重要
此功能在 Beta 版中。
本文介绍如何使用 Agent Bricks:信息提取创建用于信息提取的生成 AI 代理。
Agent Bricks 提供了一种简单的无代码方法来生成和优化特定于域的高质量 AI 代理系统,用于常见 AI 用例。
什么是 Agent Bricks:信息提取?
Agent Bricks 支持信息提取,并简化了将大量未标记的文本文档转换为结构化表格的过程,其中包含每个文档的提取信息。
信息提取的示例包括:
- 从合同中提取价格和租赁信息。
- 根据客户笔记组织数据。
- 从新闻文章中获取重要详细信息。
代理砖块:信息提取利用自动评估功能(包括 MLflow 和 代理评估)来快速评估特定提取任务的成本质量权衡。 通过此评估,可以就准确度与资源投入之间的平衡做出明智的决策。
要求
- 包含以下内容的工作区:
- 已启用 Mosaic AI Agent Bricks 预览版 (Beta)。 请参阅 “管理 Azure Databricks 预览版”。
- 已启用无服务器计算。 请参阅启用无服务器计算。
- 已启用 Unity Catalog。 请参阅为 Unity Catalog 启用工作区。
- 其中一个受支持区域中的工作区:
eastus、eastus2、westus、centralus或northcentralus。 - 通过
system.ai架构访问 Unity 目录中的基础模型。 - 通过非零预算访问无服务器预算策略。
- 能够使用
ai_querySQL 函数。 - 要从中提取数据的文件。 这些文件必须位于 Unity 目录卷或表中。
- 若要构建代理,Unity Catalog 卷中至少需有 10 个未标记的文档,或表中有 10 行记录。
- 若要优化代理(可选)步骤 4:查看和部署优化代理,必须在 Unity 目录卷中至少有 75 个未标记的文档或表中至少有 75 行。
创建信息提取代理
转到 ![]() 工作区左侧导航窗格中的代理,然后单击“ 信息提取”。
工作区左侧导航窗格中的代理,然后单击“ 信息提取”。
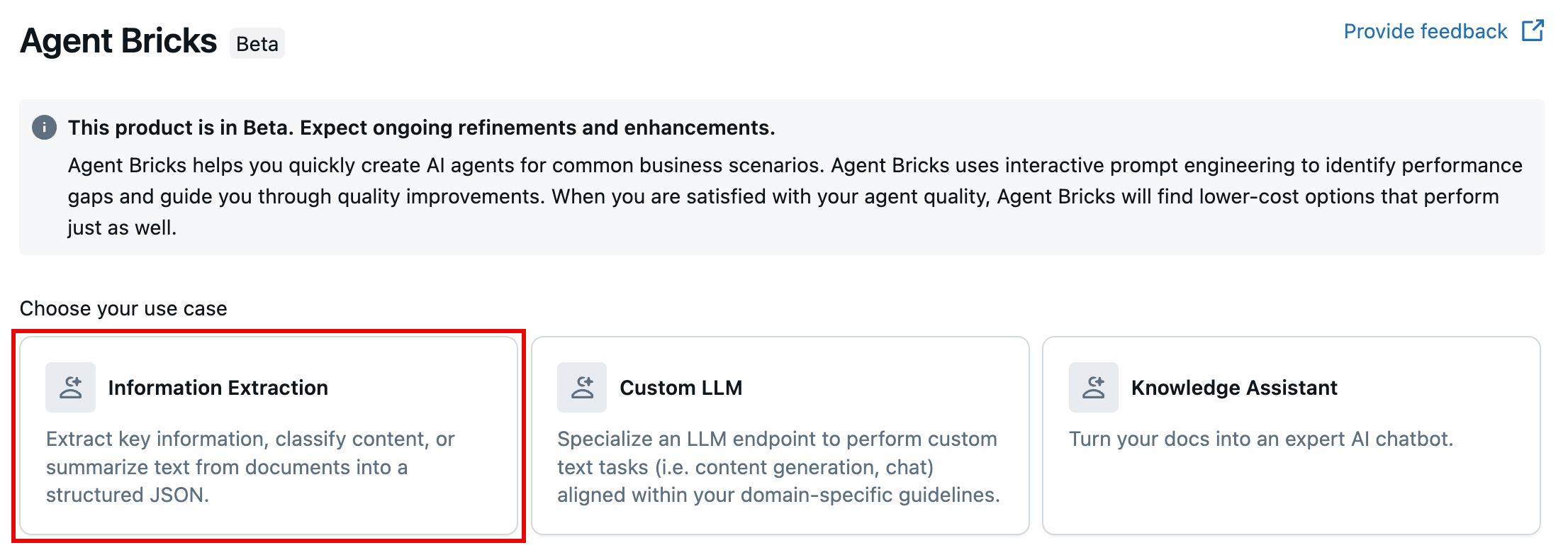
步骤 1:添加输入数据和输出示例
在“配置”选项卡上,单击“显示示例 ”以展开信息提取代理的示例输入和模型响应。>
在下面的窗格中,配置代理:
在 “源文档 ”字段中,从 Unity 目录卷中选择要使用的文件夹或表。 如果选择了表,请从下拉列表中选择包含文本数据的列。
文件夹必须包含 支持的文档格式 ,表列必须包含 支持的数据格式的数据。 此数据集用于创建代理。
下面是一个示例卷:
/Volumes/main/info-extraction/bbc_articles/在“示例输出”字段中,提供示例响应:
{ "title": "Economy Slides to Recession", "category": "Politics", "paragraphs": [ { "summary": "GDP fell by 0.1% in the last three months of 2004.", "word_count": 38 }, { "summary": "Consumer spending had been depressed by one-off factors such as the unseasonably mild winter.", "word_count": 42 } ], "tags": ["Recession", "Economy", "Consumer Spending"], "estimate_time_to_read_min": 1, "published_date": "2005-01-15", "needs_review": false }为代理提供名称。 如果不想更改它,可以保留默认名称。
选择“创建代理”。
支持的文档格式
下表显示了源文档支持的文档文件类型(如果提供 Unity 目录卷)。
| 代码文件 | 文档文件 | 日志文件 |
|---|---|---|
|
|
|
受支持的数据格式
代理砖块:如果提供 Unity 目录表,信息提取支持源文档的以下数据类型和架构。 Agent Bricks还可以从每个文档中提取这些数据类型。
strintfloatboolean- 自定义嵌套字段
- 上述数据类型的数组
步骤 2:生成和改进代理
在“ 生成 ”选项卡上的 “代理配置 ”窗格中,优化架构定义以获取更好的结果。
(可选)为代理添加全局说明,例如可应用于所有字段的提示。
调整希望代理用于输出响应的架构字段的说明。 代理依赖这些说明来了解你想要提取的内容。

单击“ 更新代理”。
在 “生成 ”选项卡的左侧,查看建议和示例输出。
根据为每个字段提供的规范查看模型输出示例。
查看用于优化代理性能的 Databricks 建议。
应用建议,并根据需要调整“代理配置”窗格中的说明和指示。
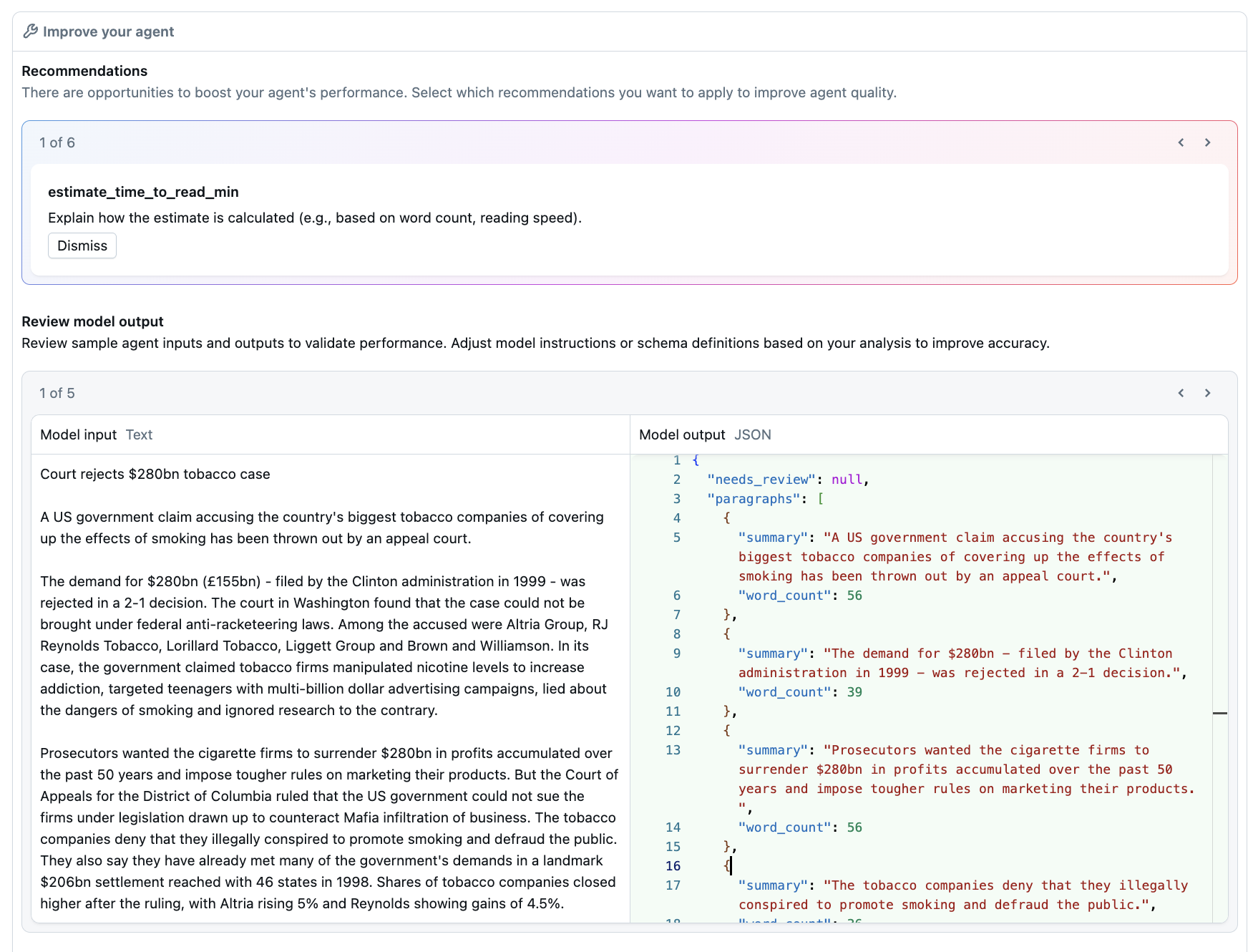
应用更改和建议后,选择“更新代理”以保存对代理所做的更改。 “改进代理”窗格将会更新,以显示新的示例模型输出。 此窗格中的建议不会更新。
现在,你已创建用于提取信息的代理。
步骤 3:使用代理
可以在 Databricks 中的工作流中使用代理。
在“使用”选项卡上,
选择“开始提取”以打开 SQL 编辑器,然后使用 将请求发送到新的信息提取代理。
ai_query(可选)如果要优化代理的成本,请选择“优化”。
- 优化需要至少 75 个文件。
- 优化可能需要大约一个小时。
- 在优化过程中,将阻止对当前处于活动状态的代理进行更改。
优化完成后,系统会将你定向到“查看”选项卡,以查看当前处于活动状态的代理与针对成本进行优化的代理之间的比较。 请参阅(可选)步骤 4:查看和部署优化的代理。
- (可选)选择“ 创建管道 ”以部署按计划间隔运行的管道,以在新数据上使用代理。 请参阅 Lakeflow 声明性管道,以获取有关管道的详细信息。
提取 ABIE 的“使用”选项卡上所有文档磁贴和“优化代理性能”磁贴的数据。
(可选)步骤 4:查看和部署优化代理
在“使用”选项卡上选择“优化”后,Databricks 会比较多个不同的优化策略来生成和建议优化的代理。 这些策略包括使用 Databricks Geos 微调基础模型。
在“查看”选项卡上:
在“评估结果”中,可以直观地比较优化后的代理和处于活动状态的代理。 为了执行评估,Databricks 会根据每个字段的数据类型选择指标,并使用评估数据集比较活动代理和已针对成本优化的代理。 此评估集基于用于创建原始代理的数据子集。
- 指标将按字段记录到 MLflow 运行中(聚合到顶级字段)。
- 从“列”下拉菜单中选择
overall_score和is_schema_match列。
查看这些结果后,如果要部署此优化代理而不是当前活动的代理,请单击“部署”。
局限性
- Databricks 建议至少使用 1000 个文档来优化代理。 添加更多文档时,代理可以学习的知识库会增加,这会提高代理的质量及其提取准确度。
- 如果源文档包含大于 3 MB 的文件,则代理创建将失败。
- 在代理生成过程中,可能会跳过大于 64 KB 的文档。
- 输入和输出限制为 128K 令牌。
- 不支持使用 Azure 专用链接的工作区,包括 Azure 专用链接后面的存储。
- 不支持联合架构类型。