txtai 是一个一体的嵌入数据库,用于语义搜索、LLM 业务流程和语言模型工作流。
MLflow 跟踪 为 txtai 提供自动跟踪功能。 可以通过调用 mlflow.txtai.autolog 函数来启用 txtai 的自动追踪,MLflow 将捕获 LLM 调用的追踪数据、嵌入、向量搜索,并将这些记录到当前活跃的 MLflow 实验。
先决条件
若要将 MLflow 跟踪与 txtai 配合使用,需要安装 MLflow、 txtai 库和 mlflow-txtai 扩展。
开发
对于开发环境,请安装带有“Databricks Extras”的完整 MLflow 包,txtai以及mlflow-txtai:
pip install --upgrade "mlflow[databricks]>=3.1" txtai mlflow-txtai
完整 mlflow[databricks] 包包括用于 Databricks 的本地开发和试验的所有功能。
生产
对于生产部署,请安装mlflow-tracing、txtai和mlflow-txtai。
pip install --upgrade mlflow-tracing txtai mlflow-txtai
包 mlflow-tracing 已针对生产用途进行优化。
注释
推荐使用 MLflow 3 以获得与 txtai 相关的最佳追踪体验。
在运行示例之前,需要配置环境:
对于不使用 Databricks 笔记本的用户:设置 Databricks 环境变量:
export DATABRICKS_HOST="https://your-workspace.cloud.databricks.com"
export DATABRICKS_TOKEN="your-personal-access-token"
对于 Databricks 笔记本中的用户:这些凭据会自动为您设置。
API 密钥:确保设置 LLM 提供程序 API 密钥:
export OPENAI_API_KEY="your-openai-api-key"
# Add other provider keys as needed if using txtai with different models
基本示例
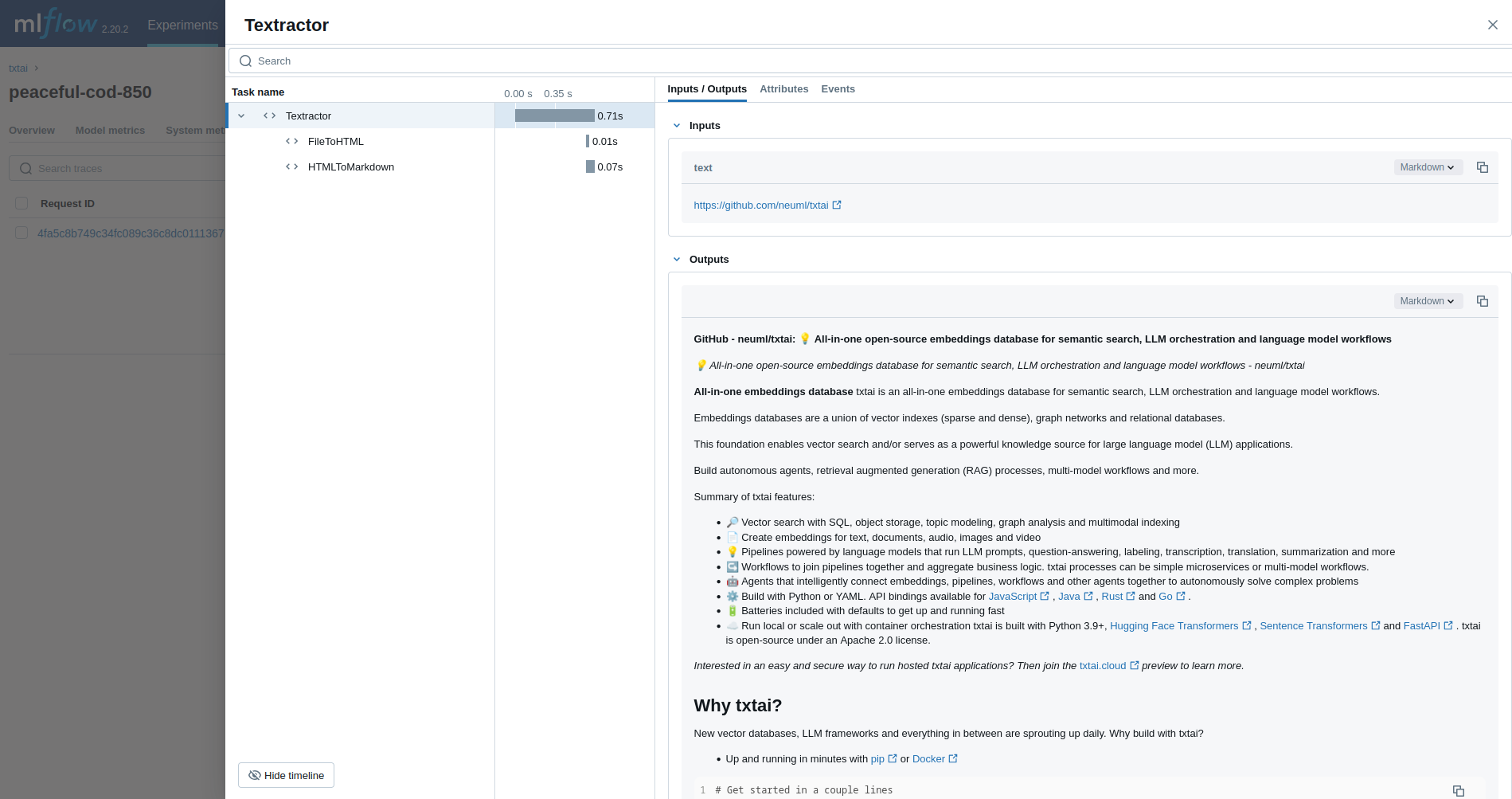
第一个示例跟踪 Textractor 管道。
import mlflow
from txtai.pipeline import Textractor
import os
# Ensure any necessary LLM provider API keys are set in your environment if Textractor uses one
# For example, if it internally uses OpenAI:
# os.environ["OPENAI_API_KEY"] = "your-openai-key"
# Enable MLflow auto-tracing for txtai
mlflow.txtai.autolog()
# Set up MLflow tracking to Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/txtai-demo")
# Define and run a simple Textractor pipeline.
textractor = Textractor()
textractor("https://github.com/neuml/txtai")
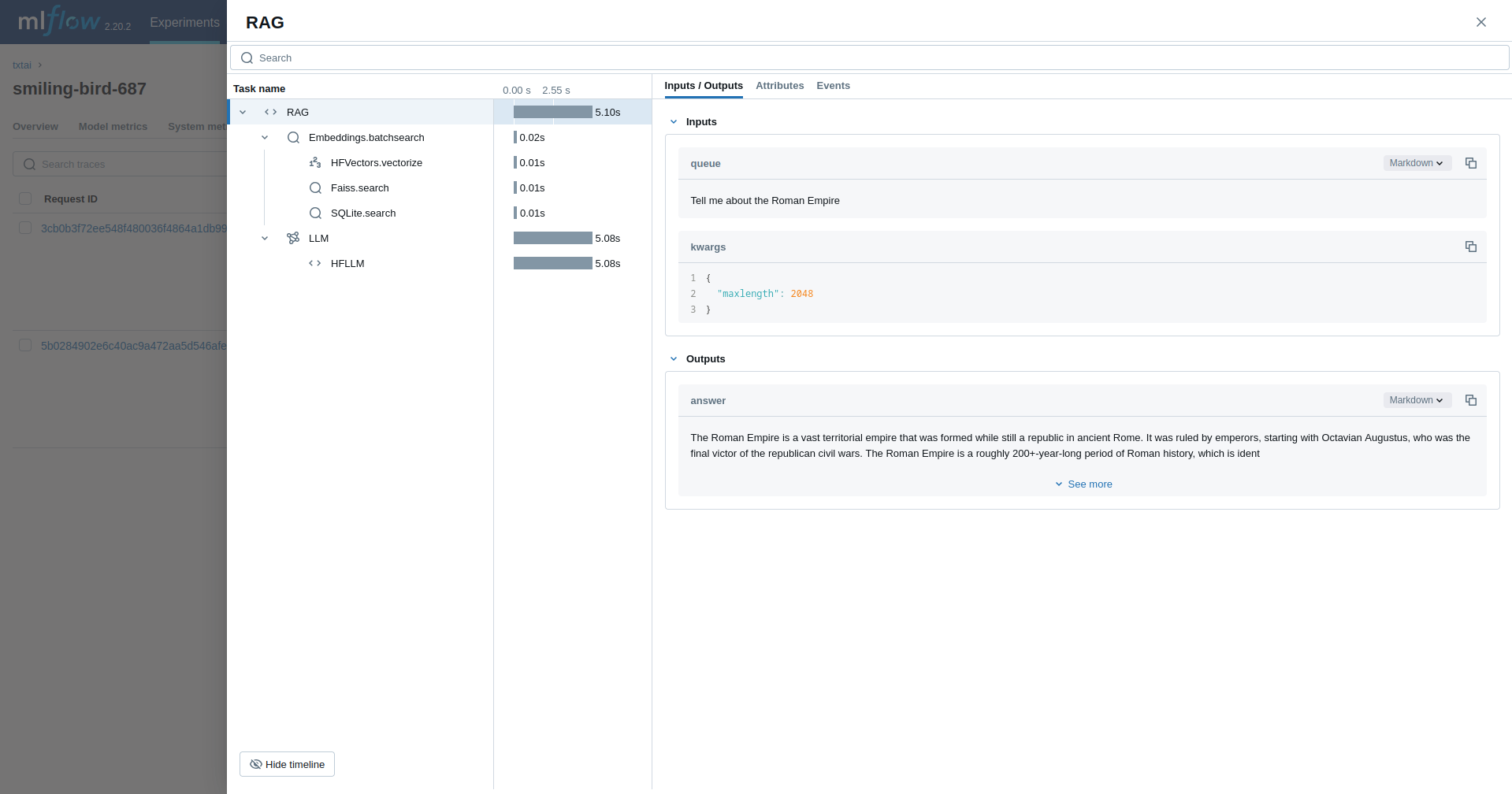
检索增强生成 (RAG)
下一个示例跟踪 RAG 管道。
import mlflow
from txtai import Embeddings, RAG
import os
# Ensure your LLM provider API key (e.g., OPENAI_API_KEY for the Llama model via some services) is set
# os.environ["OPENAI_API_KEY"] = "your-key" # Or HUGGING_FACE_HUB_TOKEN, etc.
# Enable MLflow auto-tracing for txtai
mlflow.txtai.autolog()
# Set up MLflow tracking to Databricks if not already configured
# mlflow.set_tracking_uri("databricks")
# mlflow.set_experiment("/Shared/txtai-rag-demo")
wiki = Embeddings()
wiki.load(provider="huggingface-hub", container="neuml/txtai-wikipedia-slim")
# Define prompt template
template = """
Answer the following question using only the context below. Only include information
specifically discussed.
question: {question}
context: {context} """
# Create RAG pipeline
rag = RAG(
wiki,
"hugging-quants/Meta-Llama-3.1-8B-Instruct-AWQ-INT4",
system="You are a friendly assistant. You answer questions from users.",
template=template,
context=10,
)
rag("Tell me about the Roman Empire", maxlength=2048)
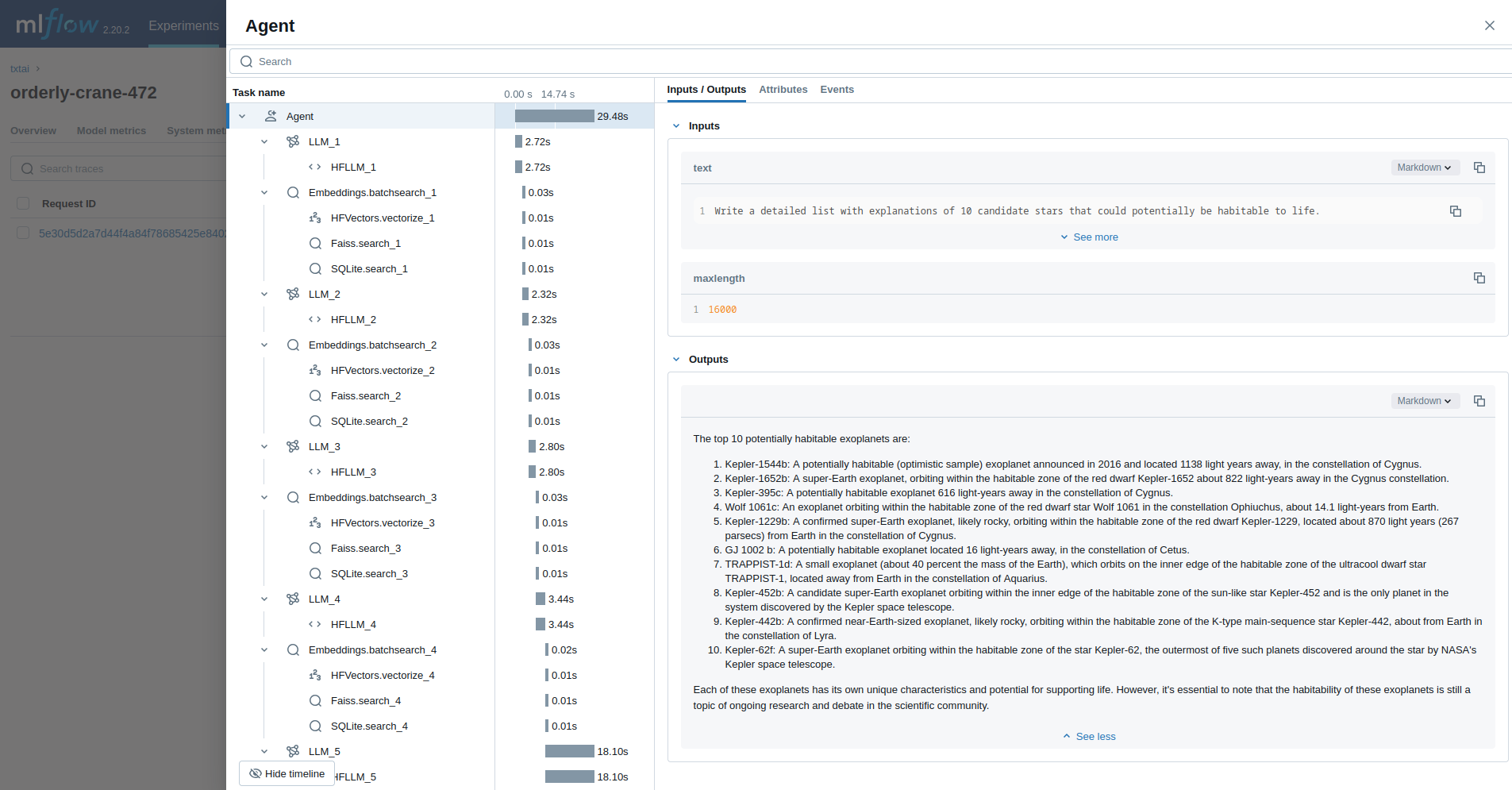
代理人
最后一个示例运行一个 txtai 代理 ,旨在研究天文问题。
import mlflow
from txtai import Agent, Embeddings
import os
# Ensure your LLM provider API key (e.g., OPENAI_API_KEY for the Llama model via some services) is set
# os.environ["OPENAI_API_KEY"] = "your-key" # Or HUGGING_FACE_HUB_TOKEN, etc.
# Enable MLflow auto-tracing for txtai
mlflow.txtai.autolog()
# Set up MLflow tracking to Databricks if not already configured
# mlflow.set_tracking_uri("databricks")
# mlflow.set_experiment("/Shared/txtai-agent-demo")
def search(query):
"""
Searches a database of astronomy data.
Make sure to call this tool only with a string input, never use JSON.
Args:
query: concepts to search for using similarity search
Returns:
list of search results with for each match
"""
return embeddings.search(
"SELECT id, text, distance FROM txtai WHERE similar(:query)",
10,
parameters={"query": query},
)
embeddings = Embeddings()
embeddings.load(provider="huggingface-hub", container="neuml/txtai-astronomy")
agent = Agent(
tools=[search],
llm="hugging-quants/Meta-Llama-3.1-8B-Instruct-AWQ-INT4",
max_iterations=10,
)
researcher = """
{command}
Do the following.
- Search for results related to the topic.
- Analyze the results
- Continue querying until conclusive answers are found
- Write a Markdown report
"""
agent(
researcher.format(
command="""
Write a detailed list with explanations of 10 candidate stars that could potentially be habitable to life.
"""
),
maxlength=16000,
)
详细信息
有关将 txtai 与 MLflow 配合使用的更多示例和指南,请参阅 MLflow txtai 扩展文档