你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
了解如何使用适用于 Visual Studio Code 的 Apache Spark 和 Hive 工具。 使用工具为 Apache Spark 创建和提交 Apache Hive 批处理作业、交互式 Hive 查询和 PySpark 脚本。 首先,本文将介绍如何在 Visual Studio Code 中安装 Spark 和 Hive 工具。 随后介绍如何将作业提交到 Spark 和 Hive 工具。
可将 Spark 和 Hive 工具安装在 Visual Studio Code 支持的平台上。 注意针对不同平台的以下先决条件。
先决条件
完成本文中的步骤需要以下各项:
- 一个 Azure HDInsight 群集。 若要创建群集,请参阅 HDInsight 入门。 或使用支持 Apache Livy 终结点的 Spark 和 Hive 群集。
- Visual Studio Code。
- Mono。 只有 Linux 和 macOS 需要 Mono。
- Visual Studio Code 的 PySpark 交互式环境。
- 本地目录。 本文使用的是
C:\HD\HDexample。
安装 Spark & Hive Tools
满足先决条件后,可遵循以下步骤安装适用于 Visual Studio Code 的 Spark 和 Hive 工具:
打开 Visual Studio Code。
从菜单栏中,导航到“查看”>“扩展” 。
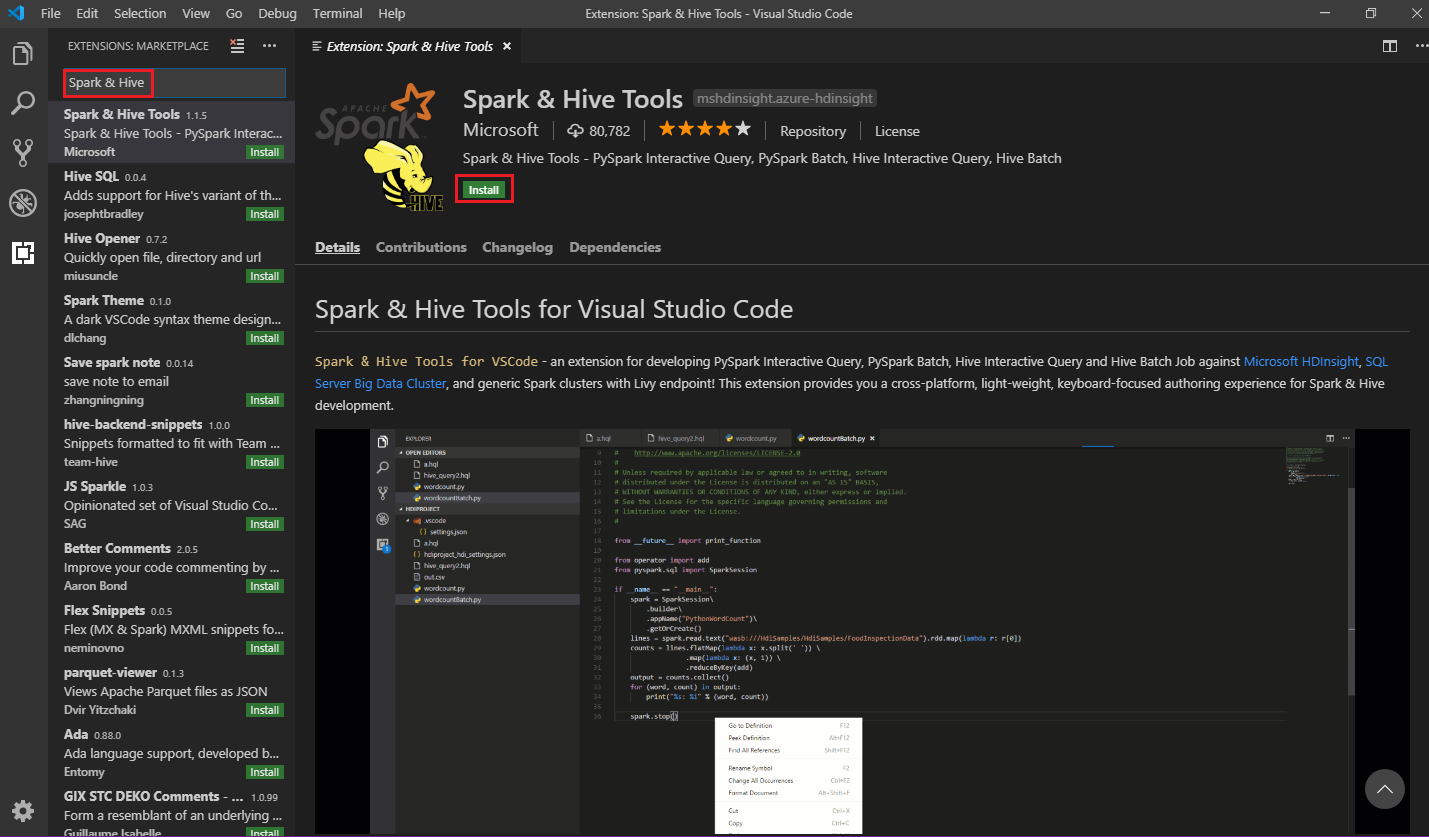
在搜索框中,输入“Spark & Hive”。
从搜索结果中选择“Spark 和 Hive 工具”,然后选择“安装”:
根据需要选择“重载”。
打开工作文件夹
若要打开工作文件夹并在 Visual Studio Code 中创建文件,请执行以下步骤:
在菜单栏中,导航到“文件”>“打开文件夹...”,然后选择“选择文件夹”按钮。>
C:\HD\HDexample该文件夹显示在左侧的“资源管理器”视图中。在“资源管理器”视图中选择
HDexample文件夹,然后选择工作文件夹旁边的“新建文件”图标: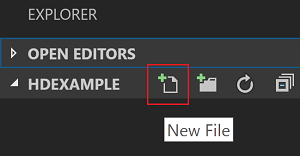
为新文件命名,使用
.hql(Hive 查询)或.py(Spark 脚本)作为文件扩展名。 本示例使用 HelloWorld.hql。
设置 Azure 环境
国家云用户请先遵循以下步骤设置 Azure 环境,然后使用“Azure:登录”命令登录到 Azure:
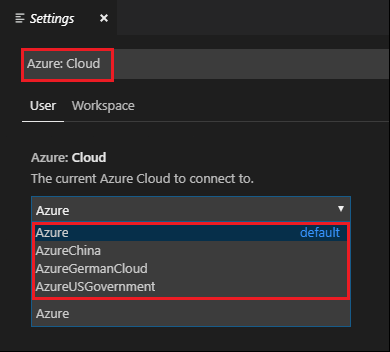
导航到“文件”>“首选项”>“设置”。
搜索以下字符串:Azure:云。
从列表中选择国家云:
连接到 Azure 帐户
在你可以从 Visual Studio Code 将脚本提交到群集之前,用户可以登录 Azure 订阅,或链接 HDInsight 群集。 使用 Ambari 用户名/密码或 ESP 群集的域加入凭据连接到 HDInsight 群集。 遵循以下步骤连接到 Azure:
在菜单栏中,导航到“视图”>“命令面板...”,然后输入“Azure: 登录”:
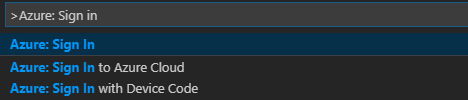
按照登录说明登录到 Azure。 连接后,Visual Studio Code 窗口底部的状态栏上会显示 Azure 帐户名称。
链接群集
链接:Azure HDInsight
可以使用 Apache Ambari 管理的用户名链接标准群集,也可以使用域用户名(例如:user1@contoso.com)链接 Enterprise Security Pack 安全 Hadoop 群集。
在菜单栏中,导航到“视图”>“命令面板...”,然后输入“Spark/Hive: Link a Cluster”。

选择链接的群集类型“Azure HDInsight”。
输入 HDInsight 群集 URL。
输入 Ambari 用户名,默认为 admin。
输入 Ambari 密码。
选择群集类型。
设置群集的显示名称(可选)。
查看“输出”视图以进行验证。
注意
如果群集已登录到 Azure 订阅中并且已链接群集,则使用链接用户名和密码。
链接:通用 Livy 终结点
在菜单栏中,导航到“视图”>“命令面板...”,然后输入“Spark/Hive: Link a Cluster”。
选择链接的群集类型“通用 Livy 终结点”。
输入通用 livy 终结点。 例如:http://10.172.41.42:18080.
选择授权类型“基本”或“无”。 如果选择“基本”:
输入 Ambari 用户名,默认为 admin。
输入 Ambari 密码。
查看“输出”视图以进行验证。
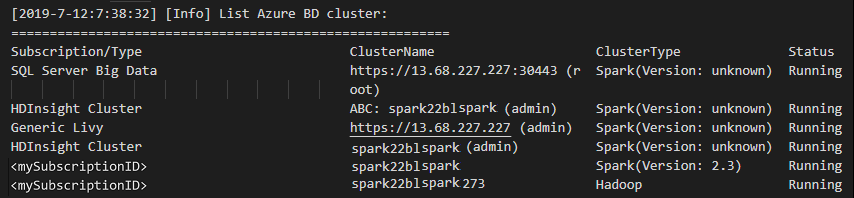
列出群集
在菜单栏中,导航到“视图”>“命令面板...”,然后输入“Spark/Hive: List Cluster”。
选择所需的订阅。
检查“输出”视图。 此视图显示你的链接群集(或多个群集),以及你的 Azure 订阅下的所有群集:
设置默认群集
重新打开前面所述的
HDexample文件夹(如果已关闭)。选择前面创建的 HelloWorld.hql 文件。 它将在脚本编辑器中打开。
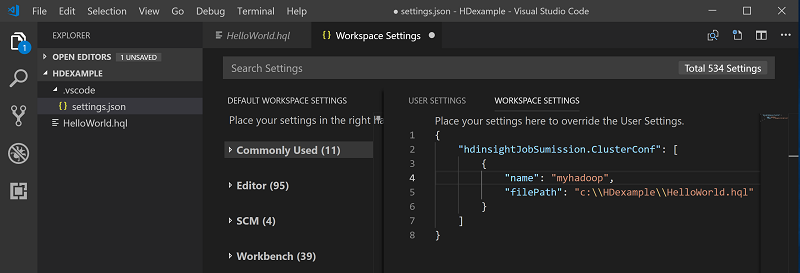
右键单击脚本编辑器,然后选择“Spark/ Hive:Set Default Cluster”。
连接到 Azure 帐户或链接某个群集(如果尚未这样做)。
选择一个群集作为当前脚本文件的默认群集。 工具将自动更新 .VSCode\settings.json 配置文件:
提交交互式 Hive 查询和 Hive 批处理脚本
通过 Visual Studio Code 的 Spark 和 Hive 工具,可将交互式 Hive 查询和 Hive 批处理脚本提交到群集。
重新打开前面所述的
HDexample文件夹(如果已关闭)。选择前面创建的 HelloWorld.hql 文件。 它将在脚本编辑器中打开。
将以下代码复制并粘贴到 Hive 文件中,然后保存该文件:
SELECT * FROM hivesampletable;连接到 Azure 帐户或链接某个群集(如果尚未这样做)。
右键单击脚本编辑器,然后选择“Hive:Interactive”以提交查询,或使用 Ctrl+Alt+I 快捷键。 选择“Hive:批处理”以提交脚本,或使用 Ctrl+Alt+H 快捷键。
如果尚未指定默认群集,请选择群集。 工具还允许使用上下文菜单提交代码块而非整个脚本文件。 不久之后,查询结果将显示在新选项卡中:
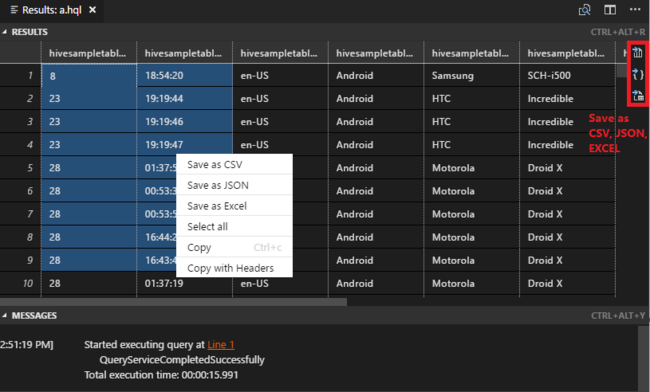
“结果”面板:可以将整个结果作为 CSV、JSON、Excel 保存到本地路径,也可以只选择多个行。
“消息”面板:选择行号会跳转到运行的脚本的第一行。
提交交互式 PySpark 查询
Pyspark 交互的先决条件
请注意,HDInsight 交互式 PySpark 查询需要使用 Jupyter 扩展版本 (ms-jupyter):v2022.1.1001614873 和 Python 扩展版本 (ms-python):v2021.12.1559732655、Python 3.6.x 和 3.7.x。
用户可通过以下方式执行 PySpark Interactive 命令。
在 PY 文件中使用 PySpark Interactive 命令
使用 PySpark Interactive 命令提交查询时,请执行以下步骤:
重新打开前面所述的
HDexample文件夹(如果已关闭)。遵循前面所述的步骤创建新的 HelloWorld.py 文件。
将以下代码复制并粘贴到脚本文件中:
from operator import add from pyspark.sql import SparkSession spark = SparkSession.builder \ .appName('hdisample') \ .getOrCreate() lines = spark.read.text("/HdiSamples/HdiSamples/FoodInspectionData/README").rdd.map(lambda r: r[0]) counters = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) coll = counters.collect() sortedCollection = sorted(coll, key = lambda r: r[1], reverse = True) for i in range(0, 5): print(sortedCollection[i])窗口右下角显示安装 PySpark/Synapse Pyspark 内核的提示。 可以单击“安装”按钮继续安装 PySpark/Synapse Pyspark;或单击“跳过”按钮跳过此步骤。
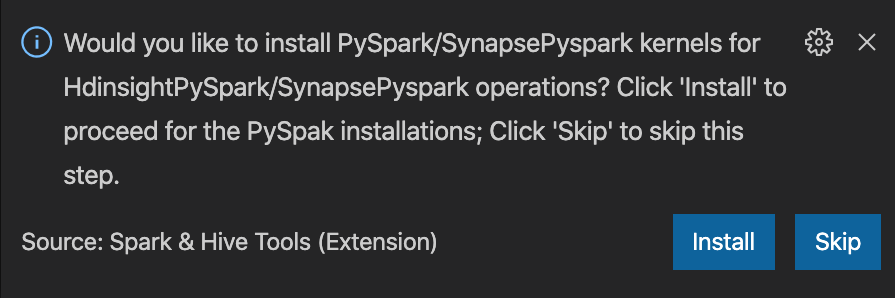
如果以后需要安装,可以导航到“文件”>“首选项”>“设置”,然后在设置中取消选中“HDInsight:允许跳过 Pyspark 安装”。
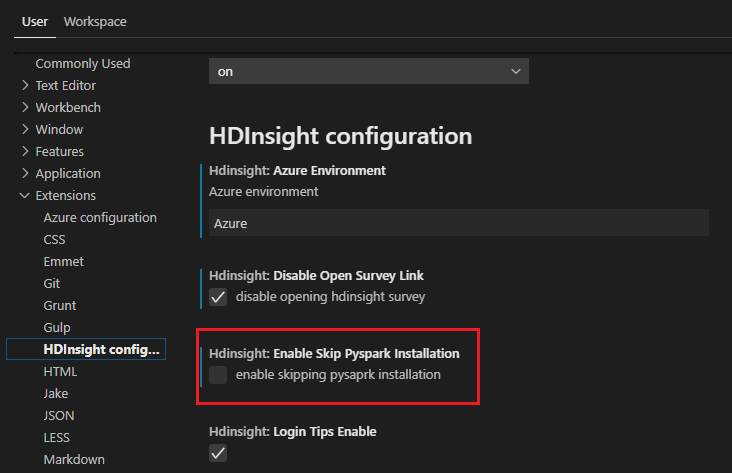
如果在步骤 4 中安装成功,则会在窗口右下角显示“已成功安装 PySpark”消息框。 单击“重载”按钮可重载此窗口。
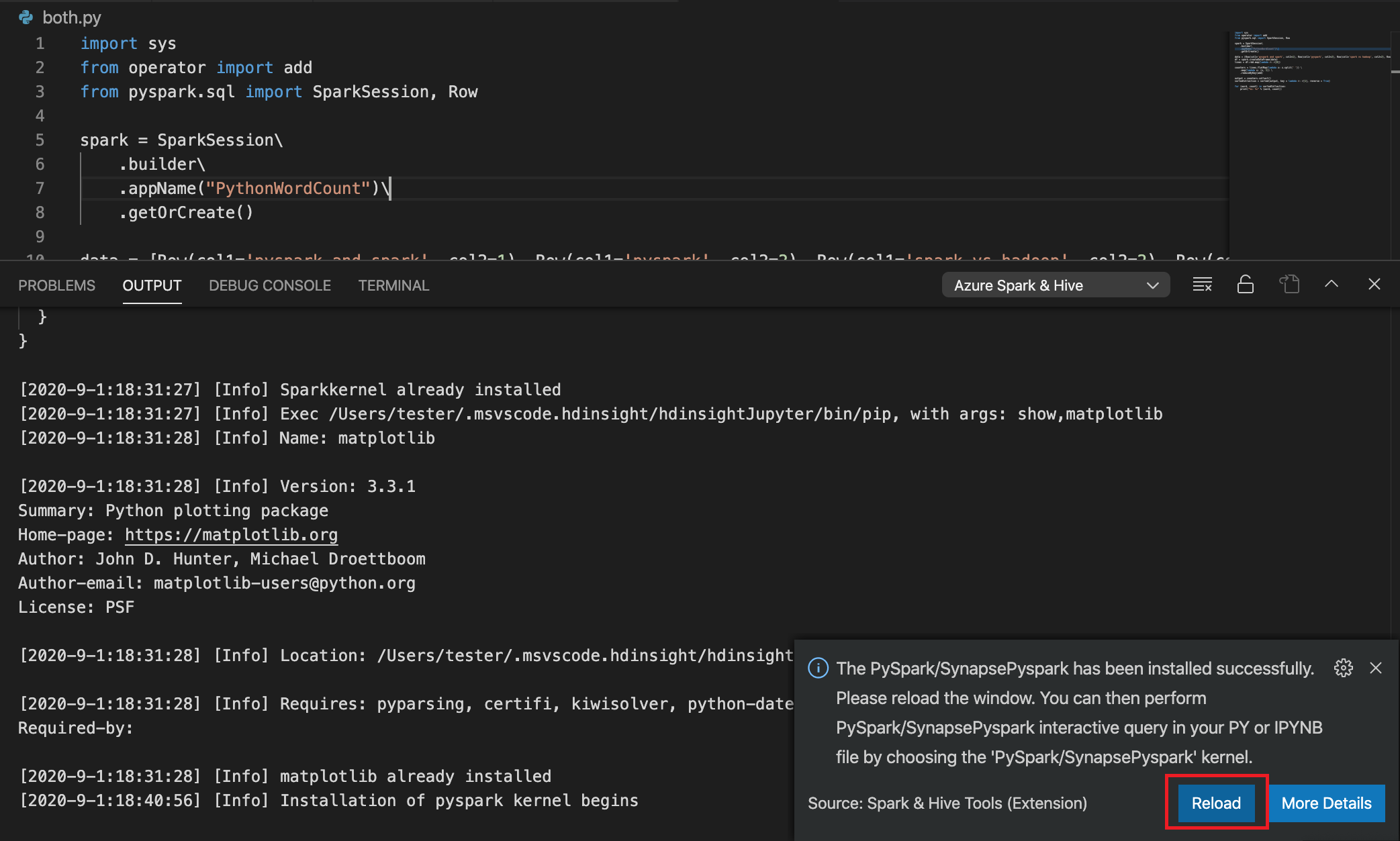
从菜单栏中,导航到“查看”>“命令面板...”或使用 Shift + Ctrl + P 键盘快捷键,然后输入“Python:选择解释器以启动 Jupyter 服务器”。

选择下面的 Python 选项。

从菜单栏中,导航到“查看”>“命令面板...”或使用 Shift + Ctrl + P 键盘快捷键,然后输入“开发人员:重载窗口”。

连接到 Azure 帐户或链接某个群集(如果尚未这样做)。
选择所有代码,右键单击脚本编辑器并选择“Spark: PySpark Interactive / Synapse: Pyspark Interactive”以提交查询。
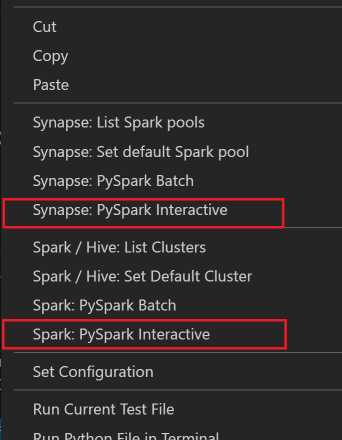
如果尚未指定默认群集,请选择群集。 不久之后,新选项卡中会显示“Python Interactive 结果”。单击 PySpark 可将内核切换到“PySpark/Synapse Pyspark”,代码会成功运行。 如果要切换到 Synapse Pyspark 内核,建议在 Azure 门户中禁用自动设置。 否则,首次使用时,可能需要很长时间才能唤醒群集和设置 synapse 内核。 如果工具还允许使用上下文菜单提交代码块而非整个脚本文件:
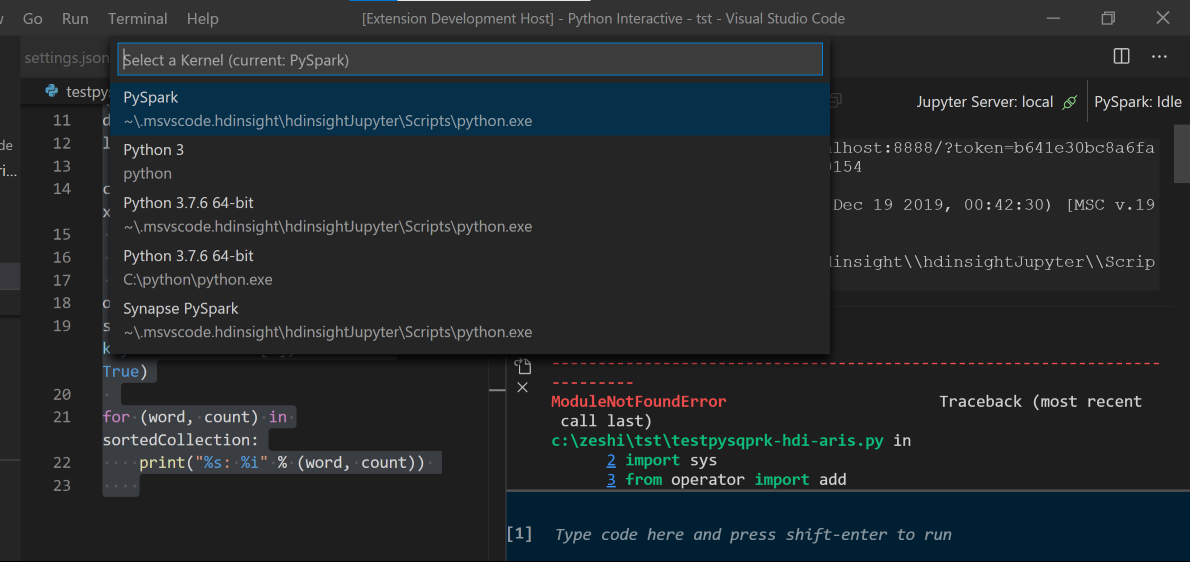
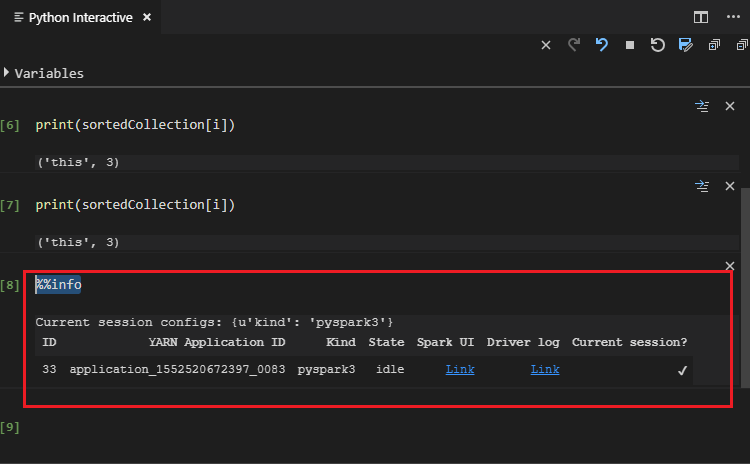
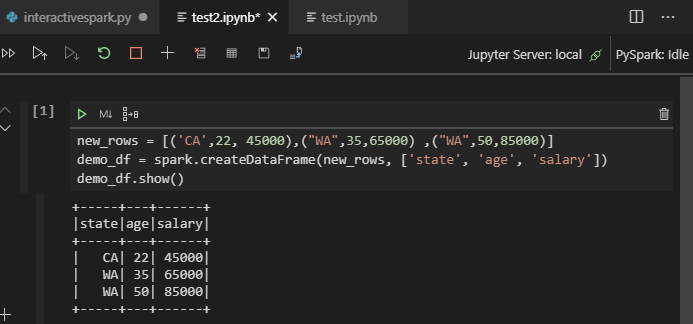
输入 %%info,然后按 Shift+Enter 查看作业信息(可选):
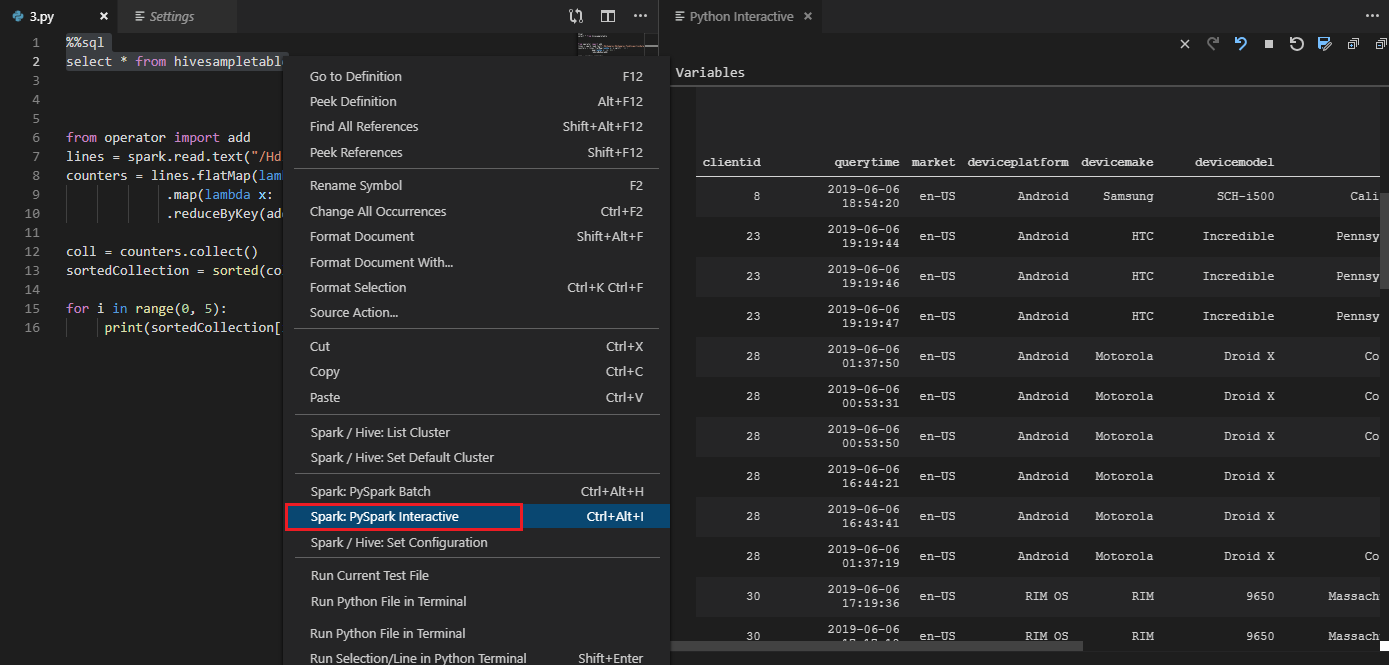
工具还支持 Spark SQL 查询:
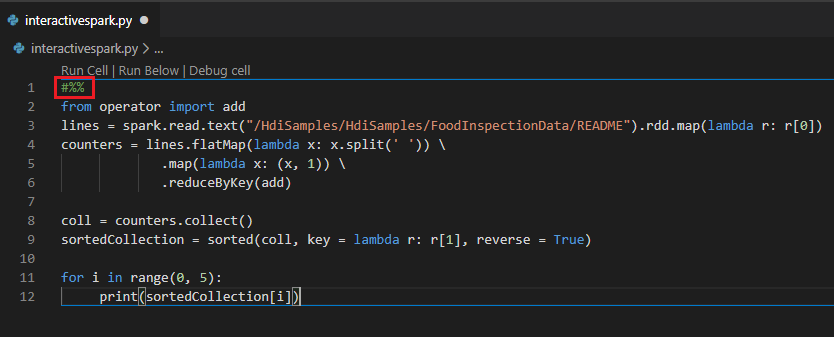
使用 #%% 注释在 PY 文件中执行交互式查询
将 #%% 添加到 PY 代码之前以获取笔记本体验。
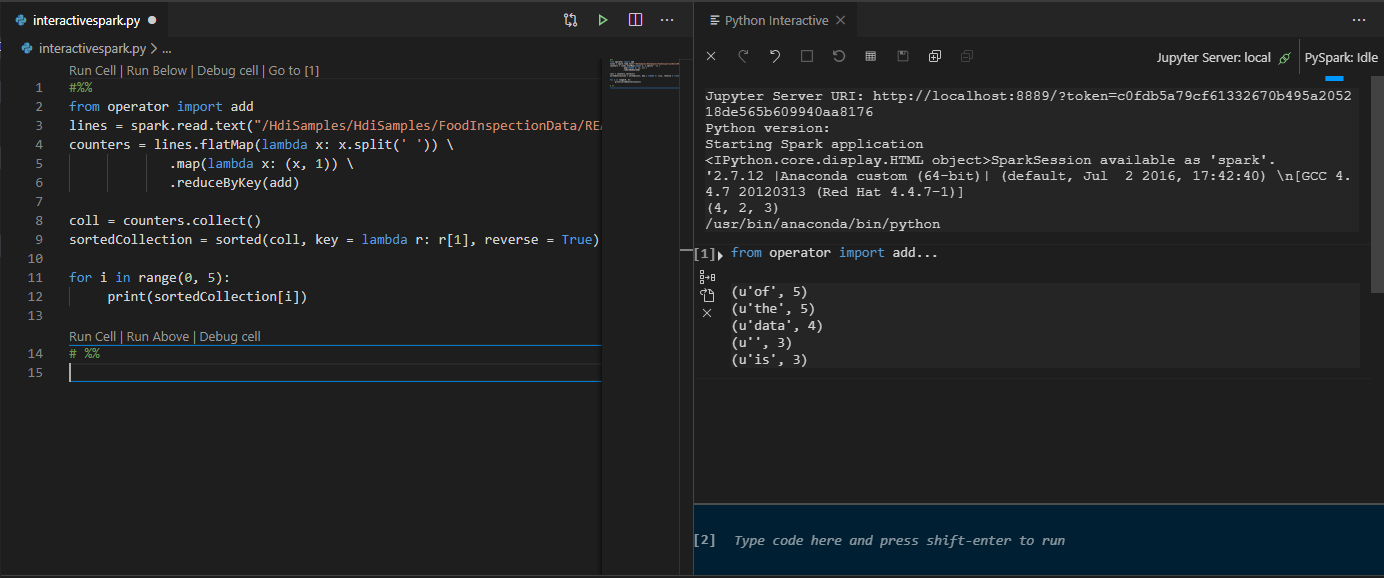
单击“运行单元格”。 不久之后,Python Interactive 结果会显示在一个新选项卡中。单击 PySpark 将内核切换为“PySpark/Synapse PySpark”,然后再次单击“运行单元格”,代码将成功运行。
利用 Python 扩展中的 IPYNB 支持
若要创建 Jupyter Notebook,可以使用命令面板中的命令,也可以在工作区中创建新的
.ipynb文件。 有关详细信息,请参阅在 Visual Studio Code 中使用 Jupyter Notebook单击“运行单元格”按钮,按提示“设置默认 Spark 池”(建议每次打开笔记本之前都设置默认群集/池),然后重载窗口。
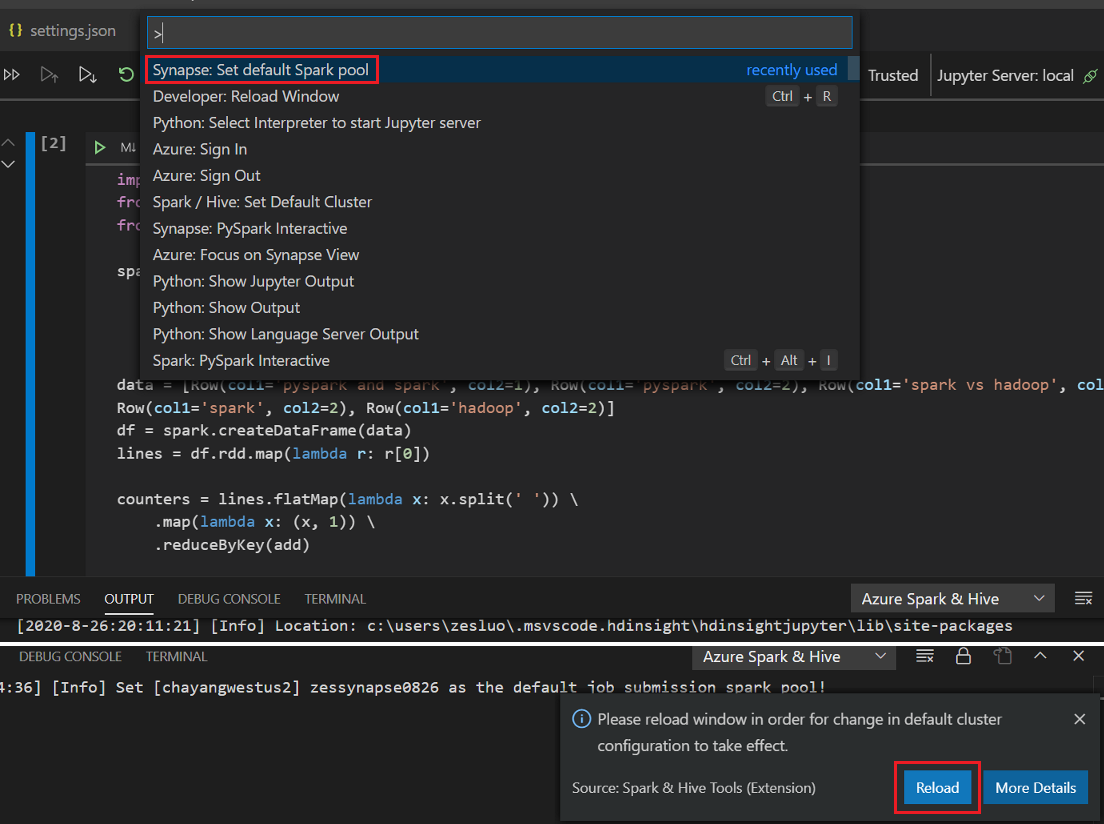
单击 PySpark 将内核切换为“PySpark/Synapse Pyspark”,然后单击“运行单元格”,一段时间后将显示结果。
注意
对于 Synapse PySpark 安装错误,由于其他团队不再维护其依赖项,因此也不会再对它进行维护。 如果你尝试使用交互式 Synapse Pyspark,请改用 Azure Synapse Analytics。 这是一项长期更改。
提交 PySpark 批处理作业
重新打开前面所述的
HDexample文件夹(如果已关闭)。遵循前面所述的步骤创建新的 BatchFile.py 文件。
将以下代码复制并粘贴到脚本文件中:
from __future__ import print_function import sys from operator import add from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv').rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' '))\ .map(lambda x: (x, 1))\ .reduceByKey(add) output = counts.collect() for (word, count) in output: print("%s: %i" % (word, count)) spark.stop()连接到 Azure 帐户或链接某个群集(如果尚未这样做)。
右键单击脚本编辑器,然后选择“Spark: PySpark Batch”或“Synapse: PySpark Batch*”。
选择要将 PySpark 作业提交到的群集/Spark 池:
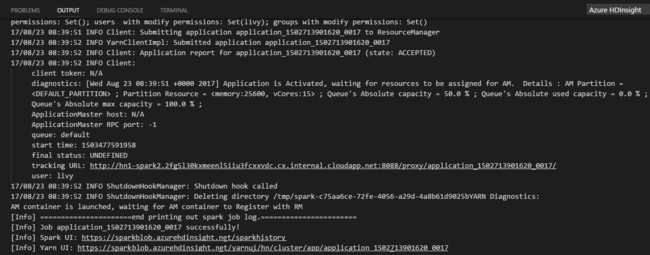
提交 Python 作业后,提交日志将显示在 Visual Studio Code 的“输出”窗口中。 同时还会显示 Spark UI URL 和 Yarn UI URL。 如果将批处理作业提交到 Apache Spark 池,则还会显示 Spark 历史记录 UI URL 和 Spark 作业应用程序 UI URL。 你可以在 Web 浏览器中打开 URL 以跟踪作业状态。
与 HDInsight Identity Broker (HIB) 集成
连接带有 ID 代理的 HDInsight ESP 群集 (HIB)
可以按照常规步骤登录到 Azure 订阅,以连接带有 ID 代理的 HDInsight ESP 群集 (HIB)。 登录后,将在 Azure 资源管理器中看到群集列表。 有关详细信息,请参阅连接到 HDInsight 群集。
在带有 ID 代理的 HDInsight ESP 群集 (HIB) 上运行 Hive/PySpark 作业
若要运行 hive 作业,可以按照常规步骤将作业提交到带有 ID 代理的 HDInsight ESP 群集 (HIB)。 有关更多说明,请参阅提交交互式 Hive 查询和 Hive 批处理脚本。
若要运行交互式 PySpark 作业,可以按照常规步骤将作业提交到带有 ID 代理的 HDInsight ESP 群集 (HIB)。 请参考“提交交互式 PySpark 查询”。
若要运行 PySpark 批处理作业,可以按照常规步骤将作业提交到带有 ID 代理的 HDInsight ESP 群集 (HIB)。 有关更多说明,请参阅提交 PySpark 批处理作业。
Apache Livy 配置
支持 Apache Livy 配置。 可在工作空间文件夹中的 .VSCode\settings.json 内配置 Apache Livy。 目前,Livy 配置仅支持 Python 脚本。 有关详细信息,请参阅 Livy 自述文件。
方法 1
- 从菜单栏中,导航到“文件”>“首选项”>“设置” 。
- 在“搜索设置”框中,输入“HDInsight 作业提交: Livy Conf”。
- 选择“在 settings.json 中编辑”以获取相关搜索结果。
方法 2
提交一个文件,注意 .vscode 文件夹会自动添加到工作文件夹。 可以通过选择“.vscode\settings.json”来查看 Livy 配置。
项目设置:
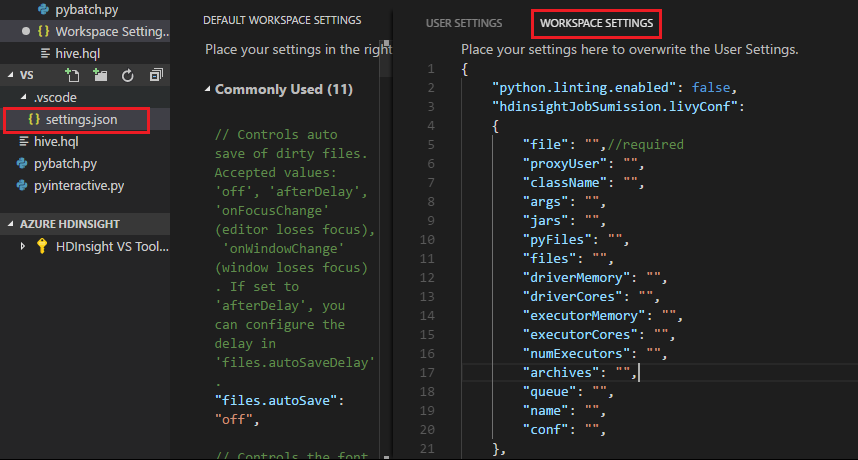
注意
对于 driverMemory 和 executorMemory 设置,请设置值和单位。 例如:1g 或 1024m。
支持的 Livy 配置:
POST /batches
请求正文
name description type file 包含要执行的应用程序的文件 Path(必需) proxyUser 运行作业时要模拟的用户 String className 应用程序 Java/Spark 主类 String args 应用程序的命令行参数 字符串列表 jars 此会话中要使用的 Jar 字符串列表 pyFiles 将在本次会话中使用的 Python 文件 字符串列表 files 此会话中要使用的文件 字符串列表 driverMemory 用于驱动程序进程的内存量 String driverCores 用于驱动程序进程的内核数 int executorMemory 每个执行程序进程使用的内存量 String executorCores 每个执行程序使用的内核数 int numExecutors 为此会话启动的执行程序数 int archives 将在本次会话中使用的存档 字符串列表 队列 要提交到的 YARN 队列的名称 String name 此会话的名称 String conf Spark 配置属性 key=val 的映射 响应正文 创建的 Batch 对象。
name description type ID 会话 ID int appId 此会话的应用程序 ID String appInfo 详细的应用程序信息 key=val 的映射 log 日志行 字符串列表 state 批处理状态 String 注意
提交脚本时,分配的 Livy 配置将显示在输出窗格中。
通过资源管理器与 Azure HDInsight 集成
可以通过 Azure HDInsight 资源管理器直接在群集中预览 Hive 表:
连接到 Azure 帐户(如果尚未这样做)。
选择最左侧列中的“Azure”图标。
在左窗格中,展开“AZURE:HDINSIGHT”。 此时会列出可用的订阅和群集。
展开群集以查看 Hive 元数据数据库和表架构。
右键单击 Hive 表。 例如:hivesampletable。 选择“预览”。
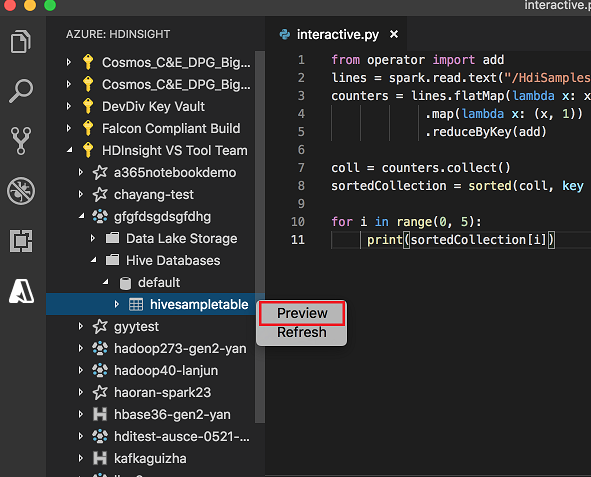
此时会打开“预览结果”窗口:
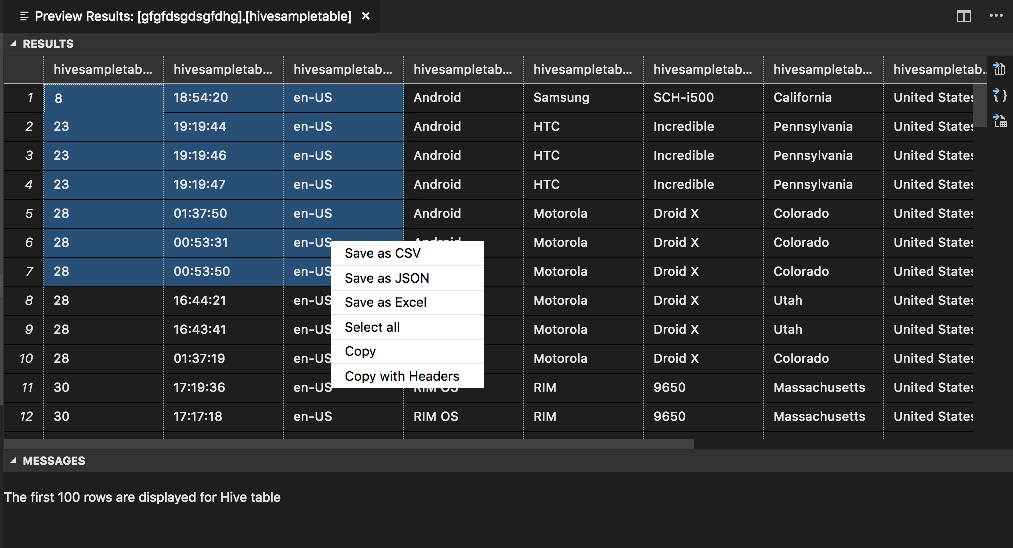
“结果”面板
可以将整个结果作为 CSV、JSON、Excel 保存到本地路径,也可以只选择多个行。
“消息”面板
如果表中的行数大于 100,将显示消息:“显示了 Hive 表的前 100 行”。
如果表中的行数小于或等于 100,将显示以下消息:“显示了 Hive 表的 60 行”。
如果表中没有任何内容,将显示以下消息:“
0 rows are displayed for Hive table.”注意
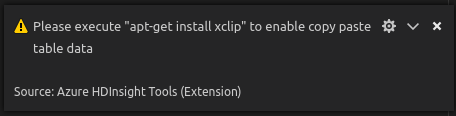
在 Linux 中,安装 xclip 用于复制表数据。
其他功能
适用于 Visual Studio Code 的 Spark 和 Hive 还支持以下功能:
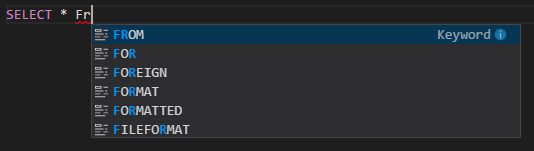
IntelliSense 自动完成。 弹出关键字、方法、变量和其他编程元素的相关建议。 不同图标表示不同类型的对象:
IntelliSense 错误标记。 语言服务会为 Hive 脚本的编辑错误添加下划线。
语法突出显示。 语言服务使用不同颜色来区分变量、关键字、数据类型、函数和其他编程元素:
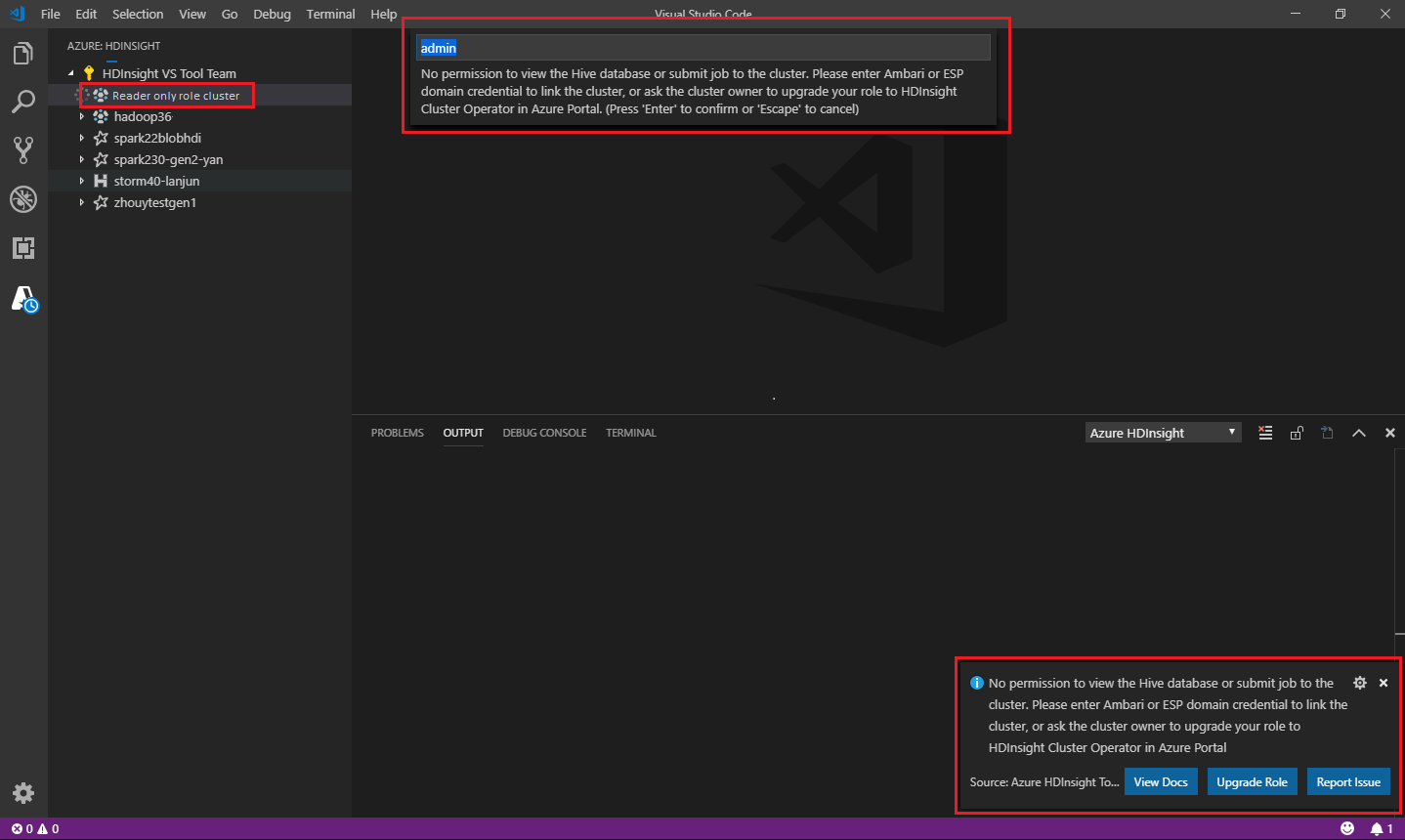
仅限读取者角色
分配有群集“仅限读取者”角色的用户无法将作业提交到 HDInsight 群集,也无法查看 Hive 数据库。 需在 Azure 门户中联系群集管理员将你的角色升级到 HDInsight 群集操作员。 如果你有有效的 Ambari 凭据,可遵循以下指导手动链接群集。
浏览 HDInsight 群集
选择 Azure HDInsight 资源管理器展开 HDInsight 群集时,如果你对群集拥有“仅限读取者”角色,系统会提示你链接群集。 使用 Ambari 凭据通过以下方法链接到群集。
将作业提交到 HDInsight 群集
将作业提交到 HDInsight 群集时,如果你对群集拥有“仅限读取者”角色,系统会提示你链接群集。 使用 Ambari 凭据通过以下步骤链接到群集。
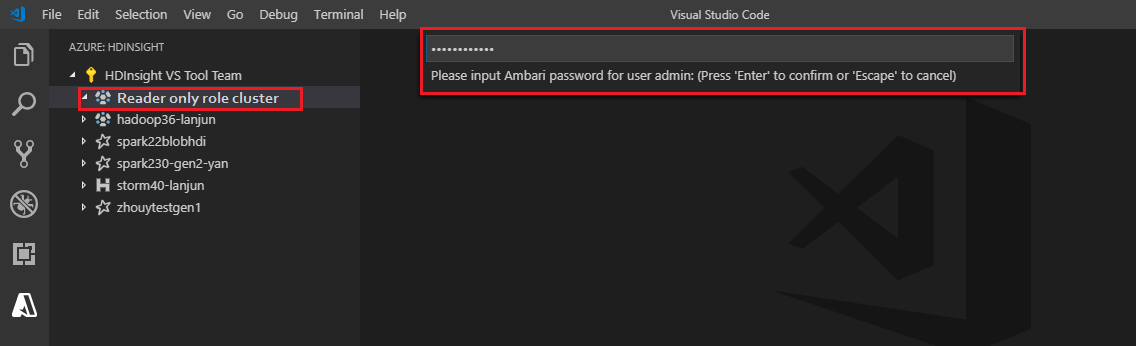
链接到群集
输入有效的 Ambari 用户名。
输入有效的密码。
注意
可以使用
Spark / Hive: List Cluster来检查链接的群集:
Azure Data Lake Storage Gen2
浏览 Data Lake Storage Gen2 帐户
选择 Azure HDInsight 资源管理器,展开 Data Lake Storage Gen2 帐户。 如果 Azure 帐户对 Gen2 存储没有访问权限,则系统会提示你输入存储访问密钥。 验证访问密钥后,Data Lake Storage Gen2 帐户将自动展开。
将作业提交到使用 Data Lake Storage Gen2 的 HDInsight 群集
使用 Data Lake Storage Gen2 将作业提交到 HDInsight 群集。 如果 Azure 帐户对 Gen2 存储没有写入权限,则系统会提示你输入存储访问密钥。 验证访问密钥后,作业将成功提交。

注意
可以在 Azure 门户中获取存储帐户的访问密钥。 有关详细信息,请参阅管理存储帐户访问密钥。
取消链接群集
在菜单栏中,转到“视图”>“命令面板”,然后输入“Spark/Hive: Unlink a Cluster”。
选择要取消链接的群集。
查看“输出”视图以进行验证。
注销
在菜单栏中,转到“视图”>“命令面板”,然后输入“Azure: 注销”。
已知问题
Synapse PySpark 安装错误。
对于 Synapse PySpark 安装错误,由于其他团队不再维护其依赖项,因此不会再对它进行维护。 如果你尝试使用交互式 Synapse Pyspark,请改用 Azure Synapse Analytics。 这是一项长期更改。
后续步骤
有关演示了如何使用适用于 Visual Studio Code 的 Spark 和 Hive 的视频,请观看适用于 Visual Studio Code 的 Spark 和 Hive。