本教程将指导你设置用于Visual Studio Code的 Databricks 扩展,然后在Azure Databricks群集上运行Python,并在远程工作区中作为Azure Databricks作业运行。 请参阅 Visual Studio Code 的 Databricks 扩展。
要求
本教程要求:
- 你已安装用于Visual Studio Code的 Databricks 扩展。 请参阅 在 Visual Studio Code 中安装 Databricks 扩展。
- 您有一个远程的 Azure Databricks 集群可供使用。 记下群集的名称。 若要查看可用的群集,请在Azure Databricks工作区边栏中单击Compute。 请参阅计算。
步骤 1:创建新的 Databricks 项目
在此步骤中,你将创建新的 Databricks 项目,并配置与远程Azure Databricks工作区的连接。
- 启动Visual Studio Code,然后单击File >打开文件夹并在本地开发计算机上打开一些空文件夹。
- 在边栏上,单击“Databricks”徽标图标。 这将打开 Databricks 扩展。
- 在“配置”视图中,单击“创建配置”。
- 此时会打开用于配置 Databricks 工作区的“命令面板”。 对于“Databricks 主机”,请输入或选择每个工作区的 URL,例如
https://adb-1234567890123456.7.azuredatabricks.net。 - 为项目选择一个身份验证配置文件。 请参阅 为 Visual Studio Code 的 Databricks 扩展设置授权。
步骤 2:将群集信息添加到 Databricks 扩展并启动群集
在已打开的“配置”视图中,单击“选择群集”或单击齿轮(“配置群集”)图标。
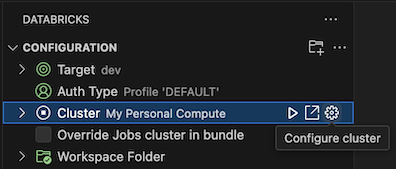
在“命令面板”中,选择之前创建的群集的名称。
如果尚未启动,请单击播放图标(“启动群集”)。
步骤 3:创建并运行Python代码
创建本地Python代码文件:在边栏上,单击文件夹(Explorer)图标。
在主菜单上,单击File >新建文件并选择Python文件。 将文件 命名为 demo.py ,并将其保存到项目的根目录中。
将以下代码添加到文件,然后将其保存。 此代码将创建并显示基本 PySpark 数据帧的内容:
from pyspark.sql import SparkSession from pyspark.sql.types import * spark = SparkSession.builder.getOrCreate() schema = StructType([ StructField('CustomerID', IntegerType(), False), StructField('FirstName', StringType(), False), StructField('LastName', StringType(), False) ]) data = [ [ 1000, 'Mathijs', 'Oosterhout-Rijntjes' ], [ 1001, 'Joost', 'van Brunswijk' ], [ 1002, 'Stan', 'Bokenkamp' ] ] customers = spark.createDataFrame(data, schema) customers.show()# +----------+---------+-------------------+ # |CustomerID|FirstName| LastName| # +----------+---------+-------------------+ # | 1000| Mathijs|Oosterhout-Rijntjes| # | 1001| Joost| van Brunswijk| # | 1002| Stan| Bokenkamp| # +----------+---------+-------------------+单击编辑器选项卡列表旁边的“在 Databricks 上运行”图标,然后单击“上传并运行文件”。 输出将显示在“调试控制台”视图中。
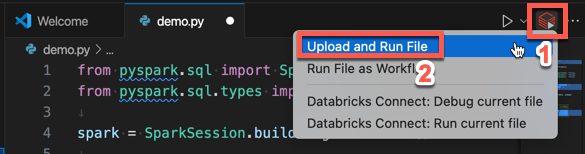
或者,在“资源管理器”视图中,右键单击
demo.py文件,然后单击“在 Databricks 上运行”>“上传和运行文件”。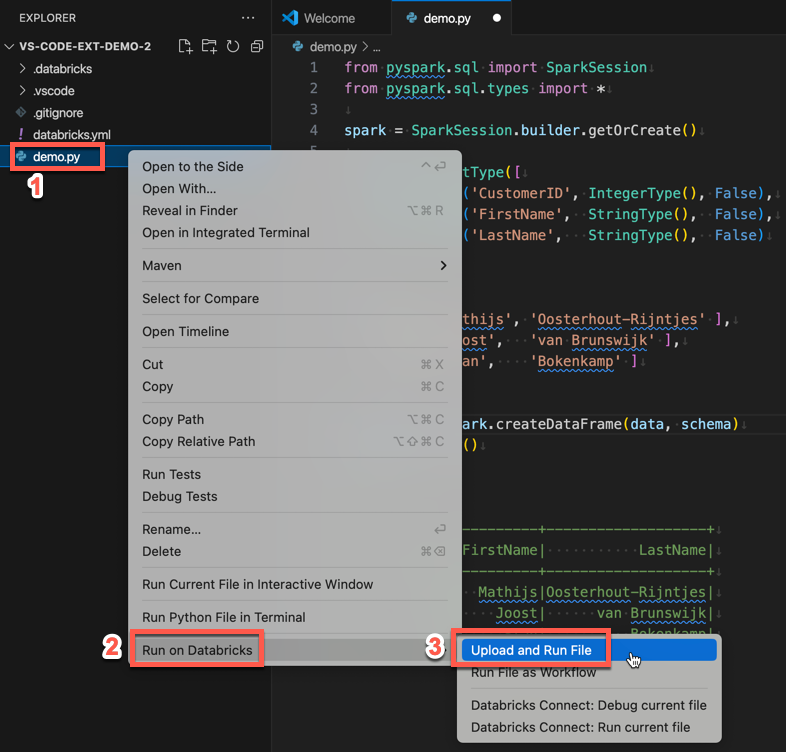
步骤 4:将代码作为作业运行
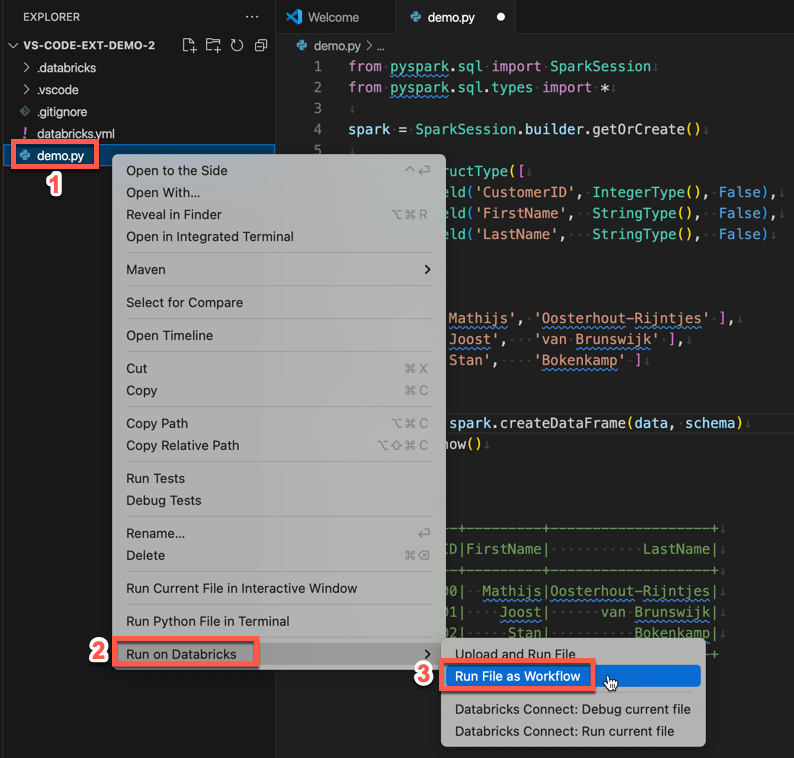
若要作为作业运行 demo.py,请单击编辑器选项卡列表旁边的“在 Databricks 上运行”图标,然后单击“将文件作为工作流运行”。 输出会显示在 demo.py 文件编辑器旁边单独的编辑器选项卡中。
![]()
或者,右键单击资源管理器面板中的 demo.py 文件,然后选择“在 Databricks 上运行”“将文件作为工作流运行”。
后续步骤
现已成功使用 Databricks 扩展用于 Visual Studio Code 上传本地 Python 文件并远程运行,您还可以:
- 通过扩展 UI 探索声明式自动化捆绑包的资源和变量。 请参阅 声明性自动化捆绑包扩展功能。
- 使用 Databricks Connect 运行或调试Python代码。 请参阅 在 Visual Studio Code 的 Databricks 插件中使用 Databricks Connect 调试代码。
- 以Azure Databricks作业的形式运行文件或笔记本。 请参阅 使用 Visual Studio Code 的 Databricks 扩展程序在 Azure Databricks 中,将文件或笔记本作为作业运行在群集上。
- 使用
pytest运行测试。 请参阅 使用 Databricks 扩展在 Visual Studio Code 中运行 Python 测试。