你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用 TypeScript 和 Azure DocumentDB 生成智能 AI 代理。 本快速入门演示了一个双代理体系结构,该体系结构执行语义式酒店搜索并生成个性化建议。
重要
此示例使用 LangChain,这是用于生成 AI 应用程序的常用框架。 LangChain 提供代理、工具和提示的抽象,以简化智能体开发。
先决条件
可以使用 Azure 开发人员 CLI 通过运行 azd 示例存储库中的命令来创建所需的 Azure 资源。 有关详细信息,请参阅 使用 Azure 开发人员 CLI 部署基础结构。
Azure资源
Microsoft Azure AI Foundry 中含以下模型部署的 Microsoft Foundry 模型资源(经典版)中的 Azure OpenAI:
-
gpt-4o部署(合成器智能体)- 建议:每分钟 50,000 令牌 (TPM) 容量 -
gpt-4o-mini部署(规划器智能体)- 建议:每分钟 30,000 令牌 (TPM) 容量 -
text-embedding-3-small部署(嵌入)- 建议:每分钟 10,000 个词元(TPM) 容量 -
令牌配额:为每个部署配置足够的 TPM,以避免速率限制
- 请参阅管理 Azure OpenAI 配额以进行配额管理
- 如果遇到 429 错误,请增加 TPM 配额或降低请求频率
-
具有矢量搜索支持的 Azure DocumentDB (与 MongoDB 兼容性)群集:
- 基于首选矢量索引算法的群集层要求:
- IVF (倒排文件索引):M10 或更高版本(默认算法)
- HNSW (分层可导航小型世界):M30 或更高版本(基于图形)
- DiskANN:M40 或更高版本(针对大规模优化)
-
防火墙配置:必需。 如果没有适当的防火墙配置,连接尝试会失败。
- 将客户端 IP 地址添加到群集的防火墙规则。 有关详细信息,请参阅 从 IP 地址授予访问权限。
- 对于无密码身份验证,请确保已启用基于角色的访问控制(RBAC)。
- 基于首选矢量索引算法的群集层要求:
开发工具
- 用于资源预配的 Azure 开发人员 CLI
- Node.js LTS
- TypeScript 5.0 或更高版本
- 用于身份验证的 Azure CLI
- 配有 DocumentDB 扩展 的 Visual Studio Code 用于数据库管理(可选)
适用于 Node.js 的代理 RAG 应用程序体系结构
此示例使用两个代理体系结构,其中每个代理具有特定角色。

此示例将 LangChain 的代理框架与 OpenAI SDK 配合使用。 它利用 LangChain 的函数调用的抽象来进行工具集成,并遵循代理和搜索工具之间的线性工作流。 执行是无状态的,没有会话历史记录,因此它适合单轮查询和响应方案。
获取 Node.js 示例代码
克隆或下载 Azure DocumentDB 示例存储库到本地计算机,以跟随快速入门操作。
导航到项目目录:
cd ai/vector-search-agent-typescript
使用 Azure 开发人员 CLI 部署 Azure 资源
使用 Azure 开发人员 CLI (azd) 预配所需的 Azure OpenAI 和 DocumentDB 资源。
登录到 Azure:
azd auth login预配和部署基础结构:
azd up出现提示时,选择订阅和位置(例如,
swedencentral或eastus2)。部署完成后,
azd输出所需的环境变量。 将它们复制到.env文件(请参阅 “配置环境变量”)。
小窍门
随时运行 azd env get-values 以查看当前环境值。
配置环境变量
如果手动创建了 Azure 资源,或者想要使用自己的现有资源,则需要为应用程序配置环境变量以连接到 Azure OpenAI 和 Azure DocumentDB。 如果使用 azd up,可以跳过此步骤,因为会在 azd 环境中自动设置必要的环境变量,并且可以使用 azd env get-values 访问它们。
在项目根目录中创建文件 .env 以配置环境变量。 可以从存储库中复制 .env.sample 文件。
编辑.env文件,并替换这些占位符值:
本快速入门使用双智能体架构(规划器 + 合成器),包含三个模型部署(两个聊天模型 + 嵌入模型)。 为每个模型部署配置环境变量。
-
AZURE_OPENAI_PLANNER_MODEL:gpt-4o-mini 模型名称 -
AZURE_OPENAI_SYNTH_MODEL:gpt-4o 模型名称 -
AZURE_OPENAI_EMBEDDING_MODEL:text-embedding-3-small 模型名称
可以在两种身份验证方法之间进行选择:使用 Azure 标识(建议)或传统连接字符串和 API 密钥进行无密码身份验证。
选项 1:无密码身份验证
对 Azure OpenAI 和 Azure DocumentDB 使用无密码身份验证。 设置USE_PASSWORDLESS=true、AZURE_OPENAI_ENDPOINT和AZURE_DOCUMENTDB_CLUSTER。
# Enable passwordless authentication
USE_PASSWORDLESS=true
# Azure OpenAI Configuration (passwordless)
AZURE_OPENAI_ENDPOINT=your-openai-endpoint
AZURE_OPENAI_PLANNER_MODEL=gpt-4o-mini
AZURE_OPENAI_PLANNER_API_VERSION=2024-08-01-preview
AZURE_OPENAI_SYNTH_MODEL=gpt-4o
AZURE_OPENAI_SYNTH_API_VERSION=2024-08-01-preview
AZURE_OPENAI_EMBEDDING_MODEL=text-embedding-3-small
AZURE_OPENAI_EMBEDDING_API_VERSION=2023-05-15
# Azure DocumentDB (passwordless)
AZURE_DOCUMENTDB_CLUSTER=your-mongo-cluster-name
AZURE_DOCUMENTDB_DATABASENAME=Hotels
AZURE_DOCUMENTDB_COLLECTION=hotel_data
# Data Configuration
DATA_FILE_WITHOUT_VECTORS=../data/Hotels.json
# Vector Index Configuration
VECTOR_INDEX_ALGORITHM=vector-ivf
EMBEDDING_DIMENSIONS=1536
无密码身份验证的先决条件:
确保已登录到 Azure:
az login为你的标识授予以下角色:
- Azure OpenAI 资源上的
Cognitive Services OpenAI User -
DocumentDB Account Contributor和Cosmos DB Account Reader RoleAzure DocumentDB 资源
有关分配角色的详细信息,请参阅 使用 Azure 门户分配 Azure 角色。
- Azure OpenAI 资源上的
无密码身份验证的工作原理
当 USE_PASSWORDLESS=true 时,应用程序使用 Azure Identity SDK 获取 OAuth 令牌 DefaultAzureCredential。 对于 Azure DocumentDB 连接,它使用 OIDC 令牌回调将访问令牌直接传递到 MongoDB 驱动程序。 这意味着没有密码或连接字符串存储在配置文件中。
身份验证流:
-
DefaultAzureCredential按顺序检查可用凭据(Azure CLI、托管标识、环境变量)。 - 对于 Azure OpenAI,令牌会自动传递到 LangChain
AzureChatOpenAI和AzureOpenAIEmbeddings客户端。 - 对于 Azure DocumentDB,令牌回调函数提取访问令牌,并通过身份验证机制将其提供给 MongoDB 客户端
MONGODB-OIDC。
import { AzureOpenAIEmbeddings, AzureChatOpenAI } from "@langchain/openai";
import { MongoClient, OIDCCallbackParams } from 'mongodb';
import { AccessToken, DefaultAzureCredential, TokenCredential, getBearerTokenProvider } from '@azure/identity';
/*
This file contains utility functions to create Azure OpenAI clients for embeddings, planning, and synthesis.
It supports two modes of authentication:
1. API Key based authentication using AZURE_OPENAI_API_KEY and AZURE_OPENAI_ENDPOINTenvironment variables.
2. Passwordless authentication using DefaultAzureCredential from Azure Identity library.
*/
// Azure Identity configuration
const OPENAI_SCOPE = 'https://cognitiveservices.azure.com/.default';
const DOCUMENT_DB_SCOPE = 'https://ossrdbms-aad.database.windows.net/.default';
// Azure identity credential (used for passwordless auth)
const CREDENTIAL = new DefaultAzureCredential();
function requireEnvVars(names: string[]) {
const missing = names.filter((name) => {
const value = process.env[name];
return !value || value.trim().length === 0;
});
if (missing.length > 0) {
throw new Error(`Missing required environment variables: ${missing.join(', ')}`);
}
}
// Token callback for MongoDB OIDC authentication
async function azureIdentityTokenCallback(
params: OIDCCallbackParams,
credential: TokenCredential
): Promise<{ accessToken: string; expiresInSeconds: number }> {
const tokenResponse: AccessToken | null = await credential.getToken([DOCUMENT_DB_SCOPE]);
return {
accessToken: tokenResponse?.token || '',
expiresInSeconds: (tokenResponse?.expiresOnTimestamp || 0) - Math.floor(Date.now() / 1000)
};
选项 2:连接字符串和 API 密钥身份验证
通过设置 USE_PASSWORDLESS=false (或省略该项)并在 AZURE_OPENAI_API_KEY 文件中提供 AZURE_DOCUMENTDB_CONNECTION_STRING 和 .env 值,使用基于密钥的身份验证。
# Disable passwordless authentication
USE_PASSWORDLESS=false
# Azure OpenAI Configuration (API key)
AZURE_OPENAI_ENDPOINT=your-openai-endpoint
AZURE_OPENAI_API_KEY=your-azure-openai-api-key
AZURE_OPENAI_PLANNER_MODEL=gpt-4o-mini
AZURE_OPENAI_PLANNER_API_VERSION=2024-08-01-preview
AZURE_OPENAI_SYNTH_MODEL=gpt-4o
AZURE_OPENAI_SYNTH_API_VERSION=2024-08-01-preview
AZURE_OPENAI_EMBEDDING_MODEL=text-embedding-3-small
AZURE_OPENAI_EMBEDDING_API_VERSION=2023-05-15
# Azure DocumentDB (connection string)
AZURE_DOCUMENTDB_CLUSTER=your-mongo-cluster-name
AZURE_DOCUMENTDB_CONNECTION_STRING=mongodb+srv://username:password@cluster.mongocluster.cosmos.azure.com/
AZURE_DOCUMENTDB_DATABASENAME=Hotels
AZURE_DOCUMENTDB_COLLECTION=hotel_data
# Data Configuration
DATA_FILE_WITHOUT_VECTORS=../data/Hotels.json
# Vector Index Configuration
VECTOR_INDEX_ALGORITHM=vector-ivf
EMBEDDING_DIMENSIONS=1536
项目结构
该项目遵循标准 Node.js/TypeScript 项目布局。 目录结构应类似于以下结构:
vector-search-agent-typescript/
├── src/
│ ├── agent.ts # Main agent application
│ ├── upload-documents.ts # Data upload utility
│ ├── cleanup.ts # Database cleanup utility
│ ├── vector-store.ts # Vector store and tool implementation
│ ├── utils/
│ │ ├── clients.ts # Azure OpenAI and DocumentDB client setup
│ │ ├── prompts.ts # System prompts and tool definitions
│ │ ├── types.ts # TypeScript type definitions
│ │ └── mongo.ts # MongoDB utility functions
│ └── scripts/ # Additional utility scripts
├── .env # Environment variable configuration
├── package.json # npm dependencies and scripts
└── tsconfig.json # TypeScript configuration
查看代理型 RAG 应用程序的 Node.js 代码
本部分介绍 AI 代理工作流的核心组件。 它重点介绍了代理如何处理请求、工具如何将 AI 连接到数据库,以及提示如何指导 AI 的行为。
Node.js Agentic RAG 应用程序
该文件 src/agent.ts 协调由 AI 提供支持的酒店建议系统。
该应用程序使用两个 Azure 服务:
- Azure OpenAI,它使用 AI 模型来了解查询并生成建议
- 存储酒店数据的 Azure DocumentDB 并执行矢量相似性搜索
Node.js 代理和工具组件
这三个组件共同处理酒店搜索请求:
- Planner 代理 - 解释请求并决定如何搜索
- 矢量搜索工具 - 查找类似于 Planner 代理描述的酒店
- 合成器代理 - 基于搜索结果编写有用的建议
智能体 RAG 应用程序工作流
应用程序通过两个步骤处理酒店搜索请求:
- 规划: 工作流调用 planner 代理,该代理分析用户的查询(如“运行小径附近的酒店”),并搜索数据库以查找匹配的酒店。
- 合成: 工作流调用合成器代理,该代理会评审搜索结果并编写个性化建议,说明哪些酒店最符合请求。
// Authentication
const clients = process.env.USE_PASSWORDLESS === 'true' || process.env.USE_PASSWORDLESS === '1' ? createClientsPasswordless() : createClients();
const { embeddingClient, plannerClient, synthClient, dbConfig } = clients;
console.log(`DEBUG mode is ${process.env.DEBUG === 'true' ? 'ON' : 'OFF'}`);
console.log(`DEBUG_CALLBACKS length: ${DEBUG_CALLBACKS.length}`);
// Get vector store (get docs, create embeddings, insert docs)
const store = await getExistingStore(
embeddingClient,
dbConfig);
const query = process.env.QUERY || "quintessential lodging near running trails, eateries, retail";
const nearestNeighbors = parseInt(process.env.NEAREST_NEIGHBORS || '5', 10);
//Run planner agent
const hotelContext = await runPlannerAgent(plannerClient, embeddingClient, query, store, nearestNeighbors);
if (process.env.DEBUG === 'true') console.log(hotelContext);
//Run synth agent
const finalAnswer = await runSynthesizerAgent(synthClient, query, hotelContext);
// Get final recommendation (data + AI)
console.log('\n--- FINAL ANSWER ---');
console.log(finalAnswer);
用于规划和合成的 Node.js 代理
src/agent.ts源文件实现规划器和合成器代理,这些代理共同处理酒店搜索请求。
规划器智能体
规划器智能体是决策制定者,负责确定如何搜索酒店。
规划器智能体接收用户的自然语言查询,并使用 LangChain 的智能体框架及其可使用的可用工具将此类查询发送到 AI 模型。 AI 决定调用矢量搜索工具并提供搜索参数。 LangChain 会自动处理工具执行,并返回匹配的酒店。 AI 无需对搜索逻辑进行硬编码,而是解释用户想要的内容,并选择如何搜索,使系统对不同类型的查询灵活。
async function runPlannerAgent(
plannerClient: any,
embeddingClient: any,
userQuery: string,
store: AzureDocumentDBVectorStore,
nearestNeighbors = 5
): Promise<string> {
console.log('\n--- PLANNER ---');
const userMessage = `Use the "${TOOL_NAME}" tool with nearestNeighbors=${nearestNeighbors} and query="${userQuery}". Do not answer directly; call the tool.`;
const contextSchema = z.object({
store: z.any(),
embeddingClient: z.any()
});
const agent = createAgent({
model: plannerClient,
systemPrompt: PLANNER_SYSTEM_PROMPT,
tools: [getHotelsToMatchSearchQuery],
contextSchema,
});
const agentResult = await agent.invoke(
{ messages: [{ role: 'user', content: userMessage }] },
// @ts-ignore
{ context: { store, embeddingClient }, callbacks: DEBUG_CALLBACKS }
);
const plannerMessages = agentResult.messages || [];
const searchResultsAsText = extractPlannerToolOutput(plannerMessages);
return searchResultsAsText;
}
合成器智能体
合成器代理是创建有用建议的 编写器 。
合成器代理接收原始用户查询以及酒店搜索结果。 它向 AI 模型发送所有内容,其中包含编写建议的说明。 它返回一个自然语言响应,用于比较酒店并解释最佳选项。 此方法很重要,因为原始搜索结果对用户不友好。 合成器将数据库记录转换为对话建议,该建议解释了某些酒店为何与用户的需求匹配。
async function runSynthesizerAgent(synthClient: any, userQuery: string, hotelContext: string): Promise<string> {
console.log('\n--- SYNTHESIZER ---');
let conciseContext = hotelContext;
console.log(`Context size is ${conciseContext.length} characters`);
const agent = createAgent({
model: synthClient,
systemPrompt: SYNTHESIZER_SYSTEM_PROMPT,
});
const agentResult = await agent.invoke({
messages: [{
role: 'user',
content: createSynthesizerUserPrompt(userQuery, conciseContext)
}]
});
const synthMessages = agentResult.messages;
const finalAnswer = synthMessages[synthMessages.length - 1].content;
console.log(`Output: ${finalAnswer.length} characters of final recommendation`);
return finalAnswer as string;
}
用于矢量存储搜索的代理工具
src/vector-store.ts源文件定义 Planner 代理使用的矢量搜索工具。
工具文件定义 AI 代理可用于查找酒店的搜索工具。 此工具是代理连接到数据库的方式。 AI 不会直接搜索数据库。 它要求使用搜索工具,该工具执行实际搜索。
Node.js 函数作为工具定义
LangChain 的 tool 函数从常规 TypeScript 函数创建工具。 工具定义包括名称、说明和架构(使用 Zod 进行验证)。 此定义使 AI 知道该工具存在以及如何正确使用它。
export const getHotelsToMatchSearchQuery = tool(
async ({ query, nearestNeighbors }, config): Promise<string> => {
try {
const store = config.context.store as AzureDocumentDBVectorStore;
const embeddingClient = config.context.embeddingClient as AzureOpenAIEmbeddings;
// Create query embedding and perform search
const queryVector = await embeddingClient.embedQuery(query);
const results = await store.similaritySearchVectorWithScore(queryVector, nearestNeighbors);
console.log(`Found ${results.length} documents from vector store`);
// Format results for synthesizer
const formatted = results.map(([doc, score]) => {
const md = doc.metadata as Partial<HotelForVectorStore>;
console.log(`Hotel: ${md.HotelName ?? 'N/A'}, Score: ${score}`);
return formatHotelForSynthesizer(md, score);
}).join('\n\n');
return formatted;
} catch (error) {
console.error('Error in getHotelsToMatchSearchQuery tool:', error);
return 'Error occurred while searching for hotels.';
}
},
{
name: TOOL_NAME,
description: TOOL_DESCRIPTION,
schema: z.object({
query: z.string(),
nearestNeighbors: z.number().optional().default(5),
}),
}
);
使用 Node.js 工具执行 Azure DocumentDB 矢量搜索
当 AI 调用该工具时,函数主体将运行。 它通过使用 Azure OpenAI 的嵌入模型将文本查询转换为数值向量来生成嵌入。 然后,它会通过向量发送到 Azure DocumentDB 来搜索数据库,后者查找具有类似向量的酒店,这意味着类似的说明。 最后,它通过将数据库记录转换为合成器代理可以理解的可读文本来设置结果的格式。
实现利用 LangChain的AzureDocumentDBVectorStore组件,实现与Azure DocumentDB的无缝集成。
为何使用此模式?
将工具与代理分离可提供灵活性。 AI 决定何时搜索和搜索内容,而该工具将处理如何搜索。 无需更改代理逻辑即可添加更多工具。
用于指导 AI 行为的智能体提示
源文件 src/utils/prompts.ts 包含代理的系统提示和工具定义。
提示词文件定义了提供给规划器和合成器智能体的 AI 模型的指令和上下文。 这些提示指导 AI 的行为,并确保它了解其在工作流中的角色。
AI 响应的质量在很大程度上取决于明确的说明。 这些提示设置边界、定义输出格式,并将 AI 放在用户做出决策的目标上。 可以自定义这些提示以更改代理的行为方式,而无需修改任何代码。
export const PLANNER_SYSTEM_PROMPT = `You are a hotel search planner. Transform the user's request into a clear, detailed search query for a vector database.
CRITICAL REQUIREMENT: You MUST ALWAYS call the "${TOOL_NAME}" tool. This is MANDATORY for every request.
Use a tool call with:
- query (string)
- nearestNeighbors (number 1-20)
QUERY REFINEMENT RULES:
- If vague (e.g., "nice hotel"), add specific attributes: "hotel with high ratings and good amenities"
- If minimal (e.g., "cheap"), expand: "budget hotel with good value"
- Preserve specific details from user (location, amenities, business/leisure)
- Keep natural language - this is for semantic search
- Don't just echo the input - improve it for better search results
- nearestNeighbors: Use 3-5 for specific requests, 10-15 for broader requests, max 20
EXAMPLES:
User: "cheap hotel" → {"tool": "${TOOL_NAME}", "args": {"query": "budget-friendly hotel with good value and affordable rates", "nearestNeighbors": 10}}
User: "hotel near downtown with parking" → {"tool": "${TOOL_NAME}", "args": {"query": "hotel near downtown with good parking and wifi", "nearestNeighbors": 5}}
User: "nice place to stay" → {"tool": "${TOOL_NAME}", "args": {"query": "hotel with high ratings, good reviews, and quality amenities", "nearestNeighbors": 10}}
Do not answer the user directly. Always call the tool.`;
// ============================================================================
// Synthesizer Prompts
// ============================================================================
export const SYNTHESIZER_SYSTEM_PROMPT = `You are an expert hotel recommendation assistant using vector search results.
Only use the TOP 3 results provided. Do not request additional searches or call other tools.
GOAL: Provide a concise comparative recommendation to help the user choose between the top 3 options.
REQUIREMENTS:
- Compare only the top 3 results across the most important attributes: rating, score, location, price-level (if available), and key tags (parking, wifi, pool).
- Identify the main tradeoffs in one short sentence per tradeoff.
- Give a single clear recommendation with one short justification sentence.
- Provide up to two alternative picks (one sentence each) explaining when they are preferable.
FORMAT CONSTRAINTS:
- Plain text only (no markdown).
- Keep the entire response under 220 words.
- Use simple bullets (•) or numbered lists and short sentences (preferably <25 words per sentence).
- Preserve hotel names exactly as provided in the tool summary.
Do not add extra commentary, marketing language, or follow-up questions. If information is missing and necessary to choose, state it in one sentence and still provide the best recommendation based on available data.`;
使用 Node.js 准备数据并将其上传到 Azure DocumentDB
此示例使用 JSON 文件中的酒店数据。 存储库包含两个版本:
-
Hotels.json- 该示例使用的酒店数据不含矢量嵌入 -
Hotels_Vector.json- 具有预计算嵌入的酒店数据(供其他示例使用)
上传的工作原理
该 upload-documents.ts 脚本执行三个步骤:
-
加载数据 - 从
Hotels.json文件读取酒店记录。 -
生成嵌入 - 对于每个酒店,脚本会将
Description字段发送到 Azure OpenAItext-embedding-3-small模型,以生成一个 1536 维矢量嵌入。 这会将文本说明转换为捕获其语义含义的数字表示形式。 - 插入和索引 — 脚本将文档(及其嵌入内容)插入 Azure DocumentDB 集合,并使用配置的算法(IVF、HNSW 或 DiskANN)创建矢量索引。
import { createClientsPasswordless, createClients } from './utils/clients.js';
import { getStore } from './vector-store.js';
/**
* Upload documents to Azure DocumentDB MongoDB Vector Store
*/
async function uploadDocuments() {
try {
console.log('Starting document upload...\n');
// Get clients based on authentication mode
const usePasswordless = process.env.USE_PASSWORDLESS === 'true' || process.env.USE_PASSWORDLESS === '1';
console.log(`Authentication mode: ${usePasswordless ? 'Passwordless (Azure AD)' : 'API Key'}`);
console.log('\nEnvironment variables check:');
console.log(` DATA_FILE_WITHOUT_VECTORS: ${process.env.DATA_FILE_WITHOUT_VECTORS}`);
console.log(` AZURE_DOCUMENTDB_DATABASENAME: ${process.env.AZURE_DOCUMENTDB_DATABASENAME}`);
console.log(` AZURE_DOCUMENTDB_COLLECTION: ${process.env.AZURE_DOCUMENTDB_COLLECTION}`);
console.log(` AZURE_DOCUMENTDB_CLUSTER: ${process.env.AZURE_DOCUMENTDB_CLUSTER}`);
console.log(` AZURE_OPENAI_EMBEDDING_MODEL: ${process.env.AZURE_OPENAI_EMBEDDING_MODEL}`);
const requiredEnvVars = [
'DATA_FILE_WITHOUT_VECTORS',
'AZURE_DOCUMENTDB_DATABASENAME',
'AZURE_DOCUMENTDB_COLLECTION',
'AZURE_DOCUMENTDB_CLUSTER',
'AZURE_OPENAI_EMBEDDING_MODEL',
];
const missingEnvVars = requiredEnvVars.filter((name) => {
const value = process.env[name];
return !value || value.trim().length === 0;
});
if (missingEnvVars.length > 0) {
throw new Error(`Missing required environment variables: ${missingEnvVars.join(', ')}`);
}
const clients = usePasswordless ? createClientsPasswordless() : createClients();
const { embeddingClient, dbConfig } = clients;
console.log('\ndbConfig properties:');
console.log(` instance: ${dbConfig.instance}`);
console.log(` databaseName: ${dbConfig.databaseName}`);
console.log(` collectionName: ${dbConfig.collectionName}`);
// Check for data file path
const dataFilePath = process.env.DATA_FILE_WITHOUT_VECTORS!;
console.log(`\nReading data from: ${dataFilePath}`);
console.log(`Database: ${dbConfig.databaseName}`);
console.log(`Collection: ${dbConfig.collectionName}`);
console.log(`Vector algorithm: ${process.env.VECTOR_INDEX_ALGORITHM || 'vector-ivf'}\n`);
// Upload documents using existing getStore function
const startTime = Date.now();
const store = await getStore(dataFilePath, embeddingClient, dbConfig);
const duration = ((Date.now() - startTime) / 1000).toFixed(2);
console.log(`\n✓ Upload completed in ${duration} seconds`);
// Close connection
await store.close();
console.log('✓ Connection closed');
// Force exit to ensure process terminates (Azure credential timers may still be active)
process.exit(0);
} catch (error: any) {
console.error('\n✗ Upload failed:', error?.message || error);
console.error('\nFull error:', error);
process.exit(1);
}
}
// Run the upload
uploadDocuments();
矢量索引创建
矢量索引是可实现快速相似性搜索的内容。 创建索引时,Azure DocumentDB 会组织嵌入向量,以便在不扫描每个文档的情况下有效地回答“查找与此描述类似的酒店”等查询。
选择的索引类型会影响性能:
| 算法 | 群集层 | 最适用于 |
|---|---|---|
| IVF | M10+ | 小型到中型数据集,降低成本 |
| HNSW | M30+ | 高召回率、快速查询 |
| DiskANN | M40+ | 大型数据集,十亿多个向量 |
import {
AzureDocumentDBVectorStore,
AzureDocumentDBSimilarityType,
AzureDocumentDBConfig
} from "@langchain/azure-cosmosdb";
import type { AzureOpenAIEmbeddings } from "@langchain/openai";
import { readFileSync } from 'fs';
import { Document } from '@langchain/core/documents';
import { HotelsData, Hotel } from './utils/types.js';
import { TOOL_NAME, TOOL_DESCRIPTION } from './utils/prompts.js';
import { z } from 'zod';
import { tool } from "langchain";
import { MongoClient } from 'mongodb';
import { BaseMessage } from "@langchain/core/messages";
type HotelForVectorStore = Omit<Hotel, 'Description_fr' | 'Location' | 'Rooms'>;
// Helper function for similarity type
function getSimilarityType(similarity: string) {
switch (similarity.toUpperCase()) {
case 'COS': return AzureDocumentDBSimilarityType.COS;
case 'L2': return AzureDocumentDBSimilarityType.L2;
case 'IP': return AzureDocumentDBSimilarityType.IP;
default: return AzureDocumentDBSimilarityType.COS;
}
}
// Consolidated vector index configuration
function getVectorIndexOptions() {
const algorithm = process.env.VECTOR_INDEX_ALGORITHM || 'vector-ivf';
const dimensions = parseInt(process.env.EMBEDDING_DIMENSIONS || '1536');
const similarity = getSimilarityType(process.env.VECTOR_SIMILARITY || 'COS');
const baseOptions = { dimensions, similarity };
switch (algorithm) {
case 'vector-hnsw':
return {
kind: 'vector-hnsw' as const,
m: parseInt(process.env.HNSW_M || '16'),
efConstruction: parseInt(process.env.HNSW_EF_CONSTRUCTION || '64'),
...baseOptions
};
case 'vector-diskann':
return {
kind: 'vector-diskann' as const,
...baseOptions
};
case 'vector-ivf':
default:
使用 Node.js 运行代理 RAG 应用程序
安装依赖项:
npm install在运行代理之前,请上传带有嵌入的酒店数据。 该
upload-documents.ts命令从 JSON 文件加载酒店,使用text-embedding-3-small每个酒店生成嵌入内容,将文档插入 Azure DocumentDB,并创建矢量索引。npm run upload使用
agent.ts命令运行酒店推荐代理。 代理调用 Planner 代理、矢量搜索和合成器代理。 输出包括相似性分数,以及合成器代理的比较分析与建议。npm startDEBUG mode is OFF DEBUG_CALLBACKS length: 0 Connected to existing vector store: Hotels.hotel_data --- PLANNER --- Found 5 documents from vector store Hotel: Nordick's Valley Motel, Score: 0.49866509437561035 Hotel: White Mountain Lodge & Suites, Score: 0.48731985688209534 Hotel: Trails End Motel, Score: 0.47985398769378662 Hotel: Country Comfort Inn, Score: 0.47431993484497070 Hotel: Lakefront Captain Inn, Score: 0.45787304639816284 --- SYNTHESIZER --- Context size is 3233 characters Output: 812 characters of final recommendation --- FINAL ANSWER --- 1. COMPARISON SUMMARY: • Nordick's Valley Motel has the highest rating (4.5) and offers free parking, air conditioning, and continental breakfast. It is located in Washington D.C., near historic attractions and trails. • White Mountain Lodge & Suites is a resort with unique amenities like a pool, restaurant, and meditation gardens, but has the lowest rating (2.4). It is located in Denver, surrounded by forest trails. • Trails End Motel is budget-friendly with a moderate rating (3.2), free parking, free wifi, and a restaurant. It is close to downtown Scottsdale and eateries. Key tradeoffs: - Nordick's Valley Motel excels in rating and proximity to historic attractions but lacks a pool or free wifi. - White Mountain Lodge & Suites offers resort-style amenities and forest trails but has the lowest rating. - Trails End Motel balances affordability and essential amenities but has fewer unique features compared to the others. 2. BEST OVERALL: Nordick's Valley Motel is the best choice for its high rating, proximity to trails and attractions, and free parking. 3. ALTERNATIVE PICKS: • Choose White Mountain Lodge & Suites if you prioritize resort amenities and forest trails over rating. • Choose Trails End Motel if affordability and proximity to downtown Scottsdale are your main concerns.
在 Visual Studio Code 中查看和管理数据
在 Visual Studio Code 中选择 DocumentDB 扩展 以连接到 Azure DocumentDB 帐户。
查看 Hotels 数据库中的数据和索引。
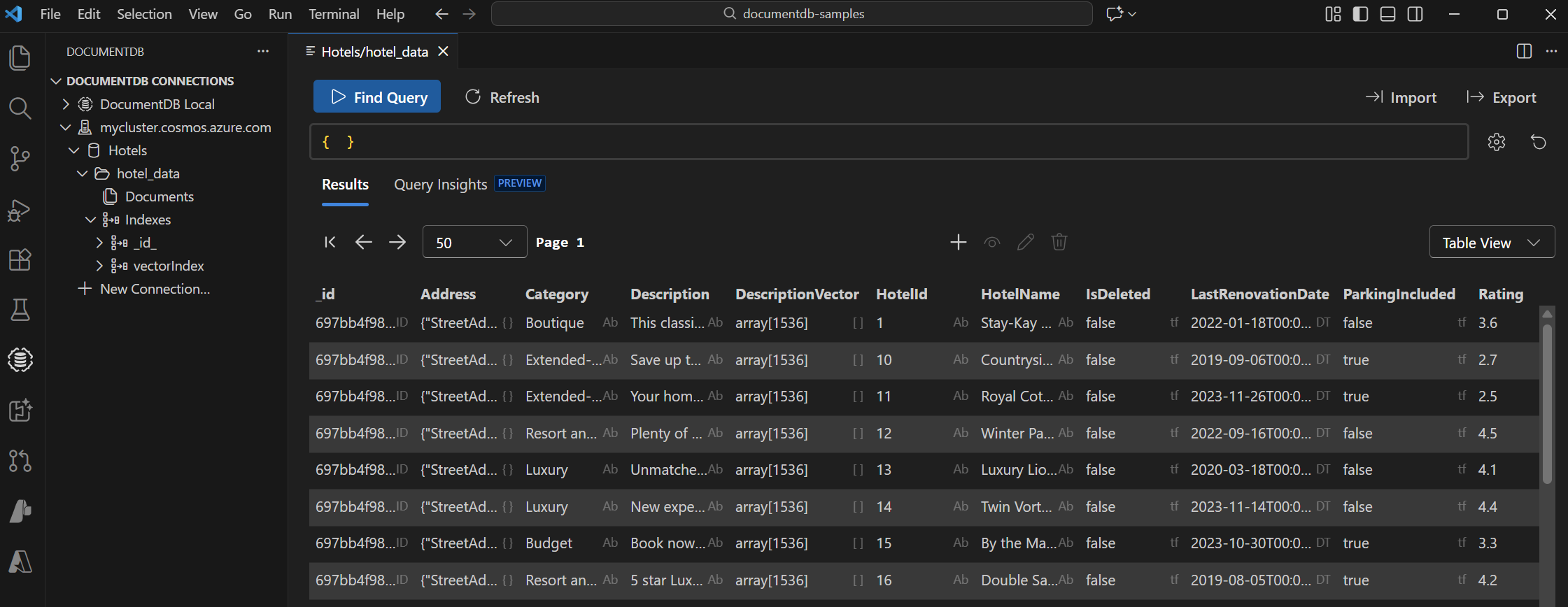
清理资源
如果你使用 azd up 来预配资源,可以使用以下命令删除所有 Azure 资源:
azd down
如果手动创建了资源,并且想要删除所有资源,请删除资源组以避免额外费用。
如果要重复使用资源,请使用清理命令在完成后删除测试数据库。 运行下面的命令:
npm run cleanup