重要
本文档已停用,可能不会更新。 本内容中提及的产品、服务或技术不再受支持。 请参阅 日期/时间模式。
在Databricks Runtime 7.0中,Date 和 Timestamp 数据类型发生了显著变化。 本文介绍:
- 与
Date类型相关联的日历。 - 类型
Timestamp及其与时区的关系。 它还介绍了时区偏移解析的详细信息,以及 Databricks Runtime 7.0 使用的 Java 8 中新时间 API 中的细微行为更改。 - 用于构造日期和时间时间戳值的 API。
- 在 Apache Spark 驱动程序上收集日期和时间对象时的常见陷阱和最佳做法。
日期和日历
A Date 是年、月和日字段的组合,例如(year=2012、month=12、day=31)。 但是,年、月和日字段的值具有约束,以确保日期值是实际的有效日期。 例如,月份的值必须介于 1 到 12 之间,日值必须介于 1 到 28、29、30 或 31 之间(具体取决于年份和月份),依此等。 该 Date 类型不考虑时区。
日历
对Date字段的约束由多种可能的日历之一定义。 有些,如 农历,仅用于特定区域。 有些,如 朱利安日历,仅用于历史记录。 事实上的国际标准是 公历 ,它几乎在世界各地用于民用目的。 它在1582年推出,并扩展为支持1582年之前的日期。 此延长日历称为 前摄公历。
Databricks Runtime 7.0 使用 Proleptic 公历,该日历已被其他数据系统(如 pandas、R 和 Apache Arrow)使用。 Databricks Runtime 6.x 及更低版本使用了儒略历和公历的组合:1582 年之前的日期使用儒略历,1582 年之后的日期使用公历。 这继承自旧版 java.sql.Date API,该 API 在 Java 8 中被 java.time.LocalDate 取代,java.time.LocalDate 使用 Proleptic 公历。
时间戳和时区
Timestamp 类型使用新的字段扩展了 Date 类型:小时、分钟、秒(可以包含小数部分),以及一个在会话范围内定义的全局时区。 它定义了具体的时间瞬间。 例如,(year=2012,month=12,day=31,hour=23,minute=59,second=59.123456),会话时区 UTC+01:00。 将时间戳值写入非文本数据源(例如 Parquet)时,这些值仅表示某一时刻(如 UTC 中的时间戳),并且没有附带时区信息。 如果在具有不同会话时区的情况下编写或读取时间戳值,您可能会看到小时、分钟和秒字段的不同值,但它们代表相同的具体的时间瞬间。
小时、分钟和秒字段具有标准范围:0-23(小时)和 0-59(分钟和秒)。 Spark 支持小数秒,精度高达微秒。 分数的有效范围为 0 到 999,999 微秒。
在任何具体时刻,根据时区,可以观察许多不同的时钟值:
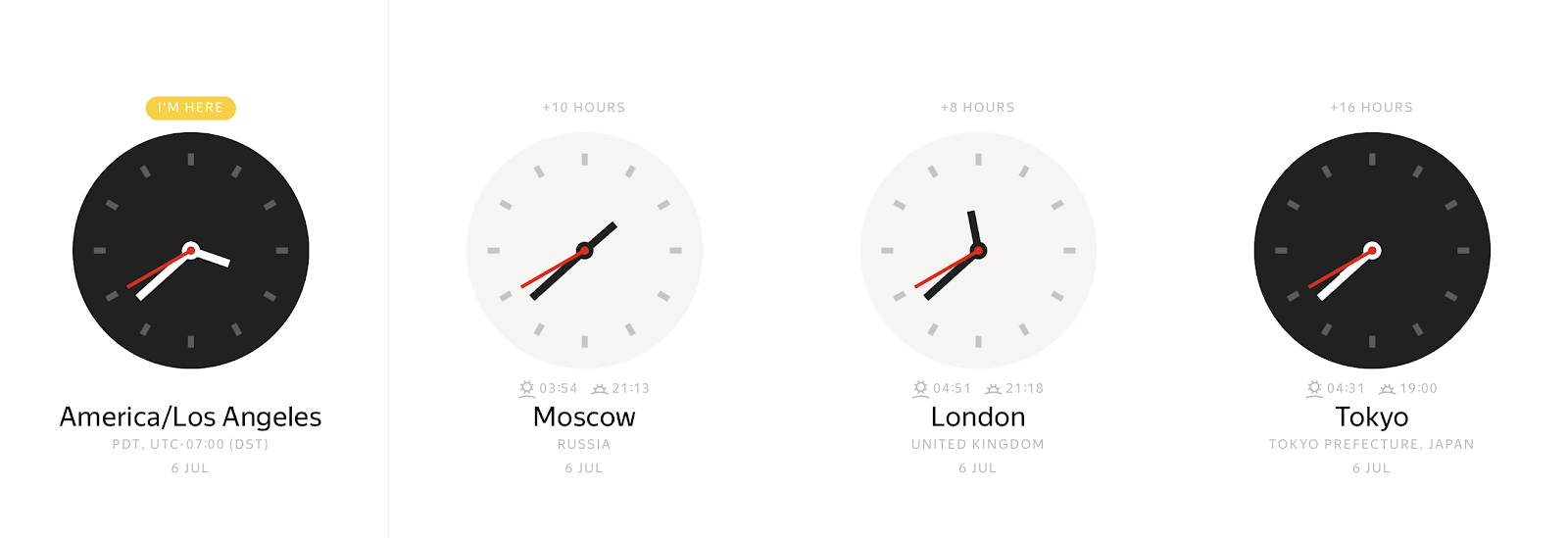
相反,墙上时钟的读数可以表示多个不同的时间瞬间。
时区偏移量允许您明确地将本地时间戳绑定到一个时间点。 通常,时区偏移量定义为格林威治标准时间(GMT)或 UTC+0 (协调世界时)的小时偏移量。 时区信息的这种表示形式消除了歧义,但它不方便。 大多数人更喜欢指出一个位置,如 America/Los_Angeles 或 Europe/Paris。 这种从时区偏移出发的额外抽象层次使生活更简单,但也带来了复杂性。 例如,现在必须维护特殊的时区数据库,以将时区名称映射到偏移量。 由于 Spark 在 JVM 上运行,因此它将映射委托给 Java 标准库,该库从 Internet 分配的数字颁发机构时区数据库 (IANA TZDB)加载数据。 此外,Java 标准库中的映射机制具有影响 Spark 行为的一些细微差别。
从 Java 8 开始,JDK 提供了不同的 API 用于日期时间的操作和时区偏移的解析,Databricks Runtime 7.0 使用了该 API。 尽管时区名称与时区偏移量的映射使用了相同的来源,即 IANA TZDB,但在 Java 8 及更高版本中,其实现方式与 Java 7 不同。
例如,查看时区中 America/Los_Angeles 1883 年之前的时间戳: 1883-11-10 00:00:00 今年从其他人中脱颖而出,因为1883年11月18日,所有北美铁路都改用了新的标准时间系统。 使用 Java 7 时间 API,可以在本地时间戳处获取时区偏移量,如下所示 -08:00:
java.time.ZoneId.systemDefault
res0:java.time.ZoneId = America/Los_Angeles
java.sql.Timestamp.valueOf("1883-11-10 00:00:00").getTimezoneOffset / 60.0
res1: Double = 8.0
等效的 Java 8 API 返回不同的结果:
java.time.ZoneId.of("America/Los_Angeles").getRules.getOffset(java.time.LocalDateTime.parse("1883-11-10T00:00:00"))
res2: java.time.ZoneOffset = -07:52:58
在1883年11月18日之前,北美的时间问题是一个地方性事务,大多数城镇都使用某种形式的当地太阳时间,由一些知名的时钟(例如,教堂的钟楼上,或珠宝店的橱窗)维护。 这就是为什么你看到如此奇怪的时区偏移量。
该示例演示 Java 8 函数更精确,并考虑到 IANA TZDB 的历史数据。 切换到 Java 8 时间 API 后,Databricks Runtime 7.0 自动受益于改进,在解析时区偏移的方式方面变得更加精确。
Databricks Runtime 7.0 还切换到适用于该 Timestamp 类型的前置公历。
ISO SQL:2016 标准声明时间戳的有效范围是从 / 0001-01-01 00:00:00 到 9999-12-31 23:59:59.999999。 Databricks Runtime 7.0 完全符合标准,并支持此范围中的所有时间戳。 与 Databricks Runtime 6.x 及更低版本相比,请注意以下子范围:
-
0001-01-01 00:00:00..1582-10-03 23:59:59.999999。 Databricks Runtime 6.x 及更低版本使用 Julian 日历,并且不符合标准。 Databricks Runtime 7.0 修复了此问题,并在获取年、月、日等时间戳的内部作中应用 Proleptic Gregorian 日历。由于日历不同,Databricks Runtime 6.x 及更低版本中存在的某些日期在 Databricks Runtime 7.0 中不存在。 例如,1000-02-29 不是有效日期,因为 1000 不是公历中的跃年。 此外,Databricks Runtime 6.x 及更低版本错误地将时区名称解析为区域偏移在此时间戳范围内。 -
1582-10-04 00:00:00..1582-10-14 23:59:59.999999。 这是 Databricks Runtime 7.0 中本地时间戳的有效范围,与 Databricks Runtime 6.x 及更低版本相比,此类时间戳不存在。 -
1582-10-15 00:00:00..1899-12-31 23:59:59.999999。 Databricks Runtime 7.0 使用 IANA TZDB 中的历史数据正确解析时区偏移。 与 Databricks Runtime 7.0 相比,Databricks Runtime 6.x 及更低版本在某些情况下可能会错误解析时区名称的区域偏移,如前面的示例所示。 -
1900-01-01 00:00:00..2036-12-31 23:59:59.999999。 Databricks Runtime 7.0 和 Databricks Runtime 6.x 及更低版本都符合 ANSI SQL 标准,并在日期时间作中使用公历,例如获取月份的日期。 -
2037-01-01 00:00:00..9999-12-31 23:59:59.999999。 Databricks Runtime 6.x 及更低版本可以错误地解析时区偏移量和夏令时偏移量。 Databricks Runtime 7.0 不支持此功能。
将时区名称映射到偏移量的一个重要方面是可能出现的本地时间戳重叠,这种重叠可能由于采用夏令时(DST)或转换至另一个标准时区偏移而出现。 例如,在 2019 年 11 月 3 日 02:00:00,美国大多数州将时钟倒退 1 小时到 01:00:00。 本地时间戳2019-11-03 01:30:00 America/Los_Angeles可以映射到2019-11-03 01:30:00 UTC-08:00或2019-11-03 01:30:00 UTC-07:00。 如果未指定偏移量,并且只是设置时区名称(例如 2019-11-03 01:30:00 America/Los_Angeles),Databricks Runtime 7.0 采用以前的偏移量,通常对应于“summer”。 该行为不同于 Databricks Runtime 6.x 和更低版本,该版本采用“冬季”偏移量。 如果存在间隙,时钟向前跳跃,则没有有效的偏移量。 对于典型的一小时夏令时调整,Spark 会将这些时间戳移动到对应于夏令时的下一个有效时间戳。
如前面的示例所示,时区名称到偏移量的映射不明确,不是一对一。 在可能的情况下,在构造时间戳时,我们建议指定确切的时区偏移量,例如 2019-11-03 01:30:00 UTC-07:00。
ANSI SQL 和 Spark SQL 时间戳
ANSI SQL 标准定义了两种类型的时间戳:
-
TIMESTAMP WITHOUT TIME ZONE或TIMESTAMP:本地时间戳(YEAR、、MONTHDAY、HOUR、MINUTE)。SECOND这些时间戳不绑定到任何时区,并且是时钟时间戳。 -
TIMESTAMP WITH TIME ZONE:区域时间戳为(YEAR、MONTH、DAY、HOUR、MINUTE、SECOND、TIMEZONE_HOUR、TIMEZONE_MINUTE)。 这些时间戳表示 UTC 时区中的即时时间 + 与每个值关联的时区偏移量(以小时和分钟为单位)。
时区偏移 TIMESTAMP WITH TIME ZONE 量不会影响时间戳所表示的物理时间点,因为时间戳由其他时间戳组件给出的 UTC 时间即时完全表示。 相反,时区偏移仅影响时间戳值的默认行为,用于显示、日期/时间组件提取(例如 EXTRACT),以及其他需要知道时区的作,例如将月份添加到时间戳。
Spark SQL 将 TIMESTAMP WITH SESSION TIME ZONE 定义为时间戳类型,它是字段(YEAR、MONTH、DAY、HOUR、MINUTE、SECOND、SESSION TZ)的组合,其中 YEAR 到 SECOND 字段标识 UTC 时区中的时间瞬间,并且 SESSION TZ 从 SQL 配置 spark.sql.session.timeZone 中获取。 会话时区可以设置为:
- 区域偏移量
(+|-)HH:mm。 此窗体允许明确定义物理时间点。 - 时区名称,格式为区域 ID
area/city,例如America/Los_Angeles。 这种形式的时区信息受到以前描述的一些问题(如本地时间戳重叠)的影响。 但是,每个 UTC 时间即时都明确与任何区域 ID 的一个时区偏移量相关联,因此,具有基于区域 ID 的时区的每个时间戳可以明确转换为具有区域偏移量的时间戳。 默认情况下,会话时区设置为 Java 虚拟机的默认时区。
Spark TIMESTAMP WITH SESSION TIME ZONE 不同于:
-
TIMESTAMP WITHOUT TIME ZONE,因为此类型的值可以映射到多个物理时间即时,但任何值TIMESTAMP WITH SESSION TIME ZONE都是具体的物理时间即时。 可以通过在所有会话(例如 UTC+0)中使用一个固定时区偏移来模拟 SQL 类型。 在这种情况下,可以将 UTC 的时间戳视为本地时间戳。 -
TIMESTAMP WITH TIME ZONE,因为根据 SQL 标准中该类型的列值可以具有不同的时区偏移量。 Spark SQL 不支持这一点。
应注意到,与全局(会话范围)时区关联的时间戳不是 Spark SQL 新发明的时间戳。 RDBMS(如 Oracle)为时间戳提供类似的类型: TIMESTAMP WITH LOCAL TIME ZONE。
构造日期和时间戳
Spark SQL 提供了一些用于构造日期和时间时间戳值的方法:
- 不带参数的默认构造函数:
CURRENT_TIMESTAMP()和CURRENT_DATE()。 - 来自其他基元 Spark SQL 类型,例如
INT,LONG和STRING - 从外部类型如 Python 日期时间或 Java 类
java.time.LocalDate/Instant。 - 从数据源(如 CSV、JSON、Avro、Parquet、ORC 等)进行反序列化。
Databricks Runtime 7.0 中引入的函数 MAKE_DATE 采用三个参数YEAR, MONTH并 DAY构造一个 DATE 值。 所有输入参数都尽可能隐式转换为 INT 类型。 该函数检查生成的日期是否为 Proleptic 公历中的有效日期,否则返回 NULL。 例如:
spark.createDataFrame([(2020, 6, 26), (1000, 2, 29), (-44, 1, 1)],['Y', 'M', 'D']).createTempView('YMD')
df = sql('select make_date(Y, M, D) as date from YMD')
df.printSchema()
root
|-- date: date (nullable = true)
若要打印 DataFrame 内容,请调用 show() 操作,该操作将日期转换为字符串,并将这些字符串传输到驱动程序,以在控制台上输出它们。
df.show()
+-----------+
| date|
+-----------+
| 2020-06-26|
| null|
|-0044-01-01|
+-----------+
同样,可以使用函数构造时间戳值 MAKE_TIMESTAMP 。 同样 MAKE_DATE,它对日期字段执行相同的验证,另外还接受时间字段 HOUR (0-23)、MINUTE (0-59) 和 SECOND (0-60)。 SECOND 的类型为 Decimal(精度 = 8,刻度 = 6),因为秒可以与小数部分一起传递到微秒精度。 例如:
df = spark.createDataFrame([(2020, 6, 28, 10, 31, 30.123456), \
(1582, 10, 10, 0, 1, 2.0001), (2019, 2, 29, 9, 29, 1.0)],['YEAR', 'MONTH', 'DAY', 'HOUR', 'MINUTE', 'SECOND'])
df.show()
+----+-----+---+----+------+---------+
|YEAR|MONTH|DAY|HOUR|MINUTE| SECOND|
+----+-----+---+----+------+---------+
|2020| 6| 28| 10| 31|30.123456|
|1582| 10| 10| 0| 1| 2.0001|
|2019| 2| 29| 9| 29| 1.0|
+----+-----+---+----+------+---------+
df.selectExpr("make_timestamp(YEAR, MONTH, DAY, HOUR, MINUTE, SECOND) as MAKE_TIMESTAMP")
ts.printSchema()
root
|-- MAKE_TIMESTAMP: timestamp (nullable = true)
至于日期,使用show()操作打印ts DataFrame的内容。 以类似的方式将时间戳转换为字符串, show() 但现在它会考虑 SQL 配置 spark.sql.session.timeZone定义的会话时区。
ts.show(truncate=False)
+--------------------------+
|MAKE_TIMESTAMP |
+--------------------------+
|2020-06-28 10:31:30.123456|
|1582-10-10 00:01:02.0001 |
|null |
+--------------------------+
Spark 无法创建最后一个时间戳,因为此日期无效:2019 年不是跃年。
你可能会注意到前面的示例中没有时区信息。 在这种情况下,Spark 需要 SQL 配置 spark.sql.session.timeZone 中的时区,并将其应用于函数调用。 您还可以通过将其作为MAKE_TIMESTAMP的最后一个参数传递来选择不同的时区。 下面是一个示例:
df = spark.createDataFrame([(2020, 6, 28, 10, 31, 30, 'UTC'),(1582, 10, 10, 0, 1, 2, 'America/Los_Angeles'), \
(2019, 2, 28, 9, 29, 1, 'Europe/Moscow')], ['YEAR', 'MONTH', 'DAY', 'HOUR', 'MINUTE', 'SECOND', 'TZ'])
df = df.selectExpr('make_timestamp(YEAR, MONTH, DAY, HOUR, MINUTE, SECOND, TZ) as MAKE_TIMESTAMP')
df = df.selectExpr("date_format(MAKE_TIMESTAMP, 'yyyy-MM-dd HH:mm:ss VV') AS TIMESTAMP_STRING")
df.show(truncate=False)
+---------------------------------+
|TIMESTAMP_STRING |
+---------------------------------+
|2020-06-28 13:31:00 Europe/Moscow|
|1582-10-10 10:24:00 Europe/Moscow|
|2019-02-28 09:29:00 Europe/Moscow|
+---------------------------------+
如示例所示,Spark 将考虑指定的时区,但将所有本地时间戳调整为会话时区。 传递给 MAKE_TIMESTAMP 函数的原始时区丢失,因为 TIMESTAMP WITH SESSION TIME ZONE 该类型假定所有值都属于一个时区,并且它甚至不会为每个值存储时区。 根据定义 TIMESTAMP WITH SESSION TIME ZONE,Spark 将本地时间戳存储在 UTC 时区中,并在提取日期时间字段或将时间戳转换为字符串时使用会话时区。
此外,可以通过类型转换从 LONG 类型来构造时间戳。 如果 LONG 列包含自 1970-01-01 00:00:00Z 以来的秒数,则可以将其转换为 Spark SQL TIMESTAMP:
select CAST(-123456789 AS TIMESTAMP);
1966-02-02 05:26:51
遗憾的是,此方法不允许指定秒的小数部分。
另一种方法是从STRING类型的值构造日期和时间戳。 可以使用特殊关键字创建字面值:
select timestamp '2020-06-28 22:17:33.123456 Europe/Amsterdam', date '2020-07-01';
2020-06-28 23:17:33.123456 2020-07-01
或者,可以使用可应用于列中所有值的强制转换:
select cast('2020-06-28 22:17:33.123456 Europe/Amsterdam' as timestamp), cast('2020-07-01' as date);
2020-06-28 23:17:33.123456 2020-07-01
如果输入字符串中省略了时区,则输入时间戳字符串将解释为指定时区或会话时区中的本地时间戳。 具有异常模式的字符串可以使用函数 to_timestamp() 转换为时间戳。 支持的模式在格式化和解析的日期/时间模式中有介绍。
select to_timestamp('28/6/2020 22.17.33', 'dd/M/yyyy HH.mm.ss');
2020-06-28 22:17:33
如果未指定模式,函数的行为方式与 CAST 类似。
为了方便使用,Spark SQL 识别接受字符串并返回时间戳或日期的所有方法中的特殊字符串值:
-
epoch是日期1970-01-01或时间戳1970-01-01 00:00:00Z的别名。 -
now是会话时区的当前时间戳或日期。 在单个查询中,它始终生成相同的结果。 -
today是对于TIMESTAMP类型的当前日期的开始,或对于DATE类型仅仅是当前日期。 -
tomorrow是时间戳新一天的开始,而对于DATE类型而言则仅指下一天。 -
yesterday是当前类型前一天或其开始日期TIMESTAMP。
例如:
select timestamp 'yesterday', timestamp 'today', timestamp 'now', timestamp 'tomorrow';
2020-06-27 00:00:00 2020-06-28 00:00:00 2020-06-28 23:07:07.18 2020-06-29 00:00:00
select date 'yesterday', date 'today', date 'now', date 'tomorrow';
2020-06-27 2020-06-28 2020-06-28 2020-06-29
Spark 允许从驱动程序端的现有外部对象的集合创建 Datasets ,并创建相应类型的列。 Spark 将外部类型的实例转换为语义上等效的内部表示形式。 例如,要从 Python 集合中创建一个包含 Dataset 和 DATE 列的 TIMESTAMP,可以使用:
import datetime
df = spark.createDataFrame([(datetime.datetime(2020, 7, 1, 0, 0, 0), datetime.date(2020, 7, 1))], ['timestamp', 'date'])
df.show()
+-------------------+----------+
| timestamp| date|
+-------------------+----------+
|2020-07-01 00:00:00|2020-07-01|
+-------------------+----------+
PySpark 使用系统时区将 Python 的日期时间对象转换为驱动程序端的内部 Spark SQL 表示形式,这与 Spark 的会话时区设置 spark.sql.session.timeZone不同。 内部值不包含有关原始时区的信息。 基于并行化日期和时间时间戳值的未来作仅根据 TIMESTAMP WITH SESSION TIME ZONE 类型定义考虑 Spark SQL 会话时区。
类似地,Spark 在 Java 和 Scala API 中将以下类型识别为外部日期时间类型:
-
java.sql.Date和java.time.LocalDate作为DATE类型的外部类型 -
java.sql.Timestamp和java.time.Instant适用于TIMESTAMP类型。
java.sql.*类型和java.time.*类型之间存在差异。
java.time.LocalDate 并 java.time.Instant 已添加到 Java 8 中,并且类型基于 Proleptic 公历-Databricks Runtime 7.0 及更高版本的日历。
java.sql.Date 和 java.sql.Timestamp 下还有一个日历——混合日历(自 1582-10-15 以来的儒略历与公历),这与 Databricks Runtime 6.x 及更早版本中使用的旧日历相同。 由于不同的日历系统,Spark 在转换到内部 Spark SQL 表示形式期间必须执行额外操作,并将输入日期/时间戳从一个日历转换为另一个日历。 在 1900 年之后,变基操作对现代时间戳有一些开销,对于旧时间戳来说可能更为显著。
以下示例演示如何从 Scala 集合生成时间戳。 第一个 java.sql.Timestamp 示例从字符串构造对象。 该方法 valueOf 将输入字符串解释为默认 JVM 时区中的本地时间戳,该时间戳可能不同于 Spark 的会话时区。 如果需要在特定时区构造java.sql.Timestamp或java.sql.Date的实例,请查看java.text.SimpleDateFormat(及其方法setTimeZone)或java.util.Calendar。
Seq(java.sql.Timestamp.valueOf("2020-06-29 22:41:30"), new java.sql.Timestamp(0)).toDF("ts").show(false)
+-------------------+
|ts |
+-------------------+
|2020-06-29 22:41:30|
|1970-01-01 03:00:00|
+-------------------+
Seq(java.time.Instant.ofEpochSecond(-12219261484L), java.time.Instant.EPOCH).toDF("ts").show
+-------------------+
| ts|
+-------------------+
|1582-10-15 11:12:13|
|1970-01-01 03:00:00|
+-------------------+
同样,你可以从DATE或java.sql.Date的集合中创建一个java.sql.LocalDate列。 实例的 java.sql.LocalDate 并行化与 Spark 的会话或 JVM 默认时区完全无关,但实例 java.sql.Date 的并行化则不然。 有细微差别:
-
java.sql.Date实例表示驱动程序上默认 JVM 时区的本地日期。 - 若要正确转换为 Spark SQL 值,驱动程序和执行程序的默认 JVM 时区必须相同。
Seq(java.time.LocalDate.of(2020, 2, 29), java.time.LocalDate.now).toDF("date").show
+----------+
| date|
+----------+
|2020-02-29|
|2020-06-29|
+----------+
为了避免任何日历和时区相关问题,我们建议将 Java 8 类型作为外部类型 java.sql.LocalDate/Instant 并行化 Java/Scala 时间戳或日期集合。
收集日期和时间戳
并行化的反向操作是将日期和时间戳从执行器收集回驱动程序,并返回一个外部类型的集合。 例如,对于上面的例子,可以使用DataFrame操作将collect()拉回到驱动程序。
df.collect()
[Row(timestamp=datetime.datetime(2020, 7, 1, 0, 0), date=datetime.date(2020, 7, 1))]
Spark 将日期和时间时间戳列的内部值作为 UTC 时区中的时间实例从执行程序传输到驱动程序,并在驱动程序的系统时区中执行到 Python 日期/时间对象的转换,而不是使用 Spark SQL 会话时区。
collect() 与上一部分中所述的 show() 操作不同。
show() 在将时间戳转换为字符串时使用会话时区,并在驱动程序上收集生成的字符串。
在 Java 和 Scala API 中,Spark 默认执行以下转换:
- Spark SQL
DATE值将转换为java.sql.Date实例。 - Spark SQL
TIMESTAMP值将转换为java.sql.Timestamp实例。
这两个转换在驱动程序的默认 JVM 时区中执行。 为了使通过Date.getDay()、getHour()等方式获得的日期/时间字段与使用 Spark SQL 函数DAY、HOUR所获得的字段保持一致,驱动程序上的默认 JVM 时区和执行程序上的会话时区必须相同。
与从 java.sql.Date/Timestamp中生成日期/时间戳类似,Databricks Runtime 7.0 执行将日期从 Proleptic 公历重新基准到混合日历(儒略历 + 公历)的操作。 该操作对现代日期(1582年之后)和时间戳(1900年之后)几乎是免费的,但对于处理古代日期和时间戳可能会带来一些开销。
可以避免此类日历相关问题,并要求 Spark 返回自 Java 8 添加以来的 java.time 类型。 如果将 SQL 配置 spark.sql.datetime.java8API.enabled 设置为 true,Dataset.collect() 将返回:
-
java.time.LocalDate用于 Spark SQLDATE类型 -
java.time.Instant用于 Spark SQLTIMESTAMP类型
现在,由于 Java 8 类型和 Databricks Runtime 7.0 及更高版本都基于 Proleptic 公历,因此转换不会受到与日历相关的问题的影响。 该collect()动作不依赖默认的 JVM 时区。 时间戳转换根本不依赖于时区。 日期转换使用 SQL 配置 spark.sql.session.timeZone中的会话时区。 例如,考虑一个具有Dataset、DATE和TIMESTAMP列的结构,将默认 JVM 时区设置为Europe/Moscow,会话时区设置为America/Los_Angeles。
java.util.TimeZone.getDefault
res1: java.util.TimeZone = sun.util.calendar.ZoneInfo[id="Europe/Moscow",...]
spark.conf.get("spark.sql.session.timeZone")
res2: String = America/Los_Angeles
df.show
+-------------------+----------+
| timestamp| date|
+-------------------+----------+
|2020-07-01 00:00:00|2020-07-01|
+-------------------+----------+
该 show() 操作在会话时间 America/Los_Angeles 打印时间戳,但如果收集 Dataset,则会转换为 java.sql.Timestamp 并通过 toString 方法输出为 Europe/Moscow:
df.collect()
res16: Array[org.apache.spark.sql.Row] = Array([2020-07-01 10:00:00.0,2020-07-01])
df.collect()(0).getAs[java.sql.Timestamp](0).toString
res18: java.sql.Timestamp = 2020-07-01 10:00:00.0
实际上,本地时间戳 2020-07-01 00:00:00 为 2020-07-01T07:00:00Z(UTC)。 如果启用 Java 8 API 并收集数据集,可以观察到:
df.collect()
res27: Array[org.apache.spark.sql.Row] = Array([2020-07-01T07:00:00Z,2020-07-01])
你可以将java.time.Instant对象转换为任何本地时间戳,而不依赖于全局 JVM 时区。 这是java.time.Instant相比java.sql.Timestamp的优势之一。 前者需要更改全局 JVM 设置,这会影响同一 JVM 上的其他时间戳。 因此,如果应用程序处理不同时区中的日期或时间戳,并且应用程序在使用 Java 或 Scala Dataset.collect() API 将数据收集到驱动程序时不应相互冲突,我们建议使用 SQL 配置 spark.sql.datetime.java8API.enabled切换到 Java 8 API。