Shiny 是 CRAN 上提供的 R 包,用于生成交互式 R 应用程序和仪表板。 可以在 Azure Databricks 集群上托管的 RStudio 服务器中使用 Shiny。 也可直接从 Azure Databricks 笔记本开发、托管和共享 Shiny 应用程序。
若要开始使用 Shiny,请参阅 Shiny 教程。 可以在 Azure Databricks 笔记本上运行这些教程。
本文介绍如何在 Azure Databricks 上运行 Shiny 应用程序以及如何在 Shiny 应用程序中使用 Apache Spark。
R 笔记本中的 Shiny
Databricks Runtime 中包含了 Shiny 包。 可以像在托管的 RStudio 中那样,在 Azure Databricks R 笔记本中以交互方式开发和测试 Shiny 应用程序。
开始在 R 笔记本中使用 Shiny
执行以下步骤以便开始:
创建 R 笔记本。
导入 Shiny 包并按以下方式运行示例应用
01_hello:library(shiny) runExample("01_hello")应用准备就绪后,输出将包含可单击链接形式的 Shiny 应用 URL,单击该链接可打开新的选项卡。若要与其他用户共享此应用,请参阅共享 Shiny 应用 URL。
注意
- 日志消息将显示在命令结果中,类似于示例中显示的默认日志消息 (
Listening on http://0.0.0.0:5150)。 - 若要停止 Shiny 应用程序,请单击“取消”。
- Shiny 应用程序使用笔记本 R 进程。 如果从群集中分离笔记本或者如果取消正在运行应用程序的单元,则 Shiny 应用程序将会终止。 当 Shiny 应用程序正在运行时,无法运行其他单元。
在 Databricks Git 文件夹中运行 Shiny 应用程序。
可以运行已签入 Databricks Git 文件夹的 Shiny 应用。
运行应用程序。
library(shiny) runApp("006-tabsets")
从文件中运行 Shiny 应用
如果 Shiny 应用程序代码是由版本控制系统管理的项目的一部分,则你可以在笔记本中运行这些代码。
注意
必须使用绝对路径,或使用 setwd() 设置工作目录。
使用类似以下的代码从存储库中检出代码:
%sh git clone https://github.com/rstudio/shiny-examples.git cloning into 'shiny-examples'...若要运行该应用程序,请在另一个单元中输入如下所示的代码:
library(shiny) runApp("/databricks/driver/shiny-examples/007-widgets/")
分享 Shiny 应用程序的 URL
启动应用时生成的 Shiny 应用 URL 可与其他用户共享。 只要应用和群集都在运行,在群集上拥有“可附加到”权限的任何 Azure Databricks 用户都可以查看应用并与之交互。
如果运行该应用的群集已终止,则该应用不再可访问。 可以在群集设置中禁用自动终止。
如果你在其他群集上附加并运行托管 Shiny 应用的笔记本,则 Shiny URL 将会更改。 此外,如果你在同一群集上重启应用,Shiny 可能会选择其他随机端口。 为确保 URL 稳定,可以设置 shiny.port 选项,或者,在同一群集上重启应用时可以指定 port 参数。
Shiny 在托管的 RStudio 服务器上
重要
Databricks 托管的 RStudio Server 已遭弃用,仅适用于 Databricks Runtime 版本 15.4 及更低版本。 有关其他选项,请参阅 托管 RStudio Server 的替代项。
要求
重要
使用 RStudio Server Pro 时,必须禁用代理身份验证。
确保 auth-proxy=1 中没有 /etc/rstudio/rserver.conf。
开始
在 Azure Databricks 上打开 RStudio。
在 RStudio 中,导入 Shiny 包并按以下方式运行示例应用
01_hello:> library(shiny) > runExample("01_hello") Listening on http://127.0.0.1:3203出现一个新窗口,显示 Shiny 应用程序。
通过 R 脚本运行 Shiny 应用
若要通过 R 脚本运行 Shiny 应用,请在 RStudio 编辑器中打开 R 脚本,然后点击右上角的“运行应用”按钮。
在 Shiny 应用内部使用 Apache Spark
可以通过 SparkR 或 sparklyr 在 Shiny 应用程序中使用 Apache Spark。
在笔记本中将 SparkR 与 Shiny 配合使用
重要
Databricks 中的 SparkR 在 Databricks Runtime 16.0 及更高版本中已弃用。
library(shiny)
library(SparkR)
sparkR.session()
ui <- fluidPage(
mainPanel(
textOutput("value")
)
)
server <- function(input, output) {
output$value <- renderText({ nrow(createDataFrame(iris)) })
}
shinyApp(ui = ui, server = server)
在笔记本中将 sparklyr 与 Shiny 配合使用
library(shiny)
library(sparklyr)
sc <- spark_connect(method = "databricks")
ui <- fluidPage(
mainPanel(
textOutput("value")
)
)
server <- function(input, output) {
output$value <- renderText({
df <- sdf_len(sc, 5, repartition = 1) %>%
spark_apply(function(e) sum(e)) %>%
collect()
df$result
})
}
shinyApp(ui = ui, server = server)
library(dplyr)
library(ggplot2)
library(shiny)
library(sparklyr)
sc <- spark_connect(method = "databricks")
diamonds_tbl <- spark_read_csv(sc, path = "/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
# Define the UI
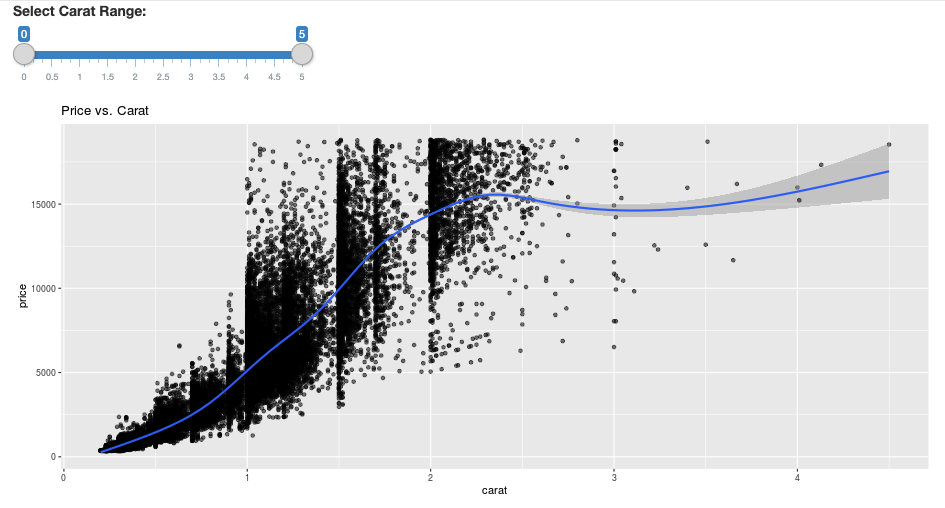
ui <- fluidPage(
sliderInput("carat", "Select Carat Range:",
min = 0, max = 5, value = c(0, 5), step = 0.01),
plotOutput('plot')
)
# Define the server code
server <- function(input, output) {
output$plot <- renderPlot({
# Select diamonds in carat range
df <- diamonds_tbl %>%
dplyr::select("carat", "price") %>%
dplyr::filter(carat >= !!input$carat[[1]], carat <= !!input$carat[[2]])
# Scatter plot with smoothed means
ggplot(df, aes(carat, price)) +
geom_point(alpha = 1/2) +
geom_smooth() +
scale_size_area(max_size = 2) +
ggtitle("Price vs. Carat")
})
}
# Return a Shiny app object
shinyApp(ui = ui, server = server)
常见问题 (FAQ)
- 为什么我的 Shiny 应用会在一段时间后“灰显”?
- 为什么我的 Shiny 查看器窗口会在一段时间后消失?
- 为何长时间的 Spark 作业从未完成?
- 如何避免超时?
- 我的应用启动后立即崩溃,但代码似乎是正确的。 这是怎么回事?
- 在开发过程中,一个 Shiny 应用链接可以接受多少个连接?
- 可以使用与 Databricks Runtime 中安装的版本不同的 Shiny 包吗?
- 如何开发可以发布到 Shiny 服务器的 Shiny 应用并访问 Azure Databricks 上的数据?
- 可以在 Azure Databricks 笔记本中开发 Shiny 应用程序吗?
- 如何保存在托管的 RStudio Server 上开发的 Shiny 应用程序?
为什么我的 Shiny 应用程序在一段时间后会变为灰色?
如果没有与 Shiny 应用交互,则大约 4 分钟后将关闭与该应用的连接。
要重新连接,请刷新 Shiny 应用页面。 仪表板状态重置。
为什么我的 Shiny 查看器窗口会在一段时间后消失?
如果 Shiny 查看器窗口在空闲几分钟后消失,这是由于与“窗口变灰”场景相同的超时机制导致的。
为什么长时间运行的 Spark 作业总是无法结束?
这也是由于空闲超时。 运行时间超过前面提到的超时时间的任何 Spark 作业都无法呈现其结果,因为连接将在作业返回之前关闭。
如何避免超时?
在 Github 的 功能请求:让客户端发送“保持连接”消息,以防止某些负载均衡器上出现 TCP 超时中,提出了一个解决方法。 该解决方法在应用程序处于空闲状态时发送心跳信号,以使 WebSocket 连接保持活动状态。 但是,如果该应用被长时间运行的计算所阻止,则此解决方法将不起作用。
Shiny 系统不支持长时间运行的任务。 Shiny 的博客文章建议使用 承诺和期货 来异步运行长时间任务,并保持应用程序不被阻塞。 这是一个使用心跳信号使 Shiny 应用保持在线状态,并在
future构造中执行长时间运行的 Spark 作业的示例。# Write an app that uses spark to access data on Databricks # First, install the following packages: install.packages('future') install.packages('promises') library(shiny) library(promises) library(future) plan(multisession) HEARTBEAT_INTERVAL_MILLIS = 1000 # 1 second # Define the long Spark job here run_spark <- function(x) { # Environment setting library("SparkR", lib.loc = "/databricks/spark/R/lib") sparkR.session() irisDF <- createDataFrame(iris) collect(irisDF) Sys.sleep(3) x + 1 } run_spark_sparklyr <- function(x) { # Environment setting library(sparklyr) library(dplyr) library("SparkR", lib.loc = "/databricks/spark/R/lib") sparkR.session() sc <- spark_connect(method = "databricks") iris_tbl <- copy_to(sc, iris, overwrite = TRUE) collect(iris_tbl) x + 1 } ui <- fluidPage( sidebarLayout( # Display heartbeat sidebarPanel(textOutput("keep_alive")), # Display the Input and Output of the Spark job mainPanel( numericInput('num', label = 'Input', value = 1), actionButton('submit', 'Submit'), textOutput('value') ) ) ) server <- function(input, output) { #### Heartbeat #### # Define reactive variable cnt <- reactiveVal(0) # Define time dependent trigger autoInvalidate <- reactiveTimer(HEARTBEAT_INTERVAL_MILLIS) # Time dependent change of variable observeEvent(autoInvalidate(), { cnt(cnt() + 1) }) # Render print output$keep_alive <- renderPrint(cnt()) #### Spark job #### result <- reactiveVal() # the result of the spark job busy <- reactiveVal(0) # whether the spark job is running # Launch a spark job in a future when actionButton is clicked observeEvent(input$submit, { if (busy() != 0) { showNotification("Already running Spark job...") return(NULL) } showNotification("Launching a new Spark job...") # input$num must be read outside the future input_x <- input$num fut <- future({ run_spark(input_x) }) %...>% result() # Or: fut <- future({ run_spark_sparklyr(input_x) }) %...>% result() busy(1) # Catch exceptions and notify the user fut <- catch(fut, function(e) { result(NULL) cat(e$message) showNotification(e$message) }) fut <- finally(fut, function() { busy(0) }) # Return something other than the promise so shiny remains responsive NULL }) # When the spark job returns, render the value output$value <- renderPrint(result()) } shinyApp(ui = ui, server = server)从加载初始页面起,有 12 小时的硬性限制,在此之后,任何连接(即使是活动连接)都将被终止。 在这种情况下,必须刷新 Shiny 应用才能重新连接。 但是,基础 WebSocket 连接可能随时因各种因素(包括网络不稳定或计算机处于睡眠模式)而关闭。 Databricks 建议重新编写 Shiny 应用,使它们不需要长期连接且不会过度依赖会话状态。
我的应用启动后立即崩溃,但代码似乎是正确的。 这是怎么回事?
在 Azure Databricks 上的 Shiny 应用中可以显示的数据总量有 50 MB 的限制。 如果应用程序的总数据大小超过此限制,则启动后将立即崩溃。 为了避免这种情况,Databricks 建议减小数据大小,例如通过降低显示数据的采样率或降低图像的分辨率。
在开发过程中,一个 Shiny 应用链接可以接受多少个连接?
Databricks 建议最多 20 个。
可以使用与 Databricks Runtime 中安装的版本不同的 Shiny 包吗?
是的。 请查阅修正 R 包的版本。
如何开发可以发布到 Shiny 服务器的 Shiny 应用并访问 Azure Databricks 上的数据?
虽然你可以在开发和测试 Azure Databricks期间使用 SparkR 或 sparklyr 自然地访问数据,但是在一个 Shiny 应用程序发布到独立托管服务之后,它不能直接访问 Azure Databricks 上的数据和表。
若要使你的应用程序在 Azure Databricks 外部运行,必须重写访问数据的方式。 下面是几个选项:
- 使用 JDBC / ODBC 将查询提交到 Azure Databricks 群集。
- 使用 Databricks Connect。
- 直接访问对象存储上的数据。
Databricks 建议你与 Azure Databricks 解决方案团队合作,为现有数据和分析体系结构找到最佳方法。
可以在 Azure Databricks 笔记本中开发 Shiny 应用程序吗?
是的,可以在 Azure Databricks 笔记本中开发 Shiny 应用程序。
如何保存在托管的 RStudio Server 上开发的 Shiny 应用程序?
你可以将应用程序代码保存在 DBF 上,也可以将代码签入版本控制中。