你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
提示
正在寻找一种简单的移动数据的方法? Microsoft Fabric 中的复制作业提供了一种简单、可缩放的方式来加载数据,而无需生成管道。 了解如何创建一个复制作业。
在本教程中,我们将使用 Azure 门户创建数据工厂。 然后,使用“复制数据”工具创建一个管道,以便将数据从 Azure Blob 存储复制到 SQL 数据库。
注意
如果对 Azure 数据工厂不熟悉,请参阅 Azure 数据工厂简介。
将在本教程中执行以下步骤:
- 创建数据工厂。
- 使用“复制数据”工具创建管道。
- 监视管道和活动运行。
Prerequisites
- Azure 订阅:如果还没有 Azure 订阅,可以在开始前创建一个免费帐户。
- Azure 存储帐户:使用 Blob 存储作为源数据存储。 如果没有 Azure 存储帐户,请参阅创建存储帐户中的说明。
- Azure SQL 数据库:使用 SQL 数据库作为接收器数据存储。 如果没有 SQL 数据库,请参阅创建 SQL 数据库中的说明。
准备 SQL 数据库
允许 Azure 服务访问 Azure SQL 数据库的逻辑 SQL Server。
验证是否为运行 SQL 数据库的服务器启用了“允许 Azure 服务和资源访问此服务器”。 通过此设置,数据工厂可将数据写入数据库实例。 若要验证并启用此设置,请转到逻辑 SQL 服务器 >“安全性”>“防火墙和虚拟网络”> 将“允许 Azure 服务和资源访问此服务器”选项设置为“打开”。
注意
“允许 Azure 服务和资源访问此服务器”的选项允许从任何 Azure 资源(而不仅仅是订阅中的资源)对 SQL Server 进行网络访问。 它可能并不适合所有环境,但适用于此有限教程。 有关详细信息,请参阅 Azure SQL Server 防火墙规则。 可以改为使用专用终结点连接到 Azure PaaS 服务,而无需使用公共 IP。
创建 blob 和 SQL 表
执行以下步骤,准备本教程所需的 Blob 存储和 SQL 数据库。
创建源 blob
启动记事本。 复制以下文本,并在磁盘上将其保存在名为 inputEmp.txt 的文件中:
FirstName|LastName John|Doe Jane|Doe创建名为 adfv2tutorial 的容器,然后将 inputEmp.txt 文件上传到该容器中。 可以使用 Azure 门户或各种工具(如 Azure 存储资源管理器)来执行这些任务。
创建接收器 SQL 表
使用以下 SQL 脚本在 SQL 数据库中创建名为
dbo.emp的表:CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO CREATE CLUSTERED INDEX IX_emp_ID ON dbo.emp (ID);
创建数据工厂
在顶部菜单中,选择“ 创建资源>分析>数据工厂 :
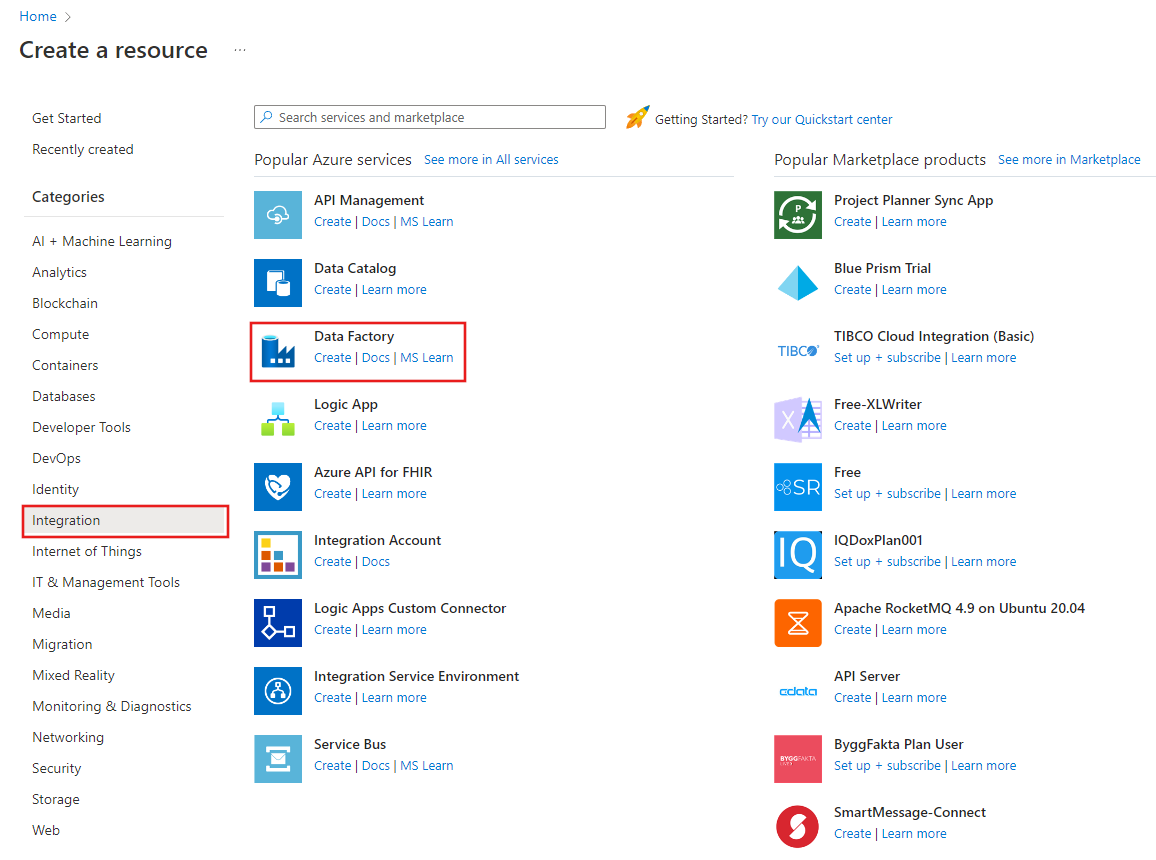
在“新建数据工厂”页的“名称”下输入 ADFTutorialDataFactory。
数据工厂的名称必须全局唯一。 可能会收到以下错误消息:
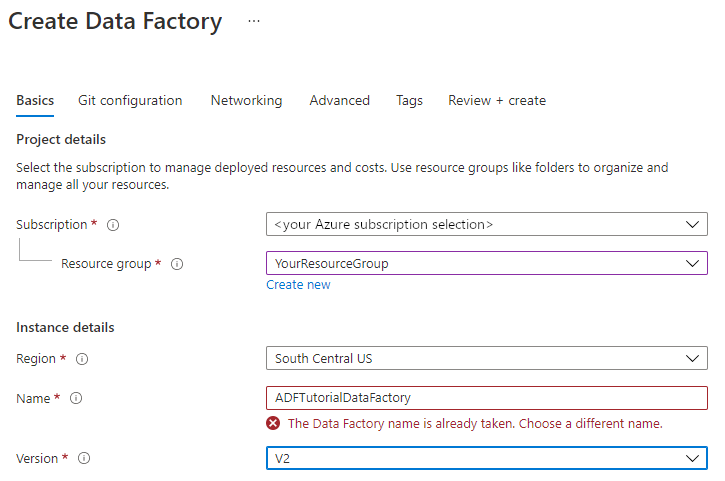
如果收到有关名称值的错误消息,请为数据工厂输入另一名称。 例如,使用名称 yournameADFTutorialDataFactory。 有关数据工厂项目的命名规则,请参阅数据工厂命名规则。
选择要在其中创建新数据工厂的 Azure 订阅。
对于“资源组”,请执行以下步骤之一:
a。 选择“使用现有资源组”,并从下拉列表选择现有的资源组。
b. 选择“新建”,并输入资源组的名称。
若要了解资源组,请参阅使用资源组管理 Azure 资源。
在“版本”下选择“V2”作为版本。
在“位置”下选择数据工厂的位置。 下拉列表中仅显示支持的位置。 数据工厂使用的数据存储(例如,Azure 存储和 SQL 数据库)和计算资源(例如,Azure HDInsight)可以位于其他位置和区域。
选择“创建”。
创建完以后,会显示“数据工厂”主页。
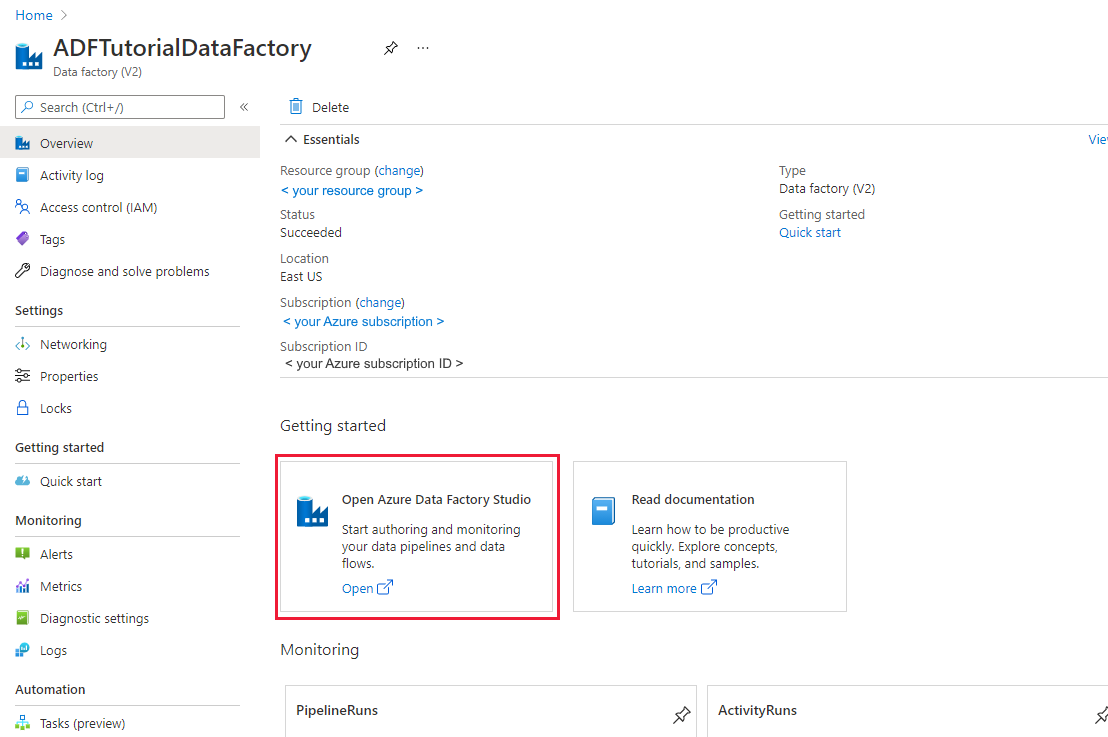
若要在单独的标签页中启动 Azure 数据工厂用户界面 (UI),请在“打开 Azure 数据工厂工作室”磁贴上选择“打开”。
使用“复制数据”工具创建管道
在 Azure 数据工厂的主页上,选择“引入”磁贴来启动“复制数据”工具。
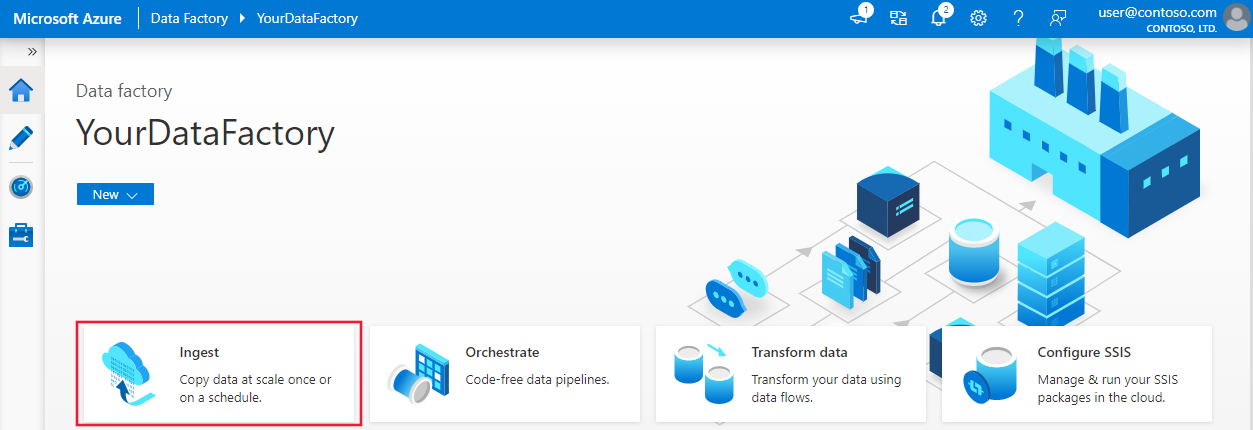
在“复制数据”工具的“属性”页上,选择“任务类型”下的“内置复制任务”,然后选择“下一步”。
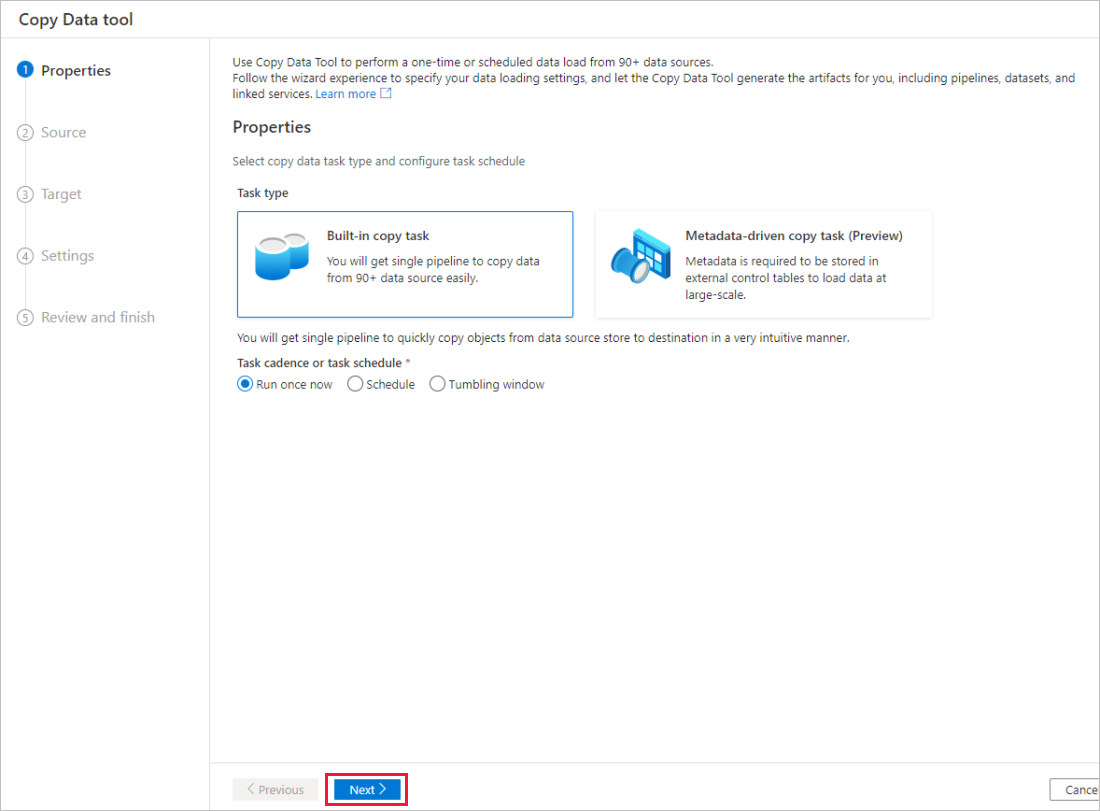
在“源数据存储”页上,完成以下步骤:
a。 选择“+ 创建新连接”添加一个连接。
b. 从库中选择“Azure Blob 存储”,然后选择“继续”。
c. 在“新建连接(Azure Blob 存储)”页上,从“Azure 订阅”列表中选择 Azure 订阅,然后从“存储帐户名称”列表中选择存储帐户。 测试连接,然后选择“创建”。
d. 在“连接”块中选择新创建的链接服务作为源。
e. 在“文件或文件夹”部分中,选择“浏览”导航到 adfv2tutorial 文件夹,选择 inputEmp.txt 文件,然后选择“确定”。
f。 选择“下一步”转到下一步骤。
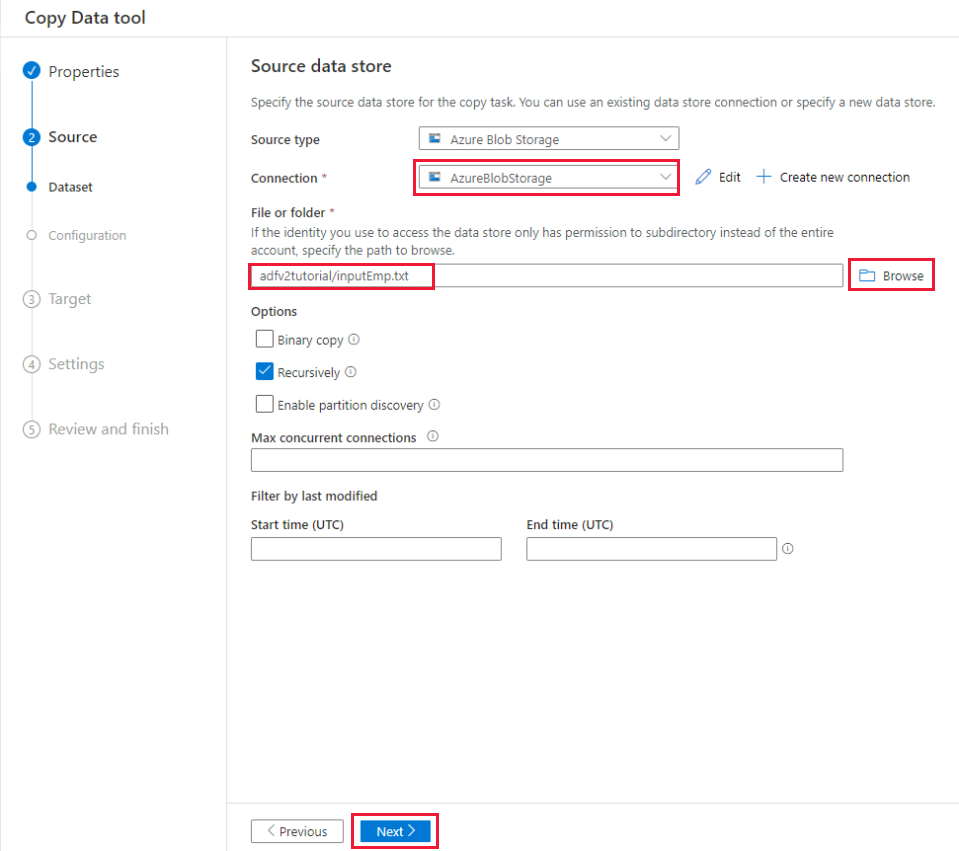
在“文件格式设置”页面上,选中“第一行作为标题”复选框。 请注意,该工具会自动检测列和行分隔符,可以通过选择此页面上的“预览数据”按钮来预览数据和查看输入数据的架构。 然后,选择“下一步”。
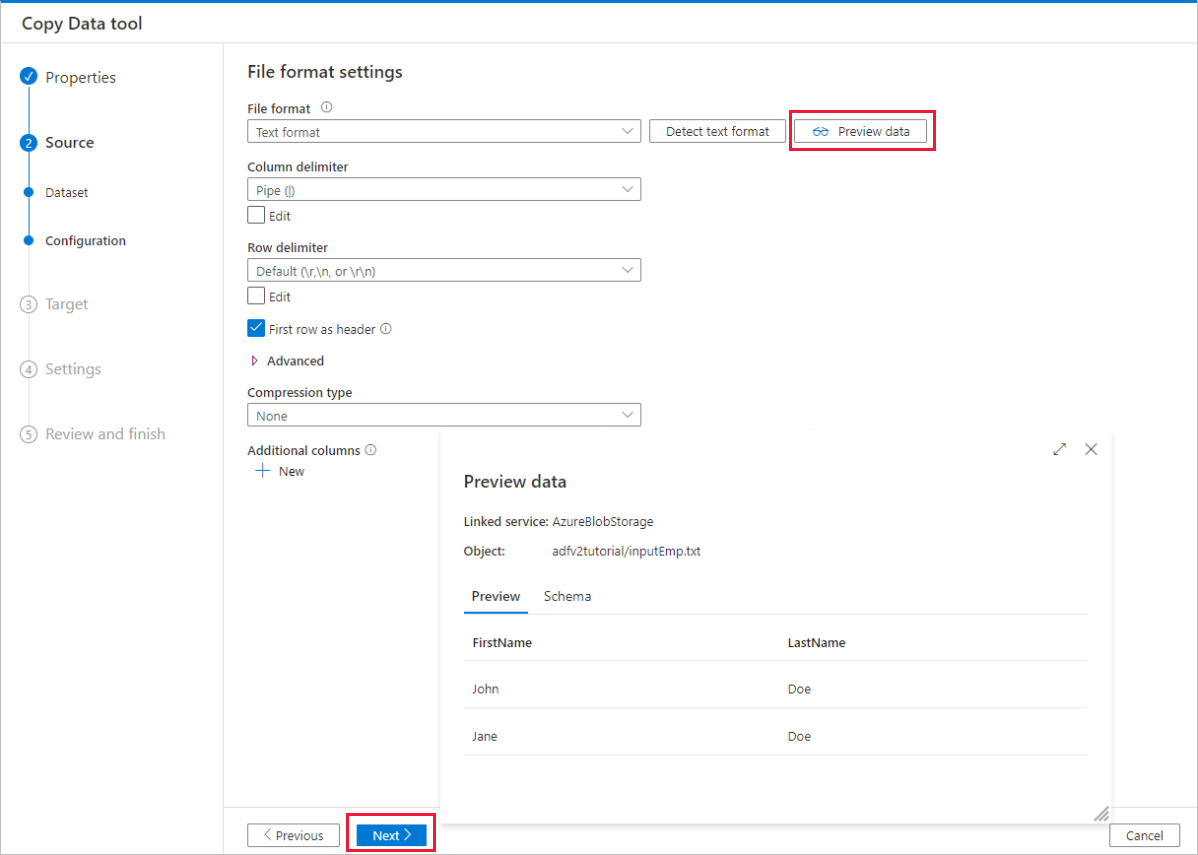
在“目标数据存储”页上,完成以下步骤:
a。 选择“+ 创建新连接”添加一个连接。
b. 从库中选择“Azure SQL 数据库”,然后选择“继续”。
c. 在“新建连接(Azure SQL 数据库)”页中,从下拉列表中选择 Azure 订阅、服务器名称和数据库名称。 然后在“身份验证类型”下选择“SQL 身份验证”,指定用户名和密码。 测试连接并选择“创建”。
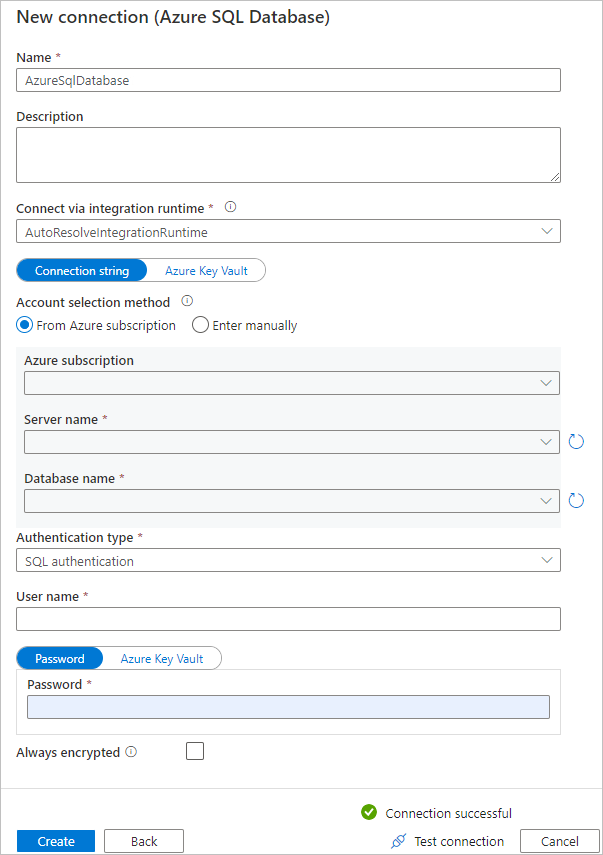
d. 选择新创建的链接服务作为接收器,然后选择“下一步”。
在“目标数据存储”页中,选择“使用现有表”并选择 表
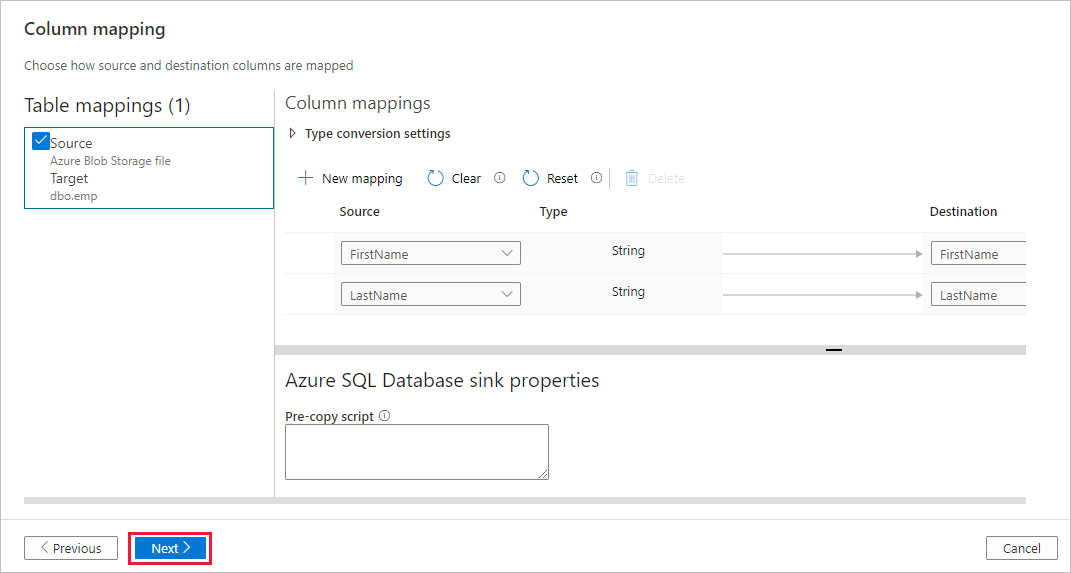
dbo.emp。 然后,选择“下一步”。在“列映射”页中,请注意,输入文件中的第二个和第三个列已映射到 emp 表的 FirstName 和 LastName 列。 请调整映射,确保没有错误,然后选择“下一步”。
在“设置”页的“任务名称”下,输入 CopyFromBlobToSqlPipeline,然后选择“下一步”。
在“摘要”页中检查设置,然后选择“下一步”。
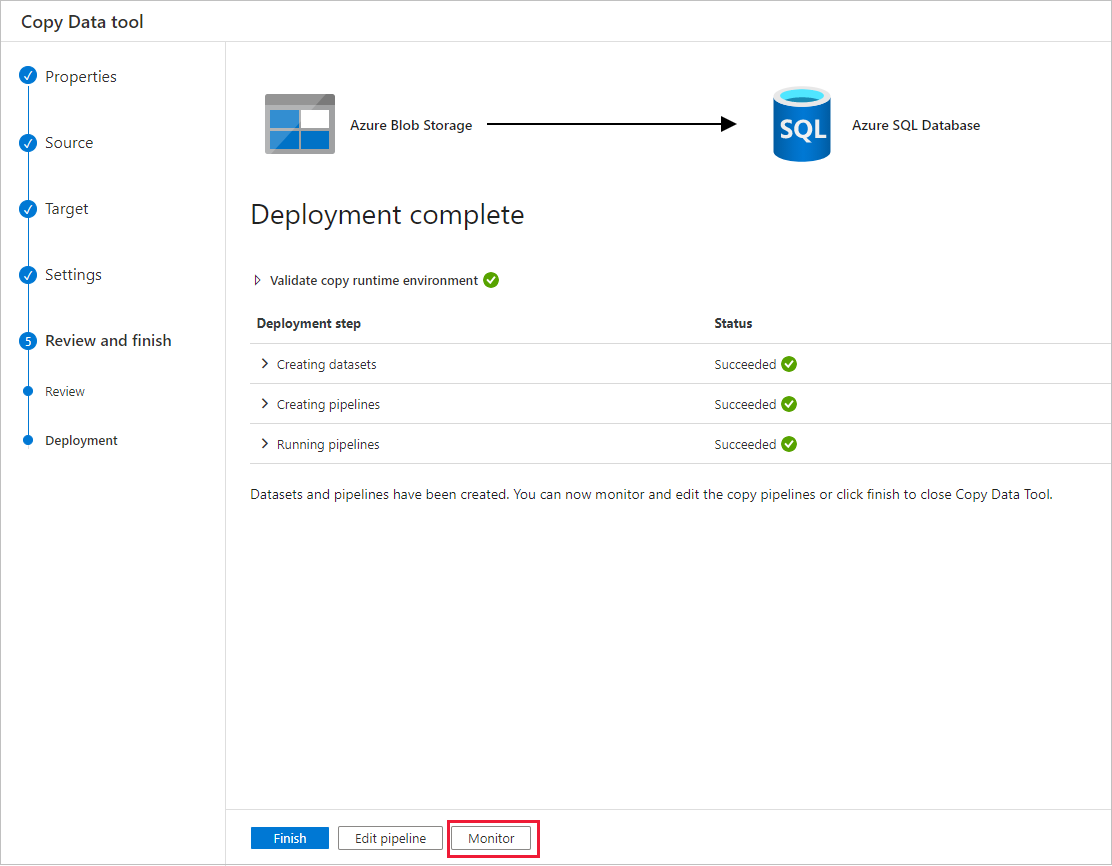
在“部署”页中,选择“监视”以监视管道(任务)。
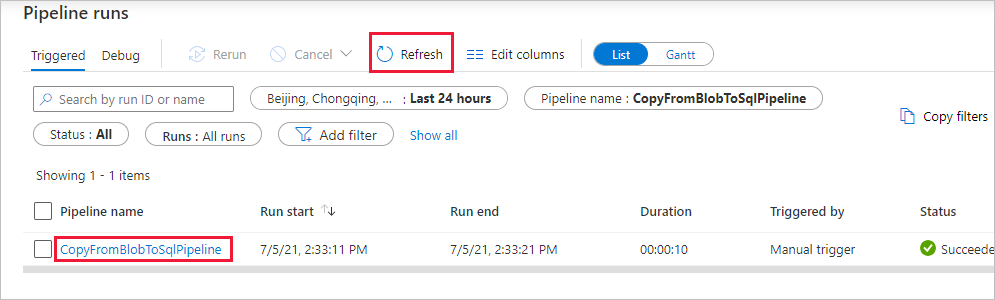
在“管道运行”页上,选择“刷新”来刷新列表。 选择“管道名称”下的链接,查看活动运行详细信息或重新运行管道。
在“活动运行”页上,选择“活动名称”列下的“详细信息”链接(眼镜图标),以获取有关复制操作的更多详细信息。 要返回到“管道运行”视图,请选择痕迹导航菜单中的“所有管道运行”链接。 若要刷新视图,请选择“刷新”。
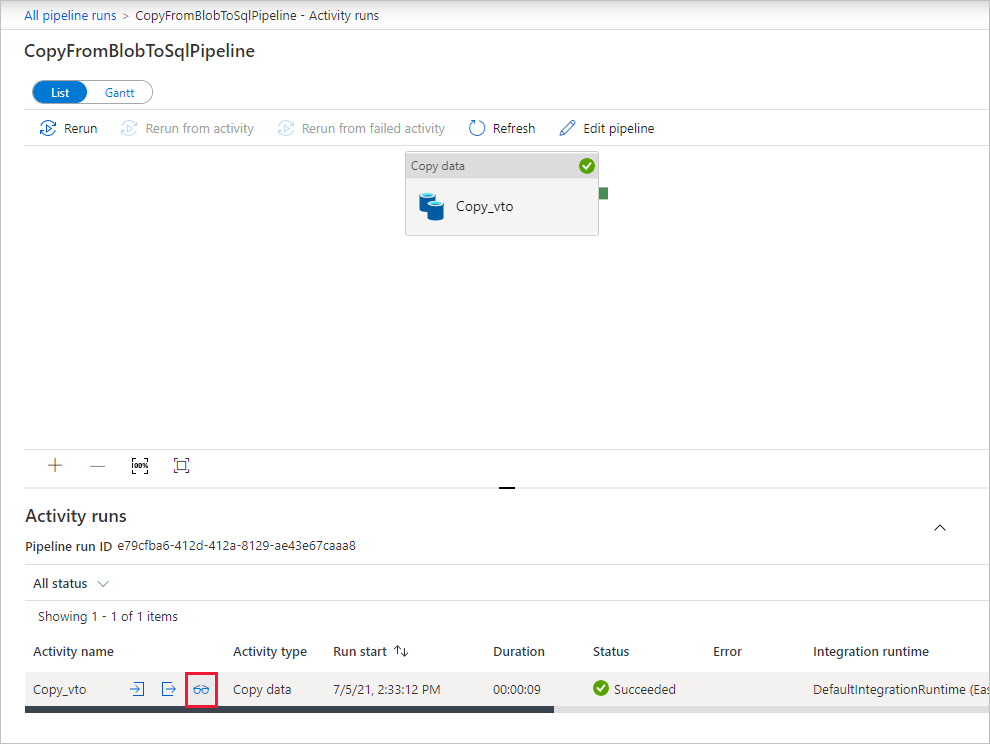
验证数据是否已插入到 SQL 数据库中的 dbo.emp 表。
选择左侧的“创作”选项卡切换到编辑器模式。 可以使用编辑器来更新通过该工具创建的链接服务、数据集和管道。 有关在数据工厂 UI 中编辑这些实体的详细信息,请参阅本教程的 Azure 门户版本。
相关内容
此示例中的管道将数据从 Blob 存储复制到 SQL 数据库。 你已了解如何执行以下操作:
- 创建数据工厂。
- 使用“复制数据”工具创建管道。
- 监视管道和活动运行。
若要了解如何将数据从本地复制到云,请转到以下教程: