重要
本页介绍 MLflow 2 的代理评估版本的 0.22 用法。 Databricks 建议使用 MLflow 3,它与代理评估 >1.0 集成。 在 MLflow 3 中,代理评估 API 现在是包的 mlflow 一部分。
有关本主题的信息,请参阅 “查看应用”。
本文介绍如何使用评审应用从主题专家(SME)收集反馈。 可以使用审核应用执行以下操作:
- 让利益干系人能够与预生产生成 AI 应用聊天并提供反馈。
- 在 Unity 目录中创建由 Delta 表支持的评估数据集。
- 利用 SME 来扩展和迭代该评估数据集。
- 利用 SME 来标记生产轨迹,以了解生成式 AI 应用的质量。
人工评估的过程中会发生什么?
Databricks 审查应用会搭建一个环境,相关人员可以与之互动,换句话说,可以进行对话、提问、提供反馈等。
使用评审应用有两种主要方法:
- 与机器人聊天:在推理表中收集问题、答案和反馈,以便可以进一步分析第一代 AI 应用的性能。 这样,评审应用有助于确保应用程序提供的答案的质量和安全性。
- 会话中的标签响应:收集标签会话中中小企业的反馈和期望,这些 反馈 和 期望 存储在 MLFLow 运行下。 可以选择将这些标签同步到评估数据集。
要求
- 开发人员必须安装
databricks-agentsSDK 才能设置权限并配置评审应用。
%pip install databricks-agents
dbutils.library.restartPython()
- 若要与机器人聊天:
- 对于标记会话:
- 每位审阅者都必须拥有访问评审应用工作区的权限。
设置权限以使用评审应用
注释
- 若要与机器人聊天,人工审阅者 不需要 访问工作区。
- 对于标记会话,人工审阅者需要访问工作区。
设置“与机器人聊天”的权限
- 对于无权访问工作区的用户,帐户管理员使用帐户级 SCIM 预配将用户和组从标识提供者自动同步到 Azure Databricks 帐户。 还可以在 Databricks 中设置标识时手动注册这些用户和组,以授予他们访问权限。 请参阅使用 SCIM 从 Microsoft Entra ID 同步用户和组。
- 对于已有权访问包含评审应用的工作区的用户,无需进行其他配置。
下面的代码示例演示如何向用户授予通过 agents.deploy部署的模型的权限。 该 users 参数采用电子邮件地址列表。
from databricks import agents
# Note that <user_list> can specify individual users or groups.
agents.set_permissions(model_name=<model_name>, users=[<user_list>], permission_level=agents.PermissionLevel.CAN_QUERY)
注释
若要为工作区中的所有用户授予权限,请设置 users=["users"]。
设置标记会话的权限
创建标记会话时提供assigned_users参数,会自动向用户授予相应的权限(对试验的写入访问权限和对数据集的读取访问权限)。
有关更多信息,请参阅下文创建标记会话并发送以供审核。
创建评审应用
自动使用 agents.deploy()
使用 agents.deploy()部署 Gen AI 应用时,将自动启用和部署评审应用。 命令的输出显示评审应用的 URL。 有关部署 gen AI 应用(也称为“代理”)的信息,请参阅 为生成式 AI 应用程序部署代理。
注释
只有在端点完全部署后,代理才会显示在审查应用程序的 UI 中。
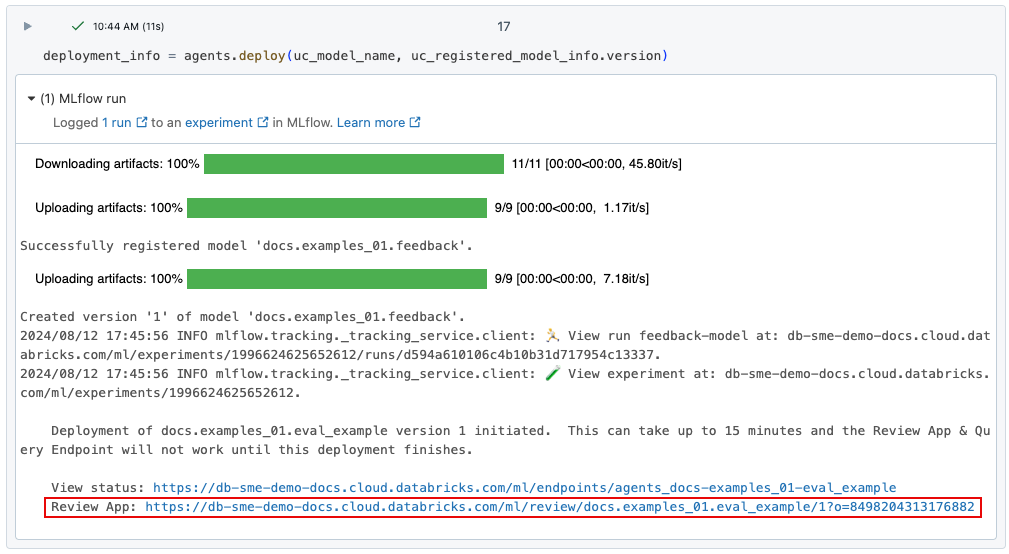
如果您丢失了评审应用 UI 的链接,可以使用 get_review_app() 找到它。
import mlflow
from databricks.agents import review_app
# The review app is tied to the current MLFlow experiment.
mlflow.set_experiment("same_exp_used_to_deploy_the_agent")
my_app = review_app.get_review_app()
print(my_app.url)
print(my_app.url + "/chat") # For "Chat with the bot".
手动使用 Python API
下面的代码片段演示如何创建评审应用并将其与用于与机器人聊天的模型服务终结点相关联。 有关如何创建标记会话,请参阅
- 创建标记会话并发送以供评审,以便标记评估数据集。
- 收集有关跟踪记录的反馈,以便标记跟踪记录。 请注意,这不需要真人客服。
from databricks.agents import review_app
# The review app is tied to the current MLFlow experiment.
my_app = review_app.get_review_app()
# TODO: Replace with your own serving endpoint.
my_app.add_agent(
agent_name="llama-70b",
model_serving_endpoint="databricks-meta-llama-3-3-70b-instruct",
)
print(my_app.url + "/chat") # For "Chat with the bot".
概念
数据集
数据集 是用于评估 gen AI 应用程序的示例集合。 数据集记录包含生成式 AI 应用程序的输入,并选择性地包含预期(真实标签,例如 或 expected_facts)。guidelines 数据集与 MLFlow 实验关联,且可直接用作 mlflow.evaluate() 的输入。 数据集由 Unity 目录中的 Delta 表提供支持,继承 Delta 表定义的权限。 若要创建数据集,请参阅 创建数据集。
示例评估数据集,仅显示输入和期望列:

评估数据集具有以下架构:
| 列 | 数据类型 | 说明 |
|---|---|---|
| 数据集记录编号 | 字符串 | 记录的唯一标识符。 |
| 输入 | 字符串 | 作为 json 序列化 dict<str, Any> 的评估输入。 |
| 期望值 | 字符串 | 作为 json 序列化 dict<str, Any> 的预期值。 expectations具有用于 LLM 法官的预留键,例如guidelines、expected_facts和expected_response。 |
| create_time | 时间戳 | 创建记录的时间。 |
| created_by | 字符串 | 创建记录的用户。 |
| 最新更新时间 | 时间戳 | 上次更新记录的时间。 |
| last_updated_by | 字符串 | 上次更新记录的用户。 |
| 源 | 结构 | 数据集记录的源。 |
| source.human | 结构 | 当源来自人类时定义。 |
| source.human.user_name | 字符串 | 与记录关联的用户的名称。 |
| source.document | 字符串 | 从文档合成记录时定义。 |
| source.document.doc_uri | 字符串 | 文档的 URI。 |
| source.document.content | 字符串 | 文档的内容。 |
| source.trace | 字符串 | 根据跟踪创建记录时定义。 |
| source.trace.trace_id | 字符串 | 跟踪的唯一标识符。 |
| 标记 | 地图 | 数据集记录的键值标记。 |
标记会话
LabelingSession 是一组有限的跟踪或数据集记录,由 SME 在审核应用 UI 中进行标记。 跟踪可以来自生产环境中的应用程序的推断表,也可以来自 MLFlow 实验中的离线跟踪。 结果以 MLFlow 运行的形式存储。 标签作为 Assessment 存储在 MLFlow 跟踪中。 具有“预期”的标签可以同步回评估数据集。
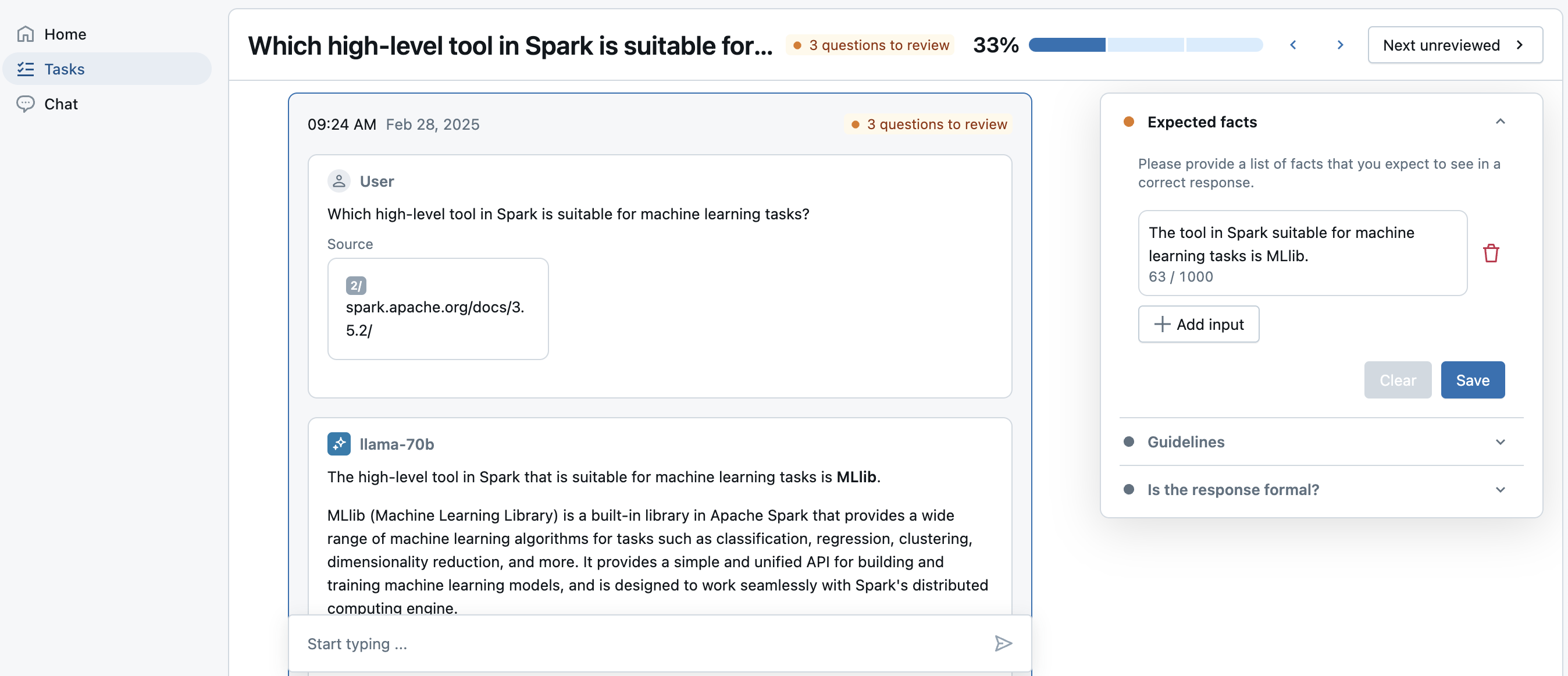
评估和标签
当 SME 为跟踪添加标签时,评估会写入 Trace.info.assessments 字段下的跟踪中。 Assessment可以有两种形式:
expectation:表示正确跟踪所具有的标签。 例如:expected_facts可用作expectation标签,表示理想响应中应存在的事实。 可以将这些expectation标签同步回评估数据集,以便将其与mlflow.evaluate()一起使用。feedback:表示对跟踪提供简单反馈的标签,例如“点赞”和“点踩”,或自由形式的评论。Assessment类型的feedback不与评估数据集一起使用,因为它们是对特定 MLFLow 跟踪的人工评估。 可以使用mlflow.search_traces()读取这些评估。
数据集
本部分介绍如何执行以下作:
- 创建数据集并将其用于评估,而无需 SME。
- 向 SME 请求标记会话,以策展更好的评估数据集。
创建数据集
以下示例创建 数据集 并插入评估。 若要向数据集添加合成评估,请参阅 合成评估集。
from databricks.agents import datasets
import mlflow
# The following call creates an empty dataset. To delete a dataset, use datasets.delete_dataset(uc_table_name).
dataset = datasets.create_dataset("cat.schema.my_managed_dataset")
# Optionally, insert evaluations.
# The `guidelines` specified here are saved to the `expectations` field in the dataset.
eval_set = [{
"request": {"messages": [{"role": "user", "content": "What is the capital of France?"}]},
"guidelines": ["The response must be in English", "The response must be clear, coherent, and concise"],
}]
dataset.insert(eval_set)
此数据集中的数据由 Unity 目录中的 Delta 表提供支持,在目录资源管理器中可见。
注释
标记会话当前不支持命名准则(使用字典)。
使用数据集进行评估
以下示例使用评估数据集从 Unity Catalog 读取数据集,以评估一个简单的系统提示代理。
import mlflow
from mlflow.deployments import get_deploy_client
# Define a very simple system-prompt agent to test against our evaluation set.
@mlflow.trace(span_type="AGENT")
def llama3_agent(request):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={
"messages": [
{"role": "system", "content": SYSTEM_PROMPT},
*request["messages"]
]
}
)
evals = spark.read.table("cat.schema.my_managed_dataset")
mlflow.evaluate(
data=evals,
model=llama3_agent,
model_type="databricks-agent"
)
创建标记会话并发送以供审阅
以下示例使用 ReviewApp.create_labeling_session从以上数据集中创建一个 LabelingSession,并通过 guidelines 字段配置会话,以便从中小企业收集 expected_facts 和 。 还可以使用 ReviewApp.create_label_schema 创建自定义标签架构
注释
- 创建标记会话时,分配的用户为:
- 已授予对 MLFlow 试验的写入权限。
- 向与审核应用关联的任何模型服务终结点授予 QUERY 权限。
- 将数据集添加到标记会话时,已分配的用户将获得对用于初始化标记会话的数据集增量表的访问权限。
若要为工作区中的所有用户授予权限,请设置 assigned_users=["users"]。
from databricks.agents import review_app
import mlflow
# The review app is tied to the current MLFlow experiment.
my_app = review_app.get_review_app()
# You can use the following code to remove any existing agents.
# for agent in list(my_app.agents):
# my_app.remove_agent(agent.agent_name)
# Add the llama3 70b model serving endpoint for labeling. You should replace this with your own model serving endpoint for your
# own agent.
# NOTE: An agent is required when labeling an evaluation dataset.
my_app.add_agent(
agent_name="llama-70b",
model_serving_endpoint="databricks-meta-llama-3-3-70b-instruct",
)
# Create a labeling session and collect guidelines and/or expected-facts from SMEs.
# Note: Each assigned user is given QUERY access to the serving endpoint above and write access.
# to the MLFlow experiment.
my_session = my_app.create_labeling_session(
name="my_session",
agent="llama-70b",
assigned_users = ["email1@company.com", "email2@company.com"],
label_schemas = [review_app.label_schemas.GUIDELINES, review_app.label_schemas.EXPECTED_FACTS]
)
# Add the records from the dataset to the labeling session.
# Note: Each assigned user above is given SELECT access to the UC delta table.
my_session.add_dataset("cat.schema.my_managed_dataset")
# Share the following URL with your SMEs for them to bookmark. For the given review app linked to an experiment, this URL never changes.
print(my_app.url)
# You can also link them directly to the labeling session URL, however if you
# request new labeling sessions from SMEs there will be new URLs. Use the review app
# URL above to keep a permanent URL.
print(my_session.url)
此时,可以将上述 URL 发送到中小企业。
在您的 SME 进行标注时,可以使用以下代码查看标注的状态:
mlflow.search_traces(run_id=my_session.mlflow_run_id)
将标签会话期望同步回数据集
SME 完成标记后,可以使用 expectation 将 标签同步回数据集。 具有类型 expectation 的标签示例包括 GUIDELINES、EXPECTED_FACTS或具有类型 expectation的自定义标签架构。
my_session.sync_expectations(to_dataset="cat.schema.my_managed_dataset")
display(spark.read.table("cat.schema.my_managed_dataset"))
现在可以使用此评估数据集:
eval_results = mlflow.evaluate(
model=llama3_agent,
data=dataset.to_df(),
model_type="databricks-agent"
)
收集有关踪迹的反馈
本部分介绍如何收集 MLFlow 跟踪对象上的标签,这些对象可能来自以下任一项:
- MLFlow 试验或运行。
- 推理表。
- 任何 MLFlow Python Trace 对象。
从 MLFlow 试验或运行中收集反馈
此示例创建一组要由中小企业标记的跟踪。
import mlflow
from mlflow.deployments import get_deploy_client
@mlflow.trace(span_type="AGENT")
def llama3_agent(messages):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={"messages": [{"role": "system", "content": SYSTEM_PROMPT}, *messages]}
)
# Create a trace to be labeled.
with mlflow.start_run(run_name="llama3") as run:
run_id = run.info.run_id
llama3_agent([{"content": "What is databricks?", "role": "user"}])
llama3_agent([{"content": "How do I set up a SQL Warehouse?", "role": "user"}])
可以获取跟踪的标签,并根据它们创建标记会话。 本示例使用单个标签架构设置标记会话,以收集有关代理响应的“形式”反馈。 SME 的标签存储为对 MLFlow 跟踪的评估。
有关更多类型的架构输入,请参阅 databricks-agents SDK。
# The review app is tied to the current MLFlow experiment.
my_app = review_app.get_review_app()
# Use the run_id from above.
traces = mlflow.search_traces(run_id=run_id)
formality_label_schema = my_app.create_label_schema(
name="formal",
# Type can be "expectation" or "feedback".
type="feedback",
title="Is the response formal?",
input=review_app.label_schemas.InputCategorical(options=["Yes", "No"]),
instruction="Please provide a rationale below.",
enable_comment=True
)
my_session = my_app.create_labeling_session(
name="my_session",
# NOTE: An `agent` is not required. If you do provide an Agent, your SME can ask follow up questions in a converstion and create new questions in the labeling session.
assigned_users=["email1@company.com", "email2@company.com"],
# More than one label schema can be provided and the SME will be able to provide information for each one.
# We use only the "formal" schema defined above for simplicity.
label_schemas=["formal"]
)
# NOTE: This copies the traces into this labeling session so that labels do not modify the original traces.
my_session.add_traces(traces)
# Share the following URL with your SMEs for them to bookmark. For the given review app, linked to an experiment, this URL will never change.
print(my_app.url)
# You can also link them directly to the labeling session URL, however if you
# request new labeling sessions from SMEs there will be new URLs. Use the review app
# URL above to keep a permanent URL.
print(my_session.url)
SME 完成标记后,生成的跟踪和评估会成为与标记会话关联的运行的一部分。
mlflow.search_traces(run_id=my_session.mlflow_run_id)
现在可以使用这些评估来改进模型或更新评估数据集。
从推理表收集反馈
此示例演示如何直接从推理表(请求负载日志)将日志痕迹添加到标记会话中。
# CHANGE TO YOUR PAYLOAD REQUEST LOGS TABLE
PAYLOAD_REQUEST_LOGS_TABLE = "catalog.schema.my_agent_payload_request_logs"
traces = spark.table(PAYLOAD_REQUEST_LOGS_TABLE).select("trace").limit(3).toPandas()
my_session = my_app.create_labeling_session(
name="my_session",
assigned_users = ["email1@company.com", "email2@company.com"],
label_schemas=[review_app.label_schemas.EXPECTED_FACTS]
)
# NOTE: This copies the traces into this labeling session so that labels do not modify the original traces.
my_session.add_traces(traces)
print(my_session.url)
示例笔记本
以下笔记本演示了在 Mosaic AI 代理评估中使用数据集和标记会话的不同方式。