本文通过示例说明如何使用系统表来监视帐户中 Lakeflow Jobs 的成本和性能。
这些查询仅计算在作业计算和无服务器计算上运行的作业成本。 在 SQL 仓库和通用计算上运行的作业不作为作业计费,因此会从成本归因中排除。
注意
这些查询不会从当前工作区的云区域之外的工作区返回记录。 要监视当前区域之外工作区的作业成本,请在部署在该区域的工作区中运行这些查询。
要求
-
system.lakeflow架构必须由帐户管理员启用。请参阅 Access 系统表。 - 若要访问这些系统表,用户必须:
- 既是元存储管理员,也是帐户管理员,或者
- 对系统架构具有
USE和SELECT权限。 请参阅授予对系统表的访问权限。
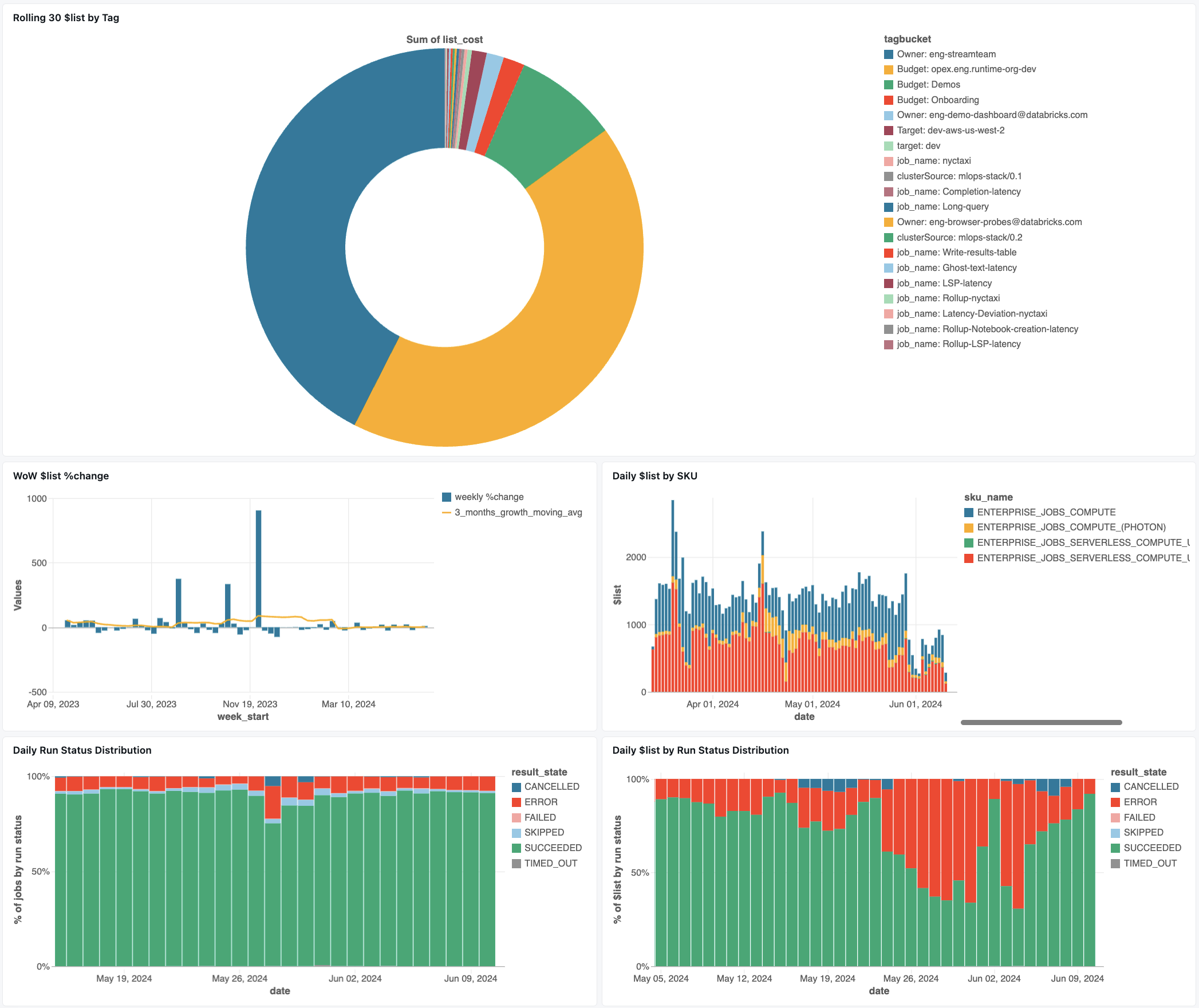
作业监控面板
以下仪表板使用系统表为您提供对 Lakeflow 作业和作业运行状况的全面监视。 它包括常见用例,例如作业性能跟踪、故障监视和资源利用率。
导入仪表板
- 从 Databricks GitHub 存储库下载仪表板 JSON 文件。
- 将仪表板导入工作区。 有关导入仪表板的说明,请参阅导入仪表板文件。
成本可观测性查询
仪表板中的以下查询演示了作业成本监视功能。
最昂贵的工作(过去 30 天)
此查询确定过去 30 天内支出最高的作业。
with list_cost_per_job as (
SELECT
t1.workspace_id,
t1.usage_metadata.job_id,
COUNT(DISTINCT t1.usage_metadata.job_run_id) as runs,
SUM(t1.usage_quantity * list_prices.pricing.default) as list_cost,
first(identity_metadata.run_as, true) as run_as,
first(t1.custom_tags, true) as custom_tags,
MAX(t1.usage_end_time) as last_seen_date
FROM system.billing.usage t1
INNER JOIN system.billing.list_prices list_prices on
t1.cloud = list_prices.cloud and
t1.sku_name = list_prices.sku_name and
t1.usage_start_time >= list_prices.price_start_time and
(t1.usage_end_time <= list_prices.price_end_time or list_prices.price_end_time is null)
WHERE
t1.billing_origin_product = "JOBS"
AND t1.usage_date >= CURRENT_DATE() - INTERVAL 30 DAY
GROUP BY ALL
),
most_recent_jobs as (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.jobs QUALIFY rn=1
)
SELECT
t2.name,
t1.job_id,
t1.workspace_id,
t1.runs,
t1.run_as,
SUM(list_cost) as list_cost,
t1.last_seen_date
FROM list_cost_per_job t1
LEFT JOIN most_recent_jobs t2 USING (workspace_id, job_id)
GROUP BY ALL
ORDER BY list_cost DESC
最近 30 天内最昂贵的任务执行
此查询确定过去 30 天内支出最高的作业运行。
with list_cost_per_job_run as (
SELECT
t1.workspace_id,
t1.usage_metadata.job_id,
t1.usage_metadata.job_run_id as run_id,
SUM(t1.usage_quantity * list_prices.pricing.default) as list_cost,
first(identity_metadata.run_as, true) as run_as,
first(t1.custom_tags, true) as custom_tags,
MAX(t1.usage_end_time) as last_seen_date
FROM system.billing.usage t1
INNER JOIN system.billing.list_prices list_prices on
t1.cloud = list_prices.cloud and
t1.sku_name = list_prices.sku_name and
t1.usage_start_time >= list_prices.price_start_time and
(t1.usage_end_time <= list_prices.price_end_time or list_prices.price_end_time is null)
WHERE
t1.billing_origin_product = 'JOBS'
AND t1.usage_date >= CURRENT_DATE() - INTERVAL 30 DAY
GROUP BY ALL
),
most_recent_jobs as (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.jobs QUALIFY rn=1
)
SELECT
t1.workspace_id,
t2.name,
t1.job_id,
t1.run_id,
t1.run_as,
SUM(list_cost) as list_cost,
t1.last_seen_date
FROM list_cost_per_job_run t1
LEFT JOIN most_recent_jobs t2 USING (workspace_id, job_id)
GROUP BY ALL
ORDER BY list_cost DESC
支出趋势分析 (7-14 天)
此查询确定在过去 2 周内,哪些作业的列表成本支出增长最大。
with job_run_timeline_with_cost as (
SELECT
t1.*,
t1.usage_metadata.job_id as job_id,
t1.identity_metadata.run_as as run_as,
t1.usage_quantity * list_prices.pricing.default AS list_cost
FROM system.billing.usage t1
INNER JOIN system.billing.list_prices list_prices
ON
t1.cloud = list_prices.cloud AND
t1.sku_name = list_prices.sku_name AND
t1.usage_start_time >= list_prices.price_start_time AND
(t1.usage_end_time <= list_prices.price_end_time or list_prices.price_end_time is NULL)
WHERE
t1.billing_origin_product = 'JOBS' AND
t1.usage_date >= CURRENT_DATE() - INTERVAL 14 DAY
),
most_recent_jobs as (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.jobs QUALIFY rn=1
)
SELECT
t2.name
,t1.workspace_id
,t1.job_id
,t1.sku_name
,t1.run_as
,Last7DaySpend
,Last14DaySpend
,last7DaySpend - last14DaySpend as Last7DayGrowth
,try_divide( (last7DaySpend - last14DaySpend) , last14DaySpend) * 100 AS Last7DayGrowthPct
FROM
(
SELECT
workspace_id,
job_id,
run_as,
sku_name,
SUM(list_cost) AS spend
,SUM(CASE WHEN usage_end_time BETWEEN date_add(current_date(), -8) AND date_add(current_date(), -1) THEN list_cost ELSE 0 END) AS Last7DaySpend
,SUM(CASE WHEN usage_end_time BETWEEN date_add(current_date(), -15) AND date_add(current_date(), -8) THEN list_cost ELSE 0 END) AS Last14DaySpend
FROM job_run_timeline_with_cost
GROUP BY ALL
) t1
LEFT JOIN most_recent_jobs t2 USING (workspace_id, job_id)
ORDER BY
Last7DayGrowth DESC
LIMIT 100
运营健康状况查询
下面是此仪表板帮助你跟踪作业性能和可靠性的一些方法。
失败的作业分析
此查询返回有关过去 30 天内运行失败次数较多的作业的信息。 可以查看运行次数、失败次数、成功率以及作业失败运行次数的成本。
with job_run_timeline_with_cost as (
SELECT
t1.*,
t1.identity_metadata.run_as as run_as,
t2.job_id,
t2.run_id,
t2.result_state,
t1.usage_quantity * list_prices.pricing.default as list_cost
FROM system.billing.usage t1
INNER JOIN system.lakeflow.job_run_timeline t2
ON
t1.workspace_id=t2.workspace_id
AND t1.usage_metadata.job_id = t2.job_id
AND t1.usage_metadata.job_run_id = t2.run_id
AND t1.usage_start_time >= date_trunc("Hour", t2.period_start_time)
AND t1.usage_start_time < date_trunc("Hour", t2.period_end_time) + INTERVAL 1 HOUR
INNER JOIN system.billing.list_prices list_prices on
t1.cloud = list_prices.cloud and
t1.sku_name = list_prices.sku_name and
t1.usage_start_time >= list_prices.price_start_time and
(t1.usage_end_time <= list_prices.price_end_time or list_prices.price_end_time is null)
WHERE
t1.billing_origin_product = 'JOBS' AND
t1.usage_date >= CURRENT_DATE() - INTERVAL 30 DAYS
),
cumulative_run_status_cost as (
SELECT
workspace_id,
job_id,
run_id,
run_as,
result_state,
usage_end_time,
SUM(list_cost) OVER (ORDER BY workspace_id, job_id, run_id, usage_end_time ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cumulative_cost
FROM job_run_timeline_with_cost
ORDER BY workspace_id, job_id, run_id, usage_end_time
),
cost_per_status as (
SELECT
workspace_id,
job_id,
run_id,
run_as,
result_state,
usage_end_time,
cumulative_cost - COALESCE(LAG(cumulative_cost) OVER (ORDER BY workspace_id, job_id, run_id, usage_end_time), 0) AS result_state_cost
FROM cumulative_run_status_cost
WHERE result_state IS NOT NULL
ORDER BY workspace_id, job_id, run_id, usage_end_time),
cost_per_status_agg as (
SELECT
workspace_id,
job_id,
FIRST(run_as, TRUE) as run_as,
SUM(result_state_cost) as list_cost
FROM cost_per_status
WHERE
result_state IN ('ERROR', 'FAILED', 'TIMED_OUT')
GROUP BY ALL
),
terminal_statues as (
SELECT
workspace_id,
job_id,
CASE WHEN result_state IN ('ERROR', 'FAILED', 'TIMED_OUT') THEN 1 ELSE 0 END as is_failure,
period_end_time as last_seen_date
FROM system.lakeflow.job_run_timeline
WHERE
result_state IS NOT NULL AND
period_end_time >= CURRENT_DATE() - INTERVAL 30 DAYS
),
most_recent_jobs as (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.jobs QUALIFY rn=1
)
SELECT
first(t2.name) as name,
t1.workspace_id,
t1.job_id,
COUNT(*) as runs,
t3.run_as,
SUM(is_failure) as failures,
(1 - COALESCE(try_divide(SUM(is_failure), COUNT(*)), 0)) * 100 as success_ratio,
first(t3.list_cost) as failure_list_cost,
MAX(t1.last_seen_date) as last_seen_date
FROM terminal_statues t1
LEFT JOIN most_recent_jobs t2 USING (workspace_id, job_id)
LEFT JOIN cost_per_status_agg t3 USING (workspace_id, job_id)
GROUP BY ALL
ORDER BY failures DESC
重试模式
此查询返回过去 30 天内频繁修复的作业的信息,包括修复次数、修复运行成本以及修复运行的累积持续时间。
with job_run_timeline_with_cost as (
SELECT
t1.*,
t2.job_id,
t2.run_id,
t1.identity_metadata.run_as as run_as,
t2.result_state,
t1.usage_quantity * list_prices.pricing.default as list_cost
FROM system.billing.usage t1
INNER JOIN system.lakeflow.job_run_timeline t2
ON
t1.workspace_id=t2.workspace_id
AND t1.usage_metadata.job_id = t2.job_id
AND t1.usage_metadata.job_run_id = t2.run_id
AND t1.usage_start_time >= date_trunc("Hour", t2.period_start_time)
AND t1.usage_start_time < date_trunc("Hour", t2.period_end_time) + INTERVAL 1 HOUR
INNER JOIN system.billing.list_prices list_prices on
t1.cloud = list_prices.cloud and
t1.sku_name = list_prices.sku_name and
t1.usage_start_time >= list_prices.price_start_time and
(t1.usage_end_time <= list_prices.price_end_time or list_prices.price_end_time is null)
WHERE
t1.billing_origin_product = 'JOBS' AND
t1.usage_date >= CURRENT_DATE() - INTERVAL 30 DAYS
),
cumulative_run_status_cost as (
SELECT
workspace_id,
job_id,
run_id,
run_as,
result_state,
usage_end_time,
SUM(list_cost) OVER (ORDER BY workspace_id, job_id, run_id, usage_end_time ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cumulative_cost
FROM job_run_timeline_with_cost
ORDER BY workspace_id, job_id, run_id, usage_end_time
),
cost_per_status as (
SELECT
workspace_id,
job_id,
run_id,
run_as,
result_state,
usage_end_time,
cumulative_cost - COALESCE(LAG(cumulative_cost) OVER (ORDER BY workspace_id, job_id, run_id, usage_end_time), 0) AS result_state_cost
FROM cumulative_run_status_cost
WHERE result_state IS NOT NULL
ORDER BY workspace_id, job_id, run_id, usage_end_time),
cost_per_unsuccesful_status_agg as (
SELECT
workspace_id,
job_id,
run_id,
first(run_as, TRUE) as run_as,
SUM(result_state_cost) as list_cost
FROM cost_per_status
WHERE
result_state != "SUCCEEDED"
GROUP BY ALL
),
repaired_runs as (
SELECT
workspace_id, job_id, run_id, COUNT(*) as cnt
FROM system.lakeflow.job_run_timeline
WHERE result_state IS NOT NULL
GROUP BY ALL
HAVING cnt > 1
),
successful_repairs as (
SELECT t1.workspace_id, t1.job_id, t1.run_id, MAX(t1.period_end_time) as period_end_time
FROM system.lakeflow.job_run_timeline t1
JOIN repaired_runs t2
ON t1.workspace_id=t2.workspace_id AND t1.job_id=t2.job_id AND t1.run_id=t2.run_id
WHERE t1.result_state="SUCCEEDED"
GROUP BY ALL
),
combined_repairs as (
SELECT
t1.*,
t2.period_end_time,
t1.cnt as repairs
FROM repaired_runs t1
LEFT JOIN successful_repairs t2 USING (workspace_id, job_id, run_id)
),
most_recent_jobs as (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.jobs QUALIFY rn=1
)
SELECT
last(t3.name) as name,
t1.workspace_id,
t1.job_id,
t1.run_id,
first(t4.run_as, TRUE) as run_as,
first(t1.repairs) - 1 as repairs,
first(t4.list_cost) as repair_list_cost,
CASE WHEN t1.period_end_time IS NOT NULL THEN CAST(t1.period_end_time - MIN(t2.period_end_time) as LONG) ELSE NULL END AS repair_time_seconds
FROM combined_repairs t1
JOIN system.lakeflow.job_run_timeline t2 USING (workspace_id, job_id, run_id)
LEFT JOIN most_recent_jobs t3 USING (workspace_id, job_id)
LEFT JOIN cost_per_unsuccesful_status_agg t4 USING (workspace_id, job_id, run_id)
WHERE
t2.result_state IS NOT NULL
GROUP BY t1.workspace_id, t1.job_id, t1.run_id, t1.period_end_time
ORDER BY repairs DESC