本文介绍了 Databricks 如何以及为何测量基础模型 API 的预配吞吐量工作负载的每秒标记数。
大型语言模型(LLM)的性能通常以每秒令牌来衡量。 配置服务终结点的生产模型时,请务必考虑应用程序发送到终结点的请求数。 这样做有助于了解终结点是否需要配置为缩放,以免影响延迟。
为在部署时采用了预配吞吐量的终结点配置横向扩展范围时,Databricks 发现使用标记推断进入系统的输入会更容易。
什么是令牌?
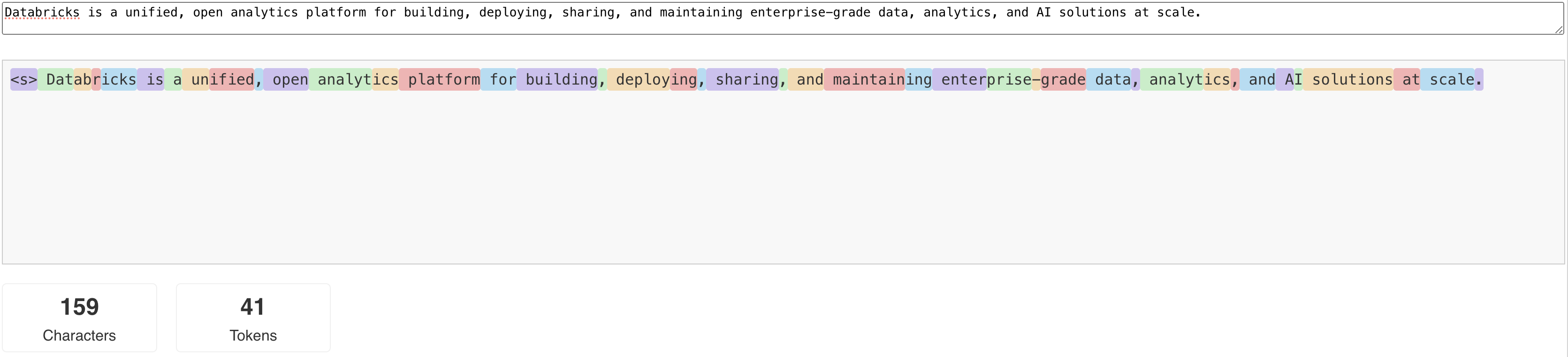
LLM 按照所谓的标记来读取和生成文本。 令牌可以是字词或子单词,用于将文本拆分为标记的确切规则因模型而异。 例如,可以使用在线工具查看Llama的分词器如何将单词转换为令牌。
下图显示了 Llama tokenizer 如何分解文本的示例:
为什么以每秒令牌数衡量 LLM 性能?
传统上,服务终结点是根据每秒并发请求数(RPS)配置的。 然而,LLM 推理请求所需的时间会因传入令牌数量和生成令牌数量的不同而不同,这可能导致请求之间的不均衡。 因此,确定终结点所需的横向扩展量需要根据请求内容(标记)来衡量终结点规模。
不同的用例具有不同的输入和输出令牌比率:
- 输入上下文的不同长度:虽然某些请求可能只涉及几个输入令牌,例如简短的问题,但其他请求可能涉及数百甚至数千个令牌,例如汇总的长文档。 这种可变性使配置服务终结点仅基于 RPS 具有挑战性,因为它不考虑不同请求的不同处理需求。
- 根据用例的不同输出长度:LLM 的不同用例可能会导致完全不同的输出令牌长度。 生成输出令牌是 LLM 推理中最耗时的部分,因此这可能会影响吞吐量。 例如,摘要需要较短且更简洁有力的回应,而文本生成(如撰写文章或产品说明)可以产生更长的答案。
如何为端点选择每秒令牌数量范围?
预配吞吐量服务终结点根据每秒可以发送到终结点的标记数范围进行配置。 终结点可以纵向扩展和缩减,以处理生产应用程序的负载。 我们将根据你的终结点缩放到的每秒标记数范围按小时收费。
了解您在预配吞吐量服务终结点上每秒令牌范围是否适合您的特定使用场景的最佳方法是使用具有代表性的数据集进行负载测试。 请参阅 执行自己的 LLM 终结点基准测试。
需要考虑两个重要因素:
- Databricks 如何测量 LLM 的每秒标记数性能。
- 自动缩放的工作原理。
Databricks 如何测量 LLM 的每秒标记数性能
Databricks 针对表示摘要任务的工作负载对终结点进行基准测试,这些任务在检索增强型生成样式用例中很常见。 具体而言,工作负荷包括:
- 2048 个输入标记
- 256 个输出标记
显示的令牌范围 合并 了输入和输出令牌吞吐量,默认情况下,针对均衡吞吐量和延迟进行了优化。
Databricks 的基准测试表明,用户可以以每个请求批大小为 1 的方式,并发地将多个令牌每秒发送到终结点。 这会模拟多个同时命中终结点的请求,这更准确地表示在生产环境中实际使用终结点的方式。
- 例如,如果预配的吞吐量服务终结点的设定速率为每秒 2304 个令牌(2048 + 256),则输入为 2048 个令牌的单个请求,预期输出为 256 个令牌需要大约 1 秒才能运行。
- 同样,如果速率设置为 5600,您可以预期单个请求在上述输入和输出令牌计数下运行大约 0.5 秒,也就是说,端点可以在大约一秒内处理两个类似的请求。
如果工作负荷与上述不同,则预期延迟会因列出的预配吞吐量速率而异。 如前所述,生成更多的输出令牌比包括更多的输入令牌更耗时。 如果要执行批处理推理并想要估计完成所需的时间,则可以计算输入和输出令牌的平均数量,并将其与上述 Databricks 基准工作负荷进行比较。
- 例如,如果您有 1000 行,平均输入令牌计数为 3000,平均输出令牌计数为 500,并且预设的吞吐量为每秒 3500 个令牌,那么由于您的平均令牌计数比 Databricks 的基准值更大,完成所有任务可能会超过 1000 秒(每行约 1 秒)。
- 同样,如果你有 1000 行、平均输入 1500 个令牌、平均输出为 100 个令牌,并且预配的吞吐量为每秒 1600 个令牌,则由于平均令牌计数小于 Databricks 基准,可能需要少于 1000 秒的总(每行 1 秒)。
若要估算完成批处理推理工作负荷所需的理想预配吞吐量,可以使用 ai_query 执行批处理 LLM 推理中的笔记本
自动缩放的工作原理
模型服务具有快速自动缩放系统,可缩放基础计算以满足应用程序的每秒标记数需求。 Databricks 以每秒令牌块为单位纵向扩展预配的吞吐量,因此,仅当使用预配的吞吐量时,才会收取额外的预配吞吐量单位的费用。
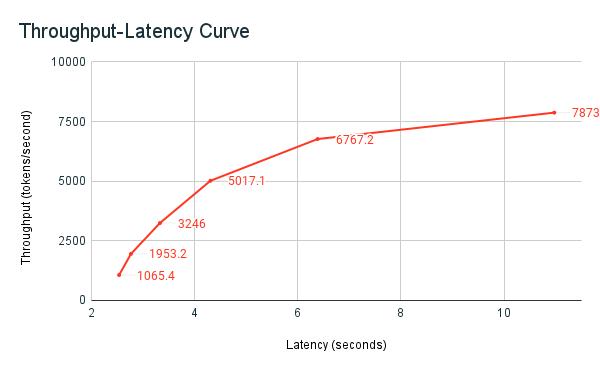
以下吞吐量延迟图显示了一个经过测试的预配吞吐量终结点,并增加了并行请求数。 第一个点表示 1 个请求、第二个、2 个并行请求、第三个、4 个并行请求等。 随着请求数量的增加,从而每秒的令牌需求也随之增加,此时可以观察到预配的吞吐量也会相应增加。 此增加表示自动缩放会增加可用的计算。 但是,你可能会开始注意到吞吐量开始趋于平稳,随着并行请求的增多,达到每秒约 8000 个标记的限制。 分配的计算资源正在被同时使用,因此总延迟增加,因为在处理之前,更多的请求必须在队列中等待。
注释
可以通过关闭缩放至零功能,并在服务端点上配置最小吞吐量,来保持吞吐量的一致性。 这样做就无需等待纵向扩展终结点。
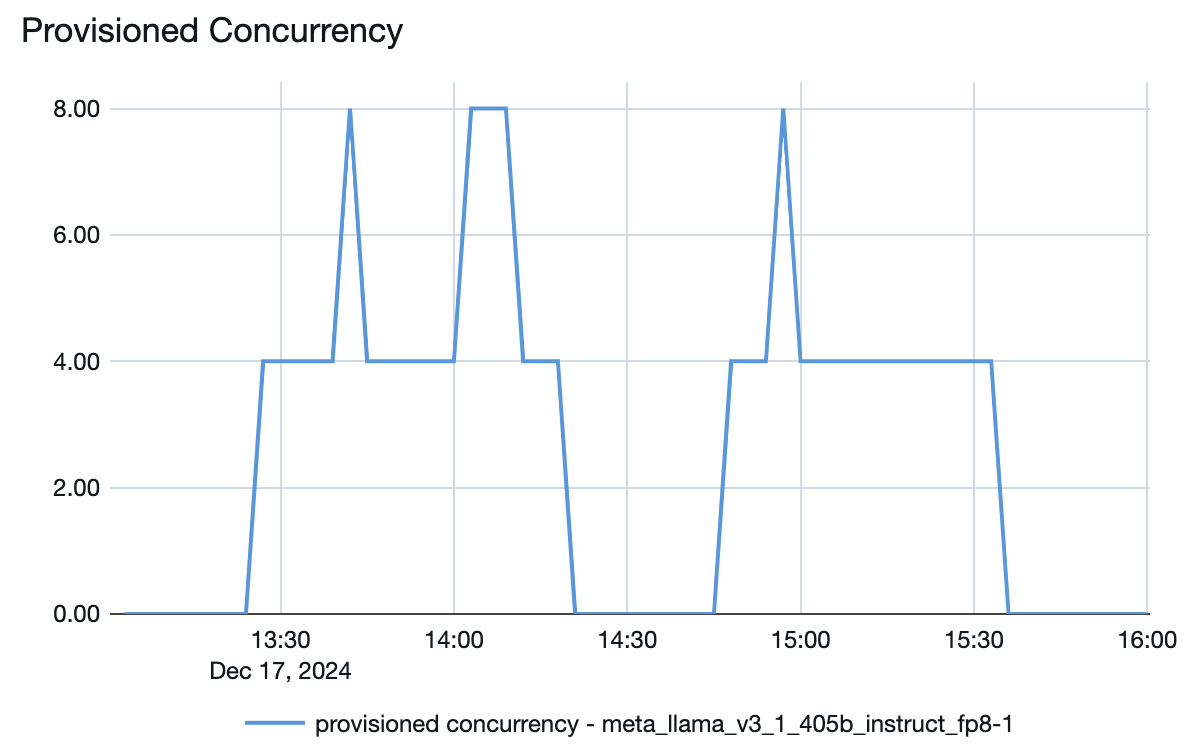
您还可以从模型服务端点查看资源如何根据需求扩展或缩减:
故障排除
如果预配的吞吐量服务终结点以小于指定速率的每秒标记数运行,请通过查看以下内容检查终结点的实际缩放量:
- 终结点指标中的预配并发绘图。
- 预配的吞吐量终结点最小带区大小。
- 转到终结点的服务实体详情,查看最多下拉菜单中的每秒最小标记数值。
然后,可以使用以下公式计算终结点实际缩放量:
- 预配的并发 * 最小带段大小 / 4
例如,上述 Llama 3.1 405B 模型的预配并发图的最大预配并发数为 8。 为其设置终结点时,最小带段大小为每秒 850 个令牌。 在此示例中,终结点缩放为最大值:
- 8 (预配并发) * 850 (最小带大小) / 4 = 每秒 1700 个令牌