Azure DevOps Services |Azure DevOps Server |Azure DevOps Server 2022
变量提供了一种在管道的各个部分包含关键数据的便捷方法。 变量的最常见用途是定义可在管道中使用的值。 所有变量都是字符串,并且是可变的。 变量的值可以在管道中从一次运行到另一次运行或从一个作业到另一个作业发生变化。
在具有相同名称的多个位置定义同一变量时,最本地范围的变量优先。 因此,在作业级别定义的变量可以覆盖在阶段级别设置的变量。 在阶段级别定义的变量会覆盖在管道根级别设置的变量。 管道根级中设置的变量将覆盖管道设置 UI 中的变量。 若要详细了解如何使用在作业、阶段和根级别定义的变量,请参阅 变量范围。
可以将变量与 expressions 结合使用,以有条件地分配值并进一步自定义流水线。
变量不同于 运行时参数。 运行时参数是类型化参数,在模板分析期间可用。
用户定义的变量
定义变量时,请使用不同的语法(宏、模板表达式或运行时)。 选择的语法确定变量在管道中呈现的位置。
在 YAML 管道中,在根级别、阶段和作业级别设置变量。 还可以在 UI 中指定 YAML 管道外部的变量。 在 UI 中设置变量时,可以加密变量并将其设置为机密。
用户定义的变量可以设置为只读。 需遵守变量的命名限制(例如:不能在变量名称的开头使用 secret)。
可以使用变量组使变量在多个pipelines之间可用。
若要在一个文件中定义变量以用于多个pipelines,请使用 templates。
用户定义的多行变量
Azure DevOps 支持多行变量,但存在一些限制。
下游组件(如管道任务)可能无法正确处理变量值。
Azure DevOps 不会更改用户定义的变量值。 在将变量值作为多行变量传递之前,需要正确设置变量值的格式。 设置变量格式时,请避免使用特殊字符,不要使用受限名称,并确保使用适用于代理操作系统的行结束符格式。
多行变量的具体行为取决于操作系统。 若要避免此问题,请确保为目标作业系统正确格式化多行变量。
Azure DevOps 永远不会更改变量值,即使提供不受支持的格式设置也是如此。
系统变量
除了用户定义的变量,Azure Pipelines还具有具有预定义值的系统变量。 例如,预定义变量 Build.BuildId 会为每个生成提供 ID,并可用于标识不同的管道运行。 如果需要唯一值,可以在脚本或任务中使用 Build.BuildId 变量。
如果使用 YAML 或经典生成管道,请参阅预定义的变量获取系统变量的综合列表。
如果您正在使用经典发布管道,请参阅发布变量。
运行管道时,系统变量会设置其当前值。 某些变量是自动设置的。 作为管道作者或最终用户,可以在管道运行之前更改系统变量的值。
系统变量是只读的。
环境变量
环境变量特定于正在使用的操作系统。 可以通过特定于平台的方式将它们注入到管道中。 格式对应于环境变量在特定脚本平台上的格式化方式。
在 UNIX 系统上(macOS 和 Linux),环境变量的格式为 $NAME。 在 Windows 上,对于批处理,格式为 %NAME%,在 PowerShell 中,格式为 $env:NAME。
系统变量和用户定义的变量(机密变量除外)也会作为平台的环境变量注入。 当变量转换为环境变量时,变量名称变为大写,句点变为下划线。 例如,变量名称 any.variable 将成为变量名称 $ANY_VARIABLE。
环境变量需遵循变量命名限制(例如:不能在变量名称开头使用 secret)。
变量命名限制
用户定义的变量和环境变量可以包含字母、数字、. 和 _ 字符。 不要使用系统保留的变量前缀。 这些前缀包括:endpoint、、inputsecret、path和securefile。 任何以这些字符串开头的变量(无论大写)都不适用于任务和脚本。 不要在变量中使用空格。 有关其他约束,请参阅 Azure Pipelines 命名限制。
了解变量语法
Azure Pipelines支持三种不同的方法来引用变量:宏、模板表达式和运行时表达式。 可以将每个语法用于不同的用途,并且每个语法都有一些限制。
在管道中,模板表达式变量 (${{ variables.var }}) 在运行时开始之前,在编译时得到处理。 宏语法变量 ($(var)) 在任务运行之前得到处理。 运行时表达式 ($[variables.var]) 也在运行时处理,但旨在与条件和表达式一起使用。 使用运行时表达式时,该表达式必须占据定义的整个右侧。
在此示例中,可以看到模板表达式在更新变量后仍具有变量的初始值。 宏语法变量的值会被更新。 模板表达式值不会更改,因为管道在运行任务之前在编译时处理所有模板表达式变量。 相反,宏语法变量在每个任务运行之前被评估。
variables:
- name: one
value: initialValue
steps:
- script: |
echo ${{ variables.one }} # outputs initialValue
echo $(one)
displayName: First variable pass
- bash: echo "##vso[task.setvariable variable=one]secondValue"
displayName: Set new variable value
- script: |
echo ${{ variables.one }} # outputs initialValue
echo $(one) # outputs secondValue
displayName: Second variable pass
宏语法变量
大多数文档示例使用宏语法 ($(var))。 使用宏语法将变量值输入到任务输入和其他变量中。
系统在运行时执行任务之前使用宏语法处理变量。 运行时在模板扩展后发生。 系统遇到宏表达式时,会将表达式替换为变量的内容。 如果没有按该名称显示的变量,则宏表达式不会更改。 例如,如果 $(var) 无法替换,它将保持不变 $(var)。
宏语法变量没有值时保持不变,因为空值(如 $() 可能意味着正在运行的任务)并且代理不应假定你希望替换该值。 例如,如果在 bash 任务中使用 $(foo) 来引用变量 foo,则替换任务输入中的所有 $() 表达式可能会破坏 bash 脚本。
宏变量仅在用于值时才会扩展,而不是用作关键字时。 值显示在管道定义的右侧。 以下内容有效:key: $(value)。 以下内容无效:$(key): value。 当用于以内联方式显示作业名称时,宏变量不会展开。 而是必须使用 displayName 属性。
注意
系统仅在 、stages 和 jobs 内为 steps 扩展宏语法变量。
它不会在编译时解析的管道关键字(例如resourcestrigger,或checkout步骤的存储库引用值)中展开它们(例如,checkout: git://MyProject/MyRepo@$(var)不起作用)。
若要参数化这些值,请改用 模板表达式 (${{ }})或 运行时参数 。
此示例将宏语法与 Bash、PowerShell 和脚本任务一起使用。 使用宏语法调用变量的语法对所有三者都是相同的。
variables:
- name: projectName
value: contoso
steps:
- bash: echo $(projectName)
- powershell: echo $(projectName)
- script: echo $(projectName)
模板表达式语法
使用模板表达式语法扩展 模板参数 和变量(${{ variables.var }})。 系统在编译时处理模板变量,并在运行时启动时替换它们。 使用模板表达式将 YAML 的部分重新用作模板。
找不到替换值时,模板变量以无提示方式合并为空字符串。 模板表达式与宏和运行时表达式不同,可以显示为键(左侧)或值(右侧)。 以下内容有效:${{ variables.key }} : ${{ variables.value }}。
运行时表达式语法
对在运行时扩展的变量使用运行时表达式语法($[variables.var])。 找不到替换值时,运行时表达式变量以无提示方式合并为空字符串。 在作业条件中使用运行时表达式来支持作业或整个阶段的条件执行。
运行时表达式变量只有在用于获取值时才会展开,而不是用作关键词。 值显示在管道定义的右侧。 以下内容有效:key: $[variables.value]。 以下内容无效:$[variables.key]: value。 运行时表达式必须占据键值对的整个右侧。 例如,key: $[variables.value] 有效,但 key: $[variables.value] foo 无效。
| 语法 | 示例 | 何时处理? | 在管道定义中的哪个位置扩展? | 找不到时如何呈现? |
|---|---|---|---|---|
| 宏 | $(var) |
任务执行前的运行时 | 值(右侧) | 打印 $(var) |
| 模板表达式 | ${{ variables.var }} |
编译时 | 键或值(左侧或右侧) | 空字符串 |
| 运行时表达式 | $[variables.var] |
运行时 | 值(右侧) | 空字符串 |
我应使用哪种语法?
如果要为任务提供安全字符串或预定义的变量输入,请使用宏语法。
如果使用条件和表达式,请选择运行时表达式。 但是,如果不希望空变量打印(例如 $[variables.var]),则不要使用运行时表达式。 例如,如果你有依赖于具有特定值或无值的变量的条件逻辑,请使用宏表达式。
通常使用模板变量作为标准。 通过利用模板变量,您的管道在流水线编译时将变量值完全集成到管道中。 尝试调试管道时,这种注入非常有用。 可以下载日志文件并评估要替换的完全扩展值。 由于变量被替换在内,因此不要将模板语法用于敏感值。
使用 AI 识别变量语法问题
此提示示例帮助 Copilot Chat 辨识管道中使用的变量类型以及变量何时被解析。 突出显示 YAML 代码,然后输入以下 Copilot 聊天提示。
What types of Azure DevOps variables are used in this YAML pipeline? Give specific examples.
When does each variable process in the pipeline?
How will each variable render when not found?
What stages and jobs will the variables be available for?
自定义提示以根据需要添加具体内容。
Copilot 由 AI 提供支持,因此可能会带来意外和错误。 有关详细信息,请参阅 Copilot 常见问题解答。
在管道中设置变量
在最常见的情况下,设置变量并在 YAML 文件中使用它们。 使用此方法可以跟踪对版本控制系统中变量的更改。 还可以在管道设置 UI 中定义变量(请参阅经典选项卡),并在 YAML 中引用它们。
以下示例演示如何设置两个变量, configuration 并在 platform后续步骤中使用它们。 要在 YAML 语句中使用变量,请将其包装在 $() 中。 不能使用变量在 YAML 语句中定义 repository 。
# Set variables once
variables:
configuration: debug
platform: x64
steps:
# Use them once
- task: MSBuild@1
inputs:
solution: solution1.sln
configuration: $(configuration) # Use the variable
platform: $(platform)
# Use them again
- task: MSBuild@1
inputs:
solution: solution2.sln
configuration: $(configuration) # Use the variable
platform: $(platform)
变量范围
在 YAML 文件中,在各种范围内设置变量:
- 在根级别,使其可用于管道中的所有作业。
- 在阶段层面,将其设置为仅对特定阶段可用。
- 在作业级别,使其仅可用于特定作业。
在 YAML 顶部定义变量时,该变量可用于管道中的所有作业和阶段,并且是一个全局变量。 YAML 中定义的全局变量在管道设置 UI 中不可见。
作业级别的变量将优先于根和阶段级别的变量。 阶段级别的变量覆盖根级别的变量。
variables:
global_variable: value # this is available to all jobs
jobs:
- job: job1
pool:
vmImage: 'ubuntu-latest'
variables:
job_variable1: value1 # this is only available in job1
steps:
- bash: echo $(global_variable)
- bash: echo $(job_variable1)
- bash: echo $JOB_VARIABLE1 # variables are available in the script environment too
- job: job2
pool:
vmImage: 'ubuntu-latest'
variables:
job_variable2: value2 # this is only available in job2
steps:
- bash: echo $(global_variable)
- bash: echo $(job_variable2)
- bash: echo $GLOBAL_VARIABLE
这两个作业的输出如下所示:
# job1
value
value1
value1
# job2
value
value2
value
指定变量
在前面的示例中,variables 关键字后跟键值对列表。
键是变量名称,值是变量值。
通过使用 模板,可以在一个 YAML 文件中定义变量,并将其包含在另一个 YAML 文件中。
变量组是一组可以在多个管道中使用的变量。 通过使用变量组,可以在一个位置管理和组织常见于各个阶段的变量。
将此语法用于管道根级别的变量模板和变量组。
在此替代语法中,variables 关键字接受变量说明符的列表。
变量说明符 name 表示常规变量,group 表示变量组,template 表示包含变量模板。
下面的示例演示了所有三种方法。
variables:
# a regular variable
- name: myvariable
value: myvalue
# a variable group
- group: myvariablegroup
# a reference to a variable template
- template: myvariabletemplate.yml
若要了解详细信息,请参阅 使用模板重复使用变量。
通过环境访问变量
请注意,变量也通过环境变量提供给脚本。 使用这些环境变量时需遵循的语法取决于脚本语言。
名字被大写,并且 . 被替换为 _。 这会自动插入到进程环境中。 下面是一些示例:
- 批处理脚本:
%VARIABLE_NAME% - PowerShell 脚本:
$env:VARIABLE_NAME - Bash 脚本:
$VARIABLE_NAME
重要
包含文件路径的预定义变量将被转换为基于代理主机类型和 shell 类型的相应样式(Windows 样式为 C:\foo\,而 Unix 样式为 /foo/)。 如果在 Windows 上运行 bash 脚本任务,则应使用环境变量方法来访问这些变量,而不是使用管道变量方法,以确保具有正确的文件路径样式。
设置机密变量
提示
系统不会自动将机密变量作为环境变量导出。 若要在脚本中使用机密变量,请将其显式映射到环境变量。 有关详细信息,请参阅 “设置机密变量”。
不要在 YAML 文件中设置机密变量。 操作系统通常会记录运行进程的命令,你不希望日志包含作为输入传入的机密。 使用脚本的环境或映射 variables 块中的变量以将机密传递给管道。
注意
Azure Pipelines在向管道日志发出数据时努力屏蔽机密,因此你可能会在输出中看到其他变量和数据掩码,以及未设置为机密的日志。
需要在管道设置界面中设置机密变量。 这些变量的作用范围限定在定义它们的管道内。 还可以在变量组中设置机密变量。
要在 Web 界面中设置机密,请执行以下步骤:
- 转到 Pipelines 页,选择相应的管道,然后选择 Edit。
- 找到该管道的变量。
- 添加或更新该变量。
- 选择“将此值保密”选项,以加密方式存储变量。
- 保存流水线。
机密变量使用 2048 位 RSA 密钥进行静态加密。 代理上提供机密供任务和脚本使用。 请小心哪些人有权限更改您的管道。
重要
我们致力于防止机密信息出现在 Azure Pipelines 的输出中,但您仍然需要采取预防措施。 切勿将机密作为输出进行回显。 某些操作系统记录命令行参数。 切勿在命令行上传递机密。 相反,我们建议将机密映射到环境变量中。
我们绝不会对敏感信息的子字符串进行遮蔽。 例如,如果将“abc123”设置为机密,则不会从日志中屏蔽“abc”。 这是为了避免在过于精细的级别屏蔽机密,从而使日志不可读。 因此,机密不应包含结构化数据。 例如,如果“{ "foo": "bar" }”设置为密钥,则“bar”不会从日志中隐藏。
与普通变量不同,它们不会自动解密为脚本的环境变量。 需要显式映射机密变量。
以下示例演示如何在 PowerShell 和 Bash 脚本中映射和使用名为 mySecret 的机密变量。 定义了两个全局变量。
GLOBAL_MYSECRET 被分配了机密变量 mySecret 的值,GLOBAL_MY_MAPPED_ENV_VAR 被分配了非机密变量 nonSecretVariable 的值。 与普通管道变量不同,没有名为 MYSECRET 的环境变量。
PowerShell 任务运行脚本来打印变量。
-
$(mySecret):这是对机密变量的直接引用,并且有效。 -
$env:MYSECRET:这会尝试将机密变量作为环境变量访问,但因为机密变量不会自动映射为环境变量,所以没有效果。 -
$env:GLOBAL_MYSECRET:这会尝试通过全局变量access机密变量,这也不起作用,因为无法以这种方式映射机密变量。 -
$env:GLOBAL_MY_MAPPED_ENV_VAR:此操作通过全局变量访问非保密变量,并且这是有效的。 -
$env:MY_MAPPED_ENV_VAR:这会通过特定于任务的环境变量访问机密变量,这是将机密变量映射到环境变量的建议方法。
variables:
GLOBAL_MYSECRET: $(mySecret) # this will not work because the secret variable needs to be mapped as env
GLOBAL_MY_MAPPED_ENV_VAR: $(nonSecretVariable) # this works because it's not a secret.
steps:
- powershell: |
Write-Host "Using an input-macro works: $(mySecret)"
Write-Host "Using the env var directly does not work: $env:MYSECRET"
Write-Host "Using a global secret var mapped in the pipeline does not work either: $env:GLOBAL_MYSECRET"
Write-Host "Using a global non-secret var mapped in the pipeline works: $env:GLOBAL_MY_MAPPED_ENV_VAR"
Write-Host "Using the mapped env var for this task works and is recommended: $env:MY_MAPPED_ENV_VAR"
env:
MY_MAPPED_ENV_VAR: $(mySecret) # the recommended way to map to an env variable
- bash: |
echo "Using an input-macro works: $(mySecret)"
echo "Using the env var directly does not work: $MYSECRET"
echo "Using a global secret var mapped in the pipeline does not work either: $GLOBAL_MYSECRET"
echo "Using a global non-secret var mapped in the pipeline works: $GLOBAL_MY_MAPPED_ENV_VAR"
echo "Using the mapped env var for this task works and is recommended: $MY_MAPPED_ENV_VAR"
env:
MY_MAPPED_ENV_VAR: $(mySecret) # the recommended way to map to an env variable
上述脚本中这两个任务的输出如下所示:
Using an input-macro works: ***
Using the env var directly does not work:
Using a global secret var mapped in the pipeline does not work either:
Using a global non-secret var mapped in the pipeline works: foo
Using the mapped env var for this task works and is recommended: ***
还可以在脚本外部使用机密变量。 例如,可以使用定义将 variables 机密变量映射到任务。 此示例演示如何在Azure文件复制任务中使用机密变量 $(vmsUser) 和 $(vmsAdminPass)。
variables:
VMS_USER: $(vmsUser)
VMS_PASS: $(vmsAdminPass)
pool:
vmImage: 'ubuntu-latest'
steps:
- task: AzureFileCopy@6
inputs:
SourcePath: 'my/path' # Specify the source path
azureSubscription: 'my-subscription' # Azure subscription name
Destination: 'AzureVMs' # Destination type
storage: 'my-storage' # Azure storage account name
resourceGroup: 'my-resource-group' # Resource group name
vmsAdminUserName: $(VMS_USER) # Admin username for the VM
vmsAdminPassword: $(VMS_PASS) # Admin password for the VM
CleanTargetBeforeCopy: false # Do not clean the target before copying
引用变量组中的机密变量
此示例演示如何在 YAML 文件中引用变量组,以及如何在 YAML 中添加变量。 该示例使用变量组中的两个变量: user 和 token。 该 token 变量是机密变量,并映射到环境变量 $env:MY_MAPPED_TOKEN ,以便可以在 YAML 中引用它。
此 YAML 进行 REST 调用以检索发布列表,并输出结果。
variables:
- group: 'my-var-group' # variable group
- name: 'devopsAccount' # new variable defined in YAML
value: 'contoso'
- name: 'projectName' # new variable defined in YAML
value: 'contosoads'
steps:
- task: PowerShell@2
inputs:
targetType: 'inline'
script: |
# Encode the Personal Access Token (PAT)
# $env:USER is a normal variable in the variable group
# $env:MY_MAPPED_TOKEN is a mapped secret variable
$base64AuthInfo = [Convert]::ToBase64String([Text.Encoding]::ASCII.GetBytes(("{0}:{1}" -f $env:USER,$env:MY_MAPPED_TOKEN)))
# Get a list of releases
$uri = "https://vsrm.dev.azure.com/$(devopsAccount)/$(projectName)/_apis/release/releases?api-version=5.1"
# Invoke the REST call
$result = Invoke-RestMethod -Uri $uri -Method Get -ContentType "application/json" -Headers @{Authorization=("Basic {0}" -f $base64AuthInfo)}
# Output releases in JSON
Write-Host $result.value
env:
MY_MAPPED_TOKEN: $(token) # Maps the secret variable $(token) from my-var-group
重要
默认情况下,在GitHub存储库中,来自分叉的拉取请求构建无法访问与你的流水线关联的机密变量。 有关详细信息,请参阅来自分叉的贡献。
跨流水线共享变量
若要在项目中跨多个流水线共享变量,请使用 Web 界面。 在库下面,使用变量组。
使用任务的输出变量
某些任务定义输出变量,可在下游步骤、作业和阶段中使用。 在 YAML 中,可以使用 dependencies 访问跨阶段和作业的变量。
在下游任务中引用矩阵作业时,请使用其他语法。 请参阅设置多作业输出变量。 还需要对部署作业中的变量使用不同的语法。 请参阅部署作业中对输出变量的支持。
- 要从同一作业中的不同任务引用变量,请使用
TASK.VARIABLE。 - 要从其他作业的任务引用变量,请使用
dependencies.JOB.outputs['TASK.VARIABLE']。
注意
默认情况下,管道中的每个阶段都依赖于 YAML 文件中与其紧邻的前面一个阶段。 如果需要引用不是紧邻当前阶段之前的阶段,可以通过向阶段添加 dependsOn 部分来重写此自动默认值。
注意
以下示例使用标准管道语法。 如果使用部署流水线,则变量和条件变量的语法将有所不同。 有关要使用的特定语法的信息,请参阅部署作业。
对于这些示例,假设你有一个名为的任务 MyTask,它设置一个名为 MyVar的输出变量。
可在表达式 - 依赖项中详细了解语法。
在同一个作业中使用输出
steps:
- task: MyTask@1 # this step generates the output variable
name: ProduceVar # because we're going to depend on it, we need to name the step
- script: echo $(ProduceVar.MyVar) # this step uses the output variable
在不同的作业中使用输出
jobs:
- job: A
steps:
# assume that MyTask generates an output variable called "MyVar"
# (you would learn that from the task's documentation)
- task: MyTask@1
name: ProduceVar # because we're going to depend on it, we need to name the step
- job: B
dependsOn: A
variables:
# map the output variable from A into this job
varFromA: $[ dependencies.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
在不同的阶段使用输出
若要使用不同阶段的输出,请使用格式 stageDependencies.STAGE.JOB.outputs['TASK.VARIABLE'] 引用变量。 在阶段级别(而不是工作级别)您可以在条件中使用这些变量。
输出变量仅在下一个下游阶段中可用。 如果多个阶段使用相同的输出变量,请使用 dependsOn 条件。
stages:
- stage: One
jobs:
- job: A
steps:
- task: MyTask@1 # this step generates the output variable
name: ProduceVar # because we're going to depend on it, we need to name the step
- stage: Two
dependsOn:
- One
jobs:
- job: B
variables:
# map the output variable from A into this job
varFromA: $[ stageDependencies.One.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
- stage: Three
dependsOn:
- One
- Two
jobs:
- job: C
variables:
# map the output variable from A into this job
varFromA: $[ stageDependencies.One.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
还可以使用文件输入在阶段之间传递变量。 因此,需要在作业的第二个阶段定义变量,然后将变量作为env: 输入传递。
## script-a.sh
echo "##vso[task.setvariable variable=sauce;isOutput=true]crushed tomatoes"
## script-b.sh
echo 'Hello file version'
echo $skipMe
echo $StageSauce
## azure-pipelines.yml
stages:
- stage: one
jobs:
- job: A
steps:
- task: Bash@3
inputs:
filePath: 'script-a.sh'
name: setvar
- bash: |
echo "##vso[task.setvariable variable=skipsubsequent;isOutput=true]true"
name: skipstep
- stage: two
jobs:
- job: B
variables:
- name: StageSauce
value: $[ stageDependencies.one.A.outputs['setvar.sauce'] ]
- name: skipMe
value: $[ stageDependencies.one.A.outputs['skipstep.skipsubsequent'] ]
steps:
- task: Bash@3
inputs:
filePath: 'script-b.sh'
name: fileversion
env:
StageSauce: $(StageSauce) # predefined in variables section
skipMe: $(skipMe) # predefined in variables section
- task: Bash@3
inputs:
targetType: 'inline'
script: |
echo 'Hello inline version'
echo $(skipMe)
echo $(StageSauce)
上述管道中阶段的输出如下所示:
Hello inline version
true
crushed tomatoes
列出变量
使用 az pipelines 变量列表命令列出管道中的所有变量。 若要开始,请参阅 Get started with Azure DevOps CLI。
az pipelines variable list [--org]
[--pipeline-id]
[--pipeline-name]
[--project]
参数
-
org:Azure DevOps 组织 URL。 使用
az devops configure -d organization=ORG_URL.. 配置默认组织。 如果未配置为默认值或使用 进行选取,git config则为必需。 示例:--org https://dev.azure.com/MyOrganizationName/。 - pipeline-id:如果未提供 pipeline-name,则是必需的。 管道的 ID。
- pipeline-name:如果未提供 pipeline-id,则是必需的;如果已提供 pipeline-id,则忽略。 管道的名称。
-
project:project的名称或 ID。 使用
az devops configure -d project=NAME_OR_ID配置默认项目。 如果未配置为默认值或使用 进行选取,git config则为必需。
示例
以下命令列出了 ID 为 12 的管道中的所有变量,并以表格式显示结果。
az pipelines variable list --pipeline-id 12 --output table
Name Allow Override Is Secret Value
------------- ---------------- ----------- ------------
MyVariable False False platform
NextVariable False True platform
Configuration False False config.debug
在脚本中设置变量
脚本可以定义管道使用中后续步骤的变量。 此方法设置的所有变量都被视为字符串。 若要从脚本设置变量,请使用命令语法并打印到 stdout。
从脚本中设置一个作业范围限定的变量
若要从脚本设置变量,请使用 task.setvariable日志记录命令。 此命令更新后续作业的环境变量。 后续作业可以使用 macro 语法,并在任务中作为环境变量来访问新变量。
如果设置为 issecret true,变量的值将保存为机密并从日志中屏蔽。 有关机密变量的详细信息,请参阅 日志记录命令。
steps:
# Create a variable
- bash: |
echo "##vso[task.setvariable variable=sauce]crushed tomatoes" # remember to use double quotes
# Use the variable
# "$(sauce)" is replaced by the contents of the `sauce` variable by Azure Pipelines
# before handing the body of the script to the shell.
- bash: |
echo my pipeline variable is $(sauce)
后续步骤还会将管道变量添加到其环境中。 不能在定义变量的步骤中使用变量。
steps:
# Create a variable
# Note that this does not update the environment of the current script.
- bash: |
echo "##vso[task.setvariable variable=sauce]crushed tomatoes"
# An environment variable called `SAUCE` has been added to all downstream steps
- bash: |
echo "my environment variable is $SAUCE"
- pwsh: |
Write-Host "my environment variable is $env:SAUCE"
上一管道的输出。
my environment variable is crushed tomatoes
my environment variable is crushed tomatoes
设置多任务输出变量
如果要使变量可供将来的作业使用,则必须使用 isOutput=true 将其标记为输出变量。 然后,可以将其映射到将来的作业,方法是使用 $[] 语法并包括用于设置变量的步骤名称。 多作业输出变量仅适用于同一阶段的作业。
要将变量传递到不同阶段的作业,可使用阶段依赖项语法。
注意
默认情况下,管道中的每个阶段都依赖于 YAML 文件中与其紧邻的前面一个阶段。 因此,每个阶段都可以使用上一阶段的输出变量。 若要访问进一步阶段,需要修改依赖关系图,例如,如果阶段 3 需要阶段 1 中的变量,则需要明确声明对阶段 1 的依赖。
创建多作业输出变量时,应将表达式分配给变量。 在此 YAML 中,$[ dependencies.A.outputs['setvarStep.myOutputVar'] ] 分配给变量 $(myVarFromJobA)。
jobs:
# Set an output variable from job A
- job: A
pool:
vmImage: 'windows-latest'
steps:
- powershell: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the value"
name: setvarStep
- script: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable into job B
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobA: $[ dependencies.A.outputs['setvarStep.myOutputVar'] ] # map in the variable
# remember, expressions require single quotes
steps:
- script: echo $(myVarFromJobA)
name: echovar
上一管道的输出。
this is the value
this is the value
要将变量从一个阶段设置为另一个阶段,请使用 stageDependencies。
stages:
- stage: A
jobs:
- job: A1
steps:
- bash: echo "##vso[task.setvariable variable=myStageOutputVar;isOutput=true]this is a stage output var"
name: printvar
- stage: B
dependsOn: A
variables:
myVarfromStageA: $[ stageDependencies.A.A1.outputs['printvar.myStageOutputVar'] ]
jobs:
- job: B1
steps:
- script: echo $(myVarfromStageA)
如果要从 matrix 或 slice 设置变量,则在从下游作业访问变量时,必须包含:
- 作业的名称。
- 该步骤。
jobs:
# Set an output variable from a job with a matrix
- job: A
pool:
vmImage: 'ubuntu-latest'
strategy:
maxParallel: 2
matrix:
debugJob:
configuration: debug
platform: x64
releaseJob:
configuration: release
platform: x64
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the $(configuration) value"
name: setvarStep
- bash: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the debug job
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobADebug: $[ dependencies.A.outputs['debugJob.setvarStep.myOutputVar'] ]
steps:
- script: echo $(myVarFromJobADebug)
name: echovar
jobs:
# Set an output variable from a job with slicing
- job: A
pool:
vmImage: 'ubuntu-latest'
parallel: 2 # Two slices
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the slice $(system.jobPositionInPhase) value"
name: setvarStep
- script: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the job for the first slice
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobsA: $[ dependencies.A.outputs['setvarStep.myOutputVar'] ]
steps:
- script: "echo $(myVarFromJobsA)"
name: echovar
请确保将作业名称作为部署作业的输出变量的前缀。 在这种情况下,作业名为 A:
jobs:
# Set an output variable from a deployment
- deployment: A
pool:
vmImage: 'ubuntu-latest'
environment: staging
strategy:
runOnce:
deploy:
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the deployment variable value"
name: setvarStep
- bash: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the job for the first slice
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromDeploymentJob: $[ dependencies.A.outputs['A.setvarStep.myOutputVar'] ]
steps:
- bash: "echo $(myVarFromDeploymentJob)"
name: echovar
 设置
设置  设置
设置  设置
设置 使用表达式设置变量
可以使用表达式设置变量。 您在将变量设置为先前作业中另一个变量的输出时,已经遇到过这种方法。
- job: B
dependsOn: A
variables:
myVarFromJobsA1: $[ dependencies.A.outputs['job1.setvarStep.myOutputVar'] ] # remember to use single quotes
可以使用任何受支持的表达式来设置变量。 下面是设置变量充当计数器的示例,该计数器从 100 开始,每次运行递增 1,每天重置为 100。
jobs:
- job:
variables:
a: $[counter(format('{0:yyyyMMdd}', pipeline.startTime), 100)]
steps:
- bash: echo $(a)
有关计数器、依赖项和其他表达式的详细信息,请参阅表达式。
为步骤配置可设置的变量
可以在步骤中定义 settableVariables,也可以指定不能设置任何变量。
在此示例中,脚本无法设置变量。
steps:
- script: echo This is a step
target:
settableVariables: none
在下面的示例中,脚本可以设置变量 sauce ,但不能设置变量 secretSauce。 您在管道运行页面上看到一个警告。

steps:
- bash: |
echo "##vso[task.setvariable variable=Sauce;]crushed tomatoes"
echo "##vso[task.setvariable variable=secretSauce;]crushed tomatoes with garlic"
target:
settableVariables:
- sauce
name: SetVars
- bash:
echo "Sauce is $(sauce)"
echo "secretSauce is $(secretSauce)"
name: OutputVars
排队时允许
如果变量出现在 YAML 文件的块中 variables ,则其值是固定的,用户无法在队列时重写它。 在 YAML 文件中定义变量,但有时此方法没有意义。 例如,你可能想要定义机密变量,而不是在 YAML 中公开它。 或者,可能需要在管道运行期间手动设置变量值。
要定义队列时值,有两种选择。 可以在 UI 中定义变量,并选择允许用户在运行此管道时替代此值选项,也可以改为使用运行时参数。 如果变量不是机密,最佳做法是使用运行时参数。
要在队列时间设置变量,请在管道中添加一个新变量,并选择覆盖选项。 只有具有 “编辑队列生成”配置 权限的用户才能更改变量的值。
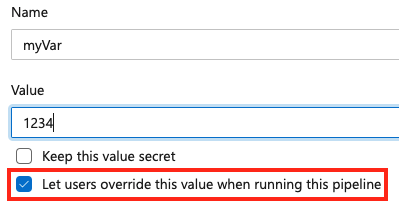
要允许在队列时设置变量,请确保该变量不会也出现在管道或作业的 variables 块中。 如果同时在 YAML 的变量块和 UI 中定义变量,则 YAML 中的值优先。
为了提高安全性,请在队列时间可设置的变量中使用预定义的值集以及安全类型(如布尔值和整数)。 对于字符串,请使用预定义的值集。

变量的扩展
在多个作用域中设置具有相同名称的变量时,以下优先级将应用(优先优先顺序最高):
- 在 YAML 文件中设置的作业级别变量
- 在 YAML 文件中设置的阶段级别变量
- 在 YAML 文件中设置的管道级别变量
- 在排队时设置的变量
- 在管道设置 UI 中设置的管道变量
在以下示例中,在 YAML 文件中的管道级别和作业级别设置相同的变量 a 。 还在变量组 G 中设置了此变量,并在管道设置 UI 中将其设置为变量。
variables:
a: 'pipeline yaml'
stages:
- stage: one
displayName: one
variables:
- name: a
value: 'stage yaml'
jobs:
- job: A
variables:
- name: a
value: 'job yaml'
steps:
- bash: echo $(a) # This will be 'job yaml'
在同一范围内设置同名变量时,最后一个设定的值优先。
stages:
- stage: one
displayName: Stage One
variables:
- name: a
value: alpha
- name: a
value: beta
jobs:
- job: I
displayName: Job I
variables:
- name: b
value: uno
- name: b
value: dos
steps:
- script: echo $(a) #outputs beta
- script: echo $(b) #outputs dos
注意
当您在 YAML 文件中设置变量时,不要在 web 编辑器中将其定义为可在队列时设置。 当前无法在排队时更改 YAML 文件中设置的变量。 如果希望某个变量可在排队时设置,请不要在 YAML 文件中设置此变量。
运行开始时,变量会被展开一次,然后在每个步骤开始时再次被展开。 例如:
jobs:
- job: A
variables:
a: 10
steps:
- bash: |
echo $(a) # This will be 10
echo '##vso[task.setvariable variable=a]20'
echo $(a) # This will also be 10, since the expansion of $(a) happens before the step
- bash: echo $(a) # This will be 20, since the variables are expanded just before the step
前面的示例中有两个步骤。 在作业开始时展开一次 $(a),在两个步骤的开头再次展开一次。
由于变量是在作业开始时展开的,因此不能在策略中使用变量。 在以下示例中,不能使用变量 a 来扩展作业矩阵,因为变量仅在每个展开作业的开头可用。
jobs:
- job: A
variables:
a: 10
strategy:
matrix:
x:
some_variable: $(a) # This does not work
如果变量 a 是上一个作业的输出变量,则可以在将来的作业中使用此变量。
- job: A
steps:
- powershell: echo "##vso[task.setvariable variable=a;isOutput=true]10"
name: a_step
# Map the variable into job B
- job: B
dependsOn: A
variables:
some_variable: $[ dependencies.A.outputs['a_step.a'] ]
递归扩展
在代理上,使用 $( ) 语法引用的变量以递归方式展开。
例如:
variables:
myInner: someValue
myOuter: $(myInner)
steps:
- script: echo $(myOuter) # prints "someValue"
displayName: Variable is $(myOuter) # display name is "Variable is someValue"