了解如何使用 Lakeflow Spark 声明性管道(SDP)为数据业务流程和自动加载程序创建新管道。 本教程通过清理数据和创建查询,以扩展示例管道,从而找出前 100 个用户。
本教程介绍如何使用 Lakeflow 管道编辑器:
- 使用默认文件夹结构创建新管道,并从一组示例文件开始。
- 使用预期定义数据质量约束。
- 使用编辑器功能通过新的转换来扩展管道,以对数据执行分析。
要求
在开始本教程之前,必须:
- 登录到Azure Databricks工作区。
- 为工作区启用 Unity Catalog。
- 为工作区启用 Lakeflow 管道编辑器,并且必须选择加入。 请参阅 “启用 Lakeflow 管道编辑器”和“更新后的监视”。
- 有权创建计算资源或访问计算资源。
- 有权在目录中创建新架构。 所需的权限为
ALL PRIVILEGES或USE CATALOG和CREATE SCHEMA。
步骤 1:创建管道
在此步骤中,将使用默认文件夹结构和代码示例创建管道。 代码示例引用 users 示例数据源中的 wanderbricks 表。
在Azure Databricks工作区中,单击
 New,然后
New,然后 ETL pipeline。 这会在“创建管道”页上打开管道编辑器。
ETL pipeline。 这会在“创建管道”页上打开管道编辑器。单击标头,为管道命名。
在名称下方,选择输出表的默认目录和架构。 如果未在管道定义中指定目录和架构,则使用默认的目录和架构。
在管道的 下一步中,单击
 从 SQL 示例代码开始 或 从 Python 示例代码开始,根据您的语言偏好选择。 这会更改示例代码的默认语言,但稍后可以添加其他语言的代码。 这会创建一个包含示例代码的默认文件夹结构,以帮助你入门。
从 SQL 示例代码开始 或 从 Python 示例代码开始,根据您的语言偏好选择。 这会更改示例代码的默认语言,但稍后可以添加其他语言的代码。 这会创建一个包含示例代码的默认文件夹结构,以帮助你入门。可以在工作区左侧的管道资产浏览器中查看示例代码。 下面是
transformations两个文件,每个文件生成一个管道数据集。 在explorations下方有一个笔记本,里面有帮助你查看管道输出的代码。 单击文件可在编辑器中查看和编辑代码。尚未创建输出数据集,屏幕右侧的 管道图 为空。
若要运行管道代码(文件夹中的代码
transformations),请单击屏幕右上角的 “运行管道 ”。运行完成后,工作区的底部会显示出两个新表,
sample_users_<pipeline-name>和sample_aggregation_<pipeline-name>。 还可以看到工作区右侧的 管道图 现在显示了两个表,其中sample_users是sample_aggregation的源表。
步骤 2:应用数据质量检查
在此步骤中,向sample_users表添加数据质量检查。 使用 管道预期 来约束数据。 在这种情况下,将删除没有有效电子邮件地址的任何用户记录,并将清理的表输出为 users_cleaned。
在管道资产浏览器中,单击
然后选择 “转换”。在“ 创建新转换文件 ”对话框中,进行以下选择:
- 请在语言中选择Python或SQL。 这不必与上一个选择匹配。
- 为文件命名。 在这种情况下,请选择
users_cleaned。 - 对于 目标路径,保留默认值。
- 对于 数据集类型,请将其保留为 未选择 或选择 具体化视图。 如果选择 具体化视图,它将为你生成示例代码。
单击“ 创建 ”以创建转换代码文件。
在新代码文件中,编辑代码以匹配以下内容(根据上一屏幕上的选择使用 SQL 或Python)。 替换
<pipeline-name>为sample_users表的全名。SQL
-- Drop all rows that do not have an email address CREATE MATERIALIZED VIEW users_cleaned ( CONSTRAINT non_null_email EXPECT (email IS NOT NULL) ON VIOLATION DROP ROW ) AS SELECT * FROM sample_users_<pipeline-name>;Python
from pyspark import pipelines as dp # Drop all rows that do not have an email address @dp.materialized_view @dp.expect_or_drop("no null emails", "email IS NOT NULL") def users_cleaned(): return ( spark.read.table("sample_users_<pipeline_name>") )单击“ 运行管道 ”以更新管道。 它现在应该有三个表格。
步骤 3:分析排名靠前的用户
接下来,按已创建的预订数获取前 100 名用户。 将 wanderbricks.bookings 表联接到 users_cleaned 物化视图。
在管道资产浏览器中,单击
然后选择 “转换”。在“ 创建新转换文件 ”对话框中,进行以下选择:
- 请在语言中选择Python或SQL。 这不必与以前的选择匹配。
- 为文件命名。 在这种情况下,请选择
users_and_bookings。 - 对于 目标路径,保留默认值。
- 对于数据集类型,请保持未选择。
在新代码文件中,编辑代码以匹配以下内容(根据上一屏幕上的选择使用 SQL 或Python)。
SQL
-- Get the top 100 users by number of bookings CREATE OR REFRESH MATERIALIZED VIEW users_and_bookings AS SELECT u.name AS name, COUNT(b.booking_id) AS booking_count FROM users_cleaned u JOIN samples.wanderbricks.bookings b ON u.user_id = b.user_id GROUP BY u.name ORDER BY booking_count DESC LIMIT 100;Python
from pyspark import pipelines as dp from pyspark.sql.functions import col, count, desc # Get the top 100 users by number of bookings @dp.materialized_view def users_and_bookings(): return ( spark.read.table("users_cleaned") .join(spark.read.table("samples.wanderbricks.bookings"), "user_id") .groupBy(col("name")) .agg(count("booking_id").alias("booking_count")) .orderBy(desc("booking_count")) .limit(100) )单击“ 运行管道 ”更新数据集。 运行完成后,可以在 Pipeline Graph 中看到有四个表,包括新
users_and_bookings表。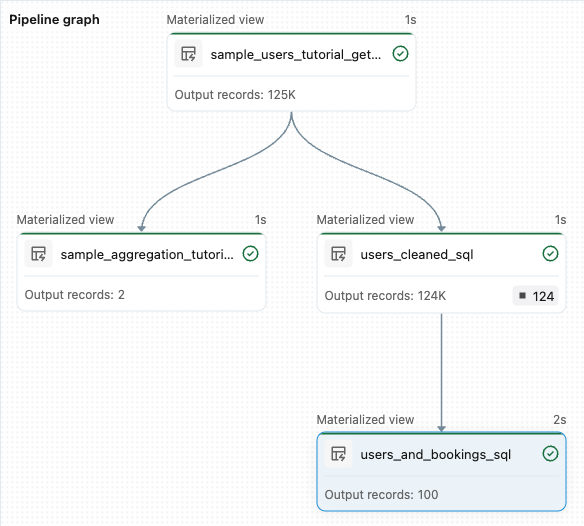
后续步骤
现在,你已了解如何使用 Lakeflow 管道编辑器的一些功能并创建了管道,下面提供了一些其他功能来了解有关以下内容的详细信息: