重要
此功能在 Beta 版中。
数据目录可以包含大量数据,通常包含已知和未知的敏感数据。 数据团队必须了解每个表中存在的敏感数据类型,以便他们既可以管理对此数据的访问,也能实现访问的民主化。
若要解决此问题,Databricks 数据分类会自动对目录中的表进行分类和标记。 这允许你在 Unity 目录中使用基于角色的访问控制(RBAC)和基于属性的访问控制(ABAC)策略等工具发现敏感数据,以及对结果应用治理控制。
使用此功能,你将能够:
- 对数据进行分类:引擎使用复合 AI 系统自动对 Unity 目录中的任何表进行分类(和标记)。
- 通过智能扫描优化成本:系统利用 Unity 目录和数据智能引擎智能确定何时扫描数据。 这意味着扫描是增量扫描并经过优化,以确保所有新数据都分类,而无需手动配置。
- 查看分类:此预览版提供 AI/BI 仪表板,可帮助你查看目录的分类结果和下游影响。
有关反馈或问题,请与我们联系 data-classification-feedback@databricks.com。
免责声明
注释
- Databricks 数据分类使用 Databricks 托管的大型语言模型(LLM)来帮助分类。 Databricks 实现安全控制来保护数据。 有关详细信息,请参阅 模型服务中的数据保护 和 Databricks AI 功能的信任和安全。
要求
启动数据分类
要启用此功能:
导航到任何目录,然后单击“ 详细信息 ”选项卡。
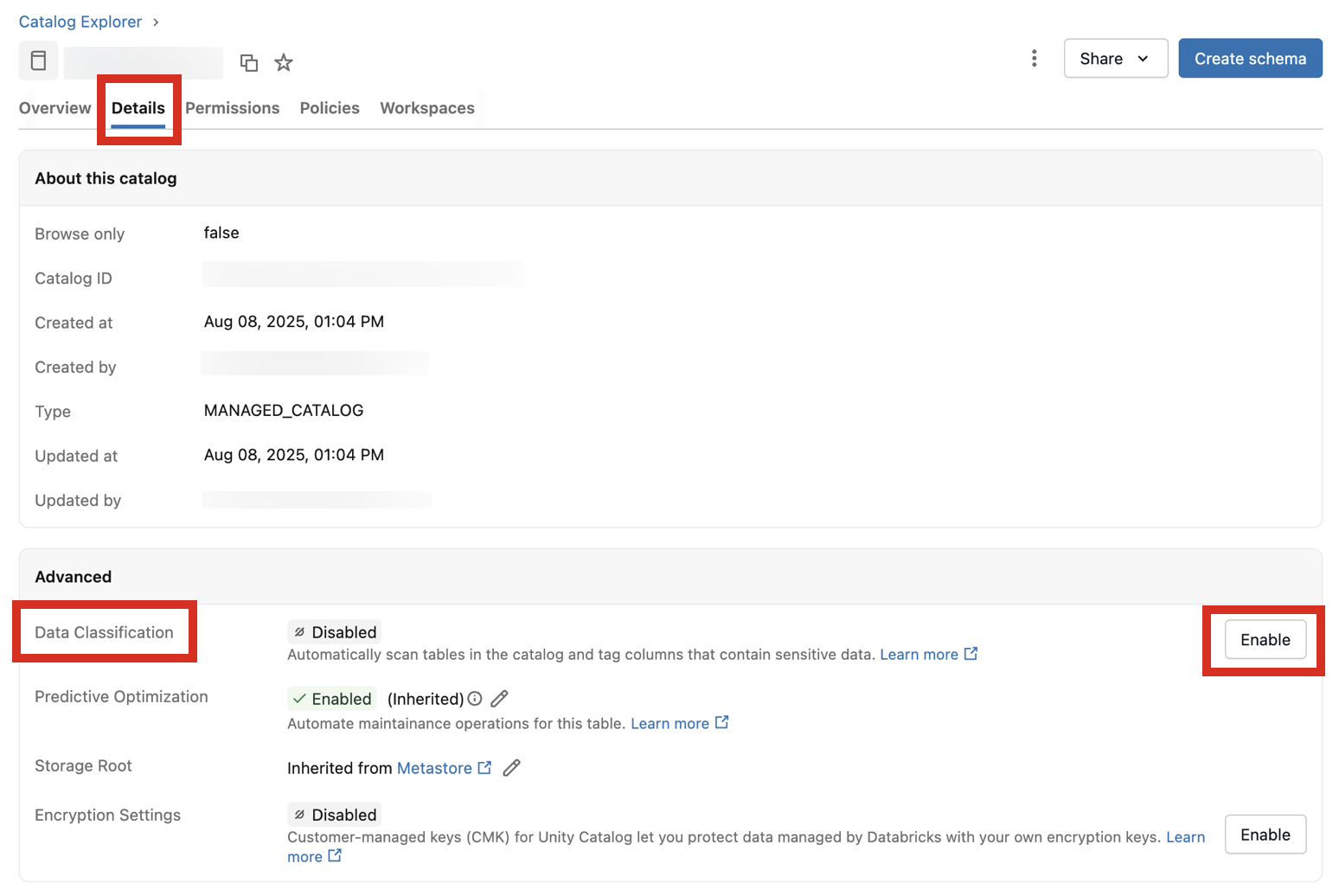
单击 “数据分类” 开关以启用它。
(可选)选择要包括以用于分类的架构。 默认情况下,包括所有架构。
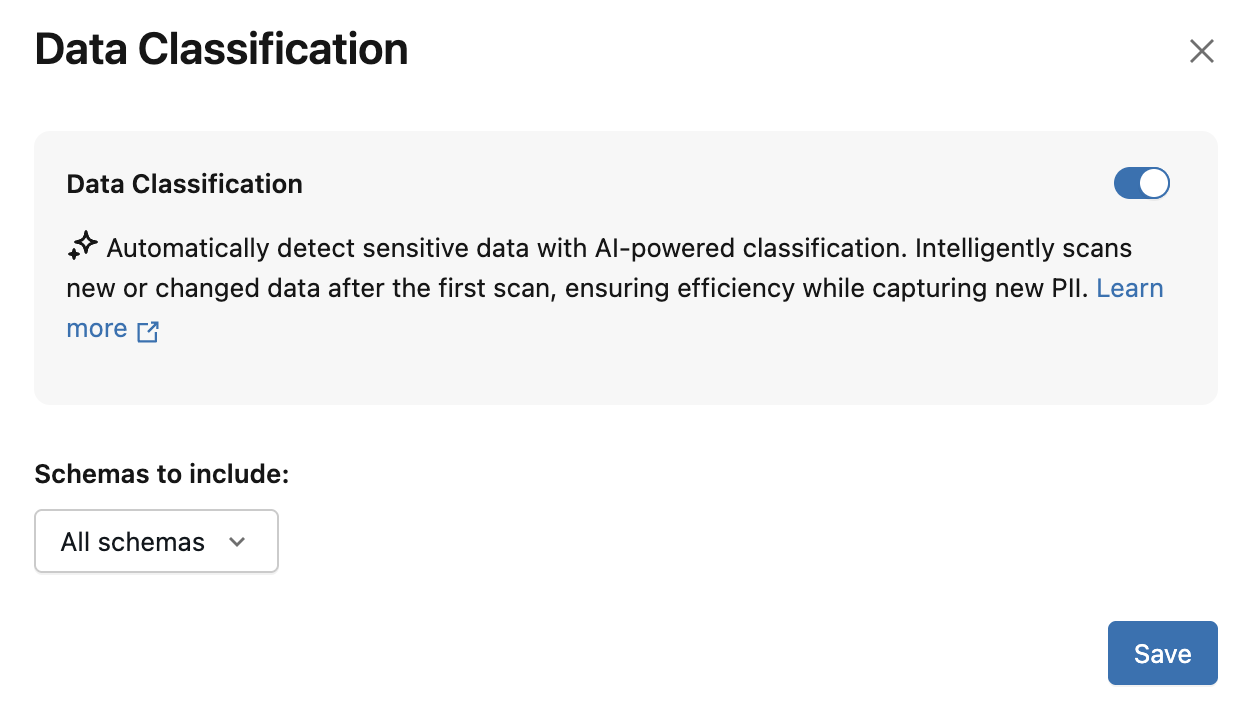
这会创建一个后台作业,该作业以增量方式扫描目录或所选架构中的所有表。
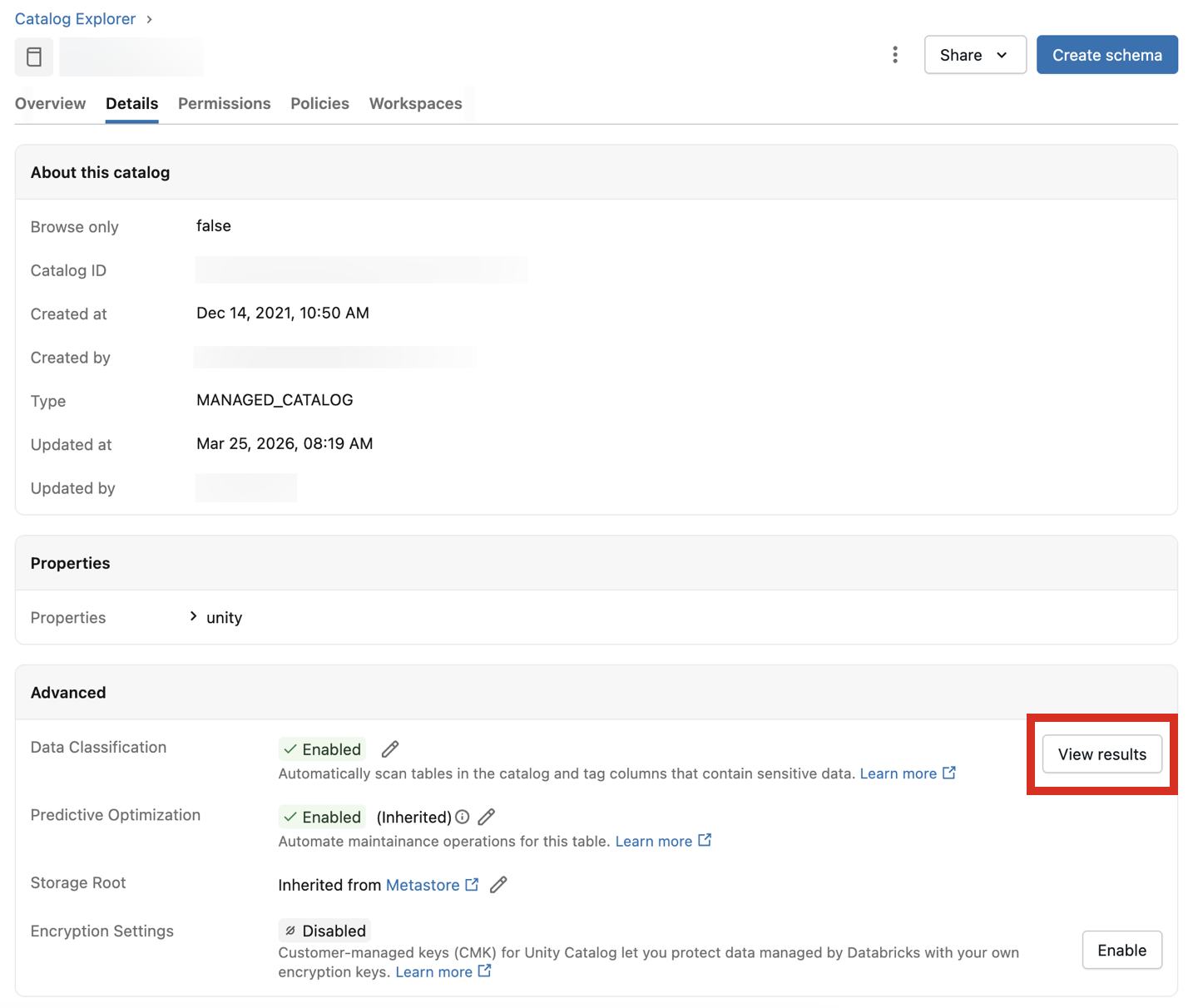
查看分类结果
若要查看分类结果,请单击切换开关旁边的 “查看结果 ”。 此时会打开一个仪表板,其中显示了目录中所有表的分类结果。
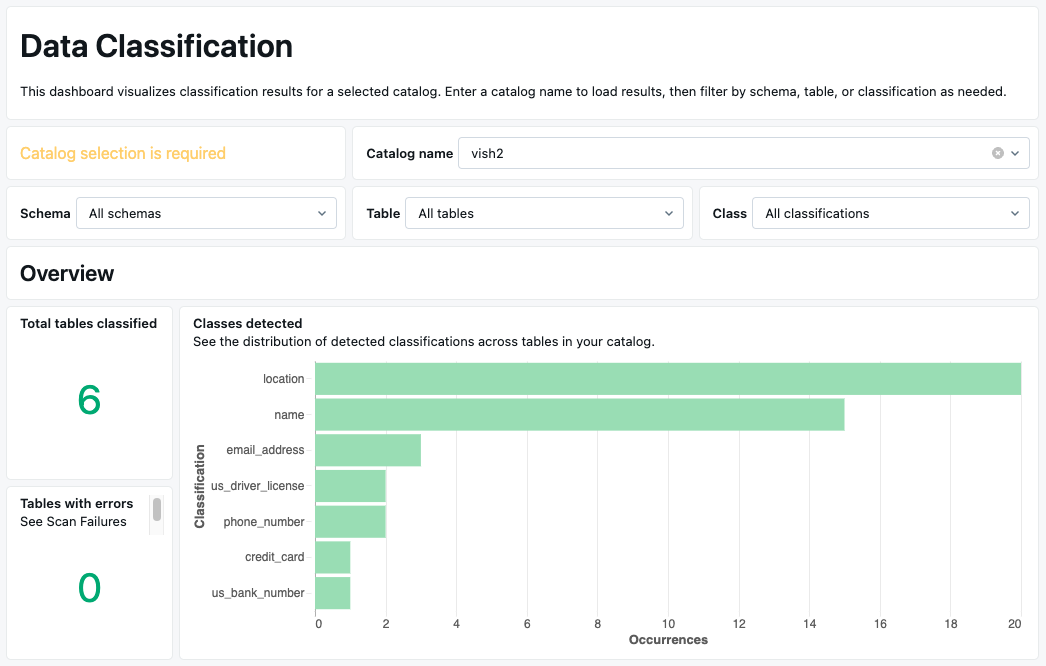
概述
“ 概述 ”部分显示已分类的表数,以及整个目录中敏感数据类的分布。 可以按架构、表或分类筛选结果。
仪表板由视图提供支持,而视图提供访问控制结果,这意味着只会向用户返回其具有读取权限的表结果行(有关更多详细信息,请参见常见问题解答)。
分类日志
“ 分类日志 ”部分显示一段时间内分类的时序图表。 这使你能够查看最新的分类,并通过敏感数据类向下钻取。
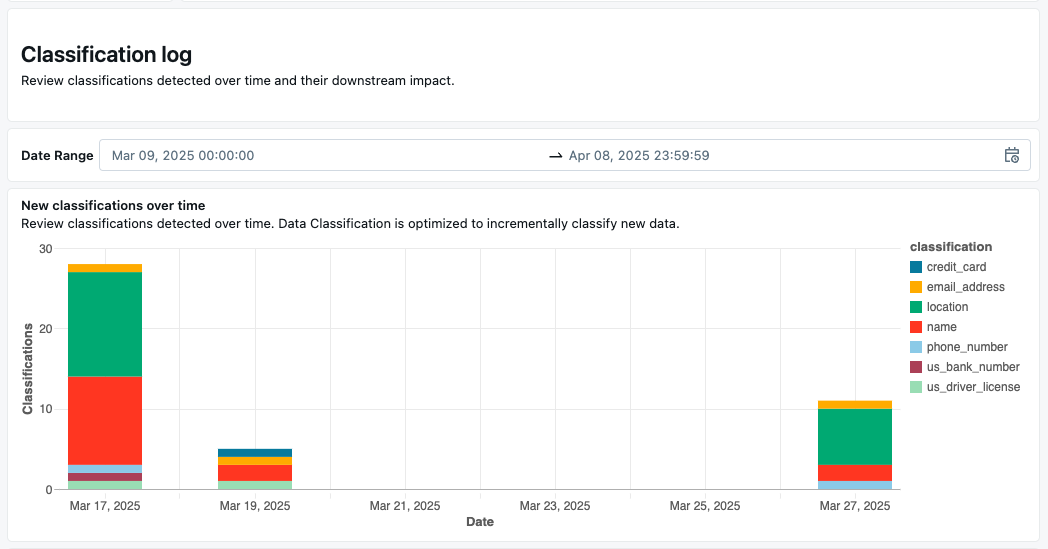
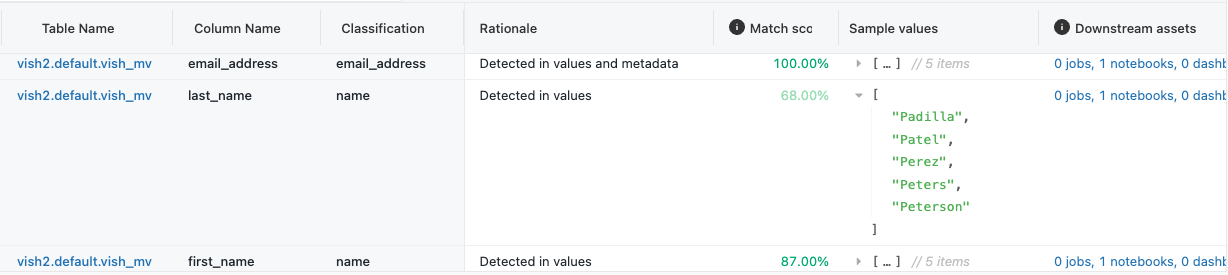
它还提供一个表,其中包含每个分类的详细信息,包括:
- 理由:分类的原因。 这可能是由于对元数据或列名称的检测、对值的检测或两者的组合造成的。
- 匹配分数:与分类相符的行所占的近似百分比。
- 示例值:与分类匹配的值的示例。 这对于了解分类上下文并验证其准确性非常有用。
- 下游资产:受分类影响的下游资产列表,包括作业、笔记本、查询和仪表板。
- 活动用户:提供的时间范围内表的活动用户数。
扫描失败
“ 扫描失败” 部分显示哪些表无法分类。 出于各种原因,可能会发生这种情况,每个表失败都附带详细的错误消息。 有关解决这些错误的帮助,请参阅 常见问题解答。
标记和治理控件
数据分类结果可以通过多种方式启用治理控制,包括:
- 敏感数据发现:可以查询分类结果以发现目录中的敏感数据并采取适当的措施。
- 行级别和列级安全性:分类可以生成可由下游策略使用的标记,以使用基于属性的访问控制(ABAC)强制实施行级和列级安全性。
- 表级安全性:分类结果可用于设置用户组和权限,以限制对敏感表和架构的访问。
发现敏感数据
仪表板中的结果视图可帮助你了解敏感数据的位置及其在目录中的使用方式。 可以使用此信息采取适当的行动,例如自动发送请求通知表所有者从其表中删除或处理个人身份信息(PII)。
行级别和列级别安全性
数据分类可以使用系统标记自动标记敏感数据。 为此,做以下事情:
- 必须在标记策略预览版中注册。
- 必须对系统标记策略(任何以
ASSIGN为前缀的标记)具有class.特权。 - 你必须拥有
APPLY TAG权限,以便在目录、架构和表上应用标记。
如果在 ABAC 预览版中注册,则可以使用 class. ABAC 策略中的标记和掩码函数自动屏蔽任何标记数据。
例如,可以创建一个策略,该策略将社会安全号码掩码给不属于特定用户组的所有用户。
要了解有关注册标记策略或 ABAC 预览版的详细信息,请联系你的帐户服务代表或 Databricks 客户支持。
强制实施列级安全性的另一个选项是将 列掩码 应用于标记列。
表级别安全性
可以使用分类结果通过用户组和权限实现表级安全性。
例如,可以创建一个调用 confidential 的用户组并将其分配给包含 name 分类的所有表,并且可以创建调用 restricted 的组并将其分配给包含 us_ssn的所有表。
查看数据分类费用
若要了解如何对数据分类计费,请访问 定价页。 可以通过运行查询或查看使用情况仪表板来查看与数据分类相关的费用。
查看系统表 system.billing.usage 的使用情况
若要检查数据分类费用,请使用如下所示的查询:
SELECT
usage_date,
identity_metadata.run_as AS run_as_user,
SUM(usage_quantity) AS dbus
FROM
system.billing.usage
WHERE
usage_date >= DATE_SUB(CURRENT_DATE(), 30)
AND billing_origin_product = 'DATA_CLASSIFICATION'
GROUP BY
usage_date,
identity_metadata.run_as
ORDER BY
usage_date DESC,
run_as_user;
从使用情况仪表板查看使用情况
如果工作区中已配置了使用情况仪表板,则可以通过选择标记为“数据分类”的计费源项目来筛选使用情况。 如果未配置使用情况仪表板,可以导入一个仪表板并应用相同的筛选。 有关详细信息,请参阅 使用情况仪表板。
常见问题
数据分类需要多长时间才能运行?
分类引擎依赖于智能扫描来确定何时扫描表。 您可以预期目录中创建的新表和列将在 24 小时内被扫描。
如果遇到超过 24 小时的延迟,请与我们联系 data-classification-feedback@databricks.com。
创建的结果表的权限是什么?
数据分类创建表来存储结果和错误(_result 以及 _errors 分别),默认情况下,只有设置分类的用户才能访问这些表。
动态视图也通过应用行级访问控制的这些表创建,因此从这些视图中读取结果的任何用户将只看到与他们已有所有权或读取访问权限的表对应的条目。
某些表未能分类;如何弄清楚发生了什么问题?
默认情况下,将跳过单个表发生的失败,并在第二天重试。 可以使用错误视图查看导致分类失败的确切错误消息。
SELECT * FROM <catalog_name>._data_classification.errors
WHERE schema_name = '<schema_name>' and table_name = '<table_name>'
数据分类是否支持视图?
不支持视图和 指标视图 。 如果视图基于现有表,Databricks 建议对基础表进行分类,以查看它们是否包含敏感数据。
支持物化视图和流式表。
数据分类是否支持增量共享目录?
不支持通过Delta Sharing共享的目录。 相反,Databricks 建议共享现有目录中的架构和表,以对敏感数据进行分类。
支持的类
下表列出了数据分类支持的类:
| 班级 | DESCRIPTION |
|---|---|
| 信用卡 | 信用卡号 |
| 电子邮件地址 | 电子邮件地址 |
| IBAN代码 | 国际银行账户号码(IBAN) |
| IP地址 | Internet 协议地址 (IPv4 或 IPv6) |
| 位置 | 位置 |
| “名称” | 人员姓名 |
| 电话号码 | 电话号码 |
| 美国银行编号 | 美国银行号码 |
| 美国驾照 | 美国驾照 |
| “us_itin” | 美国个人纳税人身份证号 |
| 美国护照 | 美国护照 |
| “us_ssn” | 美国社会保险号码 |