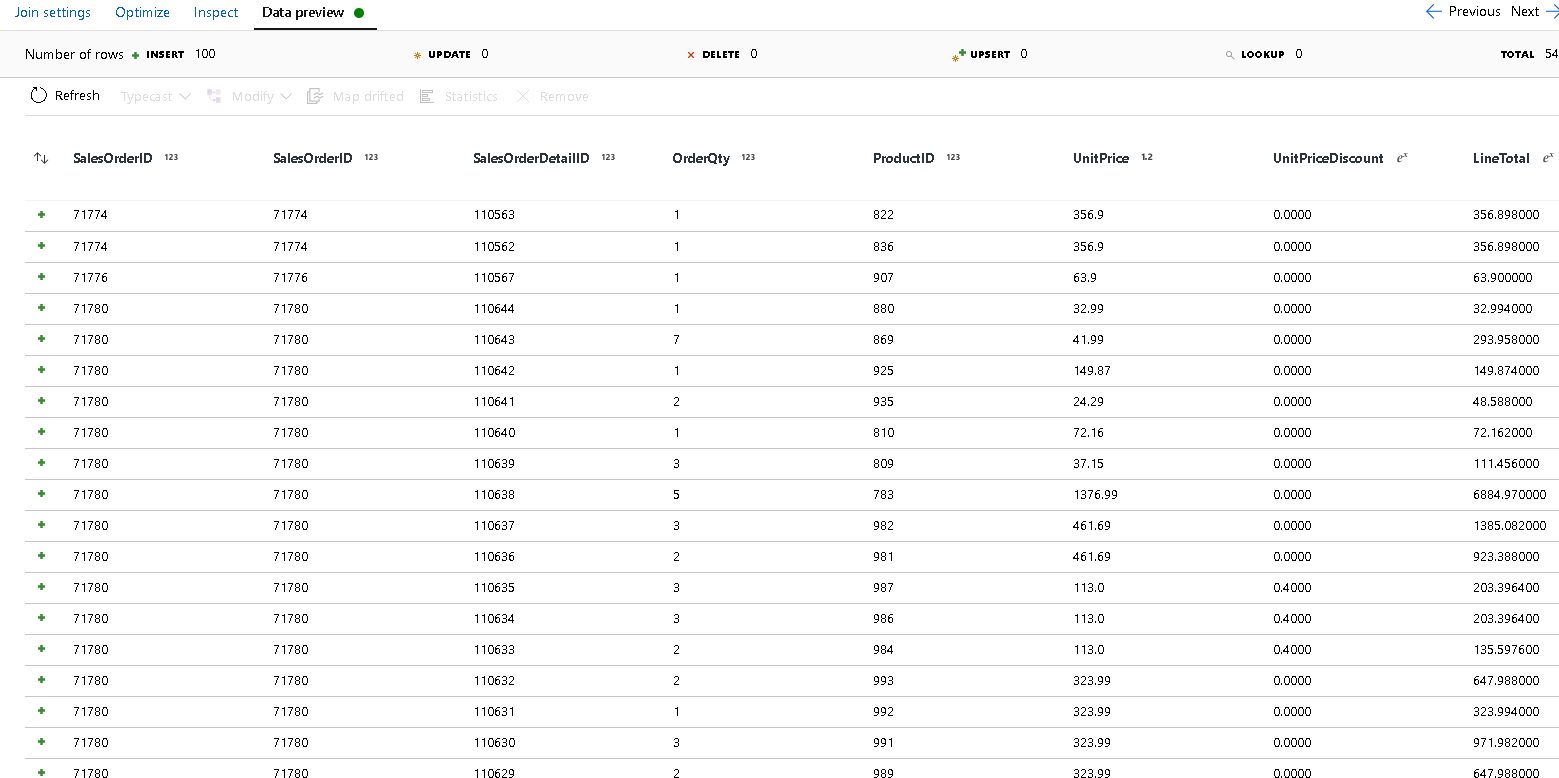
首先需要删除不需要的列并确保数据值与 Azure Cosmos DB 数据类型匹配,然后才能创建数组来使这些行非规范化。
接下来添加一个选择转换,并按如下所示设置字段映射:
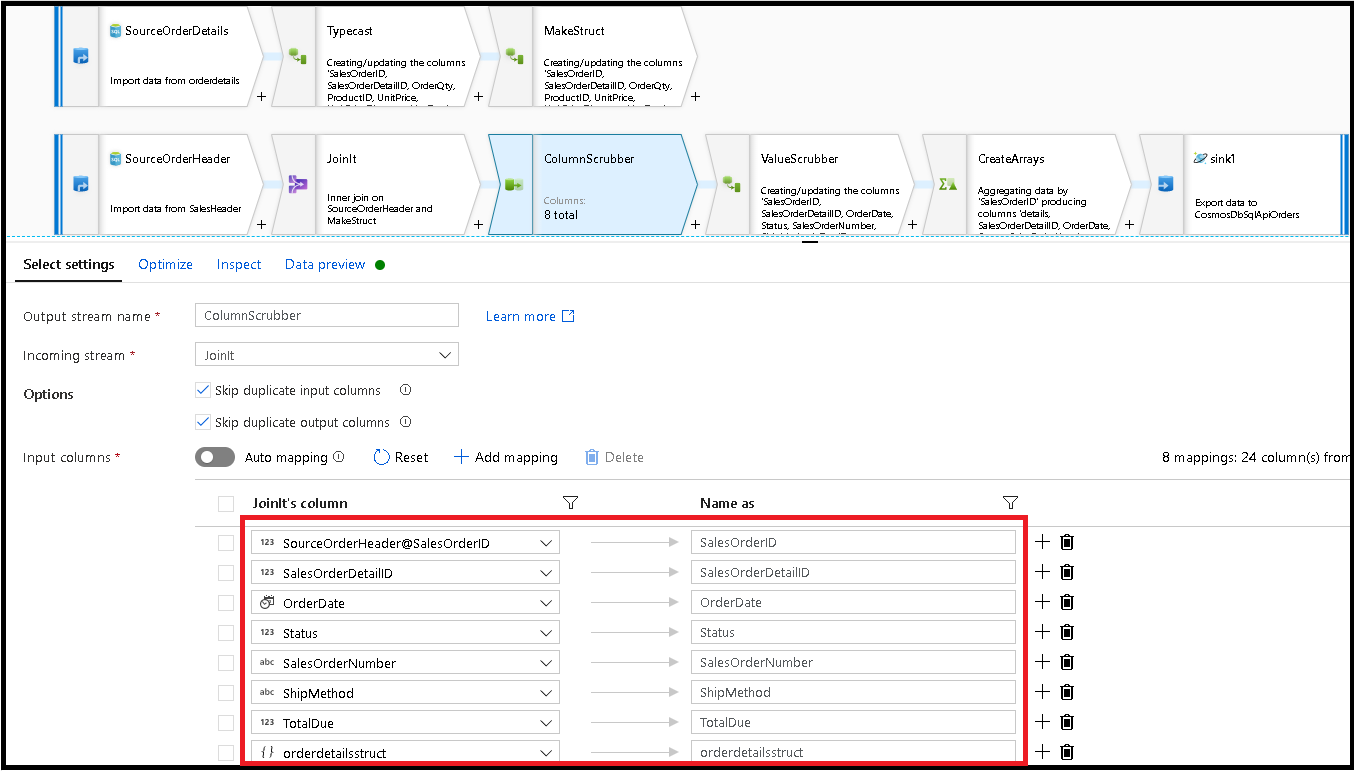
接下来,再次强制转换货币列,这一次转换为
TotalDue。 与上面的步骤 7 类似,将公式设置为:toDouble(round(TotalDue,2))。在这里,我们按常用键
SalesOrderID分组来使行非规范化。 添加聚合转换,并将“分组依据”设置为SalesOrderID。在聚合公式中,添加一个名为“details”的新列,并使用此公式来收集之前创建的
orderdetailsstruct结构中的值:collect(orderdetailsstruct)。聚合转换将仅输出属于聚合或分组依据公式的列。 因从,我们还需要包含销售标头中的列。 为此,请在同一聚合转换中添加列模式。 此模式包括输出中的所有其他列,不包括下面列出的列(OrderQty、UnitPrice、SalesOrderID):
instr(name,'OrderQty')==0&&instr(name,'UnitPrice')==0&&instr(name,'SalesOrderID')==0
在其他属性中使用“this”语法 ($$),以便我们维护相同的列名并使用
first()函数作为聚合。 这会告诉 ADF 保留找到的第一个匹配值: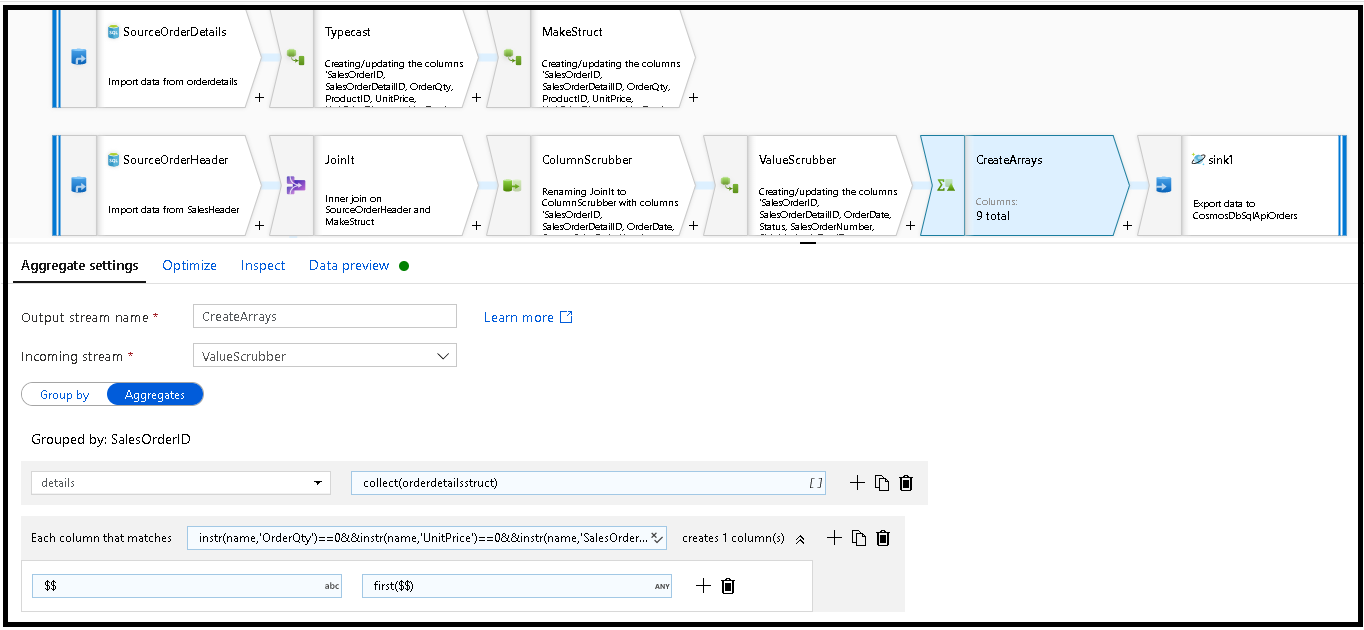
现在可通过添加接收器转换来完成迁移流。 选择数据集旁边的“新建”,然后添加指向 Azure Cosmos DB 数据库的 Azure Cosmos DB 数据集。 对于该集合,我们将其称为“orders”,因为它将会动态创建,因此不包含任何架构和文档。
在“接收器设置”中,将分区键设置为
/SalesOrderID并将集合操作设置为“重新创建”。 请确保“映射”选项卡如下所示: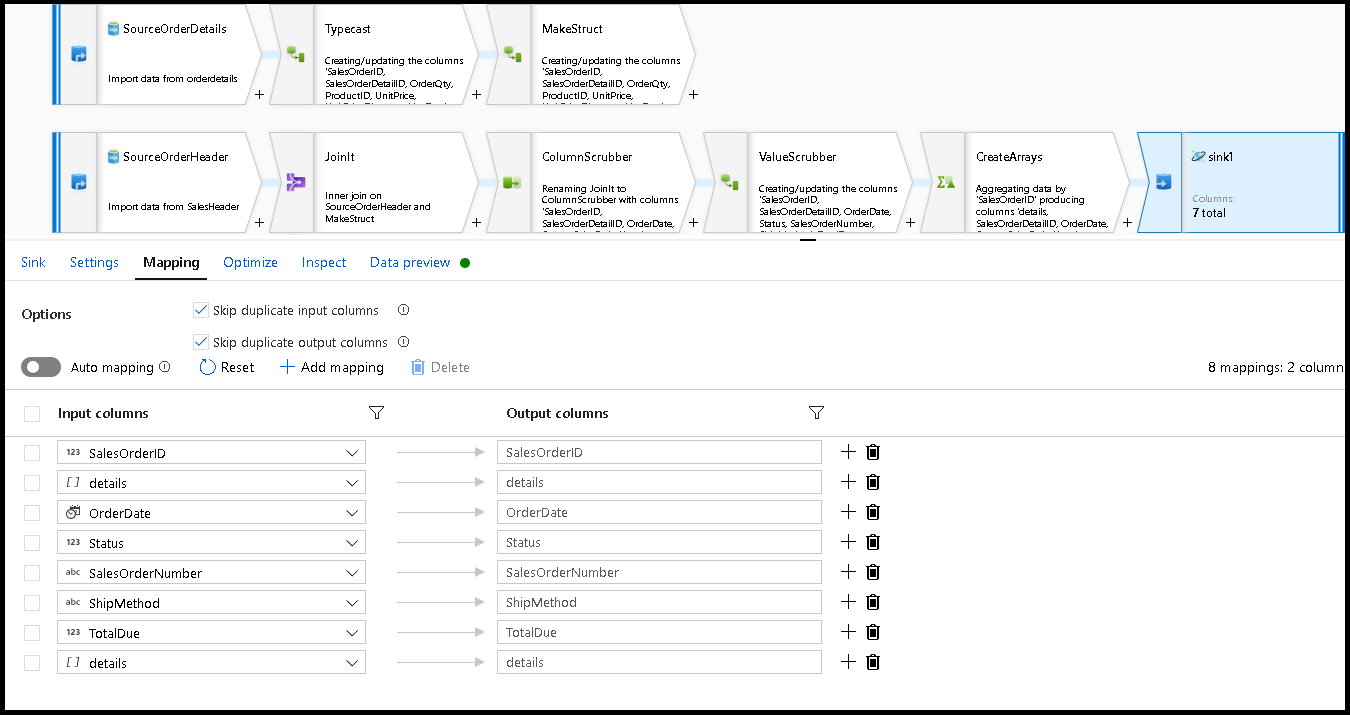
选择“数据预览”以确保你看到以下 32 行设置为以新文档形式插入你的新容器中:
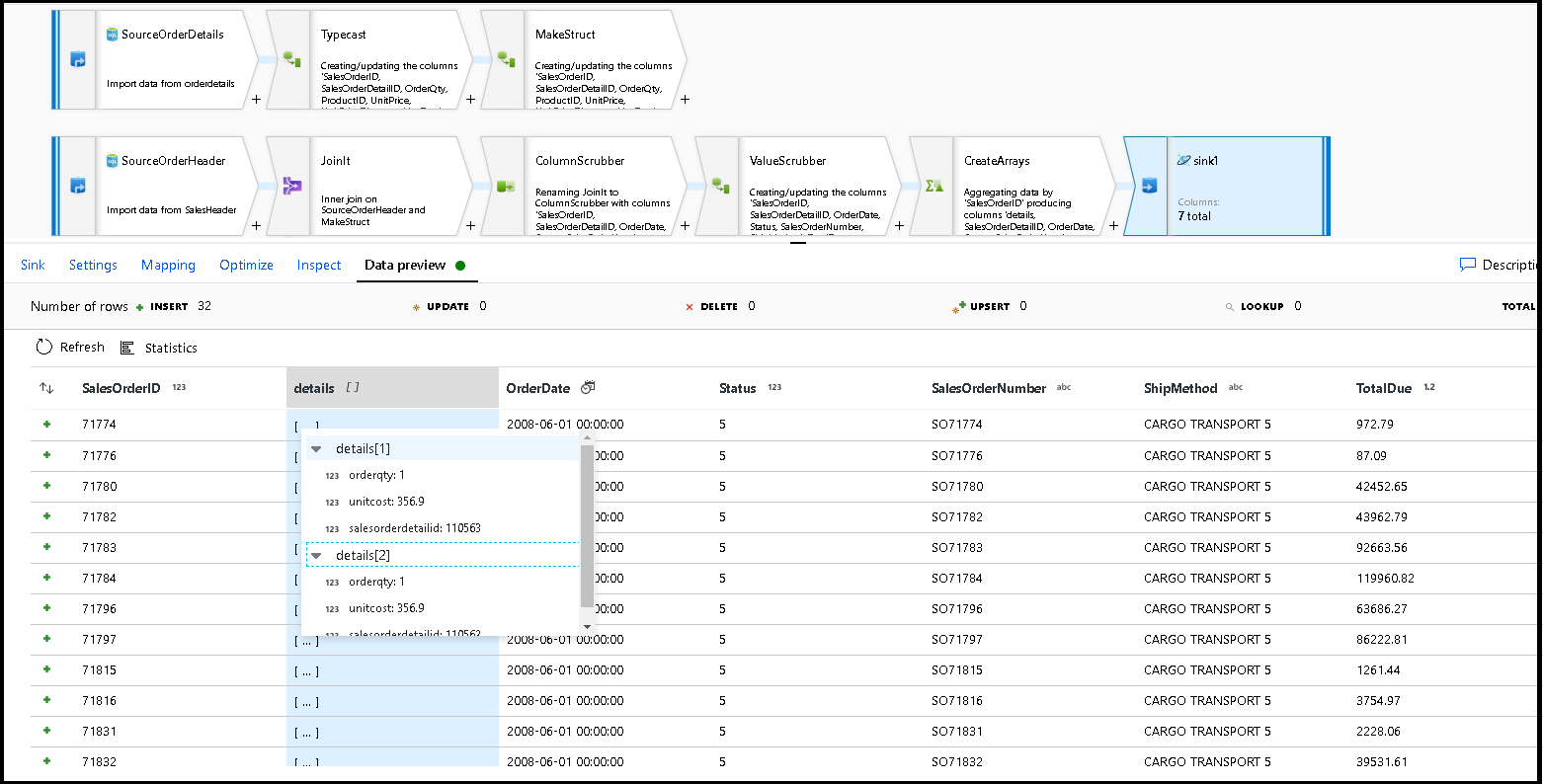
如果一切正常,你现在可以创建新的管道,将此数据流活动添加到该管道并执行它。 可从调试或触发运行执行。 几分钟后,Azure Cosmos DB 数据库中应该有一个名为“orders”的新非规范化容器。
相关内容
- 使用映射数据流转换来生成数据流逻辑的其余部分。
- 下载本教程中已完成的管道模板,并将该模板导入到工厂。