使用 Azure 门户创建包含 Azure Data Lake Storage Gen1 的 HDInsight 群集
了解如何通过 Azure 门户创建将 Azure Data Lake Storage Gen1 用作默认存储或附加存储的 HDInsight 群集。 即使附加存储只是 HDInsight 群集的可选选项,也建议你将业务数据存储在附加存储帐户中。
先决条件
在开始之前,请确保满足以下要求:
- Azure 订阅。 转到获取 Azure 免费试用版。
- Azure Data Lake Storage Gen1 帐户。 请遵循通过 Azure 门户开始使用 Azure Data Lake Storage Gen1 中的说明进行操作。 还必须在该帐户上创建根文件夹。 本文使用名为“/clusters”的根文件夹。
- Microsoft Entra服务主体。 本操作指南提供了有关如何在 Microsoft Entra ID 中创建服务主体的说明。 但是,若要创建服务主体,你必须是Microsoft Entra管理员。 如果你是管理员,则可以跳过此先决条件,继续操作。
注意
仅当是Microsoft Entra管理员时,才能创建服务主体。 Microsoft Entra管理员必须先创建服务主体,然后才能使用 Data Lake Storage Gen1 创建 HDInsight 群集。 此外,必须根据使用证书创建服务主体中所述,使用证书创建服务主体。
创建 HDInsight 群集
本部分创建使用 Data Lake Storage Gen1 作为默认存储或附加存储的 HDInsight 群集。 本文仅重点介绍配置 Data Lake Storage Gen1 的部分过程。 有关创建群集的一般信息和过程,请参阅在 HDInsight 中创建 Hadoop 群集。
创建使用 Data Lake Storage Gen1 作为默认存储的群集
若要创建使用 Data Lake Storage Gen1 作为默认存储帐户的 HDInsight 群集,请执行以下操作:
登录 Azure 门户。
有关创建 HDInsight 群集的一般信息,请遵循创建群集。
在“存储”边栏选项卡的“主存储类型”下,选择“Azure Data Lake Storage Gen1”,然后输入以下信息:
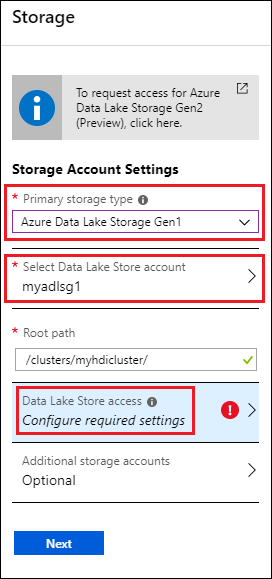
- 选择 Data Lake Store 帐户:选择一个现有的 Data Lake Storage Gen1 帐户。 必须具有现有的 Data Lake Storage Gen1 帐户。 请参阅先决条件。
- 根路径:输入群集特定文件的存储路径。 在屏幕截图中,它是 /clusters/myhdiadlcluster/,其中,/clusters 文件夹是必须存在的,myhdicluster 文件夹则由门户创建。 myhdicluster 是群集名称。
- Data Lake Store 访问:配置 Data Lake Storage Gen1 帐户和 HDInsight 群集之间的访问。 有关说明,请参阅配置 Data Lake Storage Gen1 访问。
- 附加存储帐户:添加 Azure 存储帐户作为群集的附加存储帐户。 添加额外的 Data Lake Storage Gen1 帐户后,为群集提供对更多 Data Lake Storage Gen1 帐户中数据的权限,并将某个 Data Lake Storage Gen1 帐户配置为主存储类型。 请参阅配置 Data Lake Storage Gen1 访问。
在“Data Lake Store 访问”中单击“选择”,并根据在 HDInsight 中创建 Hadoop 群集中所述继续创建群集。
创建使用 Data Lake Storage Gen1 作为额外存储的群集
以下说明会创建一个 HDInsight 群集,该群集使用 Azure Blob 存储帐户作为默认存储,使用包含 Data Lake Storage Gen1 的存储帐户作为附加存储。
若要创建使用 Data Lake Storage Gen1 作为附加存储帐户的 HDInsight 群集,请执行以下操作:
登录 Azure 门户。
有关创建 HDInsight 群集的一般信息,请遵循创建群集。
在“存储”边栏选项卡的“主存储类型”下,选择“Azure 存储”,然后输入以下信息:
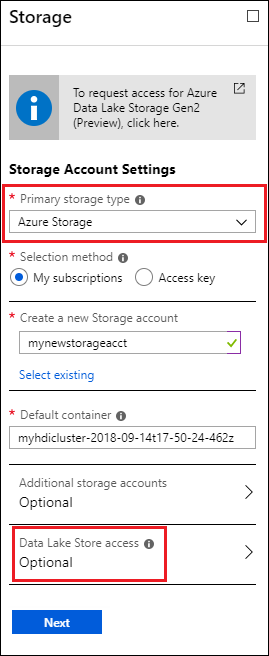
选择方法 - 若要指定属于 Azure 订阅的存储帐户,请选择“我的订阅”,然后选择存储帐户。 要指定不属于 Azure 订阅的存储帐户,请选择“访问密钥”,并提供该外部存储帐户的信息。
默认容器 - 使用默认值或指定自己的名称。
附加存储帐户 - 添加更多 Azure 存储帐户作为附加存储。
Data Lake Store 访问 - 配置 Data Lake Storage Gen1 帐户和 HDInsight 群集之间的访问。 有关说明,请参阅配置 Data Lake Storage Gen1 访问。
配置 Data Lake Storage Gen1 访问
在本部分中,将使用Microsoft Entra服务主体配置从 HDInsight 群集Data Lake Storage Gen1访问。
指定服务主体
在 Azure 门户中,可以使用现有的服务主体,或创建一个新的服务主体。
若要从 Azure 门户创建服务主体,请执行以下操作:
- 请参阅使用 Microsoft Entra ID 创建服务主体和证书。
若要从 Azure 门户使用现有服务主体,请执行以下操作:
服务主体应当拥有存储帐户的所有者权限。 请参阅将服务主体的权限设置为存储帐户的所有者。
选择“Data Lake Store 访问”。
在“Data Lake Storage Gen1 访问”边栏选项卡中,选择“使用现有项” 。
选择“服务主体”,然后选择一个服务主体。
上传与所选服务主体关联的证书(.pfx 文件),然后输入证书密码。
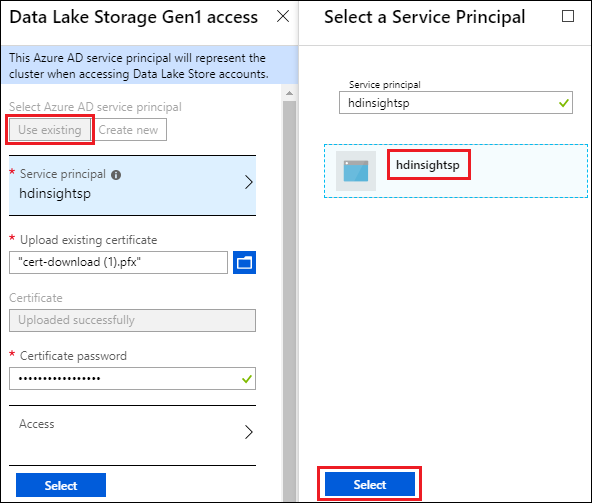
选择“访问权限”以配置文件夹访问权限。 请参阅配置文件权限。
将服务主体的权限设置为存储帐户的所有者
- 在存储帐户的“访问控制(IAM)”边栏选项卡上,单击“添加角色分配”。
- 在“添加角色分配”边栏选项卡上,选择“所有者”作为角色,然后选择 SPN并单击“保存”。
配置文件权限
配置根据帐户是用作默认存储帐户还是附加存储帐户而有所不同:
用作默认存储
- Data Lake Storage Gen1 帐户根级别的权限
- HDInsight 群集存储根级别的权限。 例如,本教程前面使用的 /clusters 文件夹。
用作附加存储
- 需要文件访问权限的文件夹上的权限。
若要在具有 Data Lake Storage Gen1 的存储帐户的根级别分配权限,请执行以下操作:
在“Data Lake Storage Gen1 访问”边栏选项卡中,选择“访问权限” 。 随即打开“选择文件权限”边栏选项卡。 它会列出你的订阅中的所有存储帐户。
将鼠标指针悬停(不要单击)在具有 Data Lake Storage Gen1 的帐户的名称上,使复选框可见,然后选中复选框。
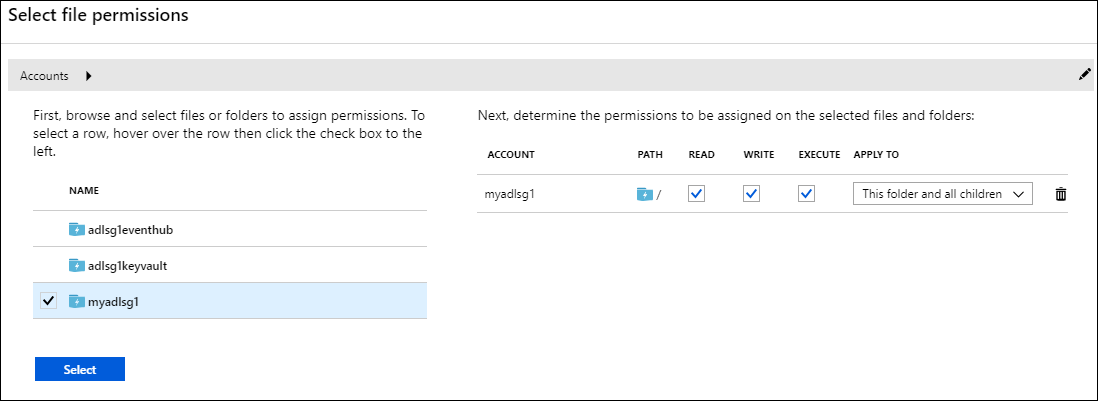
“读取”、“写入”和“执行”默认全部选中。
单击页面底部的“选择”。
选择“运行”来分配权限。
选择“完成”。
若要在 HDInsight 群集根级别分配权限,请执行以下操作:
- 在“Data Lake Storage Gen1 访问”边栏选项卡中,选择“访问权限” 。 随即打开“选择文件权限”边栏选项卡。 它将列出你的订阅中具有 Data Lake Storage Gen1 的所有存储帐户。
- 从“选择文件权限”边栏选项卡中,选择具有 Data Lake Storage Gen1 的存储帐户的名称以显示其内容。
- 通过选中文件夹左侧的复选框,选择 HDInsight 群集存储根目录。 根据之前的屏幕截图,群集存储根目录是选择 Data Lake Storage Gen1 作为默认存储时指定的 /clusters 文件夹。
- 设置文件夹上的权限。 “读取”、“写入”和“执行”默认全部选中。
- 单击页面底部的“选择”。
- 选择“运行”。
- 选择“完成”。
如果使用 Data Lake Storage Gen1 作为额外存储,则必须仅为要从 HDInsight 群集访问的文件夹分配权限。 例如,在以下屏幕截图中,你仅提供对具有 Data Lake Storage Gen1 的存储帐户中的 mynewfolder 文件夹的访问权限。
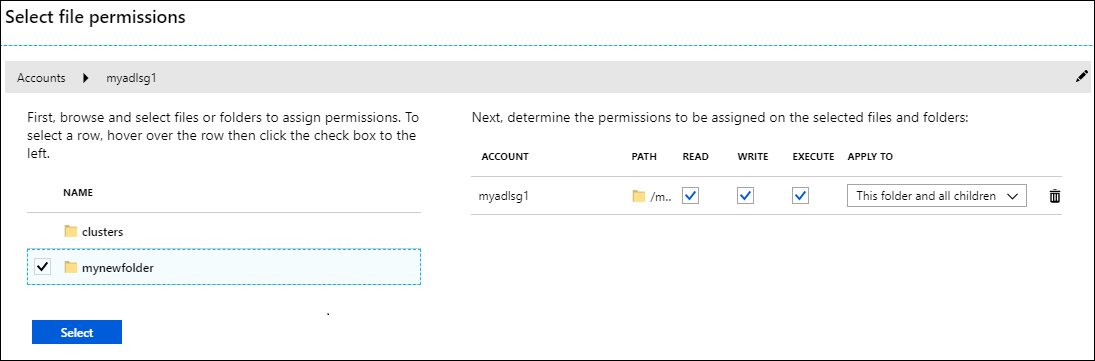
验证群集设置
群集设置完成后,在群集边栏选项卡中通过执行以下一个或两个步骤来验证结果:
若要验证群集的关联存储是否为指定的具有 Data Lake Storage Gen1 的帐户,请在左窗格中选择“存储帐户”。
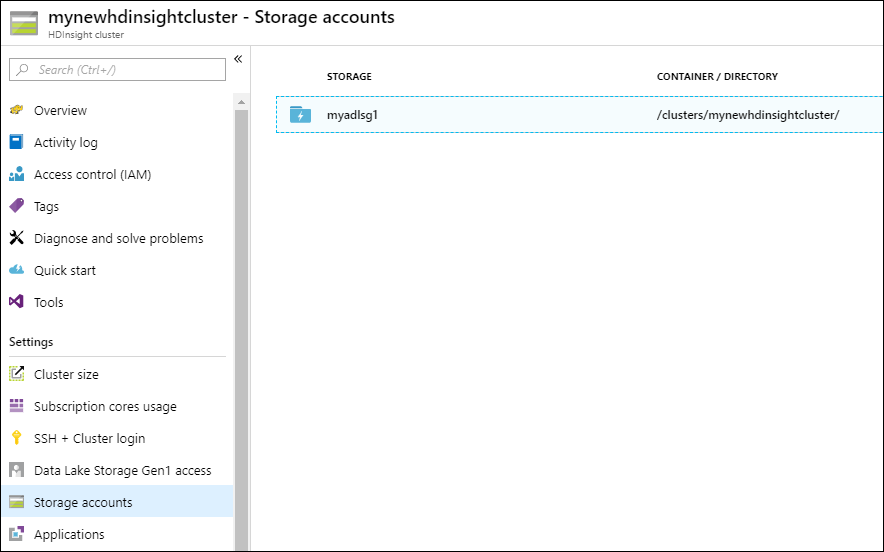
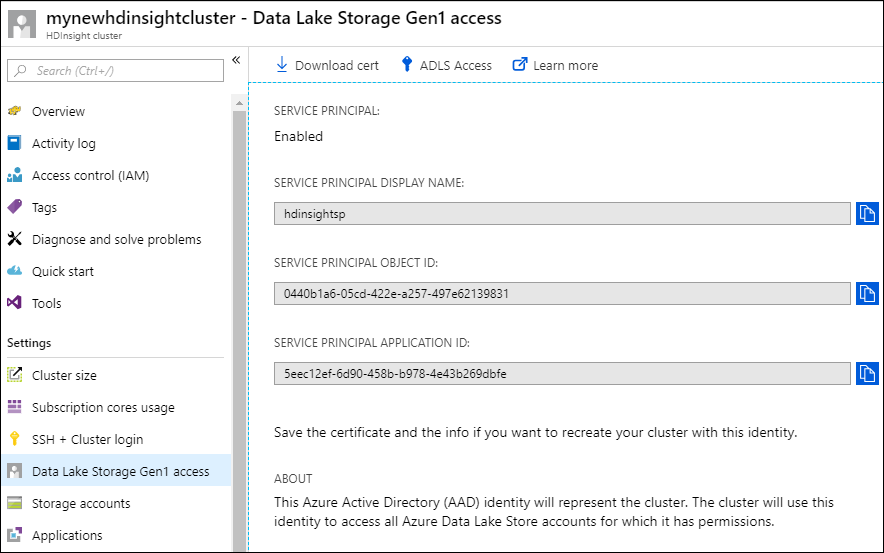
若要验证服务主体是否已与 HDInsight 群集正确关联,请在左窗格中选择“Data Lake Storage Gen1 访问”。
示例
将包含 Data Lake Storage Gen1 的群集设置为存储后,请参阅以下示例,了解如何使用 HDInsight 群集来分析 Data Lake Storage Gen1 中存储的数据。
针对 Data Lake Storage Gen1(用作主存储)中的数据运行 Hive 查询
若要运行 Hive 查询,请在 Ambari 门户中使用 Hive 视图界面。 有关 Ambari Hive 视图用法的说明,请参阅将 Hive 视图与 HDInsight 中的 Hadoop 配合使用。
处理 Data Lake Storage Gen1 中的数据时,需要更改几个字符串。
例如,如使用以 Data Lake Storage Gen1 作为主存储的群集,则数据的路径是:adl://<data_lake_storage_gen1_account_name>/azuredatalakestore.net/path/to/file。 基于 Data Lake Storage Gen1 中存储的示例数据创建表的 Hive 查询如以下语句所示:
CREATE EXTERNAL TABLE websitelog (str string) LOCATION 'adl://hdiadlsg1storage.azuredatalakestore.net/clusters/myhdiadlcluster/HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/'
说明:
-
adl://hdiadlsg1storage.azuredatalakestore.net/是具有 Data Lake Storage Gen1 的帐户的根。 -
/clusters/myhdiadlcluster是在创建群集时指定的群集数据的根。 -
/HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/是查询中所用示例文件的位置。
针对 Data Lake Storage Gen1(用作附加存储)中的数据运行 Hive 查询
如果创建的群集使用 Blob 存储作为默认存储,示例数据不会包含在将 Data Lake Storage Gen1 用作附加存储的存储帐户中。 在这种情况下,请先将数据从 Blob 存储传输到具有 Data Lake Storage Gen1 的存储帐户,然后按前面的示例中所示运行查询。
若要了解如何将数据从 Blob 存储复制到具有 Data Lake Storage Gen1 的存储帐户,请参阅以下文章:
- 使用 Distcp 在 Azure Blob 存储与 Data Lake Storage Gen1 之间复制数据
- 使用 AdlCopy 将数据从 Azure Blob 存储复制到 Data Lake Storage Gen1
在 Spark 群集中使用 Data Lake Storage Gen1
可以使用 Spark 群集对存储在 Data Lake Storage Gen1 中的数据运行 Spark 作业。 有关详细信息,请参阅使用 HDInsight Spark 群集分析 Data Lake Storage Gen1 中的数据。