重要
Lakebase 自动缩放在以下区域提供:eastus、eastus2、centralus、southcentralus、westus、westus2、canadacentral、brazilsouth、northeurope、uksouth、westeurope、australiaeast、centralindia、southeastasia。
Lakebase Autoscaling 是 Lakebase 的最新版本更新,具有自动缩放计算、缩放到零、分支和即时还原功能。 如果你是 Lakebase 预配的用户,请参阅 Lakebase 预配。
高可用性将主读/写计算与分布在可用性区域之间的一个或多个辅助计算实例配对。 当主计算实例不可用时,辅助计算实例会自动提升为主实例,应用程序将从最后提交的事务继续运行。 连接字符串保持不变。
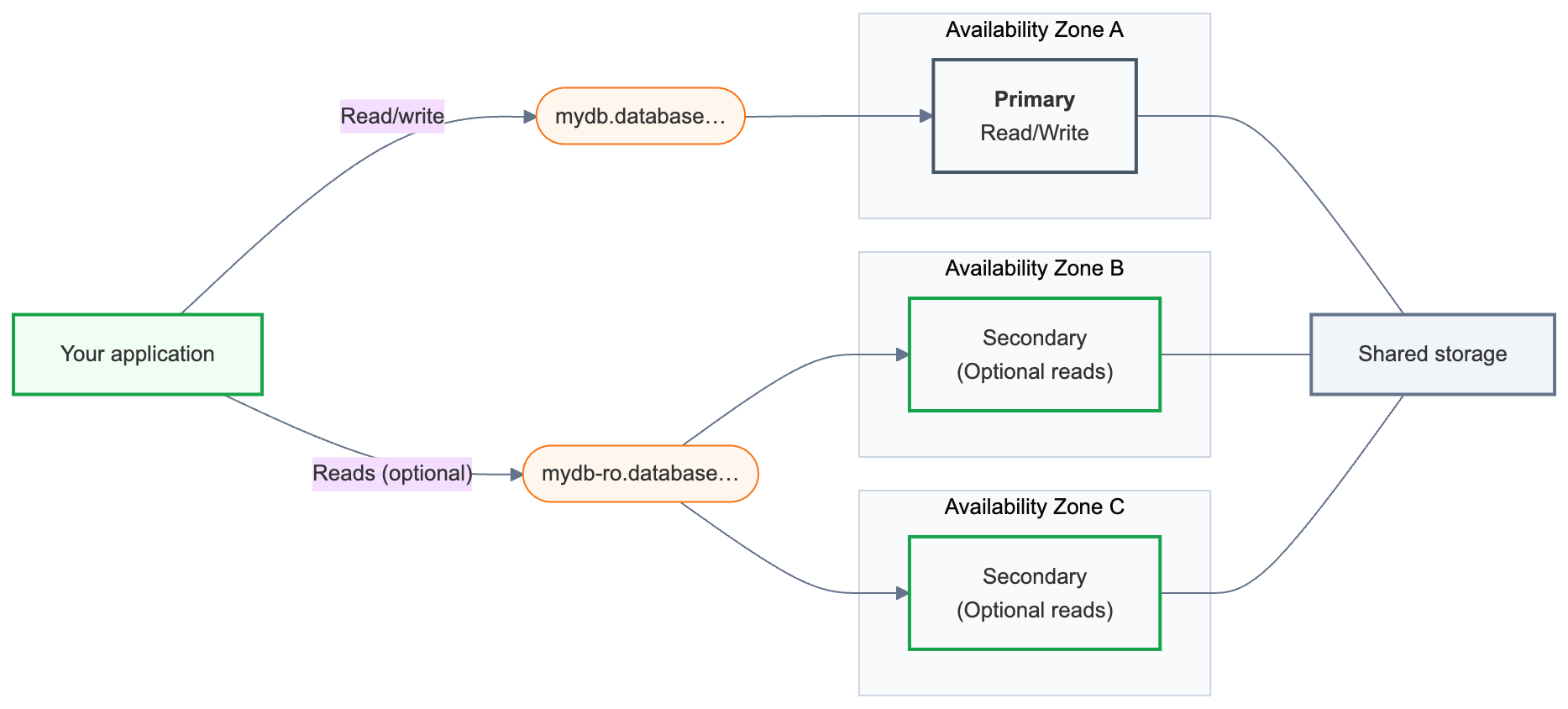
高可用性的工作原理
Lakebase 终结点是应用程序连接到的数据库地址。 高可用性端点外露两个连接字符串:
-
主要 (
{endpoint-id}.database.{region}.databricks.com)是您的主读/写连接。 在连接到数据库的每个应用程序中都使用此属性。 故障转移后,它会自动路由到当前作为主要的计算资源。 -
辅助 (
{endpoint-id}-ro.database.{region}.databricks.com) - 仅在启用 允许访问只读计算实例 时可用。 辅助计算实例主要作为故障转移备用实例存在;通过启用读取访问,可以额外将读取查询路由到它们上。
你可以从端点上的连接对话框获取这两个连接字符串。
在这些连接字符串后面,高可用性终结点始终只有一个 主 计算实例和一到三个 辅助 计算实例。 主服务器处理所有读/写流量。 辅助计算实例在不同的可用性区域中运行,并在发生故障时提升为主要实例。
每个辅助计算实例都有一个 Access 设置,用于确定是否也为读取流量提供服务:
| 辅助访问 | 它的作用是什么 |
|---|---|
| 只读 | 辅助计算实例通过 -ro 连接字符串提供读取,并可以根据需要提升为主实例 |
| 已禁用 | 辅助计算实例处于活动状态且已准备好进行故障转移,但不处理读取流量。 |
您可以通过终结点上的“允许访问只读计算实例”设置来控制此权限,该设置在“编辑计算”抽屉中可以访问。 启用后,所有辅助计算实例都提供读取;禁用时,它们仅在故障转移时处于备用状态。 在这两种情况下,计算硬件都已分配并正在运行:升级不需要新的预配,因此无论可用性区域中的需求如何,故障转移容量都是保留的。
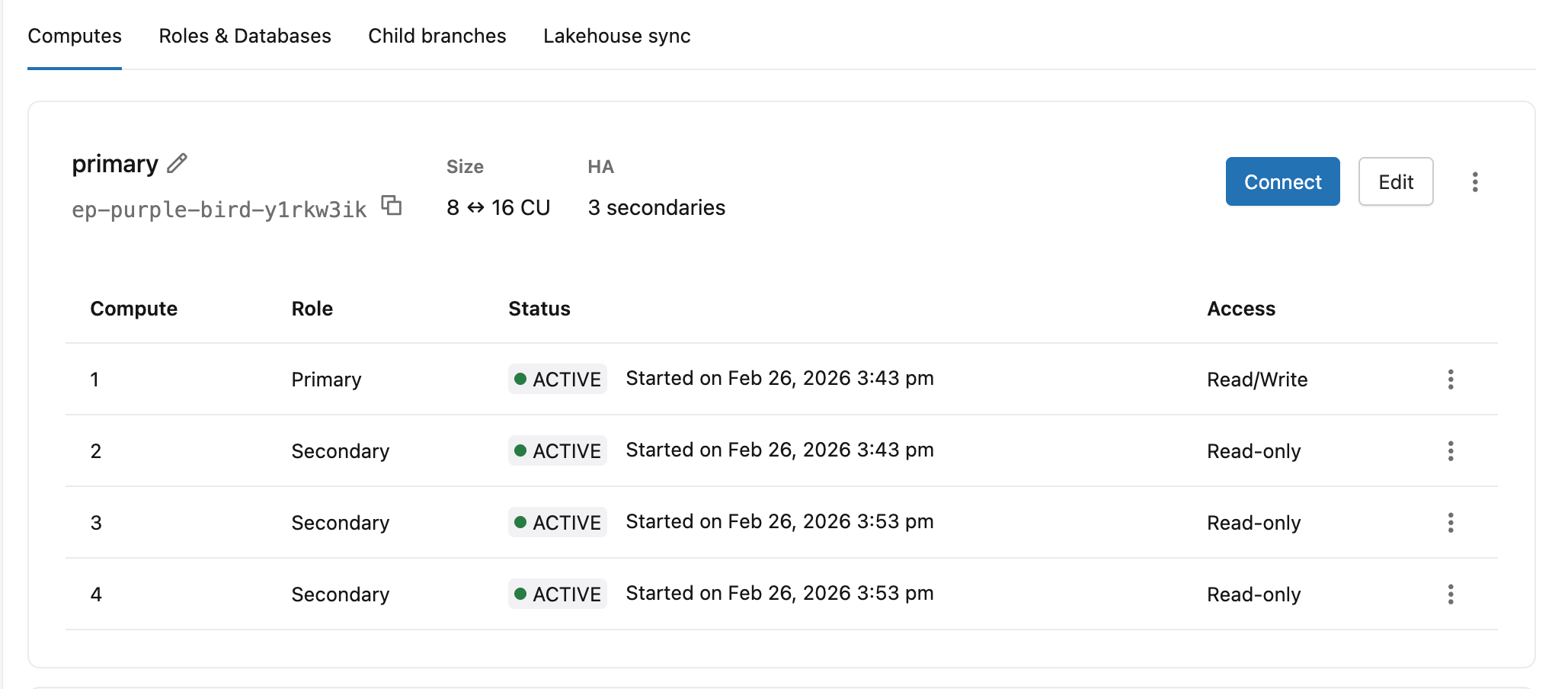
“计算”选项卡一目了然地显示每个计算实例 的角色 (主实例或辅助 角色)、状态和 访问 级别。
AZ 分发版
Lakebase 跨可用性区域分配主计算实例和辅助计算实例,从而减少单个 AZ 故障同时影响主计算实例和所有辅助计算实例的风险。
高可用性中的自动缩放
高可用性配置中的所有计算实例共享相同的自动缩放范围。 最小和最大 CU 之间的最大分布为 8 CU,与独立计算实例的限制相同。
辅助计算实例始终缩放为与主实例至少相同的 CU 大小,确保数据库容量在故障转移后保持一致。
缩放到零不适用于高可用性配置中的计算实例。 可以手动暂停所有计算实例,但终结点在暂停时将不可用。
次要计算实例与独立只读副本
辅助计算实例和独立只读副本是可以在同一分支上共存的不同功能:
| 辅助计算实例 | 独立数据库只读副本 | |
|---|---|---|
| Purpose | 故障转移 + 可选读取卸载 | 仅限读取分流 |
| 通过添加 |
高可用性配置 | 添加只读副本 |
| 参与故障转移 | 是的 | 否 |
| 连接字符串 |
-ro 在主端点上 |
拥有单独的终结点 |
| 调整大小 | 与主要(终结点级别)共享 | 独立调整大小 |
当需要高可用性和额外的读取容量超出辅助计算实例提供的功能时,可以在同一分支上合并这两个功能。 请查看 只读副本。
故障转移行为
自动故障转移 (automatic failover)
Lakebase 持续监视主要计算运行状况。 如果主节点不可用,则会自动触发故障转移。
故障转移保留所有已提交的事务。
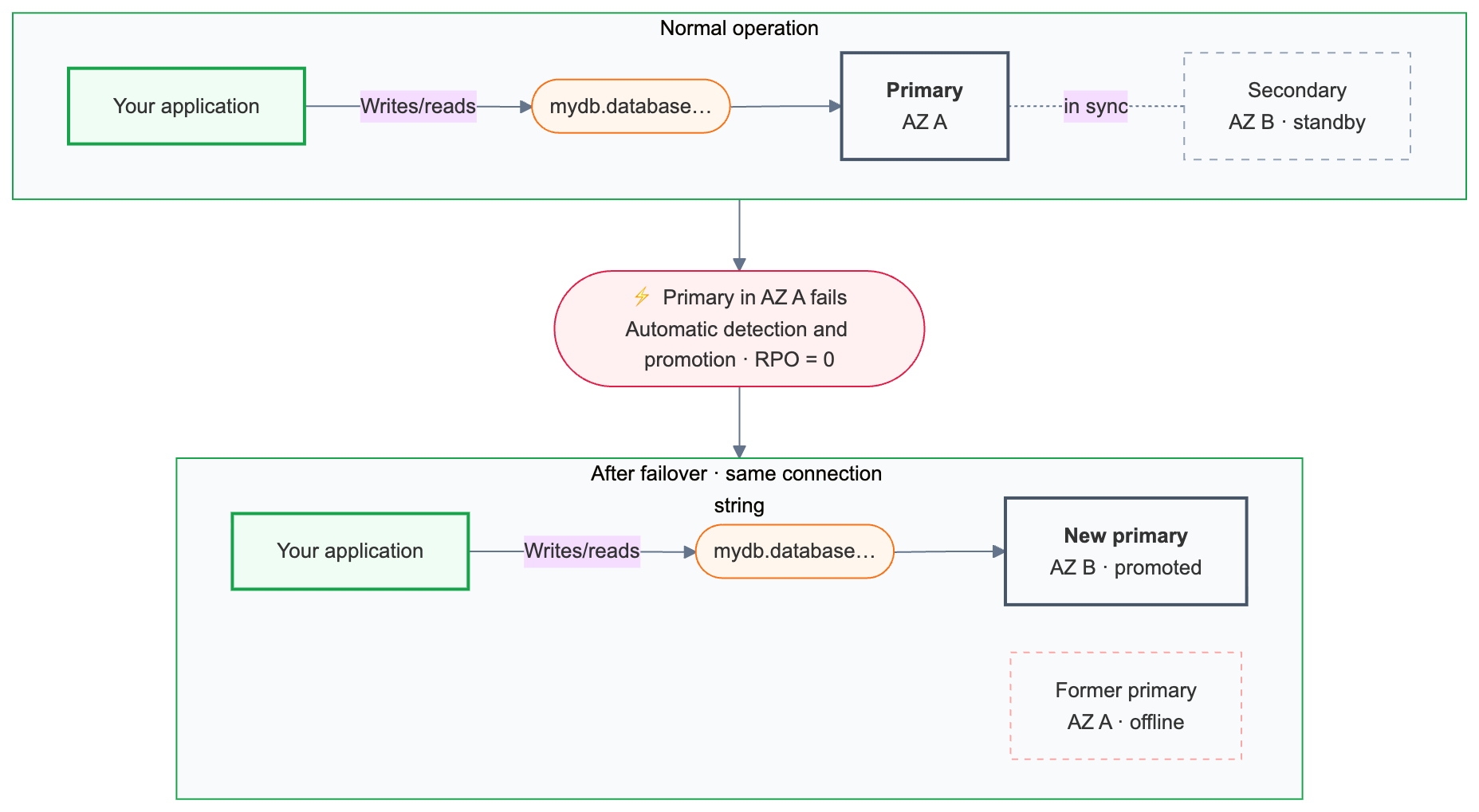
故障转移后,主连接字符串({endpoint-id}.database.{region}.databricks.com)会自动路由到新升级的计算实例。 应用程序不需要更改其连接配置,但现有连接在故障转移期间终止,必须重新连接。 具有重试逻辑的应用程序会自动处理此问题。
启用了只读访问的故障转移
启用 允许访问只读计算实例 并发生故障转移时,升级后的辅助数据库将成为新的主实例,并停止提供读取服务。 如果有两个或多个可读辅助数据库,则在预配替换之前,连接字符串上的 -ro 读取流量会继续减少。 如果您只有一个可用资源,读取操作将完全中断,直到替换准备就绪。
连接字符串
“ 连接 ”对话框显示两个连接字符串及其当前计算状态:
| “连接”对话框中的“计算”选项 | 连接字符串 | 用于 |
|---|---|---|
Primary (name) ● Active |
{endpoint-id}.database.{region}.databricks.com |
所有写入;必须命中当前主节点的读取 |
Secondary (name) ● Active RO |
{endpoint-id}-ro.database.{region}.databricks.com |
卸载读取至辅助计算实例(仅在启用 允许访问只读计算实例 时可用) |
主连接字符串始终路由到当前主数据库,包括故障转移后。
每个计算实例也有其自己的直接连接字符串,可通过每行上的操作菜单(⋮)从 “计算 ”选项卡访问。 直接连接用于对单个计算实例进行故障排除,而不是应用程序使用。 直接连接字符串是根据计算节点进行配置的,在添加、删除或提升辅助节点时可能会发生更改。
高可用性限制
| Limit | 价值 |
|---|---|
| 计算实例 | 2、3 或 4(1 个主计算实例 + 1-3 个辅助计算实例) |
| 自动缩放范围(最大值−最小值) | 最大值与最小值之间的差距≤ 8 CU |
| 缩放到零 | 在高可用性配置中,不适用于计算机实例 |
最佳做法
遵循这些做法有助于应用程序在故障转移事件期间保持复原能力和可用状态。
| 练习 | 详细信息 |
|---|---|
| 实现连接重试逻辑 | 活动连接在故障转移期间终止。 与故障的主节点的连接可能会挂起直到超时 — 在驱动程序中配置 TCP keepalives 或设置连接超时,以便及时检测故障。 与被提升的次要数据库的连接会主动终止,并立即返回错误。 带有重试逻辑的应用程序会在数秒内自动重新连接。 |
| 为用例配置辅助计数 | 每个辅助计算实例表示为故障转移预留的预分配硬件。 减少次级计数意味着故障转移容量的减少以及覆盖的可用性区域的减少。 一个辅助计算实例提供故障切换保护。 如果启用可读辅助数据库,请配置两个或更多个。 当只有一个时,在故障转移期间读取将完全中断,直到提供替换。 |
| 避免重载辅助计算实例 | 该服务可能会重启重载或落后的辅助计算实例。 监视查询负载和连接计数,如果观察到持续的高利用率,则增加 CU 大小。 |