精细访问控制允许使用视图、行筛选器和列掩码限制对特定数据的访问。 本页介绍了如何使用无服务器计算对专用计算资源强制实施精细访问控制。
注释
专用计算是配置有 专用 访问模式(以前是单用户访问模式)的通用计算或作业计算。 请参阅访问模式。
要求
若要使用专用计算查询具有精细访问控制的视图或表,请执行以下作:
- 专用计算资源必须位于 Databricks Runtime 15.4 LTS 或更高版本上。
- 必须为作业、笔记本和 Lakeflow 声明性管道的无服务器计算启用工作区。
如果专用计算资源和工作区满足这些要求,则会自动运行数据筛选。
数据筛选在专用计算上的工作原理
每当查询访问具有精细访问控制的数据库对象时,专用计算资源都会将查询传递给工作区的无服务器计算来执行数据筛选。 然后使用工作区内部云存储上的临时文件在无服务器计算和专用计算之间传输筛选的数据。
此功能适用于以下数据库对象:
- 动态视图
- 具有 行筛选器或列掩码的表
- 在用户没有 特权的表上构建的
SELECT - 具体化视图
- 流式处理表
在下图中,用户在SELECT、table_1、以及view_2上具有权限,并且table_w_rls上应用了行筛选器。 用户在SELECT上没有table_2权限,该权限由view_2引用。

table_1 上的查询完全由专用计算资源处理,因为不需要筛选。 对 view_2 和 table_w_rls 的查询需要执行数据筛选才能返回用户有权访问的数据。 这些查询由无服务器计算上的数据筛选功能进行处理。
支持写操作
重要
此功能目前以公共预览版提供。
在 Databricks Runtime 16.3 及更高版本中,可以使用以下选项写入应用行筛选器或列掩码的表:
- MERGE INTO SQL 命令,可用于实现
INSERT和UPDATEDELETE功能。 - Delta 合并操作。
DataFrame.write.mode("append")API。
若要实现INSERT、UPDATE和DELETE功能,可以使用临时表以及MERGE INTO语句的WHEN MATCHED和WHEN NOT MATCHED子句。
下面是使用 UPDATE 的 MERGE INTO 示例:
MERGE INTO target_table AS t
USING source_table AS s
ON t.id = s.id
WHEN MATCHED THEN
UPDATE SET
t.column1 = s.column1,
t.column2 = s.column2;
下面是使用 INSERT 的 MERGE INTO 示例:
MERGE INTO target_table AS t
USING source_table AS s
ON t.id = s.id
WHEN NOT MATCHED THEN
INSERT (id, column1, column2) VALUES (s.id, s.column1, s.column2);
下面是使用 MERGE INTO 的 DELETE 示例:
MERGE INTO target_table AS t
USING source_table AS s ON t.id = s.id
WHEN MATCHED AND s.some_column = TRUE THEN DELETE;
无服务器计算成本
对于执行数据筛选作的无服务器计算资源,客户需付费。 有关定价信息,请参阅平台层和加载项。
具有访问权限的用户可以查询 system.billing.usage 表以查看已收取的费用。 例如,以下查询按用户细分计算成本:
SELECT usage_date,
sku_name,
identity_metadata.run_as,
SUM(usage_quantity) AS `DBUs consumed by FGAC`
FROM system.billing.usage
WHERE usage_date BETWEEN '2024-08-01' AND '2024-09-01'
AND billing_origin_product = 'FINE_GRAINED_ACCESS_CONTROL'
GROUP BY 1, 2, 3 ORDER BY 1;
查看启用数据筛选时的查询性能
专用计算的 Spark UI 显示可用于了解查询性能的指标。 对于你针对计算资源运行的每个查询,“SQL/数据帧”选项卡会显示查询的图形表示形式。 如果查询涉及数据筛选,则 UI 会在图形底部显示“RemoteSparkConnectScan”操作程序节点。 该节点显示了可用于调查查询性能的指标。 请参阅在 Apache Spark UI 中查看计算信息。
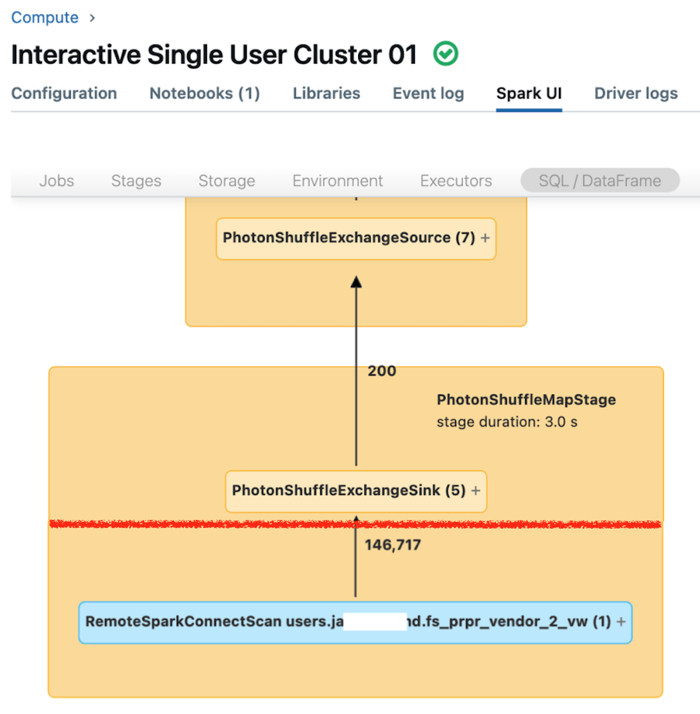
展开“RemoteSparkConnectScan”操作程序节点,查看可解决以下问题的指标:
- 数据筛选花费了多长时间? 查看“总远程执行时间”。
- 数据筛选后还剩下多少行? 查看“行输出”。
- 数据筛选后返回了多少数据(以字节为单位)? 查看“行数输出大小”。
- 有多少数据文件已经过分区修剪,因此不必从存储中读取? 查看“已删除的文件”和“已删除文件的大小”。
- 有多少数据文件无法修剪,因此必须从存储中读取? 查看“已读取的文件”和“已读取文件的大小”。
- 在必须读取的文件中,有多少个文件已在缓存中? 查看“缓存命中大小”和“缓存未命中大小”。
限制
流表仅支持批量读取。 具有行筛选器或列掩码的表不支持专用计算上的流式处理工作负荷。
无法修改默认目录 (
spark.sql.catalog.spark_catalog)。在 Databricks Runtime 16.2 及更低版本中,不支持对应用行筛选器或列掩码的表执行写入或刷新表作。
具体而言,不支持 DML 操作,例如
INSERT、DELETE、UPDATE、REFRESH TABLE和MERGE。 您只能读取这些表中的数据 (SELECT)。在 Databricks Runtime 16.3 及更高版本中,诸如
INSERT、DELETE和UPDATE的写入表操作不受支持,但可以使用受支持的MERGE来完成。在 Databricks Runtime 16.2 及更低版本中,在调用数据筛选时,默认会阻止自联接,因为这些查询可能会返回同一远程表的不同快照。 要启用这些查询,可以在运行这些命令的计算设备上将
spark.databricks.remoteFiltering.blockSelfJoins设置为false。在 Databricks Runtime 16.3 及更高版本中,快照在专用和无服务器计算资源之间自动同步。 正因为此同步,使用数据筛选功能的自联接查询会返回相同的快照,并默认启用。 例外情况是具体化视图,以及使用 Delta Sharing 共享的任何视图、具体化视图和流式处理表。 对于这些对象,默认情况下会阻止自联接,但可以通过在运行这些命令的计算上设置为
spark.databricks.remoteFiltering.blockSelfJoinsfalse 来启用这些查询。如果为具体化视图以及任何视图、具体化视图和流式处理表启用自联接查询,则必须确保没有对要联接的对象的并发写入。
- Docker 映像中不支持。
- 使用 Databricks 容器服务时,不提供支持。
- 如果在 2024 年 11 月之前使用防火墙部署工作区,则必须打开端口 8443 和 8444,才能在专用计算上启用精细访问控制。 请参阅 网络安全组规则。