重要
MICROSOFT SQL Server 连接器为 公共预览版。
本页介绍如何使用 Lakeflow Connect 从 SQL Server 引入数据并将其加载到 Azure Databricks。 SQL Server 连接器支持 Azure SQL 和 Amazon RDS SQL 数据库。 这包括在 Azure 虚拟机(VM)和 Amazon EC2 上运行的 SQL Server。 该连接器还支持通过 Azure ExpressRoute 和 AWS Direct Connect 网络在本地使用 SQL Server。
步骤概述
- 配置要引入的源数据库。
- 创建引入网关。 网关连接到 SQL Server 数据库,提取快照并更改数据,并将其存储在 Unity 目录卷中用于暂存。
- 创建引入管道。 管道将暂存卷中的快照和更改数据导入目标流式表中。
- 计划引入管道。
开始之前
若要创建引入管道,必须满足以下要求:
有权访问主 SQL Server 实例。 只读副本或辅助实例不支持更改跟踪和更改数据捕获功能。
你的工作区启用了 Unity Catalog。
为笔记本、工作流和 Lakeflow 声明性管道启用了无服务器计算。 请参阅启用无服务器计算。
创建连接:对元存储的
CREATE CONNECTION权限。若要使用现有连接,则需要连接的
USE CONNECTION或ALL PRIVILEGES权限。对目标目录的
USE CATALOG权限。对现有架构的
USE SCHEMA、CREATE TABLE和CREATE VOLUME权限,或对目标目录的CREATE SCHEMA权限。用于创建群集或自定义策略的不受限制的权限。 自定义策略必须满足以下要求:
系列:作业计算
策略系列替代:
{ "cluster_type": { "type": "fixed", "value": "dlt" }, "num_workers": { "type": "unlimited", "defaultValue": 1, "isOptional": true }, "runtime_engine": { "type": "fixed", "value": "STANDARD", "hidden": true } }Databricks 建议为引入网关指定最小的工作节点,因为它们不会影响网关性能。
"driver_node_type_id": { "type": "unlimited", "defaultValue": "r5.xlarge", "isOptional": true }, "node_type_id": { "type": "unlimited", "defaultValue": "m4.large", "isOptional": true }
有关群集策略的详细信息,请参阅 “选择群集策略”。
设置要引入的源数据库
请参阅 配置 Microsoft SQL Server 以引入 Azure Databricks。
创建 SQL Server 连接
- 在 Azure Databricks 工作区中,单击“目录”>“外部数据”>“连接”。
- 单击 创建连接。 如果未看到此按钮,则没有
CREATE CONNECTION权限。 - 输入唯一的“连接名称”。
- “连接类型”:选择“SQL Server”。
- 对于“主机”,请指定 SQL Server 域名。
- “用户”和“密码”:输入你的 SQL Server 登录凭据。
- 单击 “创建” 。
创建暂存目录和架构
暂存目录和架构可以与目标目录和架构相同。 暂存目录不能是外来目录。
目录资源管理器
- 在 Azure Databricks 工作区中,单击“目录”。
- 在“目录”选项卡上,执行下列操作之一:
- 单击“创建目录”。 如果未看到此按钮,则没有
CREATE CATALOG权限。 - 输入目录的唯一名称,然后单击“创建”。
- 选择你创建的目录。
- 单击“创建架构”。 如果未看到此按钮,则没有
CREATE SCHEMA权限。 - 输入架构的唯一名称,然后单击“创建”。
命令行界面 (CLI)
export CONNECTION_NAME="my_connection"
export TARGET_CATALOG="main"
export TARGET_SCHEMA="lakeflow_sqlserver_connector_cdc"
export STAGING_CATALOG=$TARGET_CATALOG
export STAGING_SCHEMA=$TARGET_SCHEMA
export DB_HOST="cdc-connector.database.windows.net"
export DB_USER="..."
export DB_PASSWORD="..."
output=$(databricks connections create --json '{
"name": "'"$CONNECTION_NAME"'",
"connection_type": "SQLSERVER",
"options": {
"host": "'"$DB_HOST"'",
"port": "1433",
"trustServerCertificate": "false",
"user": "'"$DB_USER"'",
"password": "'"$DB_PASSWORD"'"
}
}')
export CONNECTION_ID=$(echo $output | jq -r '.connection_id')
创建网关和引入管道
引入网关从源数据库提取快照并更改数据,并将其存储在 Unity 目录暂存卷中。 必须将网关作为连续管道运行。 这有助于适应源数据库上具有的任何更改日志保留策略。
引入管道会应用快照并将数据从暂存卷更改为目标流式处理表。
注释
每个引入管道必须与一个引入网关完全关联。
引入管道不支持多个目标目录和架构。 如果需要写入多个目标目录或模式,请创建多个网关-管道对。
Databricks 资产捆绑包
此选项卡介绍如何使用 Databricks 资产捆绑包部署引入管道。 捆绑包可以包含作业和任务的 YAML 定义,使用 Databricks CLI 进行管理,并且可以在不同的目标工作区(如开发、过渡和生产)中共享和运行。 有关详细信息,请参阅 Databricks 资产捆绑包。
使用 Databricks CLI 创建新捆绑包:
databricks bundle init将两个新资源文件添加到捆绑包:
- 管道定义文件(
resources/sqlserver_pipeline.yml)。 - 控制数据引入频率(
resources/sqlserver.yml)的工作流文件。
以下是一个示例
resources/sqlserver_pipeline.yml文件:variables: # Common variables used multiple places in the DAB definition. gateway_name: default: sqlserver-gateway dest_catalog: default: main dest_schema: default: ingest-destination-schema resources: pipelines: gateway: name: ${var.gateway_name} gateway_definition: connection_name: <sqlserver-connection> gateway_storage_catalog: main gateway_storage_schema: ${var.dest_schema} gateway_storage_name: ${var.gateway_name} target: ${var.dest_schema} catalog: ${var.dest_catalog} channel: PREVIEW pipeline_sqlserver: name: sqlserver-ingestion-pipeline ingestion_definition: ingestion_gateway_id: ${resources.pipelines.gateway.id} objects: # Modify this with your tables! - table: # Ingest the table test.ingestion_demo_lineitem to dest_catalog.dest_schema.ingestion_demo_line_item. source_catalog: test source_schema: ingestion_demo source_table: lineitem destination_catalog: ${var.dest_catalog} destination_schema: ${var.dest_schema} - schema: # Ingest all tables in the test.ingestion_whole_schema schema to dest_catalog.dest_schema. The destination # table name will be the same as it is on the source. source_catalog: test source_schema: ingestion_whole_schema destination_catalog: ${var.dest_catalog} destination_schema: ${var.dest_schema} target: ${var.dest_schema} catalog: ${var.dest_catalog} channel: PREVIEW以下是一个示例
resources/sqlserver_job.yml文件:resources: jobs: sqlserver_dab_job: name: sqlserver_dab_job trigger: # Run this job every day, exactly one day from the last run # See https://docs.databricks.com/api/workspace/jobs/create#trigger periodic: interval: 1 unit: DAYS email_notifications: on_failure: - <email-address> tasks: - task_key: refresh_pipeline pipeline_task: pipeline_id: ${resources.pipelines.pipeline_sqlserver.id}- 管道定义文件(
使用 Databricks CLI 部署管道:
databricks bundle deploy
笔记本
使用源连接、目标目录、目标架构和表更新以下笔记本中的 Configuration 单元格,以从源引入。
创建网关和引入管道
命令行界面 (CLI)
创建网关:
output=$(databricks pipelines create --json '{
"name": "'"$GATEWAY_PIPELINE_NAME"'",
"gateway_definition": {
"connection_id": "'"$CONNECTION_ID"'",
"gateway_storage_catalog": "'"$STAGING_CATALOG"'",
"gateway_storage_schema": "'"$STAGING_SCHEMA"'",
"gateway_storage_name": "'"$GATEWAY_PIPELINE_NAME"'"
}
}')
export GATEWAY_PIPELINE_ID=$(echo $output | jq -r '.pipeline_id')
创建引入管道:
databricks pipelines create --json '{
"name": "'"$INGESTION_PIPELINE_NAME"'",
"ingestion_definition": {
"ingestion_gateway_id": "'"$GATEWAY_PIPELINE_ID"'",
"objects": [
{"table": {
"source_catalog": "tpc",
"source_schema": "tpch",
"source_table": "lineitem",
"destination_catalog": "'"$TARGET_CATALOG"'",
"destination_schema": "'"$TARGET_SCHEMA"'",
"destination_table": "<YOUR_DATABRICKS_TABLE>",
}},
{"schema": {
"source_catalog": "tpc",
"source_schema": "tpcdi",
"destination_catalog": "'"$TARGET_CATALOG"'",
"destination_schema": "'"$TARGET_SCHEMA"'"
}}
]
}
}'
在管道上启动、计划和设置警报
可以在管道详细信息页上为管道创建计划。
创建管道后,重新访问 Azure Databricks 工作区,然后单击 管道。
新管道将显示在管道列表中。
若要查看管道详细信息,请单击管道名称。
在管道详细信息页上,可以通过单击“计划”来计划管道。
若要在管道上设置通知,请单击 设置,然后添加通知。
对于添加到管道的每个调度,Lakeflow Connect 会自动为其创建任务。 引入管道是作业中的任务。 可以选择将更多任务添加到作业。
验证数据引入是否成功
数据管道详细信息页上的列表视图显示在进行数据引入时处理的记录数。 这些数字会自动刷新。
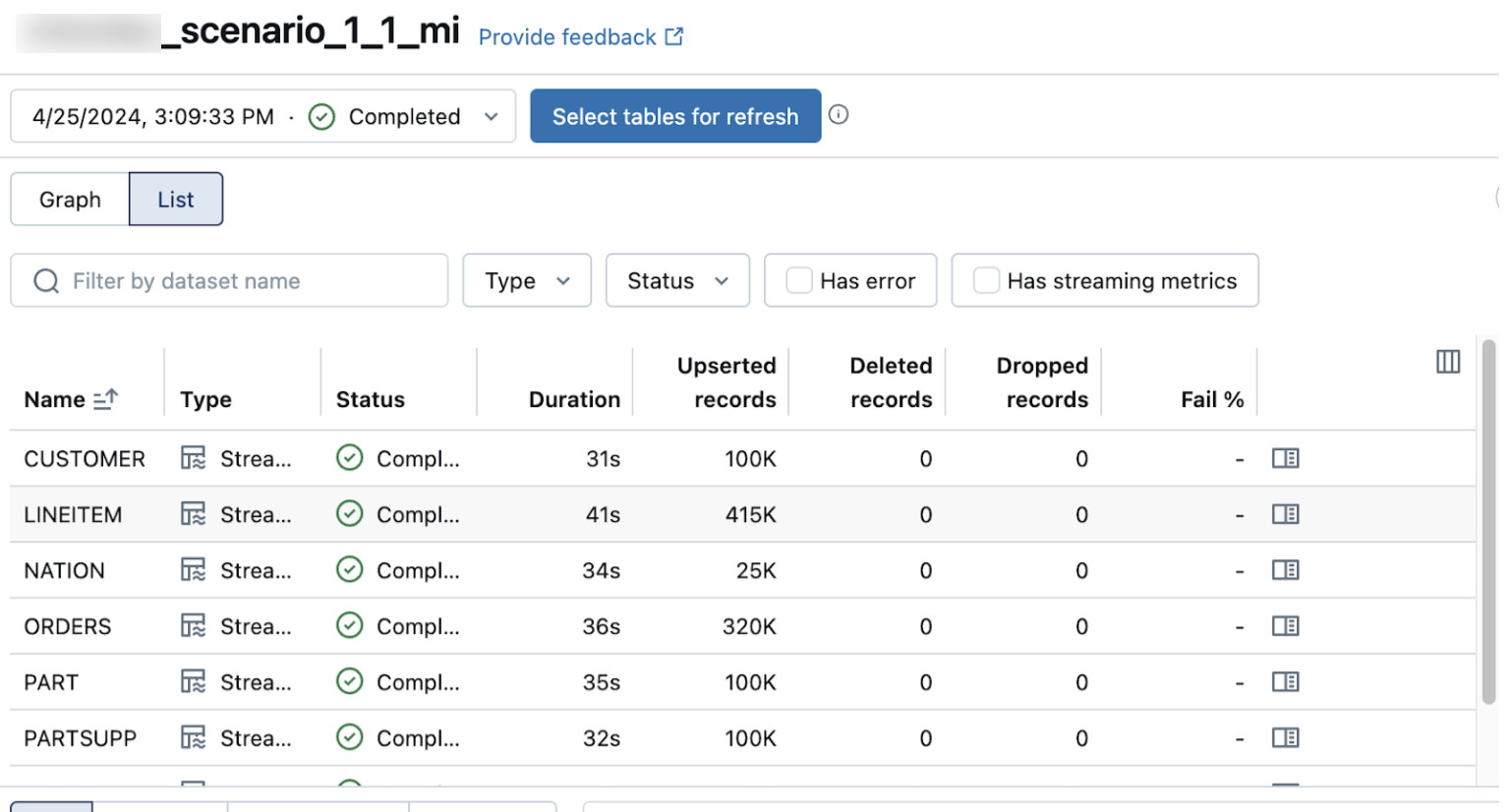
默认情况下不显示 Upserted records 和 Deleted records 列。 可以通过单击列配置 ![]() 按钮并选择它们来启用它们。
按钮并选择它们来启用它们。