本文介绍如何配置 Azure Databricks 连接,以读取和写入 Google Cloud Storage (GCS) 上存储的表和数据。
若要从 GCS 存储桶读取或写入,必须创建附加的服务帐户,并且必须将存储桶与服务帐户相关联。 可以使用为服务帐户生成的密钥直接连接到存储桶。
使用 Google 云服务帐户密钥直接访问 GCS 存储桶
若要直接读取和写入存储桶,请配置 Spark 配置中定义的密钥。
步骤 1:使用 Google Cloud 控制台设置 Google Cloud 服务帐户
必须为 Azure Databricks 群集创建服务帐户。 Databricks 建议对此服务帐户授予执行其任务所需的最低权限。
在左侧导航窗格中单击“IAM 和管理员”。
单击“服务帐户”。
单击“+ 创建服务帐户”。
输入服务帐户名称和说明。
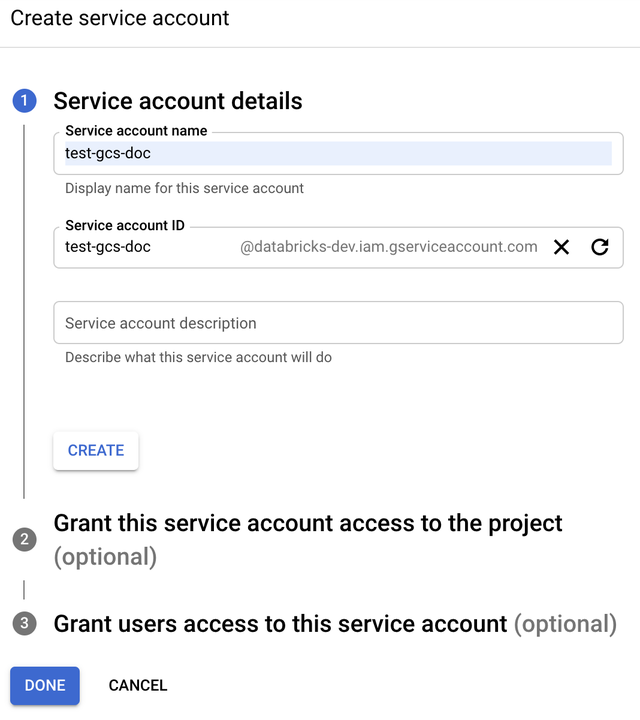
单击“创建”。
单击“继续”。
单击“完成”。
步骤 2:创建密钥以直接访问 GCS 存储桶
警告
为服务帐户生成的 JSON 密钥是一个私钥,它应只与授权用户共享,因为它控制对 Google Cloud 帐户中数据集和资源的访问。
- 在 Google Cloud 控制台的服务帐户列表中,单击新创建的帐户。
- 在“密钥”部分中,单击“添加密钥”“创建新密钥”。
- 接受 JSON 密钥类型。
- 单击“创建”。 密钥文件会下载到你的计算机。
步骤 3:配置 GCS 存储桶
创建存储桶
如果还没有存储桶,请创建一个:
在左侧导航列中,单击“存储”。
单击“创建存储桶”。
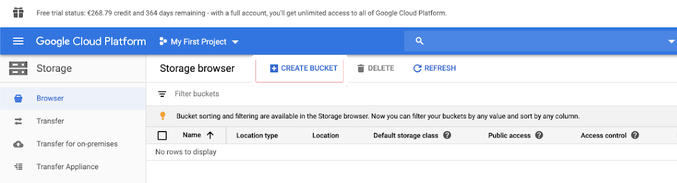
单击“创建”。
配置存储桶
配置存储桶详细信息。
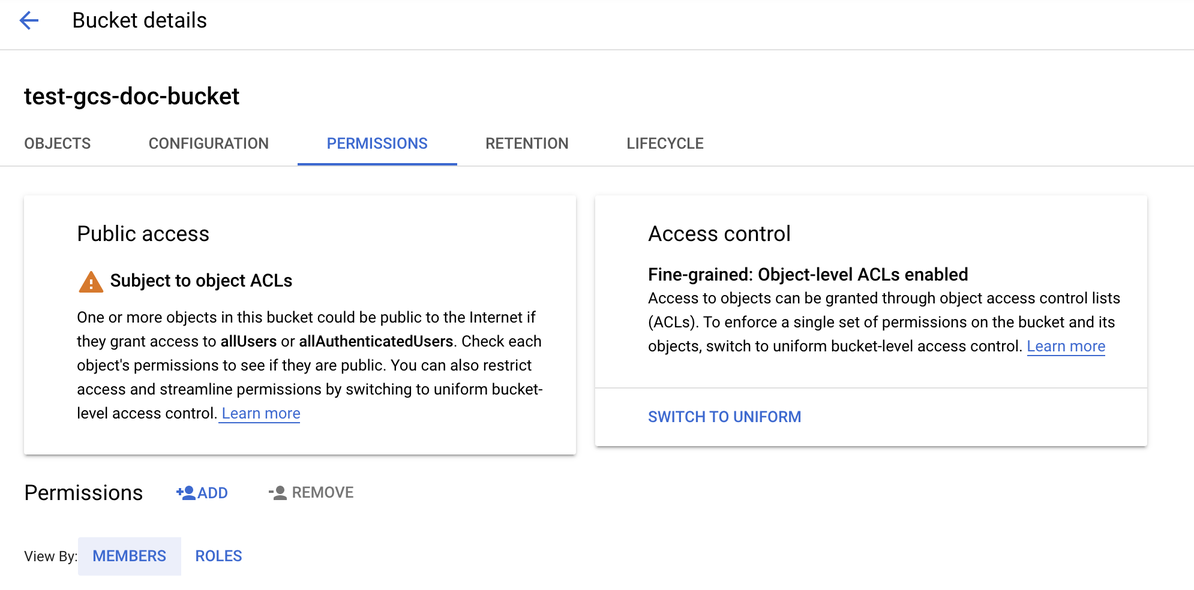
单击“权限”选项卡。
在“权限”标签旁边,单击“添加”。
向 Cloud Storage 角色中的存储桶上的服务帐户提供“存储管理员”权限。
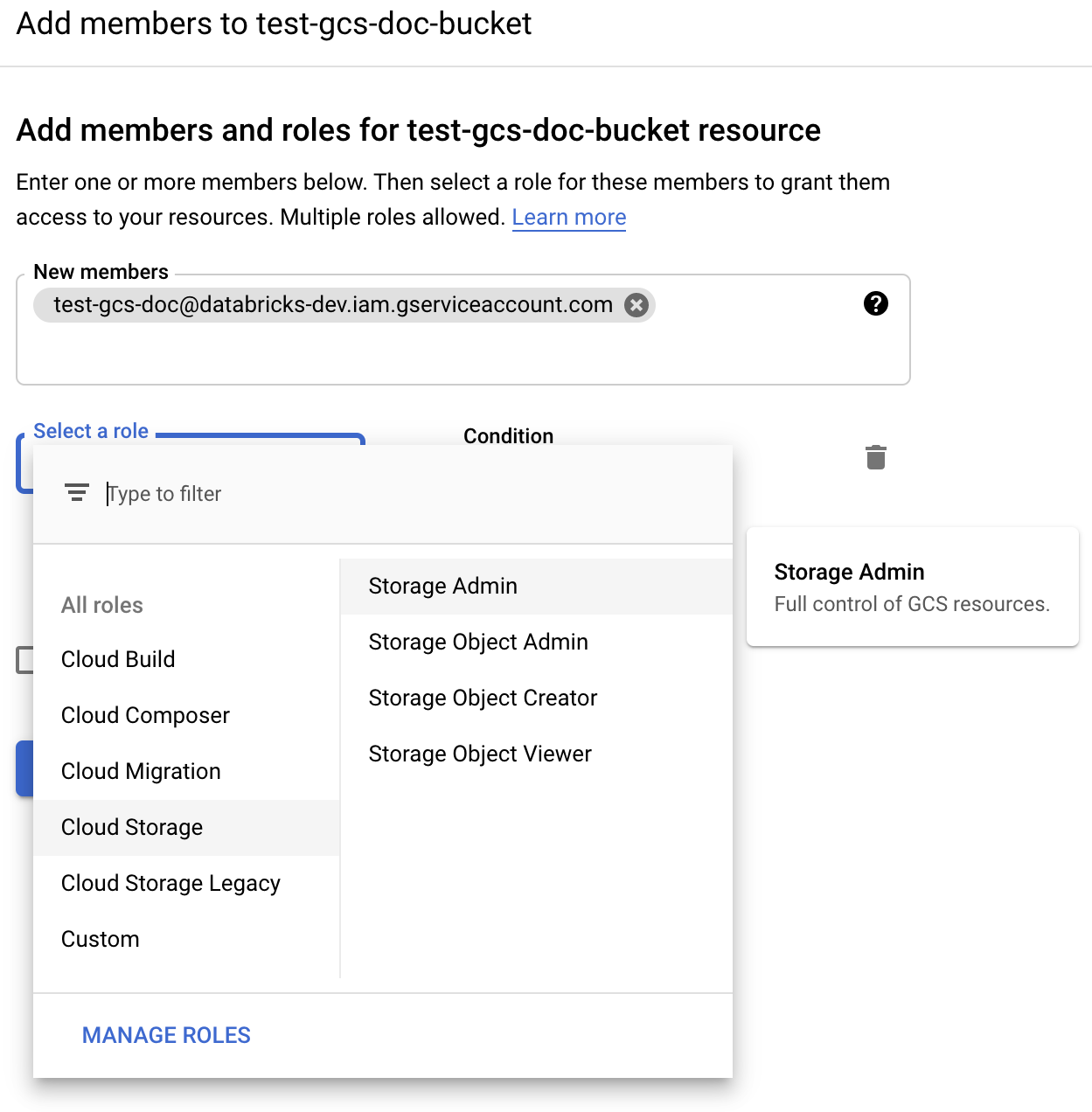
单击“保存”。
步骤 4:将服务帐户密钥放入 Databricks 机密中
Databricks 建议使用机密范围来存储所有凭据。 可以将密钥 JSON 文件中的私钥和私钥 ID 放入 Databricks 机密范围。 可以向工作区中的用户、服务主体和组授予读取机密范围的访问权限。 这可以保护服务帐户密钥,同时允许用户访问 GCS。 若要创建机密范围,请参阅 “管理机密”。
步骤 5:配置 Azure Databricks 群集
在“Spark 配置”选项卡中,配置全局配置或每存储桶配置。 以下示例使用存储为 Databricks 机密的值来设置密钥。
注意
使用群集访问控制和笔记本访问控制来保护对服务帐户和 GCS 存储桶中数据的访问。 请参阅计算权限和使用 Databricks 笔记本进行协作。
全局配置
如果应使用提供的凭证访问所有存储桶,请使用此配置。
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id {{secrets/scope/gsa_private_key_id}}
将 <client-email> 和 <project-id> 替换为你的密钥 JSON 文件中的这些确切字段名称的值。
每个桶的配置
如果必须为特定存储桶配置凭证,请使用此配置。 每存储桶配置的语法是将存储桶名称追加到每个配置的末尾,如下例所示。
重要
除了全局配置之外,还可以使用每存储桶配置。 指定每存储桶配置后,该配置将取代全局配置。
spark.hadoop.google.cloud.auth.service.account.enable.<bucket-name> true
spark.hadoop.fs.gs.auth.service.account.email.<bucket-name> <client-email>
spark.hadoop.fs.gs.project.id.<bucket-name> <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key.<bucket-name> {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id.<bucket-name> {{secrets/scope/gsa_private_key_id}}
将 <client-email> 和 <project-id> 替换为你的密钥 JSON 文件中的这些确切字段名称的值。
步骤 6:从GCS 读取
若要从 GCS 存储桶读取,请使用任何受支持格式的 Spark 读取命令,例如:
df = spark.read.format("parquet").load("gs://<bucket-name>/<path>")
若写入 GCS 存储桶,请使用任何受支持格式的 Spark 读取命令,例如:
df.write.mode("<mode>").save("gs://<bucket-name>/<path>")
将 <bucket-name> 替换为在步骤 3:配置 GCS 存储桶中创建的存储桶的名称。