本文介绍使用模型服务端点时可能会遇到的不同超时以及如何处理它们。 它涵盖模型部署超时、服务器端超时和客户端超时。
模型部署超时
使用马赛克 AI 模型服务部署模型或更新现有部署时,该过程可能会因多种原因而超时。 模型服务终结点页面的 “事件” 选项卡用于记录超时消息。 搜索“超时”以找到它们。
注释
如果容器生成和模型部署超过依赖于终结点工作负荷配置的某个持续时间,则部署过程会超时。 在部署之前检查配置,并将其与以前的成功部署进行比较。
容器生成没有硬性限制,但重试最多 3 次。 生成容器后,容器的部署将等待最多 30 分钟以处理 CPU 工作负荷,等待最多 60 分钟以处理 GPU 中小型工作负荷,等待最多 120 分钟以处理 GPU 大型工作负荷,然后超时处理。
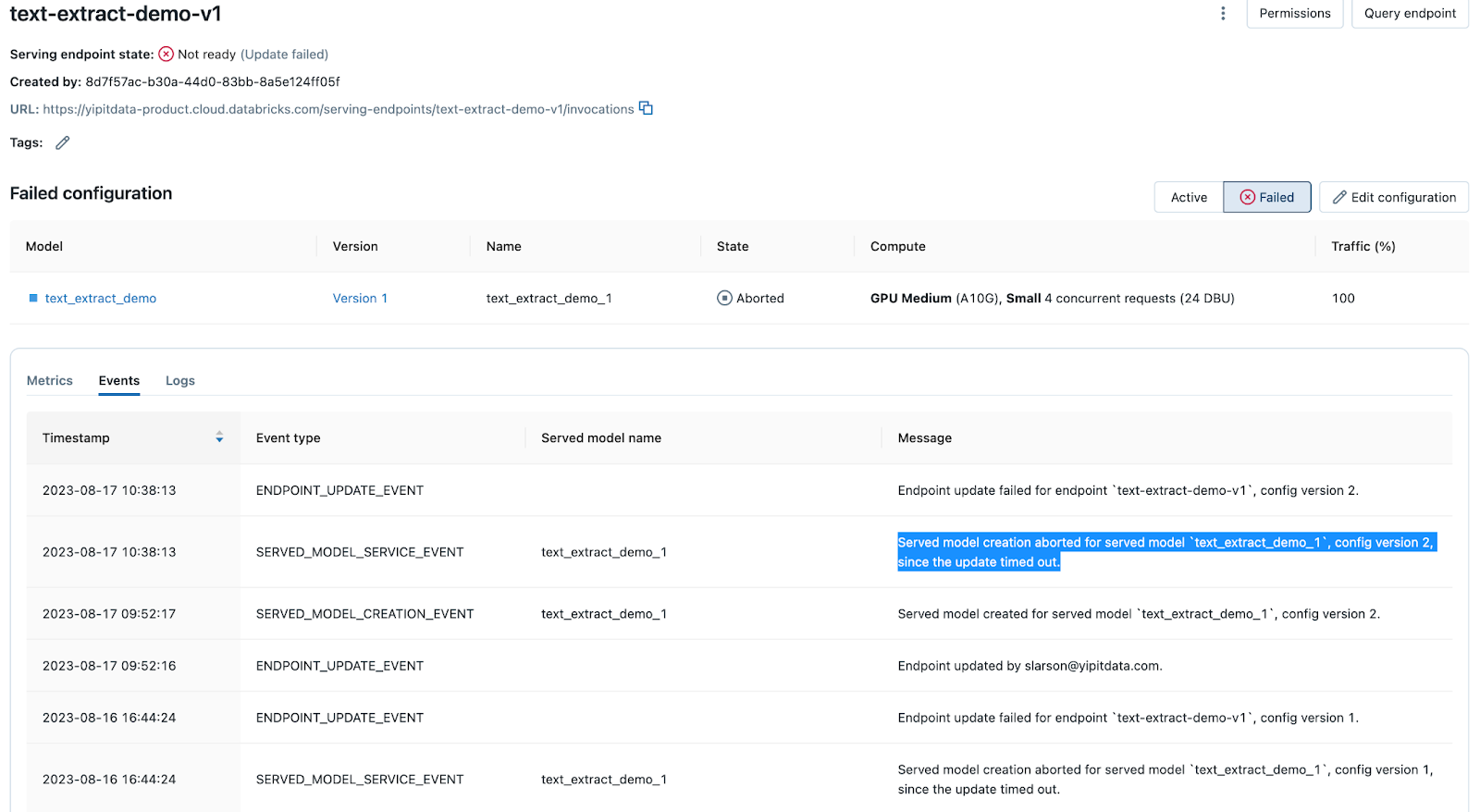
如果发现 “超时” 消息,请导航到“ 日志 ”选项卡并检查生成日志以确定原因。 示例包括库依赖项问题、资源约束、配置问题等。
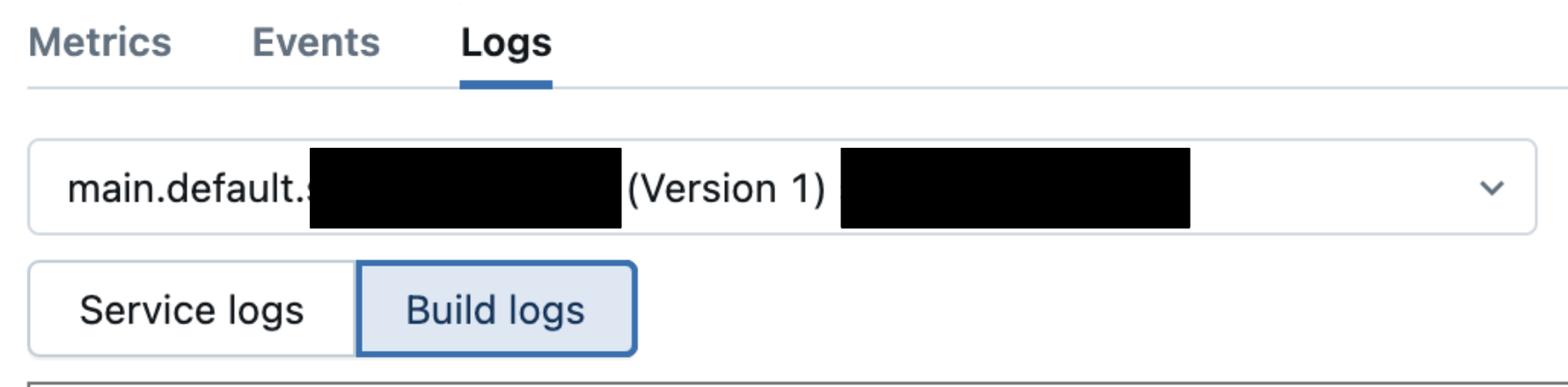
请参阅 容器生成失败后的调试。
服务器端超时
如果终结点根据服务终结点的 “事件 和 日志 ”选项卡运行正常,但在调用终结点时遇到超时,则超时可能位于服务器端。 默认超时因模型服务终结点的类型而异。 下表显示了发送到模型服务终结点的请求的默认服务器端超时。
| 终结点类型 | 请求超时限制(秒) | 注释 |
|---|---|---|
| CPU 或 GPU 服务端点 | 默认值 297 | 无法增加此限制。 |
| 为终结点提供服务的基础模型 | 默认值 297 | 无法增加此限制。 |
若要确定是否遇到服务器端超时,请查看请求在上述限制之前或之后是否超时。
- 如果请求在限制处一致失败,则可能是服务器端超时。
- 如果请求早于限制失败,则可能是因为配置问题。
- 检查服务日志以确定是否存在任何其他错误。
- 确认模型在本地运行,例如通过交互式计算工具(例如 Jupyter Notebook),或在早期版本的请求中运行。
客户端超时:MLflow 配置
客户端超时通常返回错误消息,指出 “超时” 或 4xx 错误请求。 这些超时的常见原因是 MLflow 环境变量配置。 以下是最常见的用于超时的 MLflow 环境变量。 有关超时变量的完整列表,请参阅 mlflow.environment_variables文档。
- MLFLOW_HTTP_REQUEST_TIMEOUT:指定 MLflow HTTP 请求的超时(以秒为单位)。 默认超时 120 秒。
- MLFLOW_HTTP_REQUEST_MAX_RETRIES:指定 MLflow HTTP 请求的指数退避的最大重试次数。 默认值为 7 秒。
注释
客户端上的 HTTP 请求超时设置为 120 秒,这不同于服务器端对 CPU 和 GPU 服务终结点的默认超时 297 秒。 如果希望工作负荷超过 120 秒的客户端超时,请相应地调整 MLflow 环境变量。
请执行下列作之一,以确定超时是否由 MLflow 环境变量配置引起:
- 使用示例输入(例如在笔记本中)在本地测试模型,以确认它在注册模型并部署模型之前按预期工作。
- 检查处理请求所需的时间。
- 如果请求时间超过 MLflow 环境变量的默认超时时间,或者在笔记本中收到 “超时” 消息。 示例 “超时” 消息:
Timed out while evaluating the model. Verify that the model evaluates within the timeout.
- 检查处理请求所需的时间。
- 使用 POST 请求测试为终结点提供服务的模型。
- 如果启用了服务日志,请检查终结点的服务 日志 或推理表。
- 如果要提供自定义模型,请参阅 Unity 目录推理表架构。
- 如果你的终结点提供外部模型、预配的吞吐量工作负载或代理模型,请参阅 已启用的 Unity AI 网关推理表架构。
- 如果启用了服务日志,请检查终结点的服务 日志 或推理表。
配置 MLflow 环境变量
使用服务 UI 或以编程方式使用 Python 配置 MLflow 环境变量。
服务 UI
可以为模型部署配置环境变量
- 选择要为其配置环境变量的终结点。
- 在终结点的页面上,选择右上角的 “编辑 ”。
- 在 “实体详细信息”中,展开 “高级配置 ”以添加相关的 MLflow 超时环境变量。
请参阅 添加纯文本环境变量。
Python
可以使用 Python 通过编程方式设置模型服务终结点,并包括调整后的 MLflow 环境变量。 以下示例将最大超时时间调整为 300 秒,最大重试次数调整为 3。
有关设置此载荷的更多详细信息,请参阅Databricks API 页。
import mlflow.deployments
# Get the deployment client
client = mlflow.deployments.get_deploy_client("databricks")
# Define the configuration with environment variables
config = {
"served_entities": [
{
"name": "sklearn_example-1",
"entity_name": "catalog.schema.model_name",
"entity_version": "1",
"workload_size": "Small",
"workload_type": "CPU",
"scale_to_zero_enabled": True,
"environment_vars": {
"MLFLOW_HTTP_REQUEST_MAX_RETRIES": 3,
"MLFLOW_HTTP_REQUEST_TIMEOUT": 300
}
},
],
"traffic_config": {
"routes": [
{
"served_model_name": "model_name-1",
"traffic_percentage": 100
}
]
}
}
# Create the endpoint with the specified configuration
endpoint = client.create_endpoint(
name="model_name-1",
config=config
)
客户端超时:第三方客户端 API
客户端超时通常返回错误消息,指出 “超时” 或 4xx 错误请求。 与 MLflow 配置类似,第三方客户端 API 可能会导致客户端超时,具体取决于其配置。 这些可能会影响模型服务终结点,这些终结点由使用这些第三方客户端 API 的管道组成。 请参阅 自定义 PyFunc 模型 和 PyFunc 自定义架构代理。
与 MLflow 配置调试指令类似,执行以下作来确定超时是由模型管道中使用的第三方客户端 API 导致的:
- 使用笔记本中的示例输入在本地测试模型。
- 如果在笔记本中看到 “超时” 消息,请调整第三方客户端超时窗口的任何相关参数。
- 示例 “超时” 消息:
APITimeoutError: Request timed out.
- 使用 POST 请求测试为终结点提供服务的模型。
- 如果启用了服务日志,请检查终结点的服务 日志 或推理表。
- 如果要提供自定义模型,请参阅 Unity 目录推理表架构。
- 如果您的终结点用于承载外部模型、预配的吞吐量工作负载或代理模型,请参阅 支持 Unity AI 网关的推理表架构。
- 如果启用了服务日志,请检查终结点的服务 日志 或推理表。
OpenAI 客户端示例
建立 OpenAI 客户端时,可以配置 timeout 参数,以更改客户端请求超时的最长时间。 OpenAI 客户端的默认和最大超时时间为 10 分钟。
以下示例重点介绍了如何配置第三方客户端 API 的超时设置。
%pip install openai
dbutils.library.restartPython()
from openai import OpenAI
import os
# How to get your Databricks token: https://docs.databricks.com/en/dev-tools/auth/pat.html
DATABRICKS_TOKEN = os.environ.get('DATABRICKS_TOKEN')
client = OpenAI(
timeout=10, # Number of seconds before client times out
api_key=DATABRICKS_TOKEN,
base_url="<WORKSPACE_URL>/serving-endpoints"
)
chat_completion = client.chat.completions.create(
messages=[
{
"role": "system",
"content": "You are an AI assistant"
},
{
"role": "user",
"content": "Tell me about Large Language Models."
}
],
model="model_name",
max_tokens=256
)
注释
对于 OpenAI 客户端,可以通过启用 流式处理来绕过最大超时窗口。
其他超时
闲置终结点预热
如果终结点 缩放为 0,并收到用于预热的请求,那么如果预热时所需时间过长,则可能会导致客户端超时。 这可能是管道中出现超时的原因,如上所述,管道利用了对预配置吞吐量终结点或矢量搜索索引的调用等步骤。
连接超时
连接超时与客户端等待与服务器建立连接的时间有关。 如果未在此时间内建立连接,客户端将取消尝试。 请务必注意模型管道中使用的客户端,并检查模型服务端点的服务日志和推理数据表,了解任何连接超时。 消息传送因服务而异。
- 例如, SocketTimeout (对于通过 JDBC 连接读取/写入 SQL 终结点的服务)可能如下所示:
jdbc:spark://<server-hostname>:443;HttpPath=<http-path>;TransportMode=http;SSL=1[;property=value[;property=value]];SocketTimeout=300
- 若要查找这些错误,请查找包含 术语“超时” 或 “timeout”的错误消息。
速率限制
通过终结点速率限制发出的多个请求可能会导致其他请求失败。 请参阅 资源和有效负载限制,了解基于终结点类型的速率限制。 对于第三方客户端,Databricks 建议查看正在使用的第三方客户端的文档。