本页介绍如何将 Delta 表用作 Spark 结构化流式处理 的源和 readStream 以及 writeStream 的汇。 Delta Lake 解决了流系统和文件的常见性能和可靠性问题。 其优势包括:
- 合并低延迟摄取生成的小型文件,提高性能。
- 使用多个流(或并发批处理作业)实现"精确一次"处理。
- 使用文件作为流源时有效地发现新文件。
若要了解如何在 Databricks SQL 中使用流式处理表加载数据,请参阅 Databricks SQL 中使用流式处理表。
有关 Delta Lake 的流静态联接,请参阅 stream-static joins。
将 Delta 表用作接收器
可以使用结构化流式处理将数据写入 Delta 表。 Delta Lake 事务日志保证精确一次处理,即使有其他流或批处理查询同时针对表运行。
使用结构化流处理接收器写入 Delta 表时,可能会看到带有 epochId = -1 的空提交。 这些是预期的,通常会发生:
- 在每次流式处理查询运行的第一批(这将在每个批处理中发生
Trigger.AvailableNow)。 - 更改架构时(例如添加列)。
这些空提交是有意的,并不指示错误。 它们不会以任何重要方式影响查询的正确性或性能。
Note
Delta Lake VACUUM 函数会删除所有不由 Delta Lake 管理的文件,但会跳过所有以 _ 开头的目录。 可以使用 <table-name>/_checkpoints 等目录结构将检查点与 Delta 表的其他数据和元数据一起安全地存储。
使用指标监视积压工作
使用以下指标监控 流式查询进程的积压情况:
-
numBytesOutstanding:积压工作中尚未处理的字节数。 -
numFilesOutstanding:积压工作中尚未处理的文件数。 -
numNewListedFiles:列出用于计算此批积压的 Delta Lake 文件数。 -
backlogEndOffset:用于计算积压工作的 Delta 表版本。
在笔记本中,在流式处理查询进度仪表板的 “原始数据 ”选项卡下查看这些指标:
{
"sources": [
{
"description": "DeltaSource[file:/path/to/source]",
"metrics": {
"numBytesOutstanding": "3456",
"numFilesOutstanding": "8"
}
}
]
}
追加模式
默认情况下,数据流在追加模式下运行,并且只向表中添加新记录。
使用toTable方法来流式传输到表:
Python
(events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
)
Scala
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
完整模式
使用具有完整模式的结构化流式处理在每个批处理后替换整个表。 例如,可以按客户持续更新聚合的汇总事件表:
Python
(spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
)
Scala
spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
对于没有严格延迟要求的应用程序,可以使用一次性触发器(例如 AvailableNow)节省计算资源和成本。 例如,使用此触发器按给定计划更新摘要聚合表,只处理自上次更新以来到达的新数据。 请参阅 AvailableNow:增量批处理。
处理源 Delta 表的改动
结构化流式处理以增量方式读取 Delta 表。 当流式查询从 Delta 表读取时,随着新表版本提交到源表,新记录将以幂等方式进行处理。 结构化流式处理仅接受追加输入,如果源 Delta 表发生任何修改,则会引发异常。 例如,如果某个UPDATE、DELETE或MERGE INTOOVERWRITE操作修改流式处理查询读取的源 Delta 表,则流将失败并显示错误。
根据用例,有四种典型的方法可用于处理源 Delta 表的上游更改。 下面提供了一个参考表以及每项的详细信息。
| 方法 | Pros | 缺点 |
|---|---|---|
skipChangeCommits |
简单,不需要编写复杂的逻辑。 有用的仅追加处理用于单独处理上游变化,或暂时处理错误的记录。 | 不传递更改,只处理追加。 |
| 完全刷新 | 同样简单,不需要编写复杂的逻辑。 对于具有极少数上游更改的小型数据集非常有用。 | 大型数据集的成本高昂。 需要重新处理所有下游表。 |
| 更改数据流 | 处理所有更改类型(插入、更新和删除)。 Databricks 建议尽可能从 Delta 表的 CDC 源进行流式处理,而不是直接从表中流式传输。 | 需要编写更复杂的逻辑来处理每个更改类型。 |
| 实例化视图 | 具有自动更改传播的结构化流式处理简单替代方法。 | 更高的延迟。 仅在 Lakeflow Spark 声明性管道和 Databricks SQL 中可用。 |
跳过上游更改提交 skipChangeCommits
设置为 skipChangeCommits 忽略删除或修改现有记录的事务,并仅处理追加。 当不需要通过流传播对现有数据的更改,或者首选单独的逻辑来处理这些更改时,这非常有用。 如果需要暂时忽略一次性更改,可以打开和关闭 skipChangeCommits 。
Databricks 建议对不使用更改数据馈送的大多数工作负荷使用 skipChangeCommits 。
Python
(spark.readStream
.option("skipChangeCommits", "true")
.table("source_table")
)
Scala
spark.readStream
.option("skipChangeCommits", "true")
.table("source_table")
Important
如果在开始针对表进行流式读取后 Delta 表的架构发生更改,查询将会失败。 对于大多数架构更改,可以重启流以解决架构不匹配问题并继续处理。
在 Databricks Runtime 12.2 LTS 及更低版本中,无法从启用了列映射且经历了非累加架构演变(例如重命名或删除列)的 Delta 表进行流式处理。 有关详细信息,请参阅 列映射和流式处理。
Note
在 Databricks Runtime 12.2 LTS 及更高版本中, skipChangeCommits 替换 ignoreChanges。 在 Databricks Runtime 11.3 LTS 及更低版本中,ignoreChanges 是唯一受支持的选项。 请查看 旧选项 ignoreChanges 以获取详细信息。
旧选项:ignoreDeletes
ignoreDeletes 是一个旧选项,它仅处理在分区边界处删除数据的事务(即完全分区删除)。 如果需要处理非分区删除、更新或其他修改,请改用 skipChangeCommits 。
Python
(spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
)
Scala
spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
旧选项:ignoreChanges
ignoreChanges 在 Databricks Runtime 11.3 LTS 和更低版本中提供。 在 Databricks Runtime 12.2 LTS 及更高版本中,它将替换为 skipChangeCommits。
在启用 ignoreChanges 后,当发生数据修改操作(例如 UPDATE、MERGE INTO(在 DELETE 分区内)或 OVERWRITE)之后,将重新发出源表中重写的数据文件。 未更改的行通常与新行一起发布,因此下游数据使用者必须能够处理重复项。 删除不会传播到下游。
ignoreChanges 优先于 ignoreDeletes。
相比之下, skipChangeCommits 完全忽略更改文件的操作。 由于数据修改操作(例如 UPDATE、MERGE INTO、DELETE 和 OVERWRITE),源表中的数据文件会被重写,但随之而来的更改将被完全忽略。 若要反映流源表中的更改,必须实现单独的逻辑来传播这些更改。
Databricks 建议对所有新工作负荷使用 skipChangeCommits 。 若要从 ignoreChanges 中 skipChangeCommits迁移工作负荷,请重构流式处理逻辑。
下游表的完全刷新
如果上游更改稀少,并且数据量小到足以重新处理,可以删除流处理检查点和输出表,然后从头开始重新启动数据流。 这会导致流重新处理源表中的所有数据。 请注意,此方法还需要重新处理依赖于此流的输出的所有下游表。
此方法最适合较小的数据集或工作负荷,其中上游更改不频繁,并且完全刷新的成本是可接受的。
使用更改数据馈送
对于处理所有类型更改(插入、更新和删除)的工作负载,请使用 Delta Lake 更改数据流。 更改数据馈送记录对 Delta 表的行级更改,使你可以流式传输这些更改,并编写逻辑来处理下游表中的每个更改类型。 这是最可靠的方法,因为代码显式处理每种类型的更改事件。 请参阅 在 Azure Databricks 上使用 Delta Lake 更改数据流。
如果使用 Lakeflow Spark 声明性管道,请参阅 AUTO CDC API:使用管道简化更改数据捕获。
Important
在 Databricks Runtime 12.2 LTS 及以下版本中,无法从启用了列映射且经历过非追加性架构演变的 Delta 表进行更改数据馈送的流式传输,例如重命名或删除列。 请参阅 列映射和流式处理。
使用具体化视图
具体化视图通过在源数据更改时重新计算结果自动处理上游更改。 如果不需要尽可能低的延迟并且想要避免管理流式处理复杂性,具体化视图可以简化体系结构。 具体化视图在 Lakeflow Spark 声明性管道管道和 Databricks SQL 中可用。 请参阅 具体化视图。
Example
例如,假设你有一个表 user_events,其中包含 date、user_email 和 action 列,并按 date 对该表进行了分区。 从 user_events 表向外进行流式处理,由于 GDPR 的原因,需要从中删除数据。
skipChangeCommits允许您删除多个分区中的数据(在此示例中,按照user_email进行筛选)。 使用以下语法:
spark.readStream
.option("skipChangeCommits", "true")
.table("user_events")
如果使用 user_email 语句更新 UPDATE,则包含相关 user_email 的文件将被重写。 使用 skipChangeCommits 忽略更改的数据文件。
Databricks 建议使用 skipChangeCommits ,除非您确定删除始终是完整分区删除,否则不推荐使用 ignoreDeletes。
请使用 进行幂等表写入
Note
Databricks 建议为每个需要更新的输出目标配置单独的流式写入,而不是使用 foreachBatch。 向多个接收器写入 foreachBatch 会减少并行化并增加整体延迟,因为向多个表写入在 foreachBatch 中是按序列进行的。
Delta 表支持以下 DataFrameWriter 选项,以使对多个 foreachBatch 表的写入具备幂等性:
-
txnAppId:可以在每次 DataFrame 写入时传递的唯一字符串。 例如,可以使用 StreamingQuery ID 作为txnAppId。txnAppId可以是任何用户生成的唯一字符串,不必与流 ID 相关。 -
txnVersion:充当事务版本的单调递增数字。
Delta Lake 使用 txnAppId 和 txnVersion 来识别并忽略重复写入。 例如,在失败中断批处理写入后,可以使用相同的txnAppId和txnVersion重新运行批处理,以正确识别并忽略重复项。 请参阅使用 foreachBatch 将内容写入到任意数据接收器。
Warning
如果删除流式处理检查点并使用新检查点重新启动查询,则必须提供其他 txnAppId。 新检查点以 0 的批 ID 开头。 Delta Lake 使用批 ID 和 txnAppId 作为唯一键,并跳过已见值的批次。
以下代码示例演示了此模式:
Python
app_id = ... # A unique string that is used as an application ID.
def writeToDeltaLakeTableIdempotent(batch_df, batch_id):
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 1
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 2
streamingDF.writeStream.foreachBatch(writeToDeltaLakeTableIdempotent).start()
Scala
val appId = ... // A unique string that is used as an application ID.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 1
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 2
}
使用 foreachBatch 从流式处理查询中更新插入
可以使用merge和foreachBatch将流式查询的复杂上插写入 Delta 表。 请参阅使用 foreachBatch 将内容写入到任意数据接收器。
此方法有许多应用程序:
- 使用
update输出模式提高写入性能,而complete输出模式需要为每个微分块重写整个结果表。 - 使用合并查询将更改数据流持续应用于 Delta 表,以写入更改数据
foreachBatch。 请参阅 Delta Lake 的渐变数据(SCD)和变更数据捕获(CDC)。 - 在流处理过程中进行去重。 可以使用“仅插入”合并查询在
foreachBatch中持续将数据写入自动去重的 Delta 表。 在写入 Delta 表时,请参阅数据去重。
Note
验证
merge中的foreachBatch语句是否幂等。 否则,重新启动流式查询时可能对同一批数据多次执行操作。 请参阅 “用于foreachBatch幂等表写入”。使用
merge在foreachBatch时,输入数据速率指标可能会返回一个是源头数据生成速率倍数的结果。merge多次读取输入数据,这将增加度量指标。 若要防止指标乘法,请在之前merge缓存批处理数据帧,然后在之后merge将其取消缓存。可通过
StreamingQueryProgress和笔记本流式处理速率图获取输入数据速率。 请参阅 Azure Databricks 上的结构化流式查询监控。
例如,您可以在MERGEforeachBatch中使用SQL语句:
Scala
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
// Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
// Use the view name to apply MERGE
// NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
# Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
# Use the view name to apply MERGE
# NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
# In Databricks Runtime 10.5 and below, you must use the following:
# microBatchOutputDF._jdf.sparkSession().sql("""
microBatchOutputDF.sparkSession.sql("""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
还可以使用 Delta Lake APIs 进行流式插入和更新:
Scala
import io.delta.tables.*
val deltaTable = DeltaTable.forName(spark, "table_name")
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
deltaTable.as("t")
.merge(
microBatchOutputDF.as("s"),
"s.key = t.key")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
from delta.tables import *
deltaTable = DeltaTable.forName(spark, "table_name")
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
(deltaTable.alias("t").merge(
microBatchOutputDF.alias("s"),
"s.key = t.key")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
设置初始表版本以处理更改
默认情况下,数据流从最新的可用 Delta 表版本开始。 这包括当时表的完整快照以及所有将来的更改。 Databricks 建议对大多数工作负荷使用默认的初始表版本。
可以选择使用以下选项来指定 Delta Lake 流式处理源的开始位置,而无需处理整个表。
startingVersion:要从中读取的 Delta 表版本。 在指定版本或之后,流会读取所有已提交的表更改。 如果指定的版本不可用,则流无法启动。若要查找可用的提交版本,请运行
DESCRIBE HISTORY并检查version。 若仅返回最新更改,请指定latest。 有关 Delta 表的版本信息,请参阅 使用表历史记录。startingTimestamp:开始读取的时间戳。 数据流会读取在指定时间戳或之后提交的所有表更改。 如果提供的时间戳位于所有表提交之前,则流式读取按最早的可用时间戳开始。 设置以下任一项:- 时间戳字符串。 例如
"2019-01-01T00:00:00.000Z"。 - 日期字符串。 例如
"2019-01-01"。
- 时间戳字符串。 例如
不能同时设置startingVersion和startingTimestamp。 这些设置仅适用于新的流式处理查询。 如果流式处理查询已启动且进度已记录在其检查点中,则忽略这些设置。
Important
虽然可以从指定的版本或时间戳启动流式处理源,但流式处理源的架构始终是 Delta 表的最新架构。 必须确保在指定版本或时间戳之后,不对 Delta 表进行任何不兼容的架构更改。 否则,在读取架构不正确的数据时,流式处理源可能会返回不正确的结果。
Example
例如,假设你有一个表 user_events。 如果要从版本 5 开始读取更改,请使用:
spark.readStream
.option("startingVersion", "5")
.table("user_events")
如果想了解自 2018 年 10 月 18 日以来进行的更改,可使用:
spark.readStream
.option("startingTimestamp", "2018-10-18")
.table("user_events")
处理初始快照而不删除数据
此功能在 Databricks Runtime 11.3 LTS 及更高版本上可用。
在有状态流式查询中,当水印已定义时,通过修改时间排序处理文件可能导致记录处理顺序错误。 这可能会导致水印错误地将记录标记为后期事件并删除它们。 仅当按默认顺序处理初始 Delta 快照时,才会发生这种情况。
对于具有 Delta 源表的流,查询首先处理表中存在的所有数据,并创建名为 初始快照的版本。 默认情况下,Delta 表的数据文件将基于上次修改的文件进行处理。 但是,上次修改时间不一定表示记录事件时间顺序。
若要避免在初始快照处理期间删除数据,请启用 withEventTimeOrder 该选项。
withEventTimeOrder 将初始快照数据的事件时间范围划分为时间存储桶。 每个微批处理通过筛选时间范围内的数据来处理存储桶。
maxFilesPerTrigger 和 maxBytesPerTrigger 选项仍适用于控制微批大小,但由于处理方法,这仅能大致控制。
下图显示了此过程:
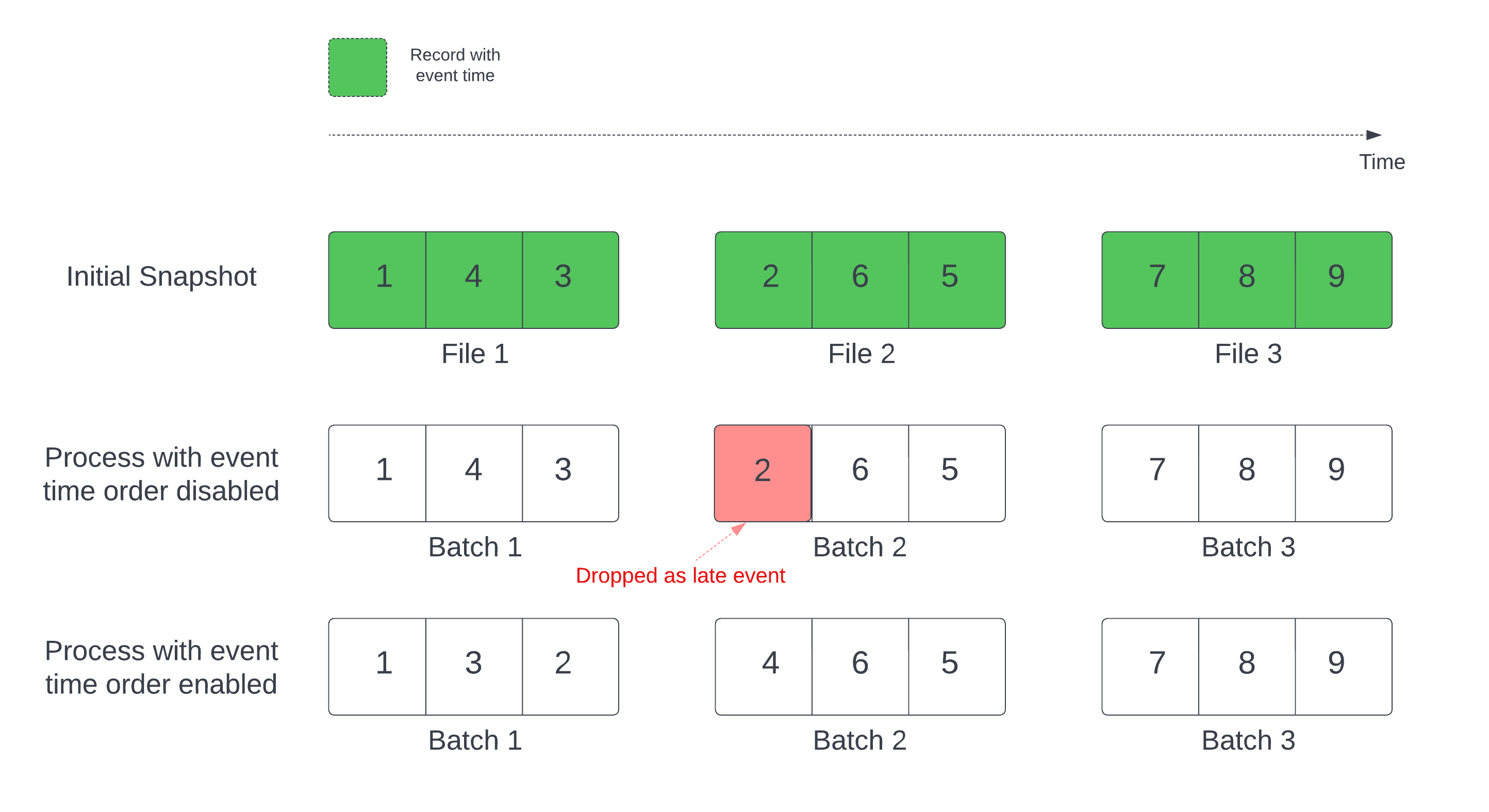
限制条件
- 如果流查询已启动,并且初始快照正在积极处理,则无法更改
withEventTimeOrder。 为了应用withEventTimeOrder的更改重新启动,必须删除检查点。 - 如果
withEventTimeOrder已启用,则无法在初始快照处理完成之前将流降级到不支持此功能的 Databricks Runtime 版本。 若要降级,请等待初始快照完成,或删除检查点并重启查询。 - 在以下方案中不支持此功能:
- 事件时间列是一个生成列,在 Delta 源和水印之间存在非投影转换过程。
- 流查询中存在具有多个 Delta 源的水印。
性能
如果 withEventTimeOrder 已启用,初始快照处理性能可能会变慢。 每个微批处理扫描初始快照,以筛选相应事件时间范围内的数据。 提高筛选性能:
- 使用 Delta 源列作为事件时间,以便应用数据跳过功能。 请参阅 数据跳过。
- 沿事件时间列对表进行分区。
使用 Spark UI 查看特定微批任务扫描的 Delta Lake 文件数量。
Example
假设你有一个 user_events 表,其中包含 event_time 列。 流式处理查询是一个聚合查询。 如果要确保在初始快照处理期间不会删除任何数据,可以使用:
spark.readStream
.option("withEventTimeOrder", "true")
.table("user_events")
.withWatermark("event_time", "10 seconds")
可以在群集上使用 Spark 配置进行设置withEventTimeOrder,以将其应用到所有流式处理查询: spark.databricks.delta.withEventTimeOrder.enabled true
限制输入速率以提高处理性能
默认情况下,结构化流式处理在每个微批处理中处理尽可能多的文件。 若要限制每批处理的数据量并管理内存使用量、稳定延迟或降低云存储成本,请使用以下选项:
-
maxFilesPerTrigger:每个微批中需要考虑的新文件数量。 默认值为 1000。 -
maxBytesPerTrigger:在每个微批中处理的数据量。 此选项设置一个“柔性最大值”,这意味着批处理大约处理此数量的数据,并且可能会超过此限制,以便在最小输入单元大于此限制的情况下,继续处理流式查询。 默认情况下,未设置此项。
如果同时使用 maxBytesPerTrigger 和 maxFilesPerTrigger,则微批处理将处理数据,直到达到 maxFilesPerTrigger 或 maxBytesPerTrigger 之一的限制。
Note
默认情况下,如果 logRetentionDuration 清理了源表中的事务,而流式查询尝试处理这些版本,则查询会失败,从而无法防止数据丢失。 可以将选项 failOnDataLoss 设置为 false,忽略丢失的数据并继续处理。 请参阅为“按时间顺序查看”查询配置数据保留。
控制云存储成本
流式查询有几个可用的触发模式,可以用于平衡成本和延迟,包括processingTime,availableNow和realTime。 请参阅 控制云存储成本。