本文介绍如何使用 Azure Databricks UI 中的本机计算指标工具收集关键硬件和 Spark 指标。 指标 UI 可用于通用计算和任务计算。
指标几乎实时可用,正常延迟不到一分钟。 指标存储在 Azure Databricks 托管的存储中,而不是客户的存储中。
笔记本和作业的无服务器计算使用查询分析,而不是指标 UI。 有关无服务器计算指标的详细信息,请参阅查看查询见解。
访问计算指标 UI
若要查看计算指标 UI,请执行以下操作:
- 单击边栏中的 “计算”。
- 单击要查看指标的计算资源。
- 单击“指标”选项卡。
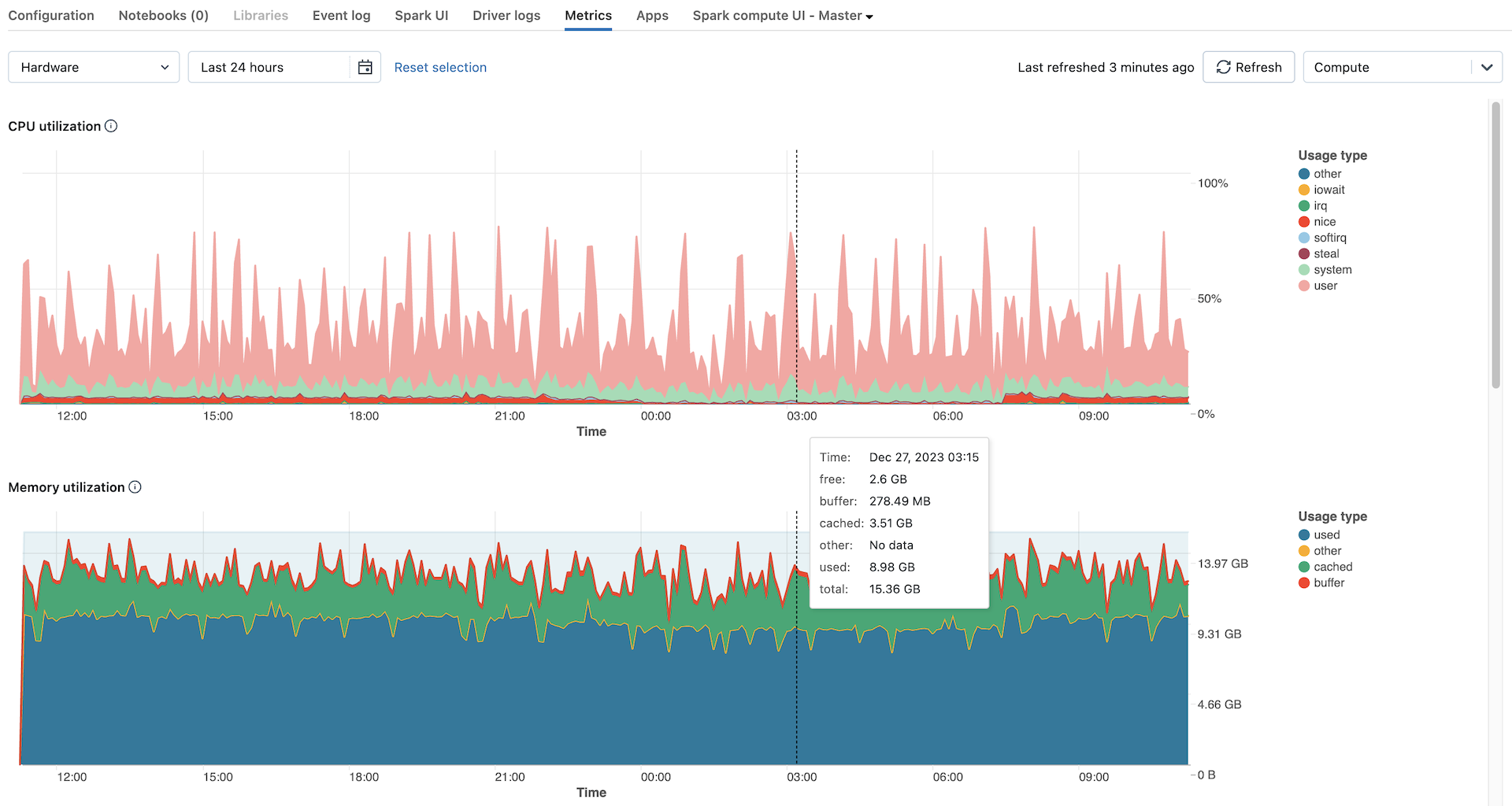
默认情况下会显示所有节点的硬件指标。 若要查看 Spark 指标,请单击标有“硬件”的下拉菜单并选择“Spark”。 如果实例启用了 GPU,也可以选择 GPU。
按时间段筛选指标
可以通过使用日期选取器筛选器选择时间范围来查看历史指标。 指标每分钟收集一次,因此你可以按过去 30 天内的任何日期、小时或分钟范围进行筛选。 单击日历图标以从预定义的数据范围中进行选择,或者在文本框内单击以定义自定义值。
注意
图表中显示的时间间隔会根据你正在查看的时间长度进行调整。 大多数指标是基于当前查看的时间间隔的平均值。
还可以通过单击“刷新”按钮获取最新指标。
查看节点级别的指标
默认情况下,指标页显示群集内所有节点(包括驱动程序)在时间段内平均的指标。
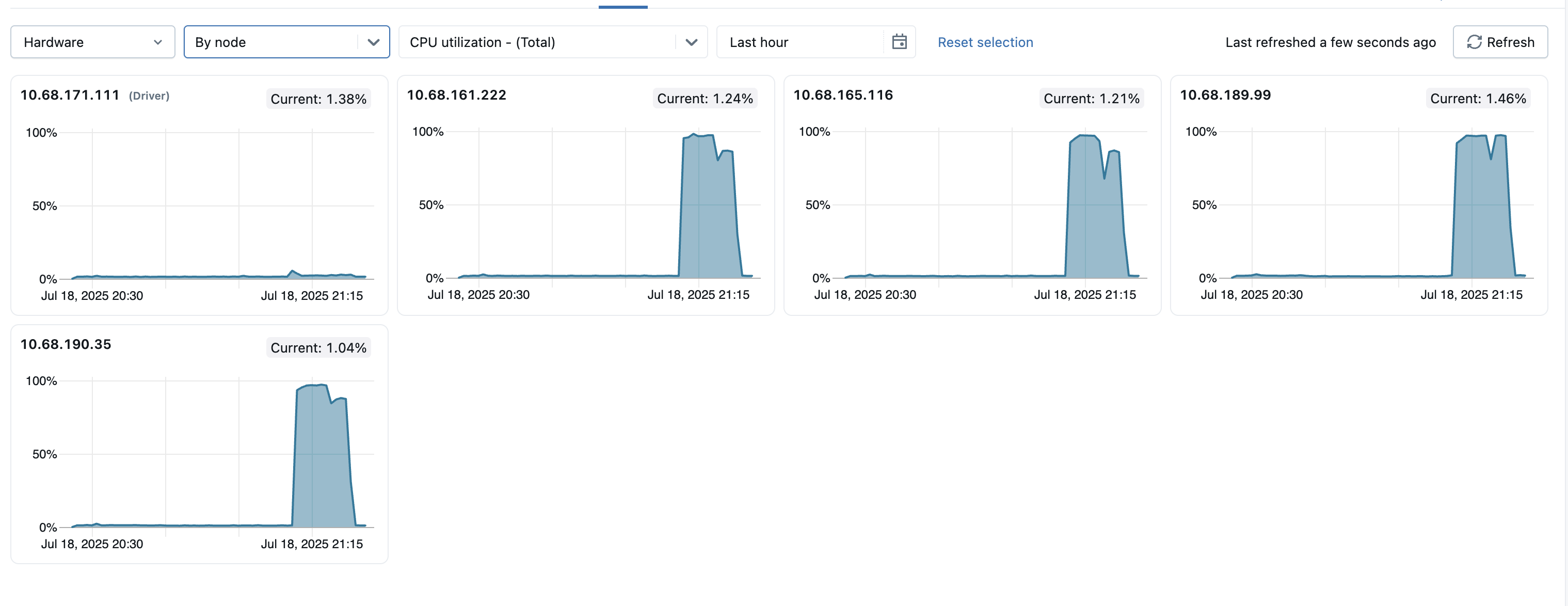
可以通过单击“ 所有节点 ”下拉菜单并选择要查看其指标的节点来查看各个节点的指标。 GPU 指标仅在单个节点级别可用。 不会为单个节点提供 Spark 指标。
为了帮助识别群集中的任何离群节点,还可以在单个页面上查看所有单个节点的指标。 若要访问此视图,请单击“ 所有节点 ”下拉菜单,然后选择“ 按节点”,然后选择要查看的指标子类别。
硬件指标图表
可以在计算指标 UI 中查看以下硬件指标图表:
-
CPU 使用率和活动节点:折线图显示给定计算的每个时间戳的活动节点数。 条形图根据总 CPU 秒成本显示每个模式下 CPU 花费的时间百分比。 以下是受跟踪的模式:
-
guest:如果运行的是 VM,则这些 VM 使用的 CPU -
iowait:等待 I/O 所花费的时间 -
idle:CPU 没有作用的时间 -
irq:中断请求花费的时间 -
nice:具有积极性的进程使用的时间,这意味着优先级比其他任务低 -
softirq:软件中断请求花费的时间 -
steal:如果你是 VM,其他 VM 从你的 CPU 资源中“偷走”的时间 -
system:内核中花费的时间 -
user:在用户环境中花费的时间
-
-
容器内存使用情况:Spark 容器消耗的内存,在所有适用节点中均平均值。 包括不可回收内存(
Container memory used)、OS 文件页缓存(Container memory file cache)和配置的内存限制(Container memory limit) 的平均值。 - JVM 堆使用情况:JVM 堆内存使用量,在所有适用节点中平均。 包括实际堆使用情况、堆容量和配置的最大堆限制的平均值。
- 网络接收和传输:每个设备通过网络接收和传输的字节数。
- 可用文件系统空间:每个装入点的文件系统总使用量(以字节为单位)。
单击“硬件”选项卡底部的“节点内存使用情况”以展开以下附加图表:
-
内存利用率和交换:折线图按模式显示总内存交换使用量(以字节为单位)。 条形图按模式显示总内存使用量(以字节为单位)。 将跟踪以下使用类型:
-
used:使用的 OS 级内存总量,包括计算上运行的后台进程使用的内存。 由于驱动程序和后台进程利用内存,即使没有运行 Spark 作业,使用情况仍会出现。 -
other:用于used、buffer或cached之外用途的内存 -
buffer:内核缓冲区使用的内存 -
cached:操作系统级别的文件系统缓存使用的内存 -
free:未使用的内存。 在图表中未归入上述类别的任何内容都是免费的。
-
Spark 指标图表
可以在计算指标 UI 中查看以下 Spark 指标图表:
- 服务器负载分布:这些磁贴显示过去一分钟内计算资源中每个节点的 CPU 使用率。 每个磁贴都是指向单个节点指标页的可单击链接。
- 活动任务:在任何给定时间执行的任务总数。
- 失败任务总数:执行器中失败的任务总数。
- 完成的任务总数:执行器中已完成的任务总数。
- 任务总数:执行程序中的所有任务(正在运行、失败和已完成)的总数。
-
随机读取总数:随机读取数据的总大小(以字节为单位)。
Shuffle read表示某个阶段开始时所有执行程序上的序列化读取数据总和。 -
总随机写入: 随机写入数据的总大小(以字节为单位)。
Shuffle Write是在传输之前(通常是某个阶段结束时)所有执行程序上所有写入序列化数据的总和。 - 总任务持续时间:JVM 在执行器上执行任务所用的总运行时间(以秒为单位)。
GPU 指标图表
注意
GPU 指标仅适用于 Databricks Runtime ML 13.3 及更高版本。
可以在计算指标 UI 中查看以下 GPU 指标图表:
- 服务器负载分布:此图表显示每个节点在过去一分钟内的 CPU 利用率。
- Per-GPU 解码器利用率:GPU 解码器利用率的百分比。
- Per-GPU 编码器利用率:GPU 编码器利用率的百分比。
- Per-GPU 帧缓冲区内存利用率字节:帧缓冲区内存利用率(以字节为单位)。
- Per-GPU 内存利用率:GPU 内存利用率的百分比。
- Per-GPU 利用率:GPU 利用率的百分比。
疑难解答
如果一段时间内的指标不完整或缺失,可能是以下问题之一:
- 负责查询和存储指标的 Databricks 服务发生中断。
- 客户方的网络问题。
- 计算处于运行不正常状态。